







机器学习任务攻略
对于机器学习过程中,存在loss很大的问题,一般处于两种情况:
- model 问题
- optimization 问题(优化器问题)
训练过程失败原因(1)—— optimization失败,gradient太慢了
- 模型的问题,梯度接近于0
- 卡在local minima 局部最小值
- saddle point 鞍点,还可以进行梯度最小值寻找
解决方式,对于局部最小值无解但是对于鞍点的解决方式可以使用泰勒展开式进行解决:
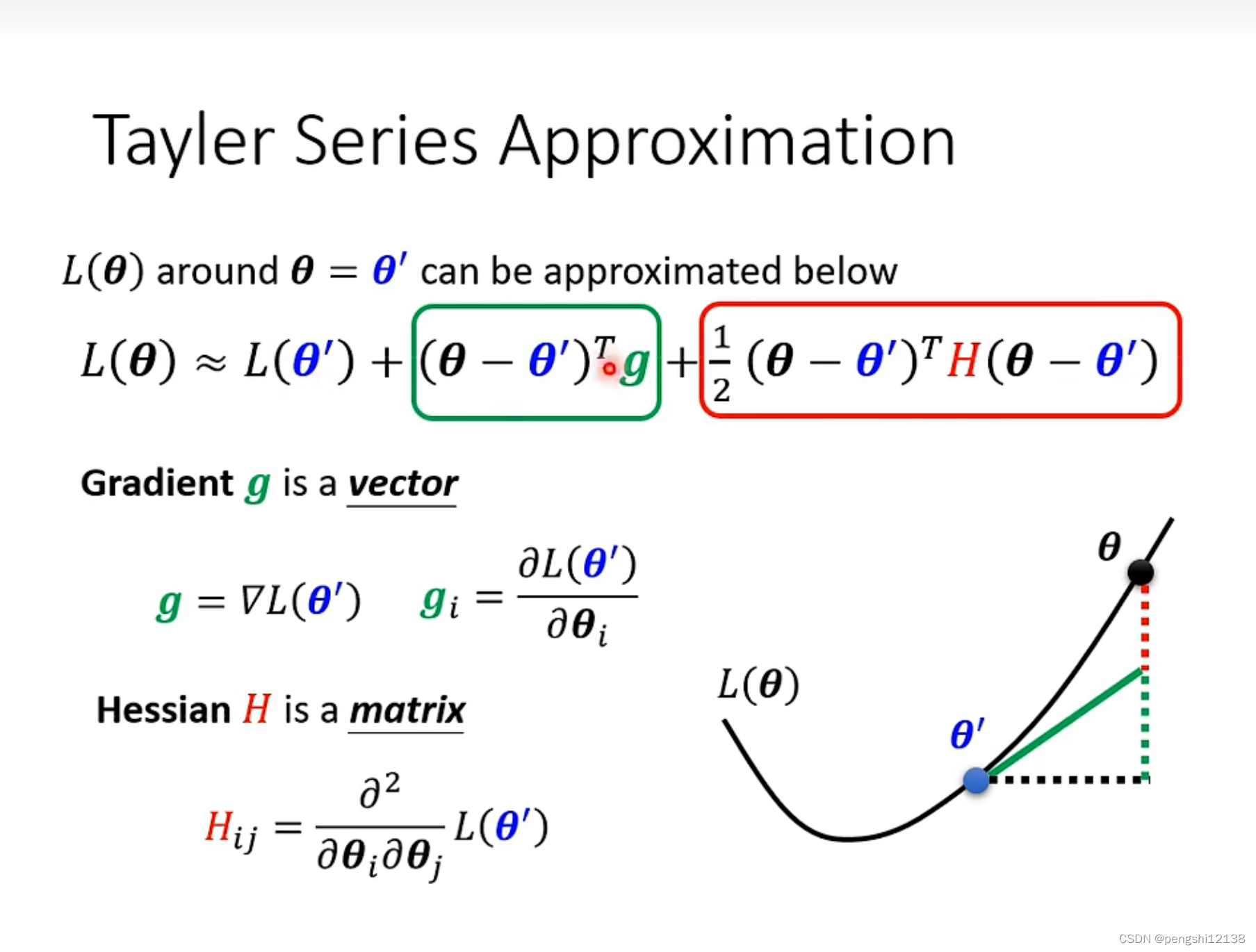

