






 本文详细介绍了孪生神经网络(Siamese Network)的概念,包括其权重共享结构、在比较任务中的应用(如签名验证和语义相似度计算),以及Contrastive Loss函数的使用。通过Fashion MNIST实例演示了如何构建和训练此类网络。
本文详细介绍了孪生神经网络(Siamese Network)的概念,包括其权重共享结构、在比较任务中的应用(如签名验证和语义相似度计算),以及Contrastive Loss函数的使用。通过Fashion MNIST实例演示了如何构建和训练此类网络。
一、孪生神经网络(Siamese network)
1.1 网络介绍
孪生神经网络简单的来说就是权重共享的网络,如下所示:
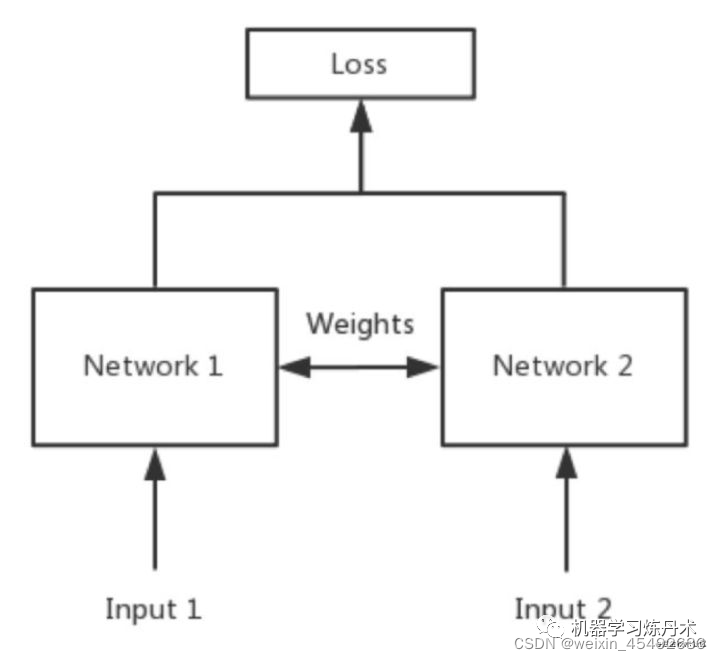
从上图我们看到,Network1和Network2共享权重,实际上在操作中这就是一个网络。孪生网络是一种模型,图中的Network可以是CNN,也可是ResNet 等等其他网络。Network1和Network2可以是同一种网络,这时候在实际操作中就相当于是一个网络,同时Network1和Network2也可以是不同的网络,也就是说Network1可以是CNN而同时Network2可以是ResNet,这种时候网络叫做伪孪生神经网络。
孪生神经网络和伪孪生神经网络分别适用于什么场景呢?
先上结论:孪生神经网络用于处理两个输入"比较类似"的情况。伪孪生神经网络适用于处理两个输入"有一定差别"的情况。比如,我们要计算两个句子或者词汇的语义相似度,使用siamese network比较适合;如果验证标题与正文的描述是否一致(标题和正文长度差别很大),或者文字是否描述了一幅图片(一个是图片,一个是文字),就应该使用pseudo-siamese network。也就是说,要根据具体的应用,判断应该使用哪一种结构,哪一种Loss。
一般网络是一个input,然后产生一个pred,将这个pred和ground truth进行比较,在返回来修正weigth。而孪生网络需要两个input,得到两个pred,然后产生一个loss。
一般来说,孪生网络是衡量两个输入的关系,也就是两个样本相似还是不相似。
举例:
有这样的一个任务,在NIPS上,在1993年发表了文章《Signature Verification using a ‘Siamese’ Time Delay Neural Network》用于美国支票上的签名验证,检验支票上的签名和银行预留的签名是否一致。当时论文中就已经用卷积网络来做验证了...当时我还没出生。
之后,2010年Hinton在ICML上发表了《Rectified Linear Units Improve Restricted Boltzmann Machines》,用来做人脸验证,效果很好。输入就是两个人脸,输出就是same or different。

还有基于Siamese网络的视觉跟踪算法,比如:Fully-convolutional siamese networks for object tracking
其中,还有人曾经使用三个输入的网络。
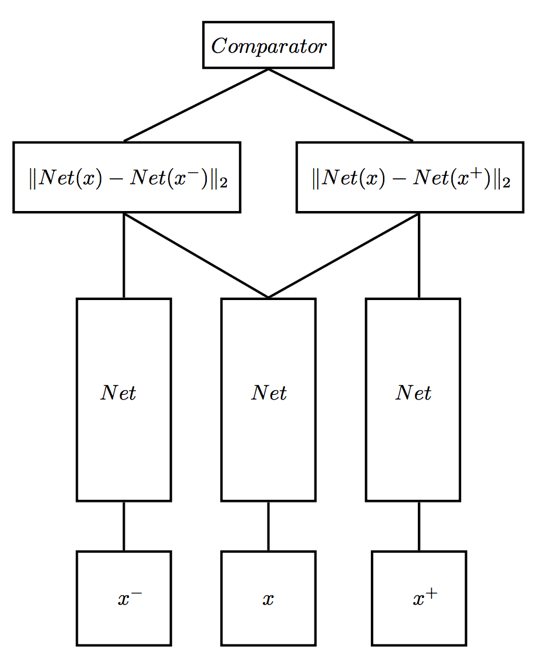
这个网络中,属于正样本,就是跟
相近的样本 , 而
。
论文是《Deep metric learning using Triplet network》,输入是三个,一个正例+两个负例,或者一个负例+两个正例,训练的目标是让相同类别间的距离尽可能的小,让不同类别间的距离尽可能的大。
