






1、环境准备
- python3
- 安装火狐浏览器
- 下载geckodriver.exe(注意与python、火狐浏览器版本匹配)geckodriver下载地址, 版本参考网站
- python selenium库安,若安装出问题,可手动下载.whl文件离线安装。下载地址
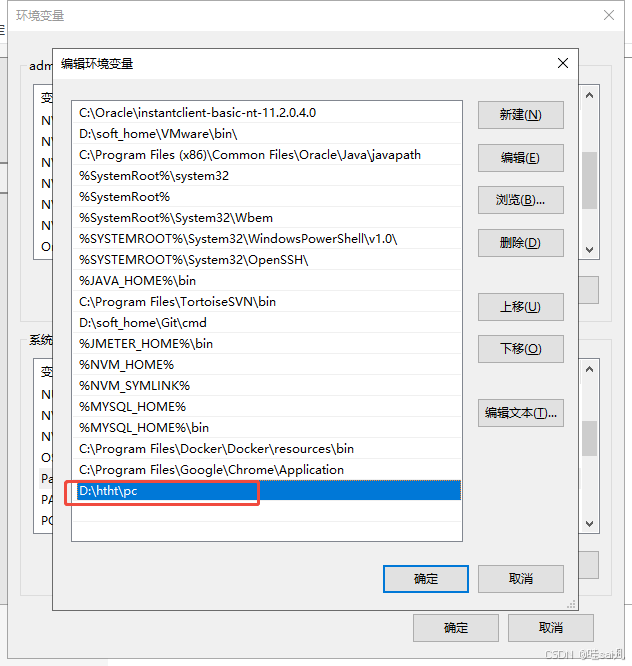
- 环境配置,需要为geckodriver.exe配置环境变量,在Path中增加geckodriver.exe存放文件夹地址,如我本地存放地址
参考代码
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.firefox.options import Options
import urllib
import os
import time
# 如果不需要显示浏览器界面,设置为 True
options = Options()
options.headless = True
# 创建浏览器操作对象
s = Service(r"D:\htht\pc\geckodriver.exe")
browser = webdriver.Firefox(service=s, options=options)
# 打开网站
browser.get('http://www.nmc.cn/publish/precipitation/1-day.html') # 打开页面
day_str = ['24小时', '48小时', '72小时', '96小时', '120小时', '144小时', '168小时']
save_map_path = "D:/htht/pc/yb/"
time.sleep(2)
for i, day in enumerate(day_str):
browser.find_element(By.LINK_TEXT, value=day).click()
# time.sleep(2)
imgpath = browser.find_element(By.XPATH, '//*[@id="imgpath"]')
imgsrc = imgpath.get_attribute('src')
full_name = imgsrc.split('/', -1)[-1].split('_')[-1].split('?')[0]
# img_name = full_name[:8] + "-" + full_name[12:15] + full_name[-4:]
img_name = full_name[:8] + "-day" + str(i+1) + full_name[-4:]
save_path = save_map_path + '/' + full_name[:4] + '/' + full_name[4:8] + '/'
if not os.path.exists(save_path):
os.makedirs(save_path)
# 下载图片
urllib.request.urlretrieve(url=imgsrc, filename=save_path + img_name)
print("{}下载完成".format(img_name))
3、执行python

参考文章:https://zhuanlan.zhihu.com/p/640800211

















 3744
3744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