H矩阵是由二次微分的导数组成,eigen value表示特征值

从负数的特征值出发,寻找出对应的特征向量,更新参数就可以了,肯定会找到比鞍点小的最小值。
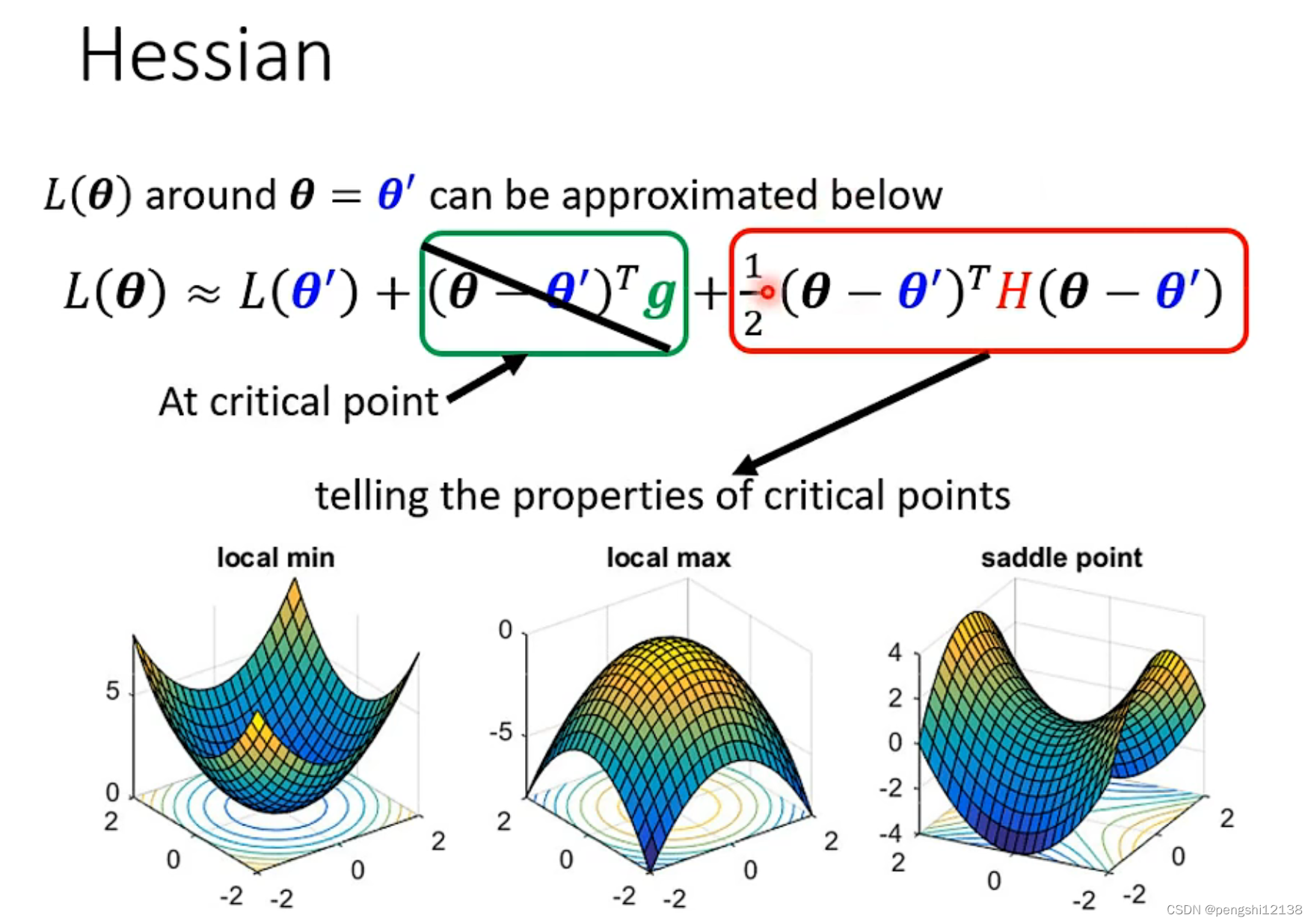
拓展知识:海森矩阵
就是收集函数的二次微分作为一个矩阵,而对于矩阵求解特征值可以得出结论:
- 所有特征值是正的,则是局部最小值
- 所有特征值是负的,则是局部最大值
- 特征值有正有负的,则是鞍点
训练过程失败原因(2)——batch和动量
