







一. SVD基础
隐形语义索引:最早的SVD应用之一就是信息检索,我们称利用SVD的方法为隐性语义检索(LSI)或隐形语义分析(LSA)
推荐系统:SVD的另一个应用就是推荐系统,较为先进的推荐系统先利用SVD从数据中构建一个主题空间,然后再在该空间下计算相似度,以此提高推荐的效果。
SVD与PCA不同,PCA是对数据的协方差矩阵进行矩阵的分解,而SVD是直接在原始矩阵上进行的矩阵分解。并且能对非方阵矩阵分解,得到左奇异矩阵U、sigma矩阵Σ、右奇异矩阵VT。
1.1奇异值与特征值基础知识:
特征值分解和奇异值分解在机器学习领域都是属于满地可见的方法。两者有着很紧密的关系,我在接下来会谈到,特征值分解和奇异值分解的目的都是一样,就是提取出一个矩阵最重要的特征。先谈谈特征值分解吧:
1)特征值:
如果说一个向量v是方阵A的特征向量,将一定可以表示成下面的形式:
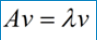
这时候λ就被称为特征向量v对应的特征值,一个矩阵的一组特征向量是一组正交向量。特征值分解是将一个矩阵分解成下面的形式:
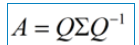
其中Q是这个矩阵A的特征向量组成的矩阵,Σ是一个对角阵,每一个对角线上的元素就是一个特征值。我这里引用了一些参考文献中的内容来说明一下。首先,要明确的是,一个矩阵其实就是一个线性变换,因为一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换。比如说下面的一个矩阵:
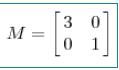
它其实对应的线性变换是下面的形式:
因为这个矩阵M乘以一个向量(x,y)的结果是:

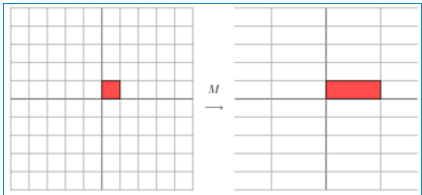
上面的矩阵是对称的,所以这个变换是一个对x,y轴的方向一个拉伸变换(每一个对角线上的元素将会对一个维度进行拉伸变换,当值>1时,是拉长,当值<1时时缩短),当矩阵不是对称的时候,假如说矩阵是下面的样子:

它所描述的变换是下面的样子:

这其实是在平面上对一个轴进行的拉伸变换(如蓝色的箭头所示),在图中,蓝色的箭头是一个最主要的变化方向(变化方向可能有不止一个),如果我们想要描述好一个变换,那我们就描述好这个变换主要的变化方向就好了。反过头来看看之前特征值分解的式子,分解得到的Σ矩阵是一个对角阵,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列)
当矩阵是高维的情况下,那么这个矩阵就是高维空间下的一个线性变换,这个线性变化可能没法通过图片来表示,但是可以想象,这个变换也同样有很多的变换方向,我们通过特征值分解得到的前N个特征向量,那么就对应了这个矩阵最主要的N个变化方向。我们利用这前N个变化方向,就可以近似这个矩阵(变换)。也就是之前说的:提取这个矩阵最重要的特征。总结一下,特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。
二.SVD的定义
SVD也是对矩阵进行分解,但是和特征分解不同,SVD并不要求要分解的矩阵为方阵。假设我们的矩阵A是一个m×n的矩阵,那么我们定义矩阵A的SVD为:
A=UΣVT
其中U是一个m×m的矩阵,Σ是一个m×n的矩阵,除了主对角线上的元素以外全为0,主对角线上的每个元素都称为奇异值,V是一个n×n的矩阵。U和V都是酉矩阵,即满足UTU=I,VTV=I。下图可以很形象的看出上面SVD的定义:



代码实现SVD:
SCV实现的相关线性代数,但我们无需担心SVD的实现,在Numpy中有一个称为线性代数linalg的线性代数工具箱能帮助我们。下面演示其用法对于一个简单的矩阵
from numpy import *
from numpy import linalg as la
df = mat(array([[1,1],[1,7]]))
U,Sigma,VT = la.svd(df)
print(U)
# [[ 0.16018224 0.98708746]
# [ 0.98708746 -0.16018224]]
print(Sigma)
# [7.16227766 0.83772234]
print(VT)
# [[ 0.16018224 0.98708746]
# [ 0.98708746 -0.16018224]]
# (用户x商品) # 为0表示该用户未评价此商品,即可以作为推荐商品
def loadExData2():
return [[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]]
# 替代上面的standEst(功能) 该函数用SVD降维后的矩阵来计算评分
def svdEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]
simTotal = 0.0; ratSimTotal = 0.0
U,Sigma,VT = la.svd(dataMat)
Sig4 = mat(eye(4)*Sigma[:4]) #将奇异值向量转换为奇异值矩阵
xformedItems = dataMat.T * U[:,:4] * Sig4.I # 降维方法 通过U矩阵将物品转换到低维空间中 (商品数行x选用奇异值列)
for j in range(n):
userRating = dataMat[user,j]
if userRating == 0 or j == item:
continue
# 这里需要说明:由于降维后的矩阵与原矩阵代表数据不同(行由用户变为了商品),所以在比较两件商品时应当取【该行所有列】 再转置为列向量传参
similarity = simMeas(xformedItems[item,:].T,xformedItems[j,:].T)
# print('%d 和 %d 的相似度是: %f' % (item, j, similarity))
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0:
return 0
else:
return ratSimTotal/simTotal
# 结果测试如下:
myMat = mat(loadExData2())
result1 = recommend(myMat,1,estMethod=svdEst) # 需要传参改变默认函数
print(result1)
result2 = recommend(myMat,1,estMethod=svdEst,simMeas=pearsSim)
print(result2)
SVD应用于图片:
from skimage import io
import matplotlib.pyplot as plt
path = 'male_god.jpg'
data = io.imread(path)
data = mat(data) # 需要mat处理后才能在降维中使用矩阵的相乘
U,sigma,VT = linalg.svd(data)
# 在重构之前,依据前面的方法需要选择达到某个能量度的奇异值
cnt = sum(sigma)
print(cnt)
cnt90 = 0.9*cnt # 达到90%时的奇异总值
print(cnt90)
count = 50 # 选择前50个奇异值
cntN = sum(sigma[:count])
print(cntN)
# 重构矩阵
dig = mat(eye(count)*sigma[:count]) # 获得对角矩阵
# dim = data.T * U[:,:count] * dig.I # 降维 格外变量这里没有用
redata = U[:,:count] * dig * VT[:count,:] # 重构
plt.imshow(redata,cmap='gray') # 取灰
plt.show() # 可以使用save函数来保存图片
SVD两个个人觉得最重要的计算步骤这里说一下:
数据集降维: 这里的sigma为对角矩阵(需要利用原来svd返回的sigma向量构建矩阵,构建需要使用count这个值)。U为svd返回的左奇异矩阵,count为我们指定的多少个奇异值,这也是sigma矩阵的维数。
重构数据集: 这里的sigma同样为对角矩阵(需要利用原来svd返回的sigma向量构建矩阵,构建需要使用count这个值),VT为svd返回的右奇异矩阵,count为我们指定的多少个奇异值(可以按能量90%规则选取)。

















 3680
3680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









