






目录
1.2.1 batch normalization (批处理归一化)
1.2.2 高分辨率分类器(high resolution classifier)
1.2.3 Convolutional With Anchor Boxes
1.2.4 细粒度特征 (Fine-Grained Features)
1.2.5 多尺度训练(multi-scale training)
一、YOLO
1.1 YOLO性能

从上表可以看出,YOLO的处理速度是可观的,但是其目标检测的准确性还是有待提高的。究其原因,主要是其bounding box的定位精度比较差。
1.2 YOLO说明
YOLO网络将分类与定位统一成一个模型,在一个网络中实现分类与定位。

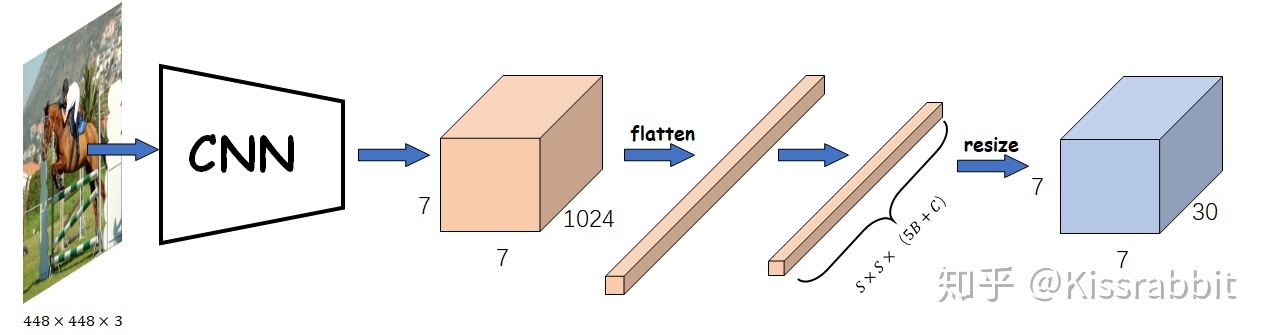
如上所示,左图为输入图像,右图为卷积网络输出的feature map。这两张图像都是的大小。这两张图的网格在位置上具有一定的一一对应的关系。对于整个YOLO网络的输出,每个网格所包含的输出如下所示:

The final prediction of the model is a 7 × 7 × 30 tensor.
滑动窗口:
从上述的过程我们可以看到,最后输出的2*2的feature map其实与最初输入的16*16*3的图像具有一定的位置关系。YOLO就是参考了这种方法。

Yolo的CNN网络将输入的图片分割成 网格,然后每个单元格负责去检测那些中心点落在该格子内的目标,如下所示,可以看到狗这个目标的中心落在左下角一个单元格内,那么该单元格负责预测这个狗。

对于每个网格产生两个预测的bounding boxes的说明:
这两个bounding boxes是由目标检测模型计算出来的框。一般来说,预测出来的(x,y,w,h)都是在0到1之间的,不同的模型对(x,y,w,h)的设置都是不同的。之所以将其限制在0到1之间,是为了模型在训练初期更加稳定,更容易收敛。
首先要清楚一点,YOLO一共有三个预测:objectness、class、bbox。其中,objectness是一个二分类,即有物体还是无物体,也就是“边界框的置信度”,对应loss函数中的那个“C”,没物体的标签显然就是0,而有物体的标签可以直接给1,也可以计算当前预测的bbox与gt之间的IoU作为有物体的标签,注意,这个IoU是objectness预测学习的标签。class就是类别预测,只有正样本处的grid cell才会被训练,也就是Pr(objectness)=1的地方,注意,这个Pr(objectness)=1就是指正样本的地方,和IoU没关,和YOLO没关,只和label有关,因为gt box的中心点落在哪个grid,哪个grid就是正样本,也就是Pr(objectness)=1。训练好的网络会正确的判断这个网格到底是不是目标的中心。也就是objectness的判断。
1.3 YOLO的网络结构分析

