







周志华机器学习-决策树
第一章 绪论
第二章 模型评估与选择
第三章 线性模型
第四章 决策树
第五章 支持向量机
第六章 神经网络
第七章 贝叶斯分类器
第八章 集成学习和聚类
一、决策树基本流程?


- 决策树的策略:分而治之
对三种“停止”的情况处理:
- 递归返回
- 对观察到的数据,根据后验概率进行划分(当前节点谁多就是谁)
- 对父节点的数据当作样本的先验概率(上一个节点谁多就是谁)

- 决策树算法的核心:如何判断怎样的属性是最适合进行划分的
二、信息增益划分

信息熵:度量样本集合纯度纯度的指标–还需要多少属性才能把当前样本划分干净,值越小代表划分得约干净
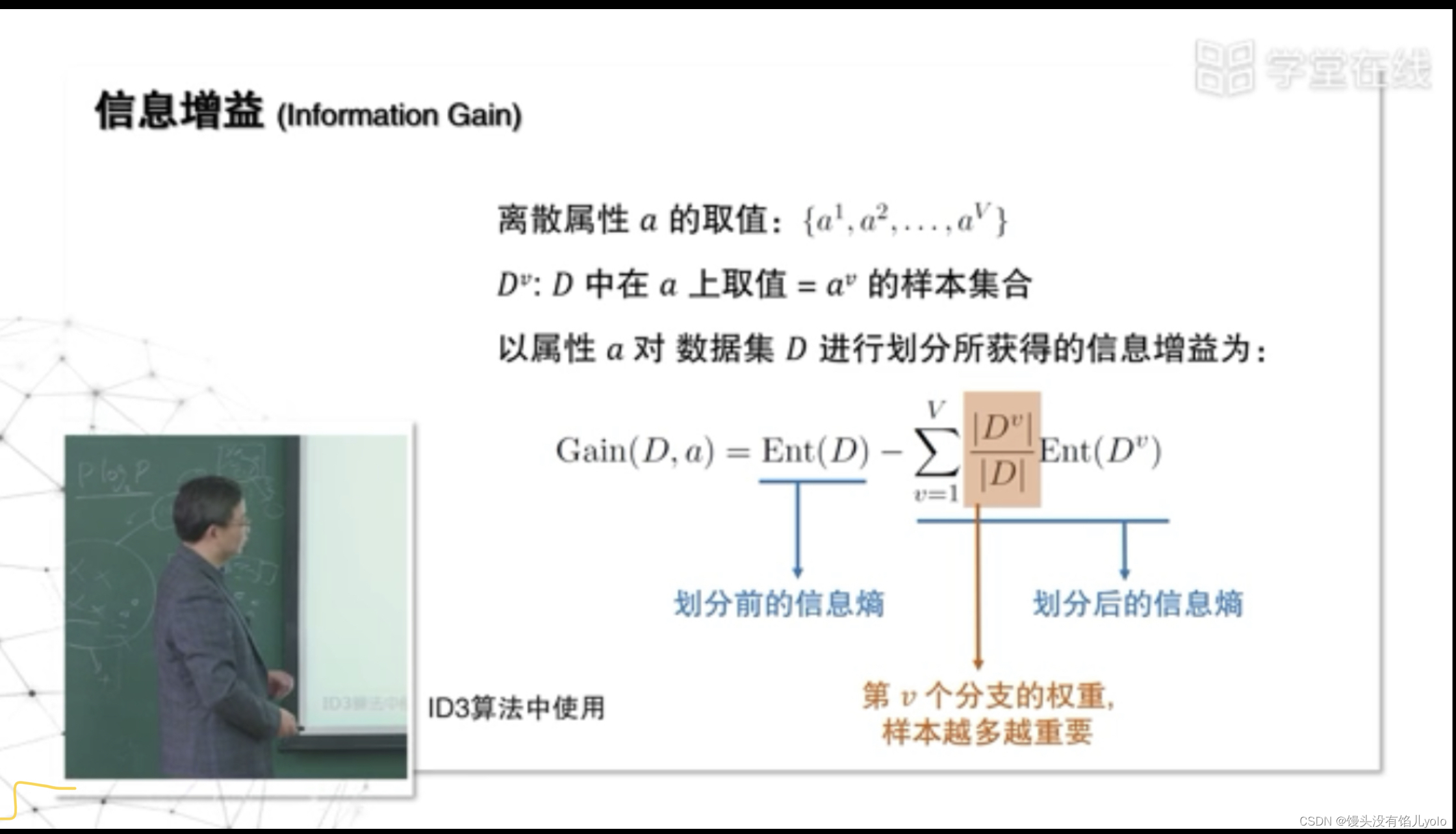
信息增益【ID3算法】:当前的划分对信息熵造成的变化
- 西瓜例子
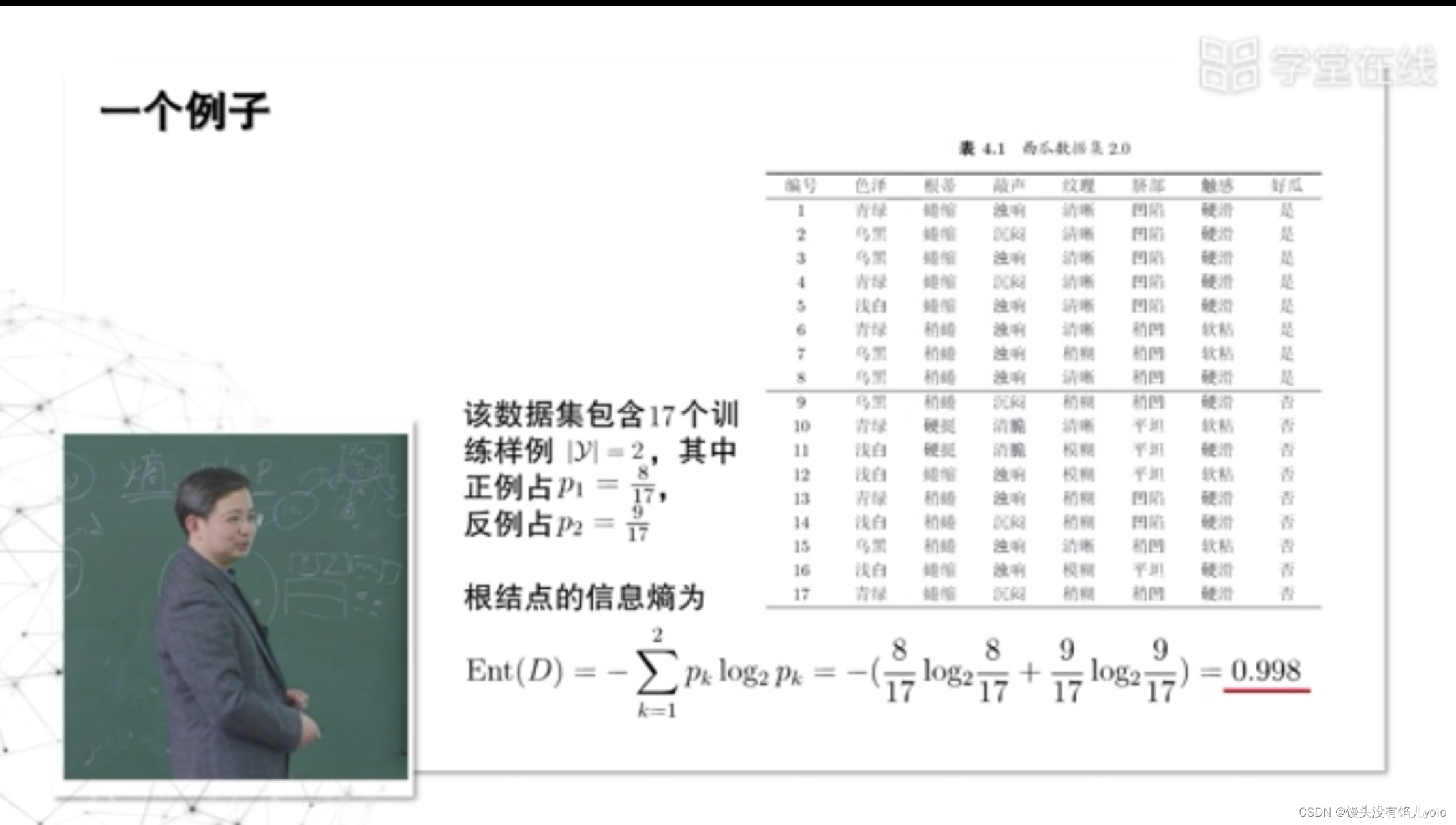
