







1. selenium简介
用于实现自动化测试的 python 包,使用前需要安装对应浏览器驱动
from time import sleep
from selenium import webdriver
option = webdriver.ChromeOptions()
# 指定chrome存储路径的二进制形式
option.binary_location='D:\Chrome\Google\Chrome\Application\chrome.exe'
# 获取谷歌浏览器驱动
driver = webdriver.Chrome(options=option)
# 浏览器访问指定网站
driver.get('http://www.baidu.com')
# 3秒后浏览器关闭
sleep(3)
2. 控制组件的各种方式
# 在输入方法之前一定要清空操作
# 输入值为value的方法【文件上传按钮也使用send_keys(path)而不是click】
# ele为定位到的组件
ele.send_keys(value)
# 点击方法
ele.click()
# 清空
ele.clear()
driver.find_element(s)
# 定位到id值为user的组件,并将'admin'填入
# by另外还能填name,class_name,xpath,css_selector等,返回WebElement单个元素
driver.find_element(by='id',value='user').send_keys('admin')
from selenium.webdriver.common.by import By
# find_elements中有s时,by参数需要传入By.xx属性,结果返回是list,装载多个WebElement元素
# 定位到tag为input的组件,并将'admin'填入第一个input组件中
driver.find_elements(by=By.TAG_NAME,value='input')[0].send_keys('admin')
超链接LINK_TEXT和PARTIAL_LINK_TEXT
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
option = webdriver.ChromeOptions()
# 指定chrome存储路径的二进制形式
option.binary_location='D:\Chrome\Google\Chrome\Application\chrome.exe'
driver = webdriver.Chrome(options=option)
# r是告知字符串内无转义字符
url = r'D:\个人\学习资料\黑马程序员\Web自动化\web自动化_day01_课件+笔记+资料+代码\02_其他资料\注册实例.html'
# 打开url对应的网页
driver.get(url)
# a标签精确匹配,定位到超链接内容为'注册A网页'的地方
# ele = driver.find_elements(by=By.LINK_TEXT,value='注册A网页')
# a标签模糊匹配,定位到所有超链接内容包含'注册'的地方
ele = driver.find_elements(by=By.PARTIAL_LINK_TEXT,value='注册')
# 选择第二个定位到的超链接并点击
ele[1].click()
# 线程暂停3秒
sleep(3)
# 浏览器关闭
driver.quit()
2.1 XPath定位
XPath是xml path的简称。在html页面中,各组件都有自己的层级结构,通过类似路径的方式定位到组件
-
通过绝对路径进行定位,以 /html 开头

-
通过相对路径进行定位,以为 // 开头【后续分隔依然是/】

-
路径 + 属性 + 逻辑 进行定位

# 对应的实现代码 ele = driver.find_elements(by=By.XPATH, value="//p[@id='login_user']/input[@name='user-test' and @class='login']") -
通过 xpath 内置方法定位
# 定位到所有标签中文本内容为xxx的元素 //*[text()='xxx'] # 定位到属性中含有xxx的元素【这里的attribute是泛指,可以是id,name等】 //*[contains(@attribute,'xxx')] # 属性以xxx开头的元素 //*[starts-with(@attribute,'xxx')]
2.2 css选择器
CSS 是一种标记语言,用于控制元素的显示样式,在 css 标记语言中找元素使用 css 选择器,极力推荐使用,查找元素的效率比 Xpath 高,语法比 Xpath 更简单
-
id 选择器(前提:元素是必须有 id 属性)
// 定位到id值为user的元素 #user# 将name属性为user的第一个元素赋值为admin ele = driver.find_elements(by=By.CSS_SELECTOR,value="[name='user']") ele[0].send_keys('admin') -
class 选择器(前提:元素是必须有 class 属性)
