









0)简述TD3
- TD3:Twin Delayed Deep Deterministic Policy Gradient ,双延迟深度确定性策略梯度。
- Deep Deterministic Policy Gradient, DDPG算法 不了解的可以看这里。
- TD3算法是一个对DDPG优化的版本,即TD3也是一种基于AC架构的面向连续动作空间的DRL算法,主要包括三个非常主要的优化。
1)Double Network
- DDPG源于DQN,是DQN解决连续控制问题的一种方法。然而DQN存在过估计问题。
(1) 什么是过估计?
- 过估计是指估计的值函数比真实的值函数大。
(2) 为什么DQN存在过估计的问题?
- 因为DQN是一种off-policy的方法,每次学习时,不是使用下一次交互的真实动作,而是使用当前认为价值最大的动作来更新目标值函数,所以会出现对Q值的过高估计。通过基于函数逼近方法的值函数更新公式可以看出:
θ t + 1 = θ t + α [ r + γ max a ′ Q ( s ′ , a ′ ; θ − ) − Q ( s , a ; θ ) ] ▽ Q ( s , a ; θ ) \theta_{t+1}=\theta_t+\alpha\left[r+\gamma \max_{a^\prime}Q(s^\prime,a^\prime;\theta^-)-Q(s,a;\theta)\right]\bigtriangledown Q(s,a;\theta) θt+1=θt+α[r+γa′maxQ(s′,a′;θ−)−Q(s,a;θ)]▽Q(s,a;θ)(3) 怎么解决这个问题?
- 为了解决过估计的问题,Hasselt提出了Double Q Learning方法,将此方法应用到DQN中,就是Double DQN,即DDQN。
- 所谓的Double Q Learning是将动作的选择和动作的评估分别用不同的值函数来实现。
动作的选择: a r g max a Q ( S t + 1 , a ; θ t ) arg\max_aQ(S_{t+1},a;\theta_t) argmaxaQ(St+1,a;θt)
动作的评估:选出 a ∗ a^* a∗后,利用 a ∗ a^* a∗处的动作值函数构造TD目标,TD目标公式为: Y t D o u b l e Q ≡ R t + 1 + γ Q ( S t + 1 , a r g max a Q ( S t + 1 , a ; θ t ) ; θ t ′ ) Y^{DoubleQ}_t\equiv R_{t+1}+\gamma Q(S_{t+1},arg\max_aQ(S_{t+1},a;\bm{\theta}_t);\bm{\theta}^\prime _t) YtDoubleQ≡Rt+1+γQ(St+1,argamaxQ(St+1,a;θt);θt′)- DDQN借鉴了Double Q-learning的思想,将选取action和估计value分别在predict network 和 target network网络上计算,有效优化了DQN的Q-Value过高估计问题。
- 而过估计这个问题也会出现在DDPG中。而要解决这个问题的思路,就在DQN的优化版本中——DDQN。
- 在TD3中,使用 两套网络(Twin) 表示不同的Q值,通过选取最小的那个作为我们更新的目标(Target Q Value),抑制持续地过高估计。 ——TD3的基本思路