先计算根节点的信息熵
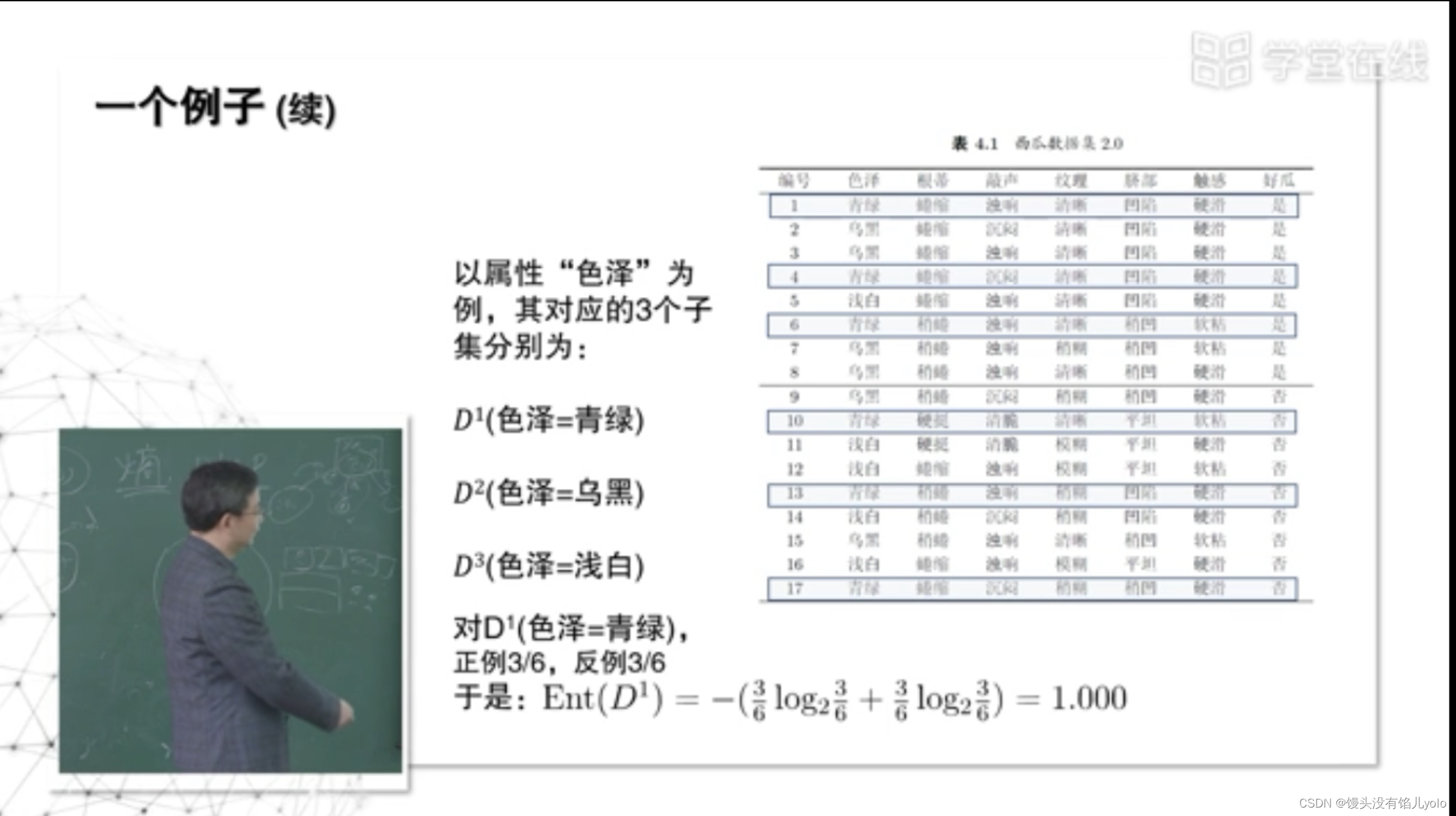
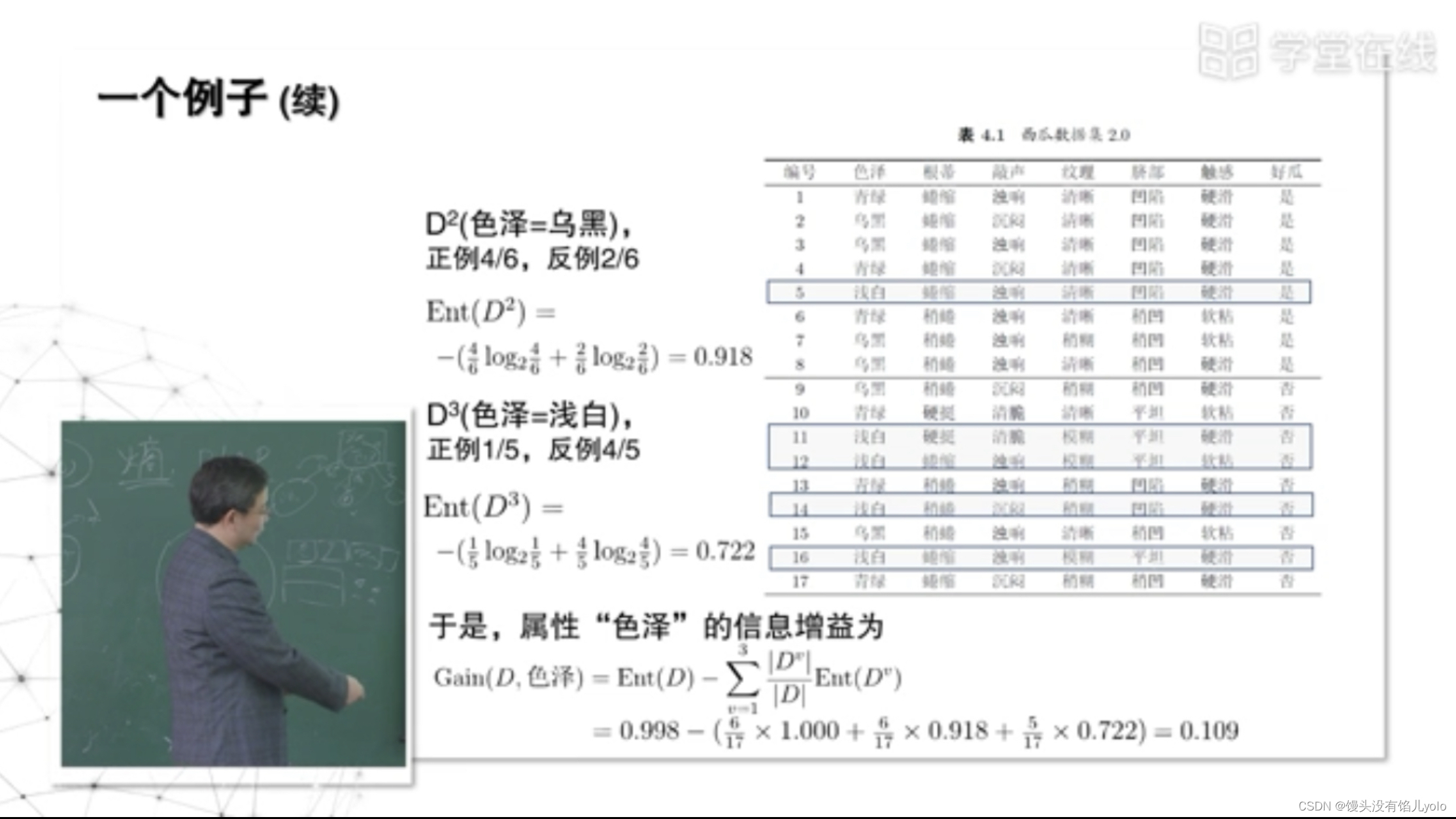
以色泽为属性计算信息熵,其带来的信息增益=根节点信息熵-划分后的信息熵