batch是训练一次的数据量,epoch表示遍历所有数据集的次数。
对于batchsize大小要看gpu的显存大小,进行并行运算,所以需要采用合适的batchsize大小,同时batchsize过大,准确率会变低,主要是优化器的原因。
下面是一般的梯度下降方式:
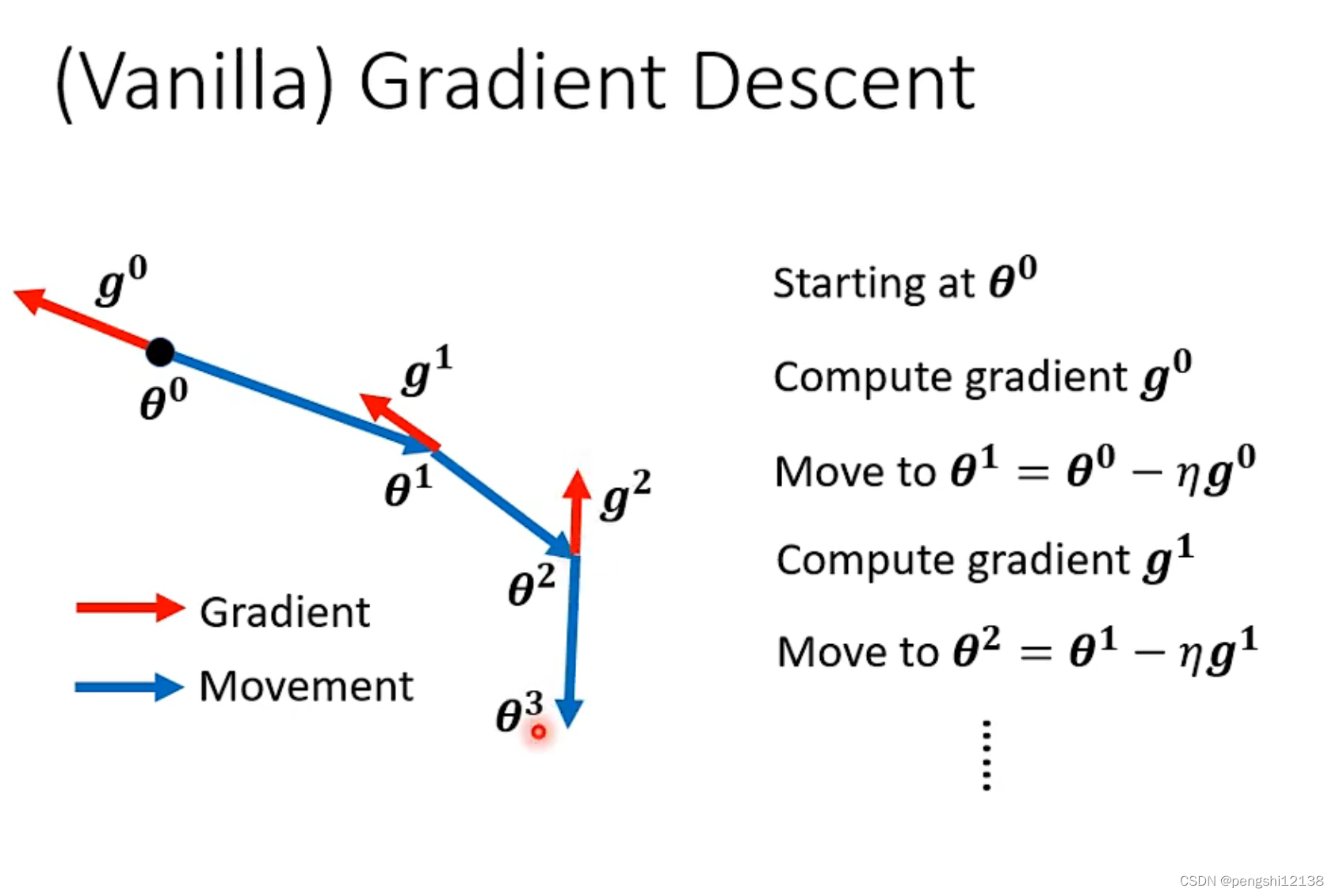
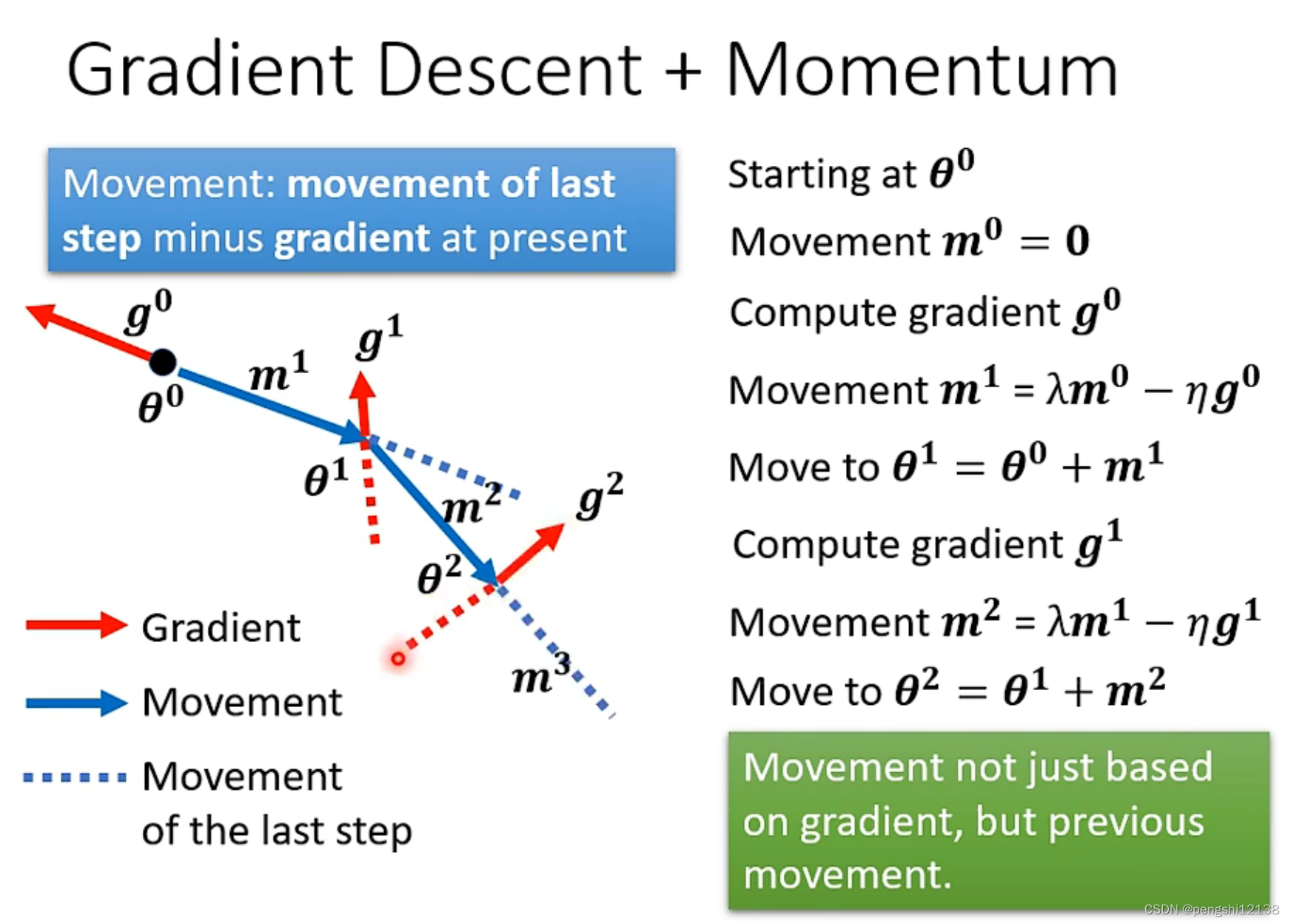
下面试添加了动量的梯度下降方式:
沿着原方向的动量加上梯度下降的方向结合进行计算