// 定位到class值为group的元素 .group -
元素选择器
// 定位到input标签的元素 input -
属性选择器
// 定位到name属性为admin的元素【任意属性都可以使用这种方法进行定位】 [name='admin'] // input标签中type属性以p字母开头的元素 input[type^='p'] // input标签中type属性以p字母结束的元素 input[type$='p'] // input标签中type属性包含p字母的元素 input[type*='p'] -
层级选择器
// 定位到严格在p下一层的input元素 p>input // 定位到p下方的input【只要在下方即可】 p input
3. 浏览器常用API
# 最大化浏览器
driver.maximize_window()
# 设置浏览器大小 单位像素
driver.set_window_size(w, h)
# 设置浏览器位置
driver.set_window_position(x, y)
# 后退操作
driver.back()
# 前进操作
driver.forward()
# 刷新操作
driver.refresh()
# 关闭当前主窗口(主窗口:默认启动哪个界面,就是主窗口)
driver.close()
# 关闭由driver对象启动的所有窗口
driver.quit()
# 获取当前页面title信息
driver.title
# 获取当前页面url信息
drive.current_url
-
driver.title 和 driver.current_url 没有括号,一般为判断上步操作是否执行成功
-
driver.maximize_window() 一般为我的前置代码,在获取 driver 后,直接编写最大化浏览器
-
driver.close() 与 driver.quit() 区别
如果当前只有 1 个窗口,close 与 quit 没有任何区别
- close():关闭当前主窗口
- quit():关闭由 driver 对象启动的所有窗口
4. 元素信息操作API
获取各组件属性值相关API,如获取id,name等属性
# 获取元素文本
ele.text
#获取元素大小
ele.size
# 获取元素id属性值
ele.get_attribute("id")
# 判断元素是否可见
ele.is_displayed()
# 判断元素是否可用
ele.is_enabled()
# 判断元素是否被选中
ele.is_selected()
- text 和 size 调用时 无括号
- get_attribute 一般应用场景:判断一组元素是否为想要的元素或者判断元素属性值是否正确
- is_displayed、is_enabled、is_selected,在特殊应用场景中使用
5. 鼠标操作API
通过鼠标操作API模拟测试鼠标的各种效果
双击
# 鼠标事件对应的方法在哪个类中ActionChains类中
from selenium.webdriver.common.action_chains import ActionChains
action = ActionChains(driver)
# 所有操作均需经过perform()方法才能展示效果,当需要模拟多步操作时将perform()放在最后执行
# 右击
action.context_click(ele).perform()
# 双击
action.double_click(ele).perform()
# 拖拽【source是需要拖拽的组件,target是目标位置组件】
action.drag_and_drop(source,target).perform()
# 根据偏移量拖拽
action.drag_and_drop_by_offset(source,xoffset,yoffset)
# 悬停
action.move_to_element(ele).perform()
6. 键盘操作API
from selenium.webdriver.common.keys import Keys
# 删除键
ele.send_keys(Keys.BACK_SPACE)
# 空格键
ele.send_keys(Keys. SPACE)
# 制表键
ele.send_keys (Keys.TAB)
# 回退键
ele.send_keys(Keys.ESCAPE)
# 回车键
ele.send_keys(Keys.ENTER)
# 全选
ele.send_keys(Keys.CONTROL , 'a')
# 复制
ele.send_keys(Keys.CONTROL , 'c')
7. 元素等待
由于电脑配置或网络原因,在查找元素时,元素代码未在第一时间内被加载出来,而抛出未找到元素异常。元素在第一次未找到时,元素等待设置的时长被激活,如果在设置的有效时长内找到元素,继续执行代码,
7.1 隐式等待
设置后对所有组件都会等待
# 找不到组件时等待10秒
driver.implicitly_wait(10)
7.2 显示等待
只等待指定组件
from selenium.webdriver.support.wait import WebDriverWait