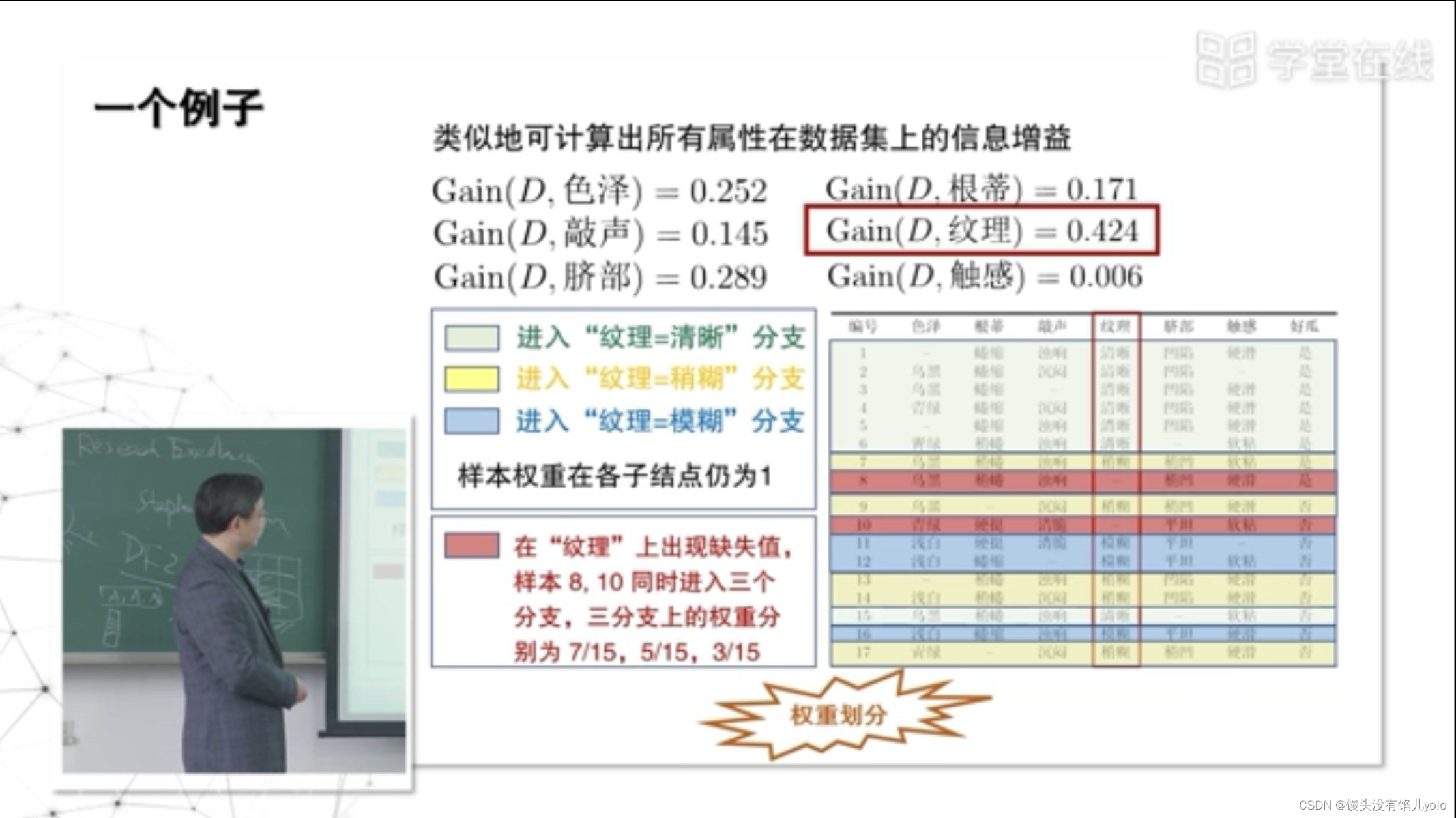
继续计算其他划分属性的信息增益,可见,“纹理”属性带来的信息增益最大,可以被选为划分属性
三、其他属性划分准则
增益率【C4.5算法】
如若只考虑信息增益,则在属性越多,分得越细的情况,其增益越大,但这种情况的泛化性能会变差。(如,将特定的电话号码对应地址,则是一一对应的关系,但其不具备泛化性能)
于是,引入了增益率的概念