训练过程失败原因(3)——自动调整学习率
可能存在loss无法下降,因为是gradient过大,导致下降不到最低点,导致不断的震荡。其中自动调整学习率的方式如下:
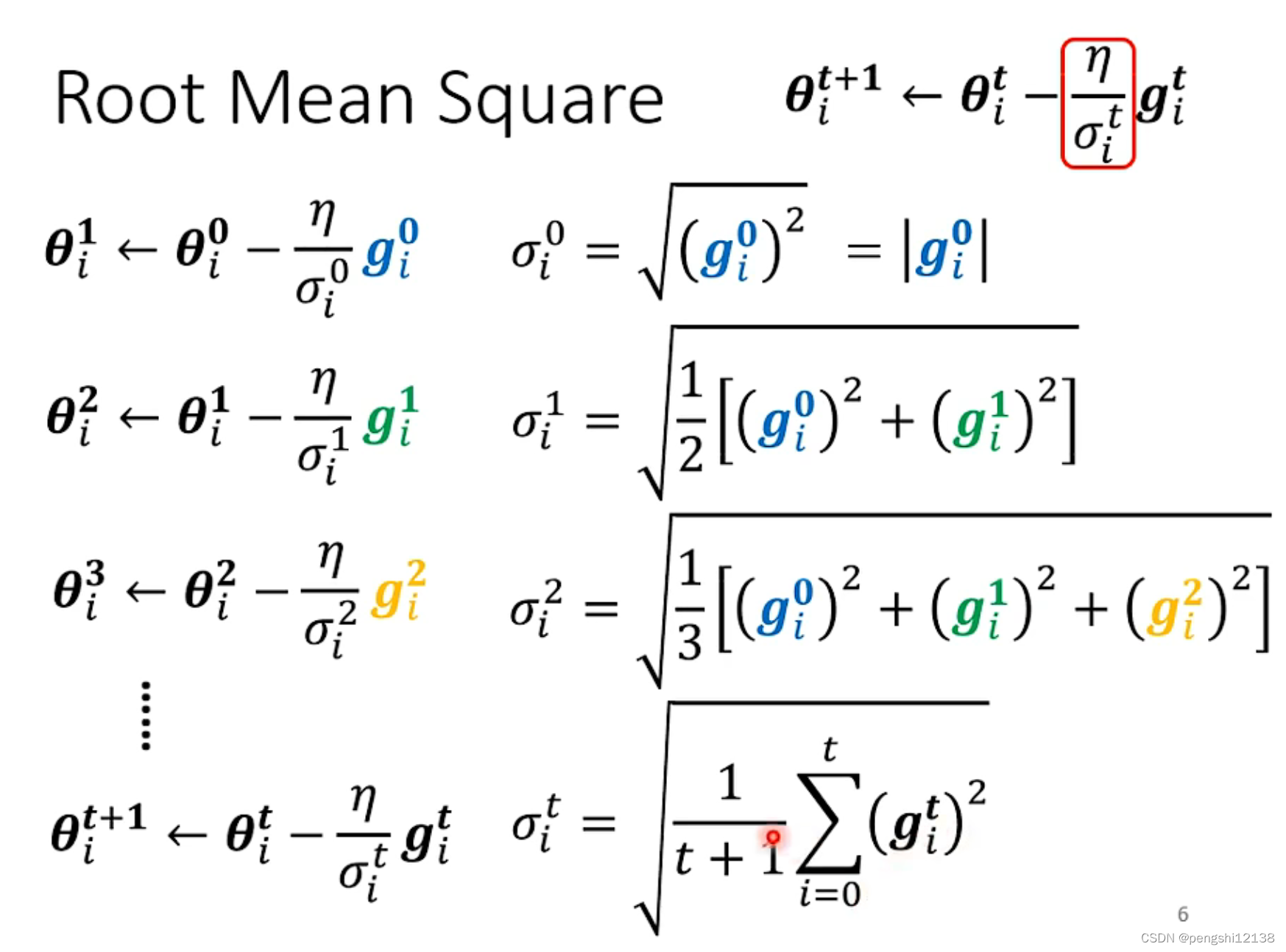
RMSprop 的学习率调整方式:
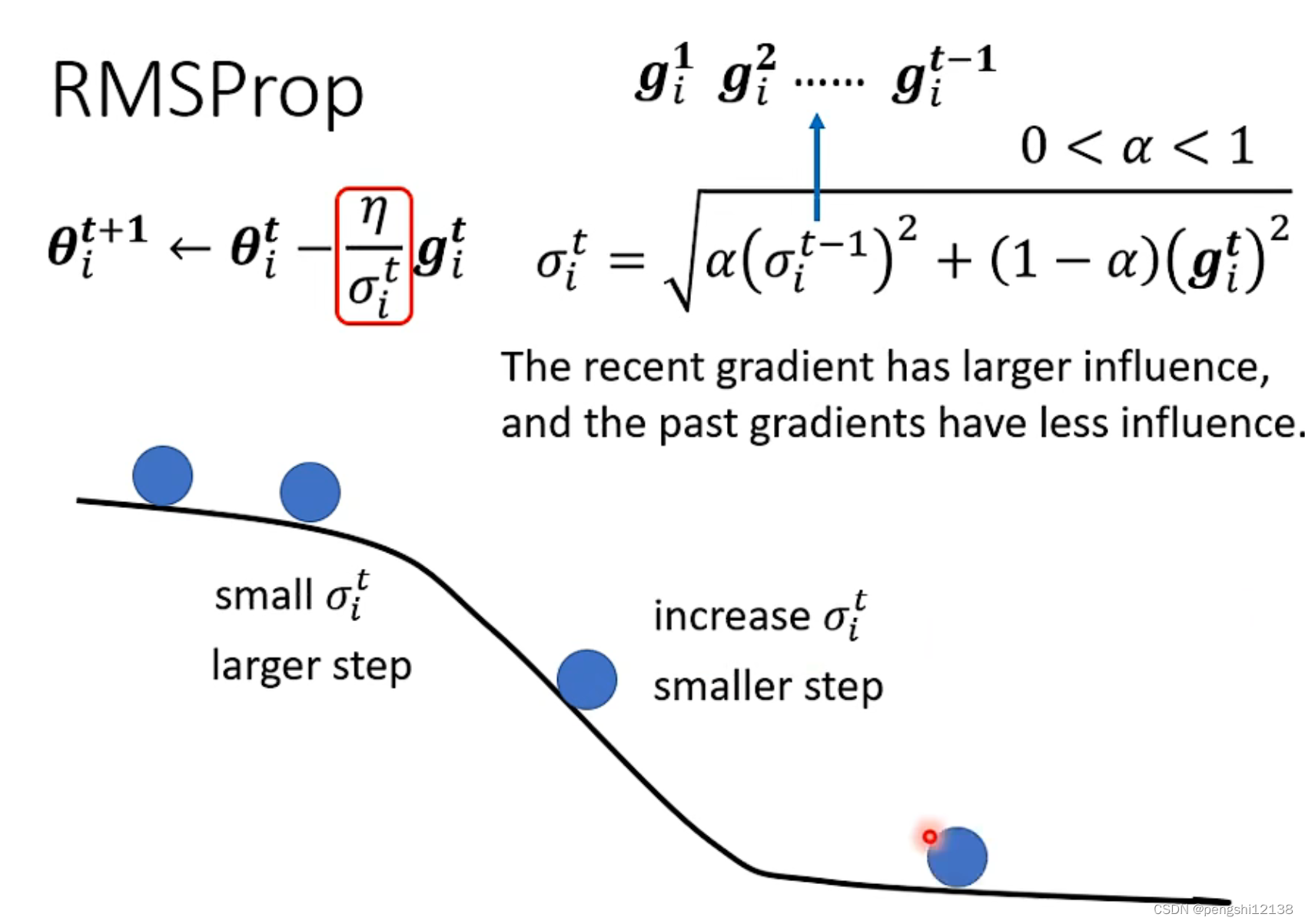
而目前所使用的Adam优化器方式采用的就是如上的方式:

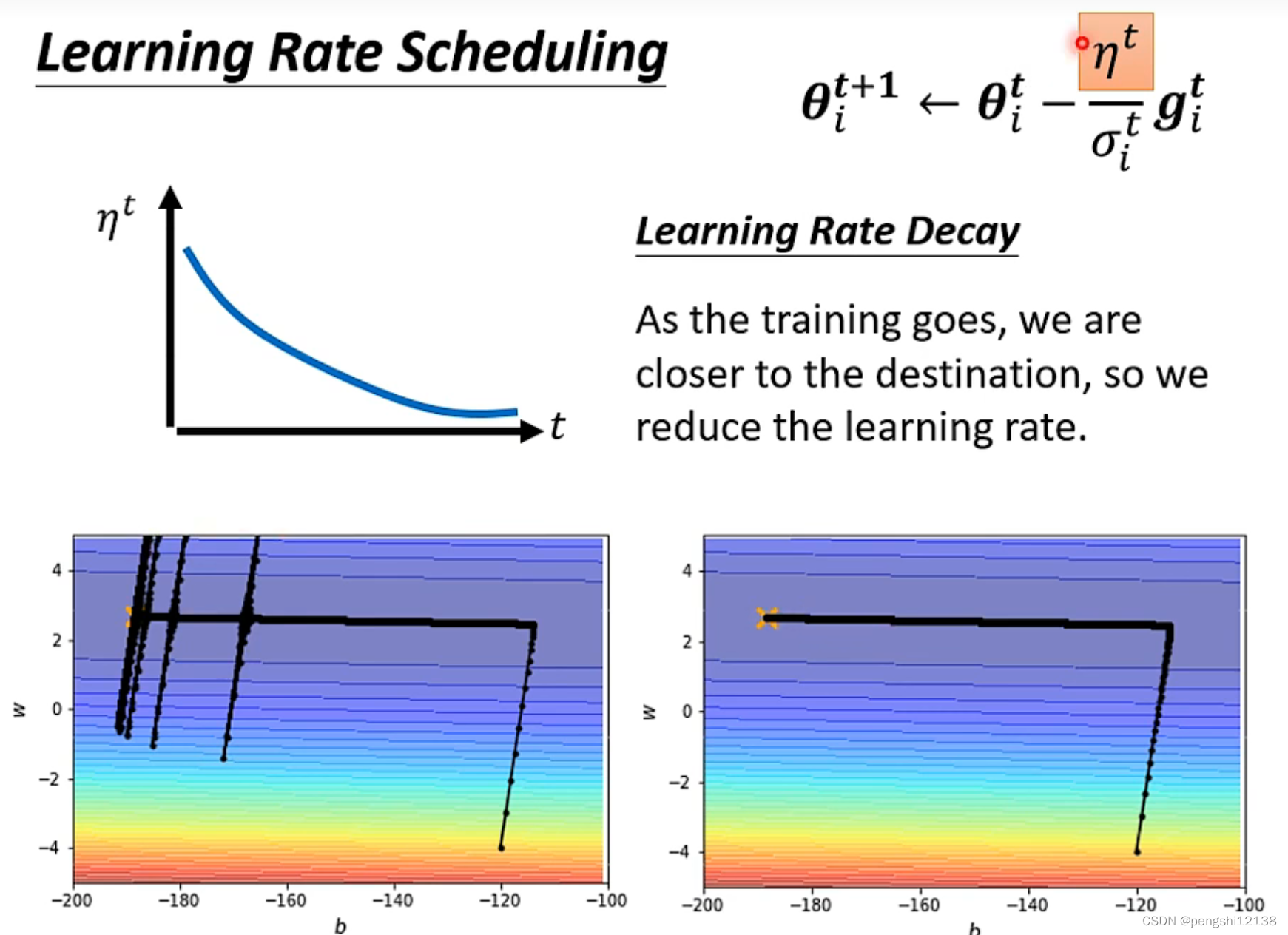