# 每隔0.5秒尝试寻找一次id值为d的组件,共持续10秒
wait_rule = WebDriverWait(driver,timeout=10,poll_frequency=0.5)
# until()参数为匿名函数,其中x是创建等待规则时传入的driver类
# 按照wait_rule的规则寻找id为user的组件
ele = wait_rule.until(lambda x:x.find_element_by_id("#user"))
# 设置组件值
ele.send_keys("admin")
8. 下拉框API
操作下拉框对应API,用 css 选择器配合 click 也可达到同样效果,使用 Select 则不需要使用 click
from selenium.webdriver.support.select import Select
# ele是下拉框对应的标签<select>,定位至select标签
s = Select(ele)
# 通过下标定位【从1开始】
s.select_by_index()
# 通过value属性定位
s.select_by_value()
# 通过下拉框文本定位
s.select_by_visible_text()
9. 弹窗处理
如果页面由弹出框【alert 警告框,confirm 确认框,prompt 提示框】,不处理,接下来的操作将不生效。
无论以上哪个对话框,都可以使用取消、同意,因为调用的是后台的事件,与页面显示按钮数量无关
# 获取对话框对象,统一转换为此对象处理
al = driver.switch_to.alert
# 获取对话框文本
al.text
# 对话框确认按钮
al.accept()
# 对话框取消按钮
al.dismiss()
10. 滚动条
在 web 自动化中有些特殊场景,如:滚动条拉倒最底层,指定按钮才可用,Selenium 中没有提供直接操作滚动条的API,但是可以通过执行 JS 语句完成此项工作
# 0是左边距【水平滚动条】,10000是上边距【垂直滚动条】,越界时拉到底
# 此处js作用是将滚动条垂直拉到底
js = "window.scrollTo(0,10000)"
# 执行js方法
driver.execute_script(js)
11. 同一页面内窗口切换
常用的 frame 表单有两种:frame、iframe
# 使用css语法可以定位至对于frame位置【可以使用name、id、iframe元素】
driver.switch_to.frame("id\name\element")
# 操作完毕后需要切换为主目录才能再次操作其余frame
driver.switch_to.default_content()
12. 多窗口切换
多个浏览器窗口间切换
# 获取当前主窗口句柄
driver.current_window_handle
# 获取当前由driver启动所有窗口句柄
driver.window_handles
# 切换至最开启的窗口
driver.switch_to.window(driver.window_handles[-1])
13. 截图
# 截图并保存至指定位置【png格式】
driver.get_screenshot_as_file(imgepath)
# 使用时间戳对事件命名
driver.get_screenshot_as_file("../image/%s.png"%(time.strftime("%Y_%m_%d %H_%M_%S")))
14. 验证码
验证码通常是为了放置恶意请求,因此程序不好直接控制,在测试环境下,通常对于验证码有如下策略
-
去掉验证码(项目在测试环境、公司自己的项目)
-
设置万能验证码(测试环境或线上环境,公司自己项目)
-
使用验证码识别技术 (由于现在的验证码千奇百怪,导致识别率太低)
-
使用cookie解决【推荐】
部分网站是动态生成的cookie则无法使用这种方法
- cookie 由服务器生成,标识一次对话的状态(登录的状态)
- 浏览器自动记录 cookie,在下一条请求时将 cookie 信息自动附加请求
# 获取所有的cookie
driver.get_cookies()
# 设置cookie
driver.add_cookies(字典)
15. PO模式
PO(Page Object),页面对象,将自动化涉及的页面或模块封装成对象,其主要有以下两个好处:
- 代码复用性
- 便于维护(脚本层和业务分类),如果元素信息变化了也不用修改脚本
PO 模式通常会将代码分为以下几个部分:
-
Base 层
存放所有页面公共方法,如定位到某个元素的方法
-
Page 层
基于页面或模块单独封装当前页面要操作的对象,是具体的业务操作,如输入用户名密码
-
Script 层
脚本层 + UnitTest,获取浏览器对象,调用 Page 层的方法进行操作
案例:使用 PO 模式测试网站登录功能
base.py
from selenium.webdriver.support.wait import WebDriverWait
class Base:
# 在获取浏览器对象后才有后续一系列操作
def __init__(self,driver):
self.driver = driver
# 切换浏览器窗口
def base_switch_win(self,index=-1):