- 分支数越多,IV越大–避免不断增加属性以增大信息增益
- 理想的情况,分得纯度越大,但所需的分支越小
- 但并非增益率最大的情况得到的决策树最完美,难以绝对正确地平衡信息增益和增益率–启发式用以解决此问题
- 增益率起到了规范化(normalization)的作用–让不可比的东西变得可比
基尼指数【CART算法】

如,每次从一堆球中抓两个球,其不一样的概率Gini(n),值代表还需要多少才能使其变干净,越小说明数据集的纯度越高
四、决策树的剪枝

剪枝方法对决策树的泛化影响大于不同划分选择的影响

五、缺失值的处理

-
样本赋权
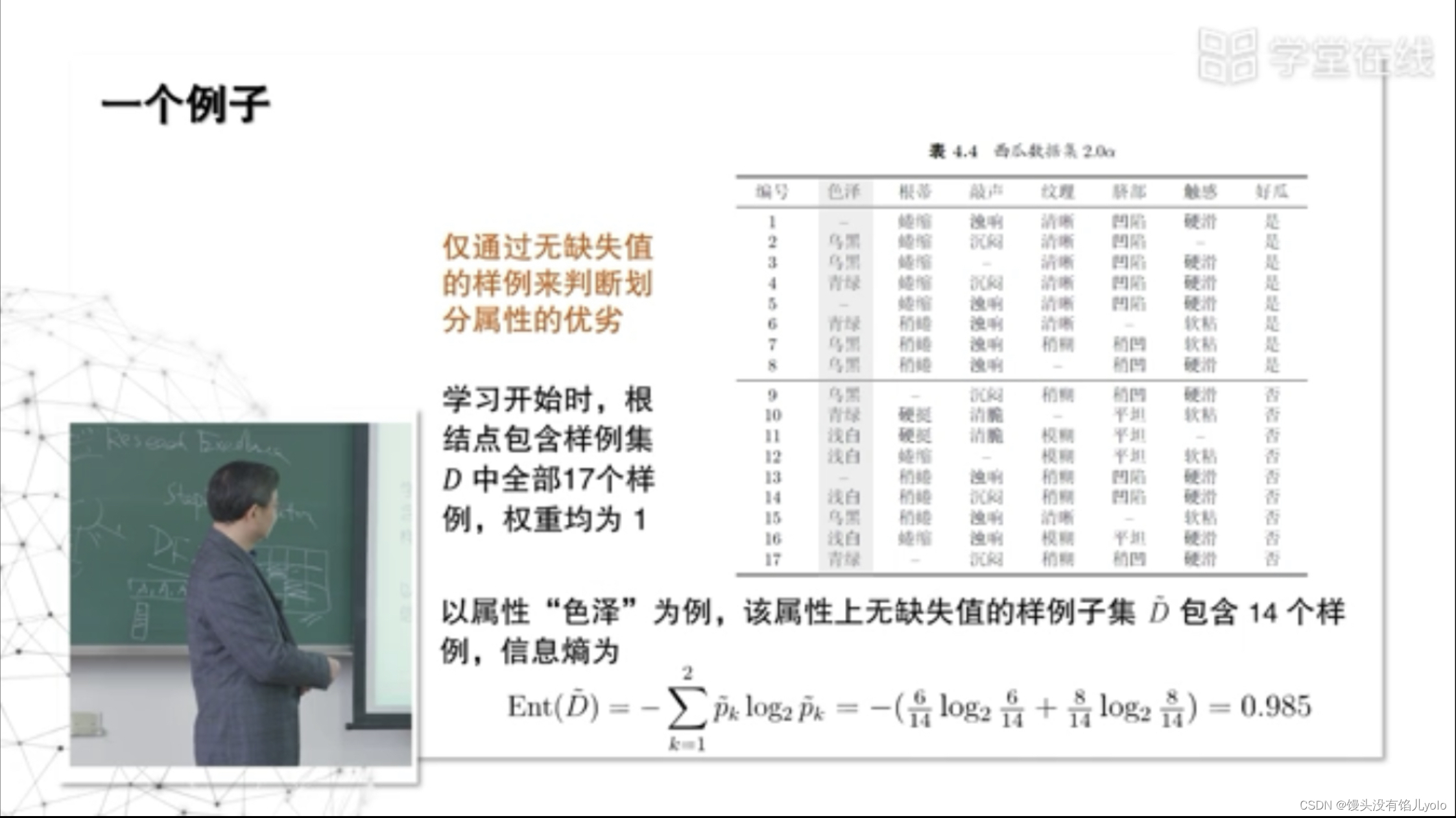

-
权重划分















 885
885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