可能会存在梯度爆炸因为存在累计前面的梯度导致某个方向的梯度爆炸,解决的方式就是用时间变化的方式使得学习率下降
同时还有随着时间的warm up方式,先变大后边小,主要是看网络情况
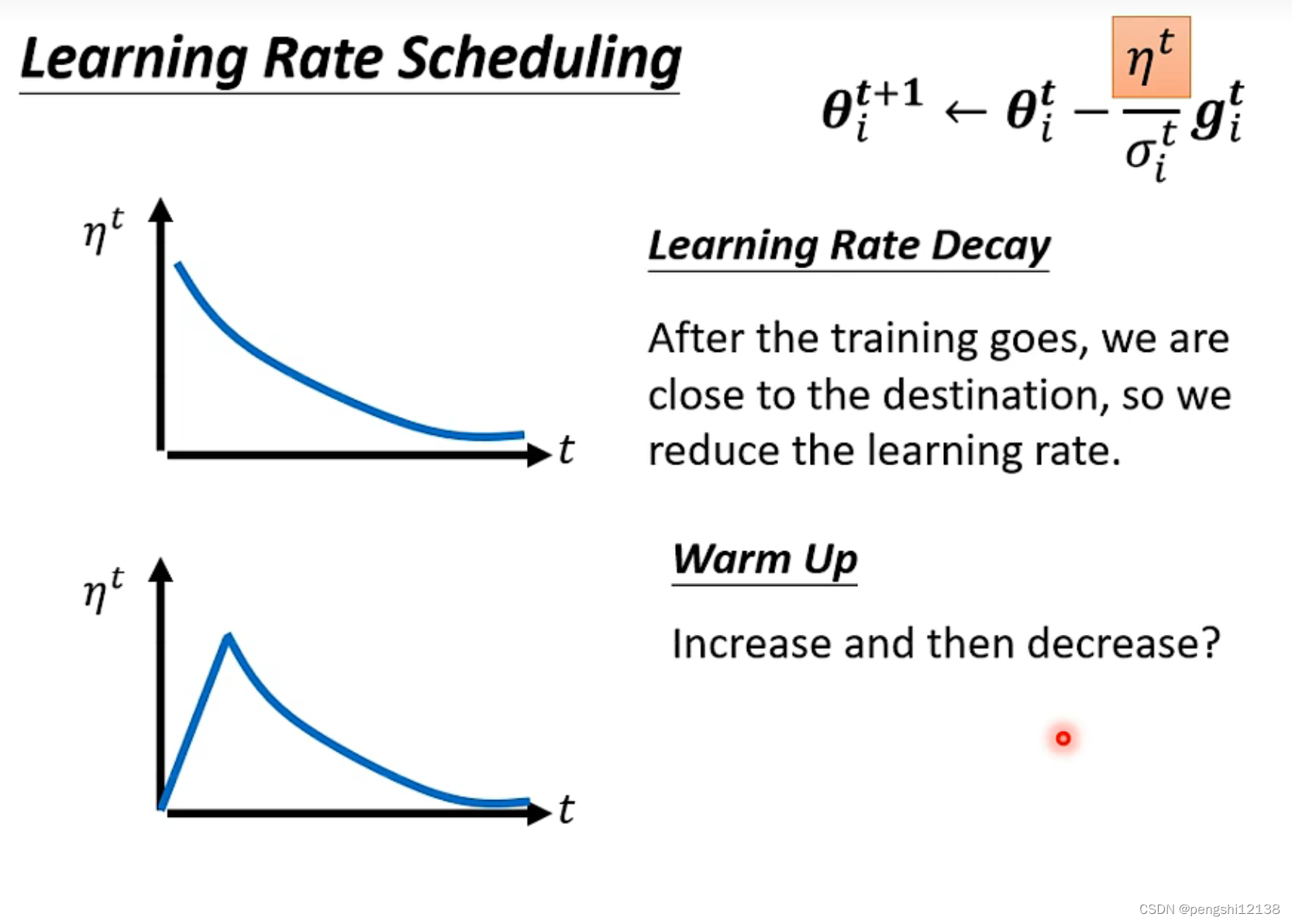

m考虑的是累积的梯度方向,而西格玛考虑的是累积的梯度大小。
训练过程失败原因(4)——分类
使用one-hot 编码格式,搭配softmax,进行分类训练,同时使用loss函数cross-entropy。
再探宝可梦、数码宝贝分类器
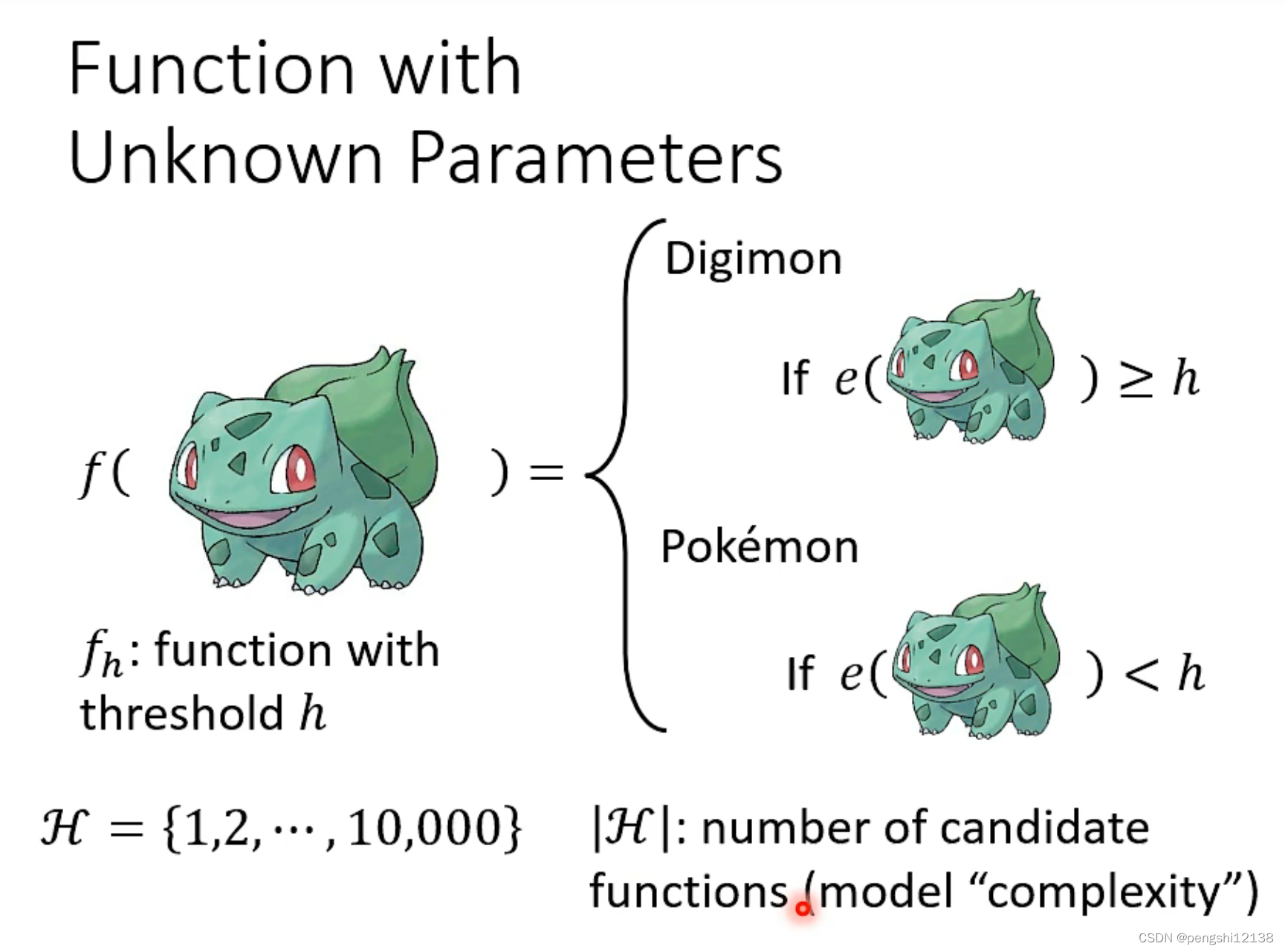
