







当前spark版本:2.4.6
1. 声明
当前内容主要为本人学习Spark的sql执行操作,实现数据获取和数据入库,当前内容参考:Spark官方文档
2. pom依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.6</version>
<scope>provided</scope>
<!-- tried to access method com.google.common.base.Stopwatch.<init>()V
from class org.apache.hadoop.mapred.FileInputFormat 使用低版本的可以解决问题 -->
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>15.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.6</version>
<scope>provided</scope>
</dependency>
<!-- <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.6</version>
<scope>provided</scope>
</dependency>
-->
<dependency>
<groupId>org.apache.iotdb</groupId>
<artifactId>spark-iotdb-connector</artifactId>
<version>0.11.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.13</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
这里注意:为2.11不是2.12,如果使用2.12就会报错:Caused by: java.lang.ClassNotFoundException: scala.Product$class
3. demo
1. 首先开启iotdb(这里使用0.11.2版本),然后再开启mysql
2.在mysql中创建一个数据库
3. 开始编写代码
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import scala.Tuple1;
/**
*
* @author hy
* @createTime 2021-08-22 10:35:10
* @description 当前内容主要为使用spark连接iotdb数据库并执行操作,并将当前的数据存放在mysql中
*
*/
public class SparkOperationIotdbTest {
public static void main(String[] args) {
// 注意出现这个错误:Caused by: java.lang.ClassNotFoundException: scala.Product$class