讨论一下孪生神经网络应用场景。
- 用于处理类别多(或类别数量不确定)、每一类样本少的分类任务。
- 一般碰到的分类问题都是类别较少,每一类样本较多的情况(如ImageNet的图像分类任务)
1.2 损失函数
在孪生神经网络中,一般使用的损失函数为Contrastive Loss.
其定义为:
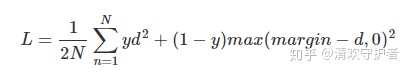
对这个公式进行分析:

网络的两个输入x_1和x_2通过网络G_w后获得两个向量和
,计算这两个向量之间的欧式距离。然后是关于输入的样本对贴标签,如果输入样本对为正样本对,也就是二者是相似的话,那么Y=0,如果输入的样本对是负样本对,也就是二者区别很大的话,那么Y=1。
则如果是正样本对,则为
如果是负样本,则为
我们训练loss函数的目的是当输出满足要求的话,那么loss函数的值很低。但是如果是负样本的话,二者区别越大,输出的loss函数就越大,这显然不符合我们之前的假设。增加一个margin,当作最大的距离。如果pred1和pred2的距离大于margin,那么就认为这两个样本距离足够大,就当其的损失为0。所以写的方法就是:
在论文中,和
都设置为0.5
因此上述的Loss函数可以变为
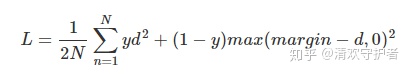
N应该是表示输入数据的数量。
1.3 代码实现
简单来说,孪生网络就是一次学习两张图片(两张图片是一类或者不是一类),从中发现它们的相似或者不同,等网络学习完成之后,再给网络输入两张图片即可知道它们是否是一类。
参考:孪生网络入门(下) Siamese Net分类服装MNIST数据集(pytorch) - 云+社区 - 腾讯云 (tencent.com)
(34条消息) 孪生网络实验记录_狂小p只和傻子玩的博客-CSDN博客
代码实现包括一下几个步骤:
- 1 准备数据
- 2 构建Dataset和可视化
- 3 构建模型
- 4 训练
首先是准备数据:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset,DataLoader
from sklearn.model_selection import train_test_split
device = 'cuda' if torch.cuda.is_available() else 'cpu'data_train = pd.read_csv('../input/fashion-mnist_train.csv')
data_train.head() 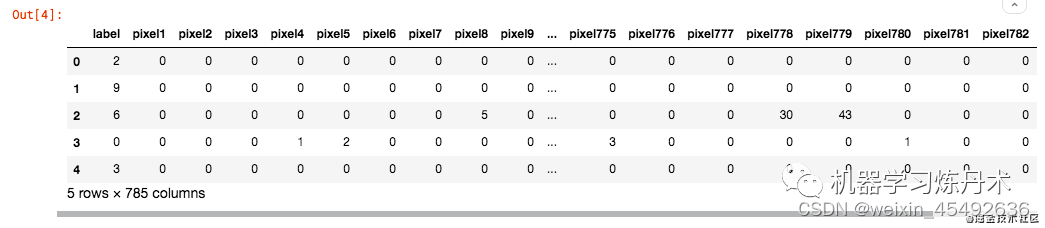
这个数据文件是csv格式,第一列是类别,之后的784列其实好似28x28的像素值。
划分训练集和验证集,然后把数据转换成28x28的图片
X_full = data_train.iloc[:,1:]
y_full = data_train.iloc[:,:1]
x_train, x_test, y_train, y_test = train_test_split(X_full, y_full, test_size = 0.05)
x_train = x_train.values.reshape(-1, 28, 28, 1).astype('float32') / 255.