H 表示存在的阈值h函数情况,表示模型复杂度,h表示阈值,对于当下训练模型来说,h表示图像黑白图像的线条数量。

损失函数没有使用交叉熵,而这个loss计算仅仅只是错误率。

现实和理想的数据集是不同的,因为现实能够收集只有部分,模型训练的目的就是符合理想的情况,即是满足所有存在的情况。

其中对于所有的h阈值进行遍历,找到一个最好的h满足L最小。
上图表示的极限的定义,将train数据集和all数据集满足的极限情况,目的就是找到一个好的train数据集能够满足好的理想情况,表示了train数据集的重要性。

h1、h2、h3表示弄坏数据集的阈值,由于并集难以计算,所以使用相加

heoffing公式表示某个h把train数据集弄坏的几率。
伊姆西隆是超参,是你在应用时自己定义的“程度”,越小越严格,效果好但概率低。

当N变大时候,对应的存在坏的h会变小

反向推导需要多少的数据集才能够使得训练集变坏的概率降低。

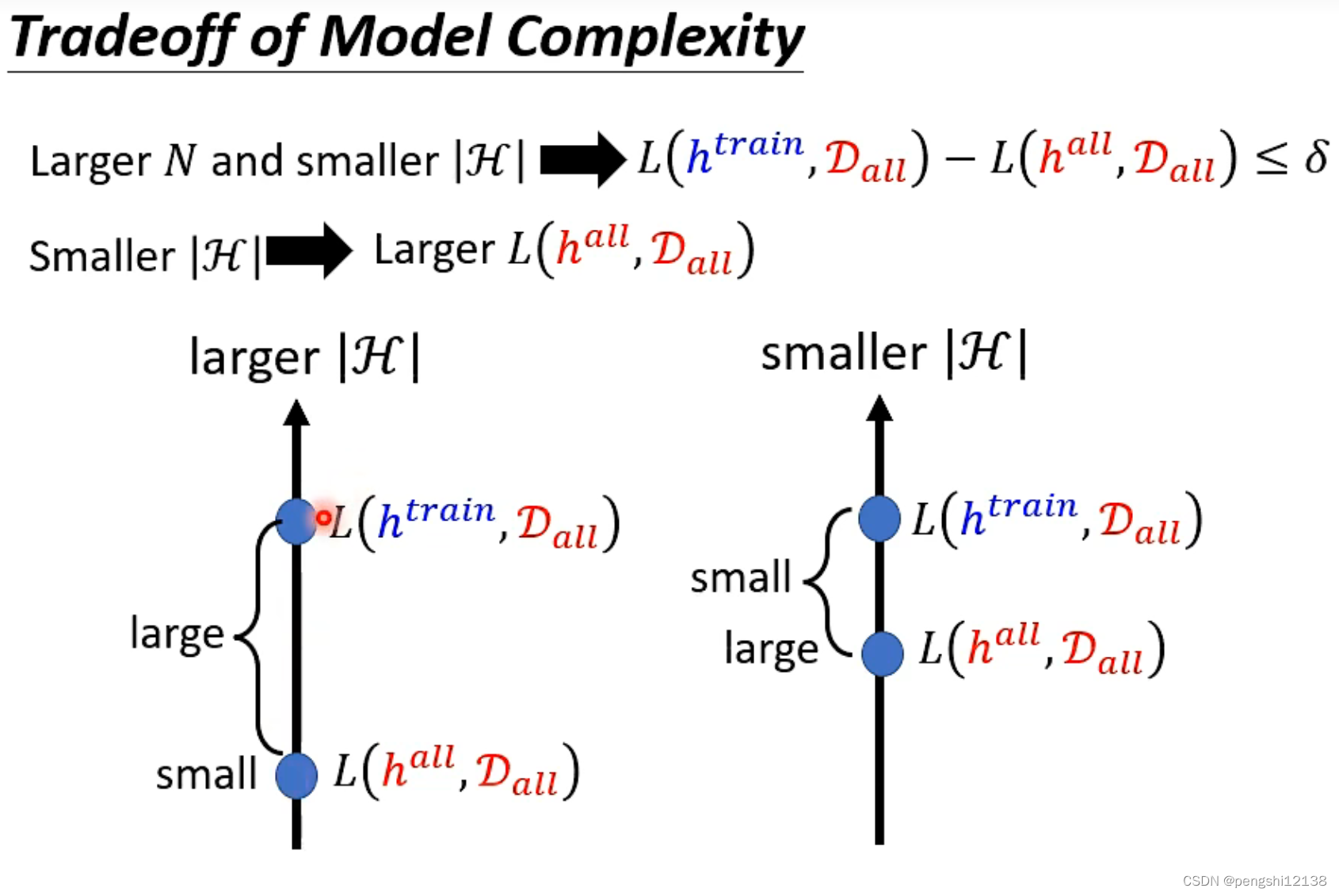
较大的H导致理想和现实的loss差距会变大,然后小的H虽然差距减少但是本身loss会变大。
