







文章目录
相关文章:
监督学习 | 集成学习之Bagging、随机森林及Sklearn实现
Boosting
提升法(Boosting,最初被称为假设提升法)是指可以将几个弱学习器结合成一个强学习器的任意集成方法。大多数提升法的总体思路是循环训练预测器,每一次都对其前序做出一些改正。可用的提升法有很多,但目前最流行的方法是AdaBoost(Adaptive Boosting,自适应提升法)和梯度提升。
1. AdaBoost
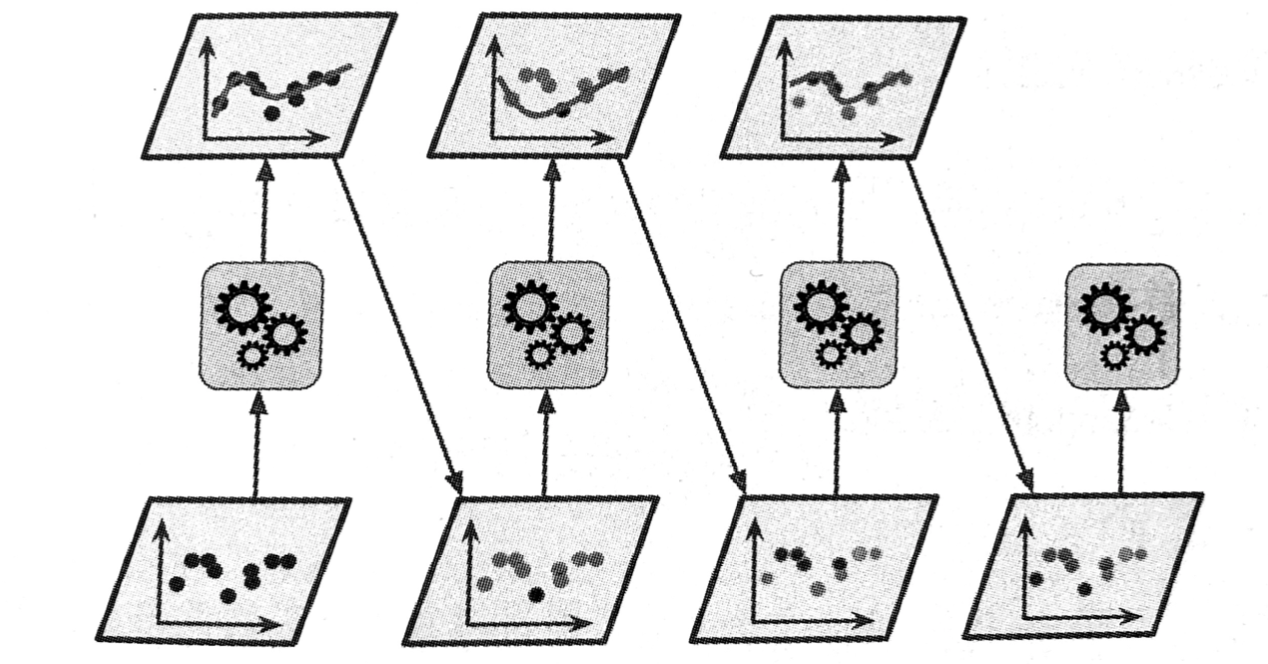
新预测器对其前序进行纠正的方法之一,就是更多地关注前序拟合不足的训练实例。从而使新的预测器不断地越来越专注于难缠的问题,这就是 AdaBoost 使用的技术。
例如要构建一个 AdaBoost 分类器,首先需要训练一个基础分类器(比如决策树),用它对训练集进行预测,然后对错误分类的训练实例增加其相对权重。接着,使用这个新的权重对第二个分类器进行训练,然后再次对训练集进行预测,继续更新权重,并不断循环前进。[1]
1.1 AdaBoost 原理

AdaBoost 有多种推导方式,比较容易理解的是基于“加线性模型”(additive model),即基学习器 h h h 的线性组合:
(1) H ( x ) = ∑ t = 1 T α t h t ( x ) H(x)=\sum_{t=1}^T \alpha_t h_t(x) \tag{1} H(x)=t=1∑Tαtht(x)(1)
来最小化指数损失函数(exponential loss function):
ℓ e x p ( H ∣ D ) = E x ∼ D [ e − f ( x ) H ( x ) ] t a g 2 \ell_{exp}(H|D)=E_{x\sim D}[e^{-f(x)H(x)}] tag{2} ℓexp(H∣D)=Ex∼D[e−f(x)H(x)]tag2
若 H ( x ) H(x) H(x) 能令指数损失函数最小化,则考虑公式 (2) 对 H ( x ) H(x) H(x) 的偏导:
(3) ∂ ℓ exp ( H ∣ D ) ∂ H ( x ) = − e − H ( x ) P ( f ( x ) = 1 ∣ x ) + e H ( x ) P ( f ( x ) = − 1 ∣ x ) \frac{\partial \ell_{\exp }(H | \mathcal{D})}{\partial H(\boldsymbol{x})}=-e^{-H(\boldsymbol{x})} P(f(\boldsymbol{x})=1 | \boldsymbol{x})+e^{H(\boldsymbol{x})} P(f(\boldsymbol{x})=-1 | \boldsymbol{x}) \tag{3} ∂H(x)∂ℓexp(H∣D)=−e−H(x)P(f(x)=1∣x)+eH(x)P(f(x)=−1∣x)(3)
令公式 (3) 为零可解得:
(4) H ( x ) = 1 2 l n P ( f ( x ) = 1 ∣ x ) P ( f ( x ) = − 1 ∣ x ) H(x)=\frac{1}{2}ln\frac{P(f(x)=1|x)}{P(f(x)=-1|x)} \tag{4} H(x)=21lnP(f(x)=−1∣x)P(f(x)=1∣x)(4)
因此有:
(5) sign ( H ( x ) ) = sign ( 1 2 ln P ( f ( x ) = 1 ∣ x ) P ( f ( x ) = − 1 ∣ x ) ) = { 1 , P ( f ( x ) = 1 ∣ x ) > P ( f ( x ) = − 1 ∣ x ) − 1 , P ( f ( x ) = 1 ∣ x ) > P ( f ( x ) = − 1 ∣ x ) = arg max y ∈ { − 1 , 1 } P ( f ( x ) = y ∣ x ) \begin{aligned} \operatorname{sign}(H(\boldsymbol{x})) &=\operatorname{sign}\left(\frac{1}{2} \ln \frac{P(f(x)=1 | \boldsymbol{x})}{P(f(x)=-1 | \boldsymbol{x})}\right) \\ &=\left \{\begin{array}{ll}{1,} & {P(f(x)=1 | \boldsymbol{x})>P(f(x)=-1 | \boldsymbol{x})} \\ {-1,} & {P(f(x)=1 | \boldsymbol{x})>P(f(x)=-1 | \boldsymbol{x})} \\ \end{array}\right.