







非数值类型数据处理
1. Get_dummies哑变量处理
1.简单示例:“男”和“女”的数值转换
import pandas as pd
df = pd.DataFrame({'客户编号': [1, 2, 3], '性别': ['男', '女', '男']})
df
df = pd.get_dummies(df, columns=['性别'])
df 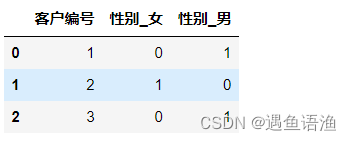
df = df.drop(columns='性别_女') df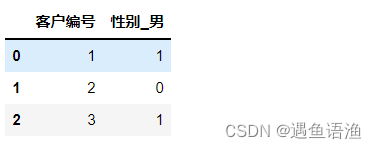
df = df.rename(columns={'性别_男':'性别'})
df 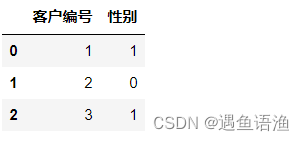
2.稍复杂点的案例:房屋朝向的数值转换
import pandas as pd
df = pd.DataFrame({'房屋编号': [1, 2, 3, 4, 5], '朝向': ['东', '南', '西', '北', '南']})
df 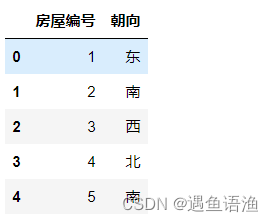
df = pd.get_dummies(df, columns=['朝向'])
df 
df = df.drop(columns='朝向_西') df
2. Label Encoding编号处理
import pandas as pd
df = pd.DataFrame({'编号': [1, 2, 3, 4, 5], '城市': ['北京', '上海', '广州', '深圳', '北京']})df
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
label = le.fit_transform(df['城市'])df['城市'] = labeldf
3. pandas库中的replace()函数
df = pd.DataFrame({'编号': [1, 2, 3, 4, 5], '城市': ['北京', '上海', '广州', '深圳', '北京']})df['城市'].value_counts()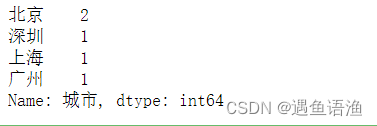
df['城市'] = df['城市'].replace({'北京': 0, '上海': 1, '广州': 2, '深圳':3})
df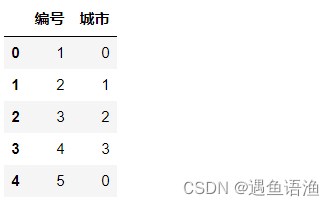
数据标准化
# 构造数据
import pandas as pd
X = pd.DataFrame({'酒精含量(%)': [50, 60, 40, 80, 90], '苹果酸含量(%)': [2, 1, 1, 3, 2]})
y = [0, 0, 0, 1, 1]
X # 查看X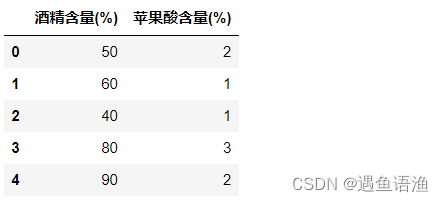
min-max标准化
from sklearn.preprocessing import MinMaxScaler
X_new = MinMaxScaler().fit_transform(X)
print(X_new) # 查看X_new
Z-score标准化
from sklearn.preprocessing import StandardScaler
X_new = StandardScaler().fit_transform(X)
print(X_new) # 查看X_new
数据分箱
import pandas as pd
data = pd.DataFrame([[22,1],[25,1],[20,0],[35,0],[32,1],[38,0],[50,0],[46,1]], columns=['年龄', '是否违约'])
data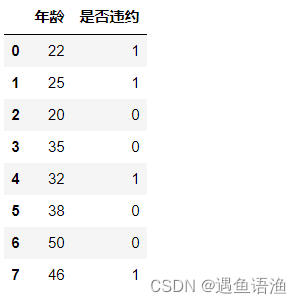
# 通过如下代码即可进行等宽数据分箱:
data_cut = pd.cut(data['年龄'], 3)
print(data_cut)
# 通过groupby()函数进行分组,count()函数(详见14.3节补充知识点)进行计数可以获取每个分箱中的样本数目,代码如下:
data['年龄'].groupby(data_cut).count()
# 补充知识点,分箱并进行编号
print(pd.cut(data['年龄'], 3, labels=[1, 2, 3])) 















 5993
5993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