# -1代表最新打开的窗口,0为主窗口
self.driver.switch_to.window(self.driver.window_handles[index])
# 查找元素【loc为(By.xxx,查询目标)】
def base_find(self,loc,timeout=10,frequency=0.5):
# 显式等待10秒,每隔0.5秒问询一次
return WebDriverWait(self.driver,timeout,frequency).until(lambda x:x.find_element(*loc))
# 输入方法
def base_input(self,loc,value):
ele = self.base_find(loc)
ele.clear()
ele.send_keys(value)
# 点击方法
def base_click(self,loc):
self.base_find(loc).click()
# 获取文本值
def base_text(self,loc):
ele = self.base_find(loc)
return ele.text
page_login.py
from ..base.base import Base
from selenium.webdriver.common.by import By
# 参数定位方式
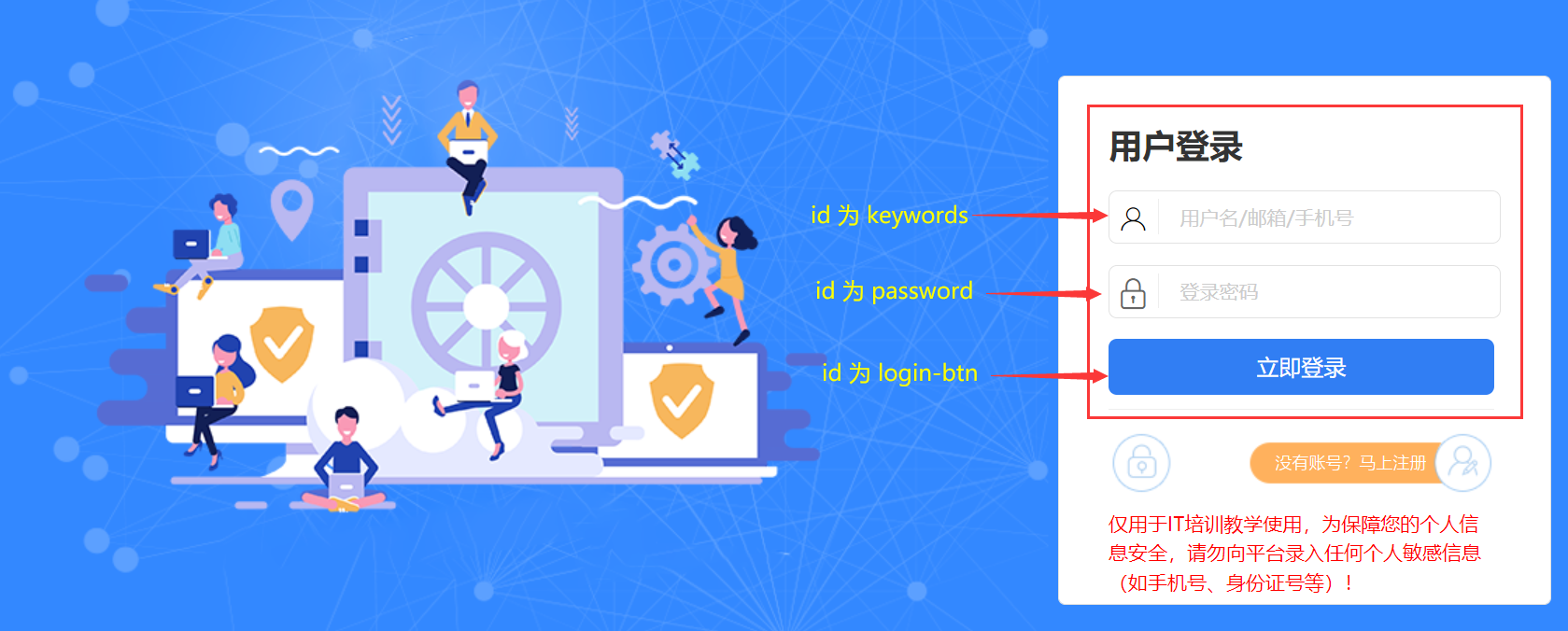
keywords = By.CSS_SELECTOR,'#keywords'
password = By.CSS_SELECTOR,'#password'
login = By.CSS_SELECTOR,'#login-btn'
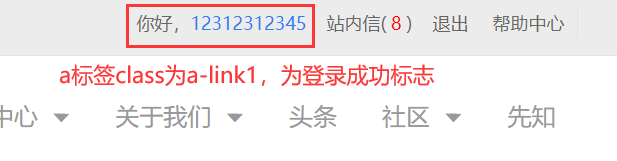
nickname = By.CSS_SELECTOR,'.a-link1'
class Page(Base):
# 切换到最新的窗口
def page_switch(self,index):
self.base_switch_win(index)
# 输入用户名
def page_insert_keywords(self,value):
self.base_input(keywords,value)
# 输入密码
def page_insert_password(self,value):
self.base_input(password, value)
# 点击登录按钮
def page_click_login(self):
self.base_click(login)
# 获取登录成功后的用户名
def page_get_nickname(self):
return self.base_text(nickname)
# 封装登录业务
def page_login(self,username,pwd):
self.page_insert_keywords(username)
self.page_insert_password(pwd)
self.page_click_login()
test01_login.py
import time
import unittest
from selenium import webdriver
from ..page.page_login import Page
from parameterized import parameterized
class TestLogin(unittest.TestCase):
# 每个方法执行前的操作
def setUp(self) -> None:
option = webdriver.ChromeOptions()
# 设置浏览器启动地址
option.binary_location = 'D:\Chrome\Google\Chrome\Application\chrome.exe'
# 获取浏览器实例对象driver
self.driver = webdriver.Chrome(options=option)
# 最大化窗口
self.driver.maximize_window()
# 打开浏览器
self.driver.get('http://xxxxx')
# 获取登录页面示例对象
self.login = Page(self.driver)
# 每个方法执行后的操作
def tearDown(self) -> None:
self.driver.quit()
# 参数化管理数据
@parameterized.expand((('123xxxxx','a1xxxxxxx'),))
def test001_login(self,keywords,password):
# 执行登录操作
self.login.page_login(keywords,password)
# 休眠一段时间等待新页面跳出
time.sleep(5)
# 切换浏览器窗口
self.login.page_switch(index=-1)
# 获取关键信息
name = self.login.page_get_nickname()
# 断言
self.assertEqual(keywords,name)















 1382
1382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