\\ & {=\underset{y \in\{-1,1\}}{\arg \max } P(f(x)=y | \boldsymbol{x})} \end{aligned} \tag{5} sign(H(x))=sign(21lnP(f(x)=−1∣x)P(f(x)=1∣x))={ 1,−1,P(f(x)=1∣x)>P(f(x)=−1∣x)P(f(x)=1∣x)>P(f(x)=−1∣x)=y∈{ −1,1}argmaxP(f(x)=y∣x)(5)
这意味着 s i g n ( H ( x ) ) sign(H(x)) sign(H(x)) 达到了贝叶斯最优错误率。换言之,若指数损失函数最小化,则分类错误率也将最小化;这说明指数损失函数是分类问题原本0/1 损失函数的一致替代损失函数。由于这个替代函数是连续可微的,因此我们用它代替 0/1 损失函数作为优化目标。
在 AdaBoost 算法中,第一个基分类器 h 1 h_1 h1 是通过直接将基学习器用于初始数据分布而得;此后迭代地生成 h t h_t ht 和 α t \alpha_t αt,当基分类器 h t h_t ht 基于分布 D t D_t Dt 产生后,该基分类器的权重 α t \alpha_t αt 应使得 α t h t \alpha_th_t αtht 最小化指数损失函数:
(6) ℓ exp ( α t h t ∣ D t ) = E x ∼ D t [ e − f ( x ) α t h t ( x ) ] = E x ∼ D t [ e − α t I ( f ( x ) = h t ( x ) ) + e α t I ( f ( x ) ≠ h t ( x ) ) ] = e − α t P x ∼ D t ( f ( x ) = h t ( x ) ) + e α t P x ∼ D t ( f ( x ) ≠ h t ( x ) ) = e − α t ( 1 − ϵ t ) + e α t ϵ t \begin{aligned} \ell_{\exp }\left(\alpha_{t} h_{t} | \mathcal{D}_{t}\right) &=\mathbb{E}_{\boldsymbol{x} \sim \mathcal{D}_{t}}\left[e^{-f(\boldsymbol{x}) \alpha_{t} h_{t}(\boldsymbol{x})}\right] \\ &=\mathbb{E}_{\boldsymbol{x} \sim \mathcal{D}_{t}}\left[e^{-\alpha_{t}} \mathbb{I}\left(f(\boldsymbol{x})=h_{t}(\boldsymbol{x})\right)+e^{\alpha_{t}} \mathbb{I}\left(f(\boldsymbol{x}) \neq h_{t}(\boldsymbol{x})\right)\right] \\ &=e^{-\alpha_{t}} P_{\boldsymbol{x} \sim \mathcal{D}_{t}}\left(f(\boldsymbol{x})=h_{t}(\boldsymbol{x})\right)+e^{\alpha_{t}} P_{\boldsymbol{x} \sim \mathcal{D}_{t}}\left(f(\boldsymbol{x}) \neq h_{t}(\boldsymbol{x})\right) \\ &=e^{-\boldsymbol{\alpha}_{t}}\left(1-\epsilon_{t}\right)+e^{\alpha_{t}} \epsilon_{t} \end{aligned} \tag{6} ℓexp(αtht∣Dt)=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 145
145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