x_test = x_test.values.reshape(-1, 28, 28, 1).astype('float32') / 255.
y_train.label.unique()
>>> array([8, 9, 7, 6, 4, 2, 3, 1, 5, 0])可以看到这个Fashion MNIST数据集中也是跟MNIST类似,划分了10个不同的类别。
- 0 T-shirt/top
- 1 Trouser
- 2 Pullover
- 3 Dress
- 4 Coat
- 5 Sandal
- 6 Shirt
- 7 Sneaker
- 8 Bag
- 9 Ankle boot
接下来就是数据可视化和数据准备
class mydataset(Dataset):
def __init__(self,x_data,y_data):
self.x_data = x_data
self.y_data = y_data.label.values
def __len__(self):
return len(self.x_data)
def __getitem__(self,idx):
img1 = self.x_data[idx]
y1 = self.y_data[idx]
if np.random.rand() < 0.5:
idx2 = np.random.choice(np.arange(len(self.y_data))[self.y_data==y1],1)
else:
idx2 = np.random.choice(np.arange(len(self.y_data))[self.y_data!=y1],1)
img2 = self.x_data[idx2[0]]
y2 = self.y_data[idx2[0]]
label = 0 if y1==y2 else 1
return img1,img2,label上面的逻辑就是,给定一个idx,然后我们先判断,这个数据是找两个同类别的图片还是两个不同类别的图片。50%的概率选择两个同类别的图片,然后最后输出的时候,输出这两个图片,然后再输出一个label,这个label为0的时候表示两个图片的类别是相同的,1表示两个图片的类别是不同的。这样就可以进行模型训练和损失函数的计算了。
仔细研究上面的代码,它的返回值两张照片和一个标签。这一步应该是对数据集进行处理,生成图像对,以及图像对的标签,也就是说这一步的操作只是针对于孪生神经网络。
下面一段的代码就是对一个batch的数据进行一个可视化:
for idx,(img1,img2,target) in enumerate(train_dataloader):
fig, axs = plt.subplots(2, img1.shape[0], figsize = (12, 6))
for idx,(ax1,ax2) in enumerate(axs.T):
ax1.imshow(img1[idx,:,:,0].numpy(),cmap='gray')
ax1.set_title('image A')
ax2.imshow(img2[idx,:,:,0].numpy(),cmap='gray')
ax2.set_title('{}'.format('same' if target[idx]==0 else 'different'))
break
接下来就是构建模型
def __init__(self,z_dimensions=2):
super(siamese,self).__init__()
self.feature_net = nn.Sequential(
nn.Conv2d(1,4,kernel_size=3,padding=1,stride=1),
nn.ReLU(inplace=True),
nn.BatchNorm2d(4),
nn.Conv2d(4,4,kernel_size=3,padding=1,stride=1),
nn.ReLU(inplace=True),
nn.BatchNorm2d(4),
nn.MaxPool2d(2),
nn.Conv2d(4,8,kernel_size=3,padding=1,stride=1),
nn.ReLU(inplace=True),
nn.BatchNorm2d(8),
nn.Conv2d(8,8,kernel_size=3,padding=1,stride=1),
nn.ReLU(inplace=True),
nn.BatchNorm2d(8),
nn.MaxPool2d(2),
nn.Conv2d(8,1,kernel_size=3,padding=1,stride=1),
nn.ReLU(inplace=True)
)
self.linear = nn.Linear(49,z_dimensions)
def forward(self,x):
x = self.feature_net(x)
x = x.view(x.shape[0],-1)
x = self.linear(x)