※有一点需要注意,DDPG算法涉及了4个网络,所以TD3需要用到6个网络。
1. 先看DDPG的网络结构:
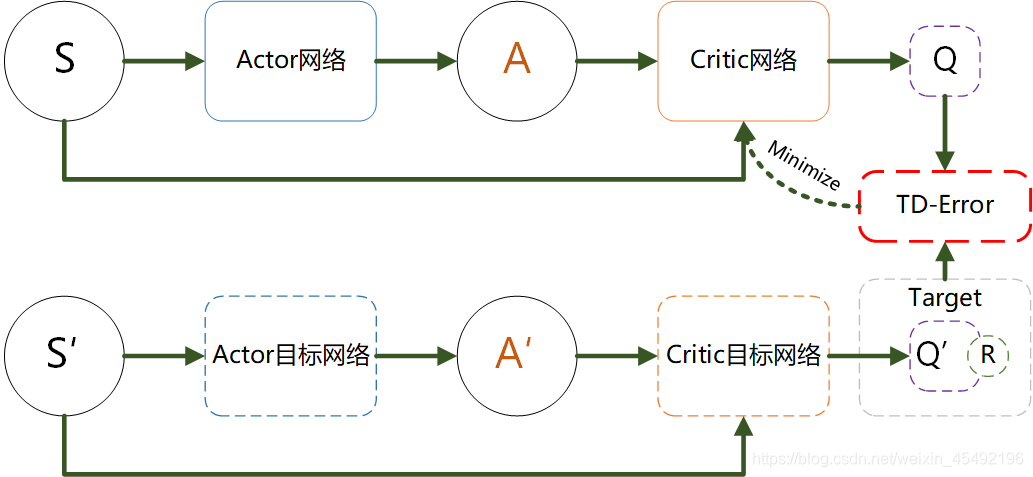
2. 可看出在DDPG中,通过Critic网络估计动作值。一个Critic的估计可能较高,那么我们再加入一个:
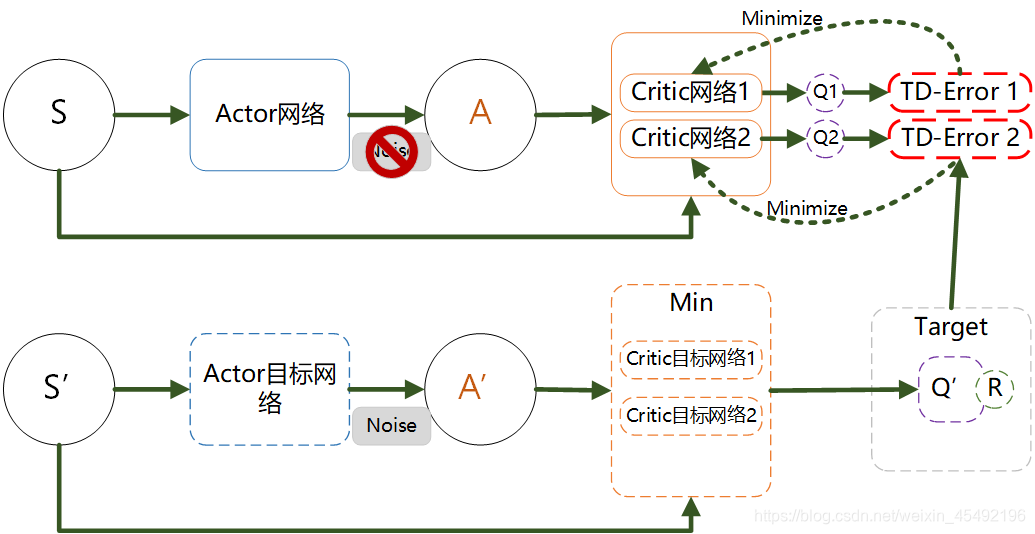
上图目标网络Q1(A')和Q2(A')取最小值min(Q1,Q2),代替了DDPG的Q'(A')计算更新目标,即Ytarget = r + gamma * min(Q1, Q2)
Ytarget将作为Q1和Q2两个网络的更新目标
Q:既然更新目标是一样的,为什么还需要两个网络?
A:虽然更新目标一样,两个网络会越来越接近实际Q值。但由于网络参数初始值不同,计算的Q值也就有所不同,那么我们可以有空间选择较小的值去估算Q值,避免过估计。
2)Delayed
- 这里说的Dalayed ,是Actor更新的Delay。 也就是说相对于Critic可以更新多次后,Actor再进行更新。
- 对于Actor来说,其实并不在乎Q值是否会被高估,其任务只是不断地做梯度上升,寻找最大的Q值。
想象一下,原本是最高点,当Actor好不容易到达最高点,Q值更新了,这里并不是最高点了。这是Actor只能转头再继续寻找新的最高点;更坏的情况是Actor被困在次高点,没能找到正确的最高点。
- 如果Q能稳定下来再学习policy,应该就会减少一些错误的更新;所以,我们可以把Critic的更新频率,调的比Actor要高一点。让critic更加确定,actor再行动。
3)Target Policy Smoothing Regularization
- 先看目标值:
y ← r + γ min i = 1 , 2 Q θ i ′ ( s ′ , a ~ ) y\leftarrow r+\gamma \min_{i=1,2}Q_{\theta^\prime_i}(s^\prime,\bm{\tilde{a}}) y←r+γi=1,2minQθi′(s′,a~) - TD3在目标网络估计Expected Return部分,对policy网络引入随机噪声,即:
a
~
←
π
ϕ
′
(
s
′
)
+
ϵ
,
ϵ
∼
clip
(
N
(
0
,
σ
~
)
,
−
c
,
c
)
\tilde{a}\leftarrow\pi_{\phi^\prime}(s^\prime)+\epsilon, \ \epsilon\thicksim \text{clip}(\mathcal{N}(0,\tilde{\sigma}), -c, c)
a~←πϕ′(s′)+ϵ, ϵ∼clip(N(0,σ~),−c,c)
以期达到对policy波动的稳定性。
算法流程

总结
TD3对DDPG的优化,主要有以下三点:
- 用类似Double DQN的方式,解决了DDPG中Critic对动作Q值过估计的问题;
- 延迟Actor更新,使Actor的训练更加稳定;
- 在Actor目标网络输出动作A’加上噪声,增加算法稳定性。
相关参考:

















 6974
6974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









