




一、引入原因
正则化是为了处理过拟合问题,关于什么是过拟合,可查看这篇博客https://blog.csdn.net/weixin_45459911/article/details/105769370
二、正则化的常用方法
1、增大训练集
训练的数据集规模越大,越不容易发生过拟合,但是这点往往受限于实际要求,所以有的时候很难实现。
2、L1 & L2范数
1、范数的数学定义
假设 x 是一个向量,它的 L p L^p Lp 范数定义:
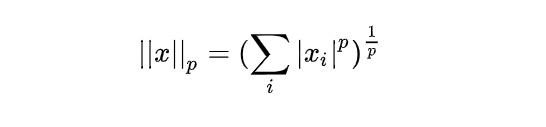
2、实现原理
在目标函数后面添加一个系数的“惩罚项”是正则化的常用方式,为了防止系数过大从而让模型变得复杂。在加了正则化项之后的目标函数为:
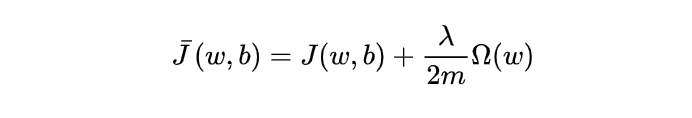
式中, λ / 2 m {\lambda}/{2m} λ/2m是一个常数, m 为样本个数, λ \lambda λ 是一个超参数,用于控制正则化程度,而 Ω ( w ) \Omega(w)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 43万+
43万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