return x一个非常简单的卷积网络,输出的向量的维度就是z-dimensions的大小
这个卷积网络5个卷积层。
BatchNorm2d:在卷积神经网络的卷积层之后总会添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定。
MaxPool2d:减小卷积层参数误差造成估计均值的偏移的误差,更多的保留纹理信息
然后就是构造损失函数:
def contrastive_loss(pred1,pred2,target):
MARGIN = 2
euclidean_dis = F.pairwise_distance(pred1,pred2)
target = target.view(-1)
loss = (1-target)*torch.pow(euclidean_dis,2) + target * torch.pow(torch.clamp(MARGIN-euclidean_dis,min=0),2)
return loss之后就是训练模型
model = siamese(z_dimensions=8).to(device)
# model.load_state_dict(torch.load('../working/saimese.pth'))
optimizor = torch.optim.Adam(model.parameters(),lr=0.001)for e in range(10):
history = []
for idx,(img1,img2,target) in enumerate(train_dataloader):
img1 = img1.to(device)
img2 = img2.to(device)
target = target.to(device)
pred1 = model(img1)
pred2 = model(img2)
loss = contrastive_loss(pred1,pred2,target)
optimizor.zero_grad()
loss.backward()
optimizor.step()
loss = loss.detach().cpu().numpy()
history.append(loss)
train_loss = np.mean(history)
history = []
with torch.no_grad():
for idx,(img1,img2,target) in enumerate(val_dataloader):
img1 = img1.to(device)
img2 = img2.to(device)
target = target.to(device)
pred1 = model(img1)
pred2 = model(img2)
loss = contrastive_loss(pred1,pred2,target)
loss = loss.detach().cpu().numpy()
history.append(loss)
val_loss = np.mean(history)
print(f'train_loss:{train_loss},val_loss:{val_loss}')这里为了加快训练,我把batch-size增加到了128个,其他的并没有改变:

接下来就是记得保存模型
torch.save(model.state_dict(),'saimese.pth')差不多是这个样子,然后看一看验证集的可视化效果,这里使用的是t-sne高位特征可视化的方法,其内核是PCA降维:
from sklearn import manifold
'''X是特征,不包含target;X_tsne是已经降维之后的特征'''
tsne = manifold.TSNE(n_components=2, init='pca', random_state=501)
X_tsne = tsne.fit_transform(X)
print("Org data dimension is {}. \
Embedded data dimension is {}".format(X.shape[-1], X_tsne.shape[-1]))
x_min, x_max = X_tsne.min(0), X_tsne.max(0)
X_norm = (X_tsne - x_min) / (x_max - x_min) # 归一化
plt.figure(figsize=(8, 8))
for i in range(10):
plt.scatter(X_norm[y==i][:,0],X_norm[y==i][:,1],alpha=0.3,label=f'{i}')
plt.legend()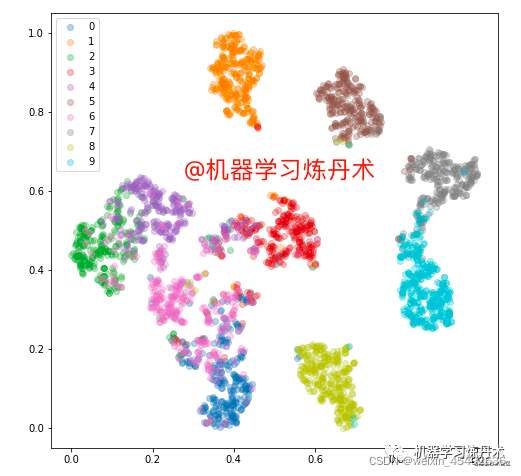
这里的可视化是将高维的特征采用PCA之后降维成像。

















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