论文中提到,YOLO模型是基于Darknet framework进行搭建的。一般来说,常见framework比如pytorch,tensorflow等。之所以选择这个framework,最重要的原因就是其计算相对于VGG16来说更简单,计算速度也越快。YOLO的模型基于GoogLeNet mode.
从上图我们其实可以清楚的看出YOLO模型其实是有两个部分的。第一个主干网络其实就是一个分类器,bounding box 位置预测其实是通过后面两个全连接实现的。(如今的object detection 很少再用全连接去进行位置预测,一般还是卷积,但是没有看到过反卷积的)
YOLO网络模型有24个卷积层和两个全连接层。
卷积层和全连接层:
简单来说卷积层其实就是一个特征提取器,其最大的特征是保留了空间位置信息。
全连接层提取特征最大特点就是利用了全局信息,但它会损失空间信息。一般全连接层会充当网络的最后几层。
对于网络的最后一层,还出现了反卷积,反卷积在某些领域表现良好,比如图像重建等。
网络最后一层的选择还是需要根据实际情况进行验证。
池化层(Pool layer)
池化层一般是用来降低feaature map的维度。
它实际上是一种形式的降采样。有多种不同形式的非线性池化函数,而其中“最大池化(Max pooling)”是最为常见的。它是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。直觉上,这种机制能够有效地原因在于,在发现一个特征之后,它的精确位置远不及它和其他特征的相对位置的关系重要。池化层会不断地减小数据的空间大小,因此参数的数量和计算量也会下降,这在一定程度上也控制了过拟合。通常来说,CNN的卷积层之间都会周期性地插入池化层。
Example:金字塔型池化层
空间金字塔池化的思想源自 Spatial Pyramid Model,它将一个pooling变成了多个scale的pooling。用不同大小池化窗口作用于上层的卷积特征。也就是说 spatital pyramid pooling layer就是把前一卷积层的feature maps的每一个图片上进行了3个卷积操作,并把结果输出给全连接层。其中每一个pool操作可以看成是一个空间金字塔的一层。
这样做的好处是,空间金字塔池化可以把任意尺度的图像的卷积特征转化成相同维度,这不仅可以让CNN处理任意尺度的图像,还能避免cropping和warping操作,导致一些信息的丢失,具有非常重要的意义。这对于目标检测以及分类等都具有重要意义。利用这种池化层可以有效的减少模型训练过程中的操作复杂度。

的卷积层:
对于一个通道的
但是对于多个通道的卷积:
相当于
作用:
1.降维 (这在GoogLeNet 中有所表现)。运用
2. 跨通道信息交互(channal)
例子:使用1x1卷积核,实现降维和升维的操作其实就是channel间信息的线性组合变化,3x3,64channels的卷积核后面添加一个1x1,28channels的卷积核,就变成了3x3,28channels的卷积核,原来的64个channels就可以理解为跨通道线性组合变成了28channels,这就是通道间的信息交互。



YOLO的缺点:
1.每个网格只能预测一个类别。如果有两个物体的中心都在同一个网格上时,这个网格也只能预测一个物体。
2.输入图像的分辨率收到限制448*448.
二、YOLO2
1.1 YOLO2性能分析
从上图我们可以看到,相较于YOLO1,YOLO2的性能得到了大幅度的提升。

上图展示的是YOLO2相对于YOLO的改进部分。
1.2 YOLO2说明
相较于YOLO,YOLO2模型多了许多细节部分。
1.2.1 batch normalization (批处理归一化)
在模型训练时,在应用激活函数之前,先对一个层的输出进行归一化,将所有批数据强制在统一的数据分布下,然后再将其输入到下一层,使整个神经网络在各层的中间输出的数值更稳定。从而使深层神经网络更容易收敛而且降低模型过拟合的风险。应用批处理归一化使得YOLO的性能提高了2%。
如今,除了批处理归一化外,还存在其他各种归一化处理的方法。
1.2.2 高分辨率分类器(high resolution classifier)
目前大部分的检测模型都会在先在ImageNet分类数据集上预训练模型的主体部分(CNN特征提取器),ImageNet分类模型基本采用大小为 224*224 的图片作为输入,分辨率相对较低,不利于检测模型。
YOLOv1在采用 224*224 分类模型预训练后,将分辨率增加至 448*448 ,并使用这个较高分辨率在检测数据集上finetune。但是直接切换分辨率,检测模型可能难以快速适应高分辨率。
因此,YOLOv2增加了在ImageNet数据集上使用 448*448 输入来finetune分类网络这一中间过程(10 epochs),这可以使得模型在检测数据集上finetune之前已经适用高分辨率输入。使用高分辨率分类器后,YOLOv2的mAP提升了约4%。
1.2.3 Convolutional With Anchor Boxes
在YOLO中,每个网格预测两个bounding boxes,这两个bounding boxes的大小,形状是模型自己计算处理出来的,但是这就限制了每个网格能够预测对象的数目。如果有两个目标的中心都在一个网格上,YOLO也只能预测一个。但是在YOLO2中运用了锚框(anchor boxes)的思想。

首先,锚框的大小,形状是人为设定的。在YOLO2中,通过聚类分析得到了锚框的数量,大小,形状。具体可参考:锚框:Anchor box综述 - 知乎 (zhihu.com)
首先,对每一个边界框,YOLO仍旧去学习中心点偏移量和
。我们知道,这个中心点偏移量是介于0到1范围之间的数,在YOLOv1时,作者没有在意这一点,直接使用线性函数输出,这显然是有问题的,在训练初期,模型很有可能会输出数值极大的中心点偏移量,导致训练不稳定甚至发散。于是,作者使用sigmoid函数使得网络对偏移量的预测是处在0到1范围中。我们的YOLOv1+正是借鉴了这一点。
其中(x,y)是box的中心坐标,是预测得到的参数。
其次,对每一个边界框,由于有了边界框的尺寸先验信息,故网络不必再去学习整个边界框的宽高了。假设某个先验框的宽和高分别为和
,网络输出宽高的偏移量为
和
。
我们可以得到的预测输出:

其中是在通过sigmoid函数的操作。
是指网格左上角处相对于整张图像的坐标。

1.2.4 细粒度特征 (Fine-Grained Features)
YOLOv2的输入图片大小为 416*416 ,经过5次maxpooling之后得到13*13大小的特征图,并以此特征图采用卷积做预测。 13*13 大小的特征图对检测大物体是足够了,但是对于小物体还需要更精细的特征图(Fine-Grained Features)。因此SSD使用了多尺度的特征图来分别检测不同大小的物体,前面更精细的特征图可以用来预测小物体。YOLOv2提出了一种passthrough层来利用更精细的特征图。YOLOv2所利用的Fine-Grained Features是 26*26大小的特征图(最后一个maxpooling层的输入)

YOLOv2所利用的Fine-Grained Features是 26*26 大小的特征图(最后一个maxpooling层的输入),对于Darknet-19模型来说就是大小为 的特征图。passthrough层与ResNet网络的shortcut类似,以前面更高分辨率的特征图为输入,然后将其连接到后面的低分辨率特征图上。前面的特征图维度是后面的特征图的2倍,passthrough层抽取前面层的每个
的局部区域,然后将其转化为channel维度,对于
的特征图,经passthrough层处理之后就变成了
的新特征图(特征图大小降低4倍,而channles增加4倍,图6为一个实例),这样就可以与后面的
特征图连接在一起形成
大小的特征图,然后在此特征图基础上卷积做预测。
1.2.5 多尺度训练(multi-scale training)
由于YOLOv2模型中只有卷积层和池化层(全卷积模型),所以YOLOv2的输入可以不限于 416*4146 大小的图片。为了增强模型的鲁棒性,YOLOv2采用了多尺度输入训练策略,具体来说就是在训练过程中每间隔一定的iterations之后改变模型的输入图片大小。由于YOLOv2的下采样总步长为32,输入图片大小选择一系列为32倍数的值: ,输入图片最小为
,此时对应的特征图大小为
(不是奇数了,确实有点尴尬),而输入图片最大为
,对应的特征图大小为
。在训练过程,每隔10个iterations随机选择一种输入图片大小,然后只需要修改对最后检测层的处理就可以重新训练。 (是否可以用金字塔型池化层来替代这种方式的多尺度训练)。
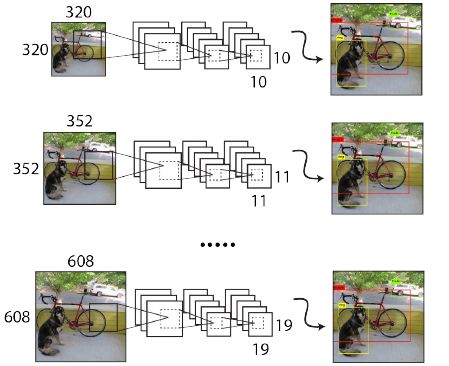
多尺度训练:对于不同尺度的输入图像,如果我们resize其分辨率,可能会导致其特征发生变化,影响最终的结果。如果对模型进行了多尺度训练则可以大大增强其鲁棒性。
图像增强(Image Augmentation):在训练过程中,YOLO2使用标准的数据增强技巧,包括随机作物、旋转、色调、饱和度和曝光转移。参考链接:Tensorflow实现图像数据增强(Data Augmentation) - Geeksongs - 博客园 (cnblogs.com)
1.2.6 YOLO2训练
YOLOv2的训练主要包括三个阶段。第一阶段就是先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为 ,共训练160个epochs。然后第二阶段将网络的输入调整为
,继续在ImageNet数据集上finetune分类模型,训练10个epochs,此时分类模型的top-1准确度为76.5%,而top-5准确度为93.3%。第三个阶段就是修改Darknet-19分类模型为检测模型,并在检测数据集上继续finetune网络。网络修改包括(网路结构可视化):移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个
卷积层,同时增加了一个passthrough层,最后使用
卷积层输出预测结果,输出的channels数为:
,和训练采用的数据集有关系。由于anchors数为5,对于VOC数据集输出的channels数就是125,而对于COCO数据集则为425。这里以VOC数据集为例,最终的预测矩阵为 T (shape为
),可以先将其reshape为
,其中
为边界框的位置和大小
,
为边界框的置信度,而
为类别预测值


YOLO2的loss函数相对于YOLO1也发生了很大的变化:

太过复杂,不解释。参考解释:目标检测|YOLOv2原理与实现(附YOLOv3) - 知乎 (zhihu.com)














 1741
1741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