// 表示当前的spark的本地版本需要修改为 原版本2.12-->2.11的版本
// 之后执行就好了
SparkSession spark = SparkSession.builder().appName("Java App Test").master("local")
/* .master("spark://192.168.1.101:7077") */
.getOrCreate();
Dataset<Row> df = spark.read().format("org.apache.iotdb.spark.db")
.option("url", "jdbc:iotdb://localhost:6667/")
.option("user", "root")
.option("password", "root")
.option("sql", "select last * from root.test").load();
// 打印出当前的schame
df.printSchema();
// 显示执行的sql的数据集
df.show();
/*
* JavaRDD<Row> javaRDD = df.toJavaRDD(); javaRDD.
*/
// 然后将这个iotdb的数据写入到mysql数据库中
df.write().format("jdbc")
.option("driver","com.mysql.cj.jdbc.Driver")
.option("url", "jdbc:mysql://localhost:3306/spark_iotdb_to_mysql?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8")
.option("user", "root")
.option("password", "root")
.option("dbtable", "iotdb_data_table")
.save();
// Dataset<Row> narrowTable = Transformer.toNarrowForm(spark, df);
// narrowTable.show();
}
}
这里使用local表示使用本地执行方式,spark.read().load()表示读的操作,spark.write().save()表示写的操作,只需要填写好库即可,spark会自动创建表和需要的字段
注意:如果该表已存在,那么就会执行报错!
执行成功的结果为:
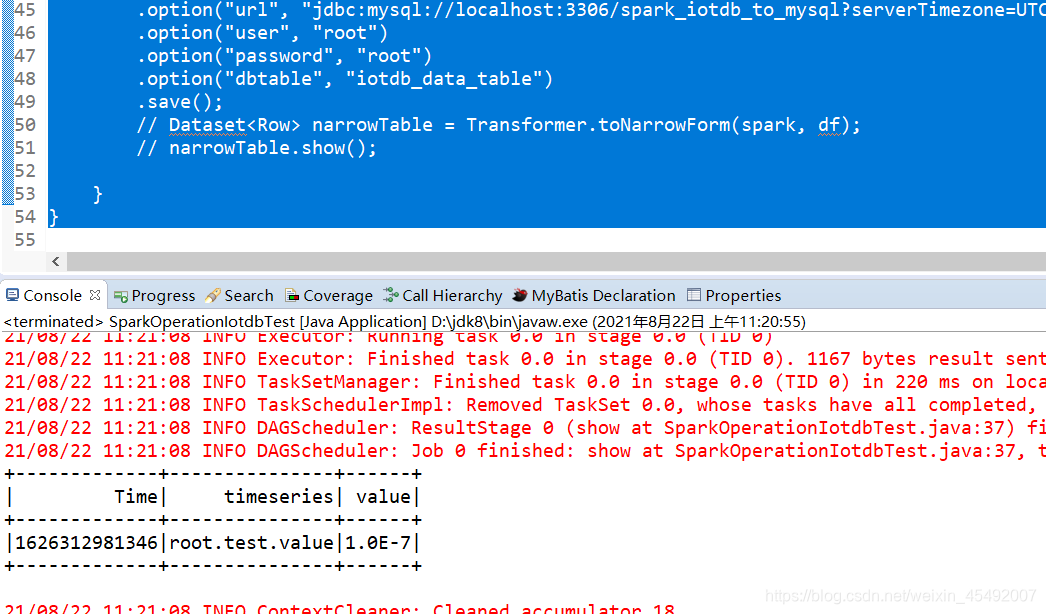
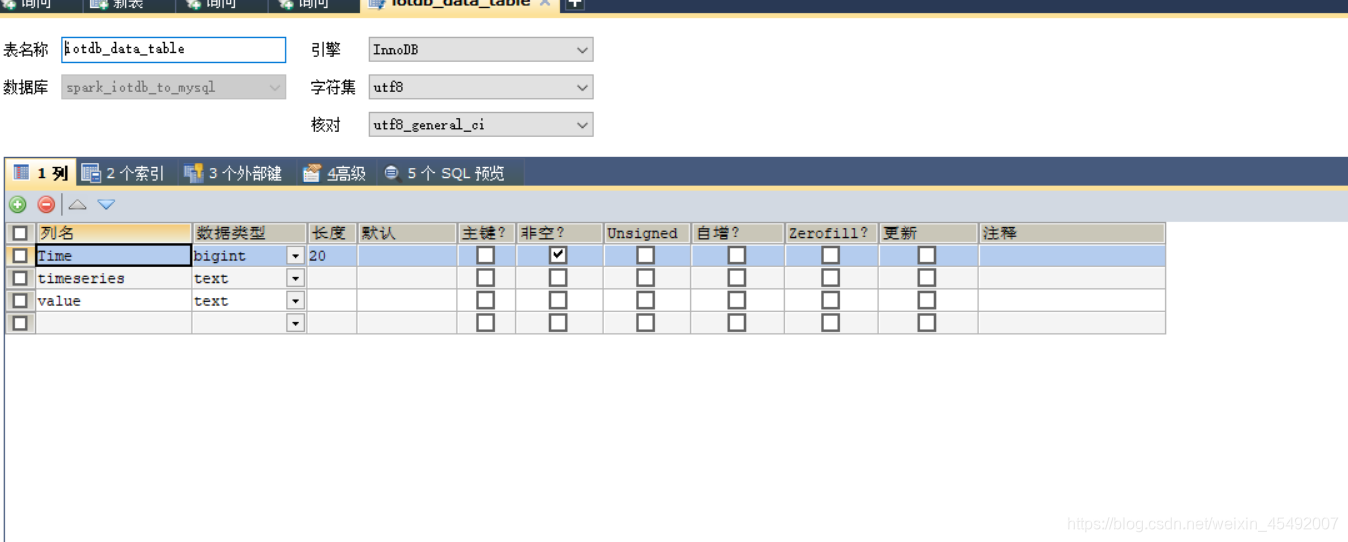
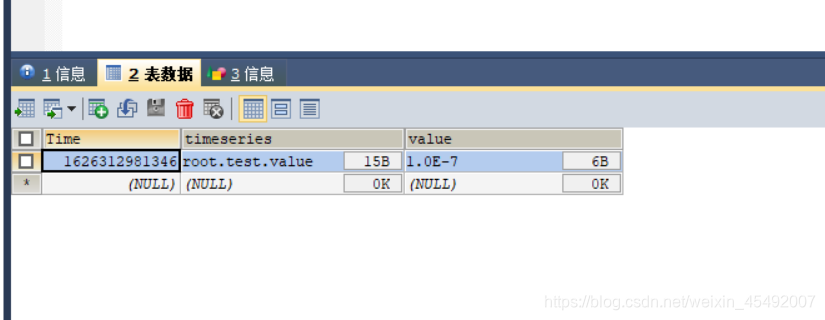
测试成功!














 2034
2034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