对于较大的N较小的H 存在理想的loss太大了,而解决这问题方式就是深度学习。
神经网络新优化器
(1)SGD
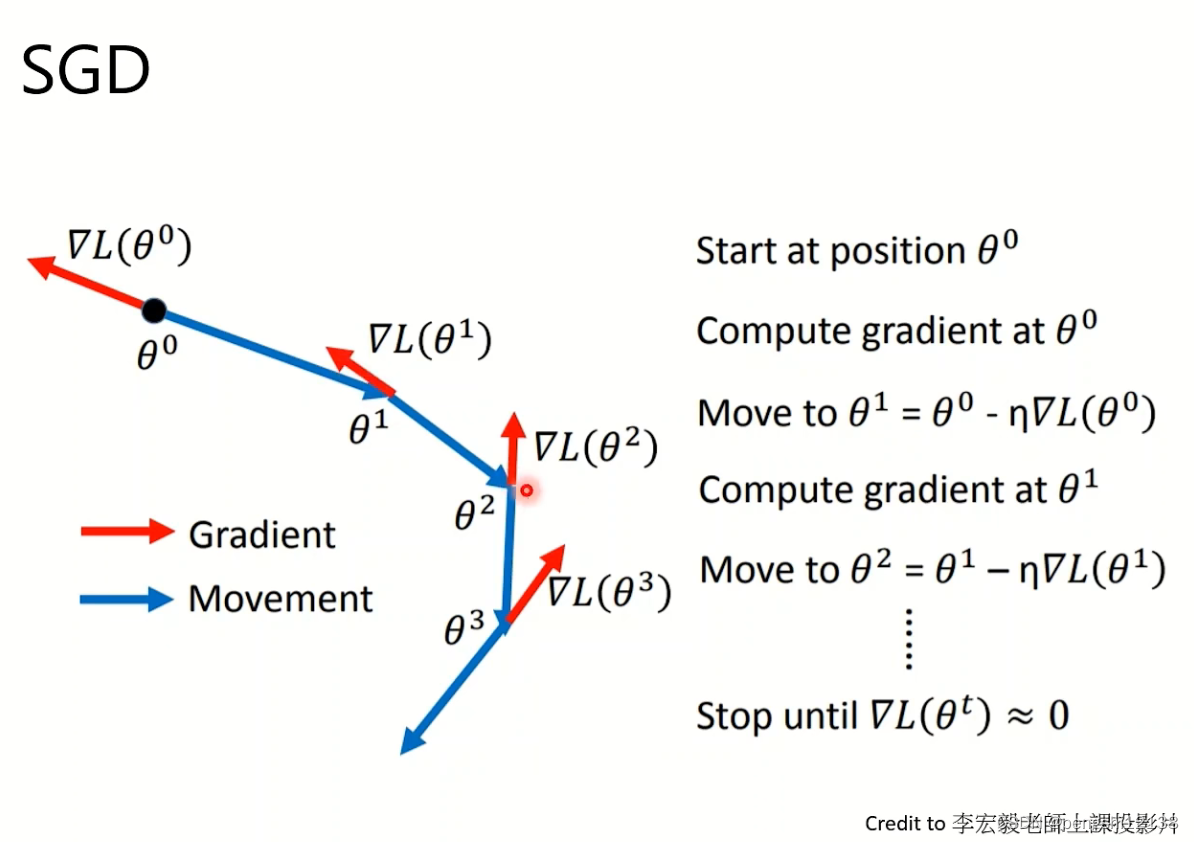
普通的梯度下降算法,利用反向传播算法计算梯度。
(2)SGD with momentum
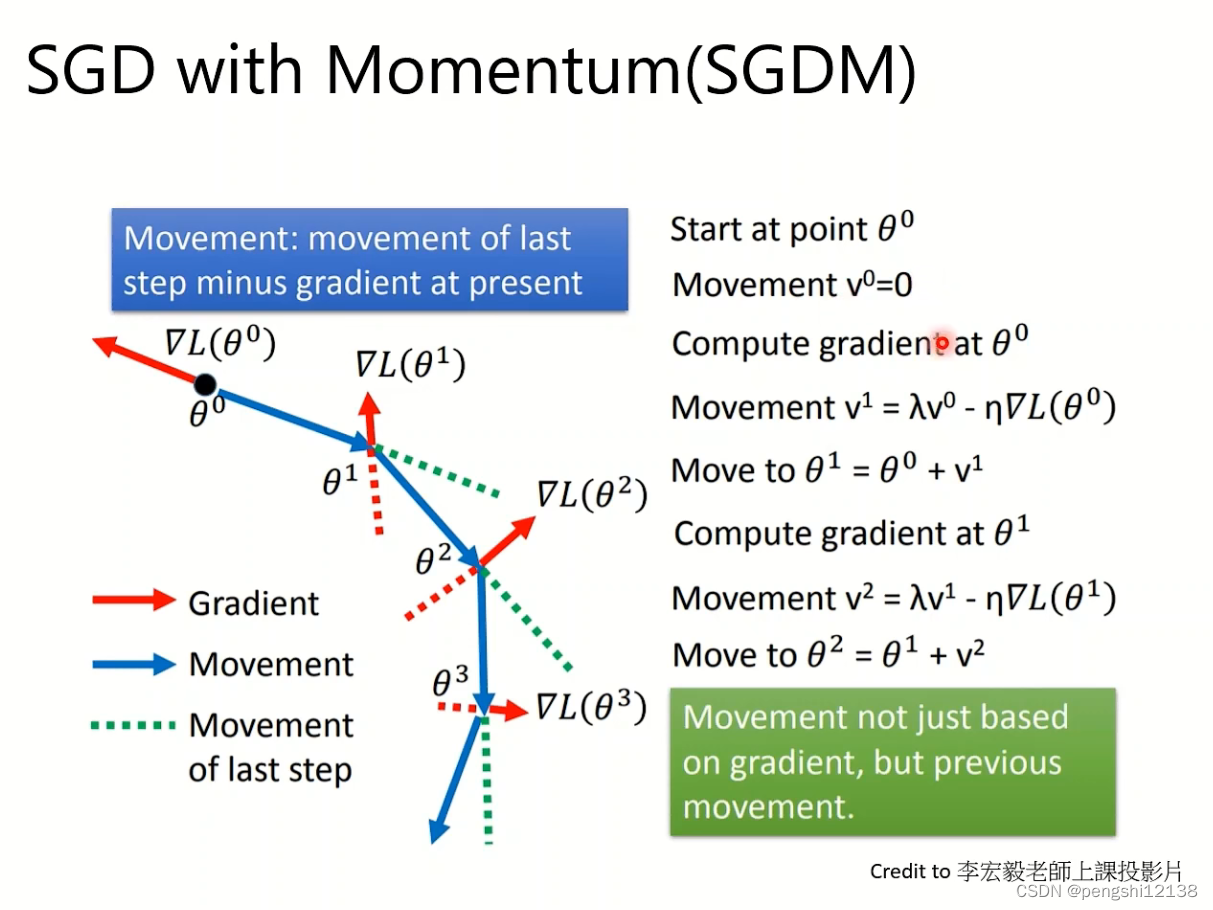
累计上了以往的训练梯度,要注意的是累加的梯度对应的batch数据集。
能够逃脱local minima,携带动量后有一定助力脱离局部最小值。
(3) Adagrad
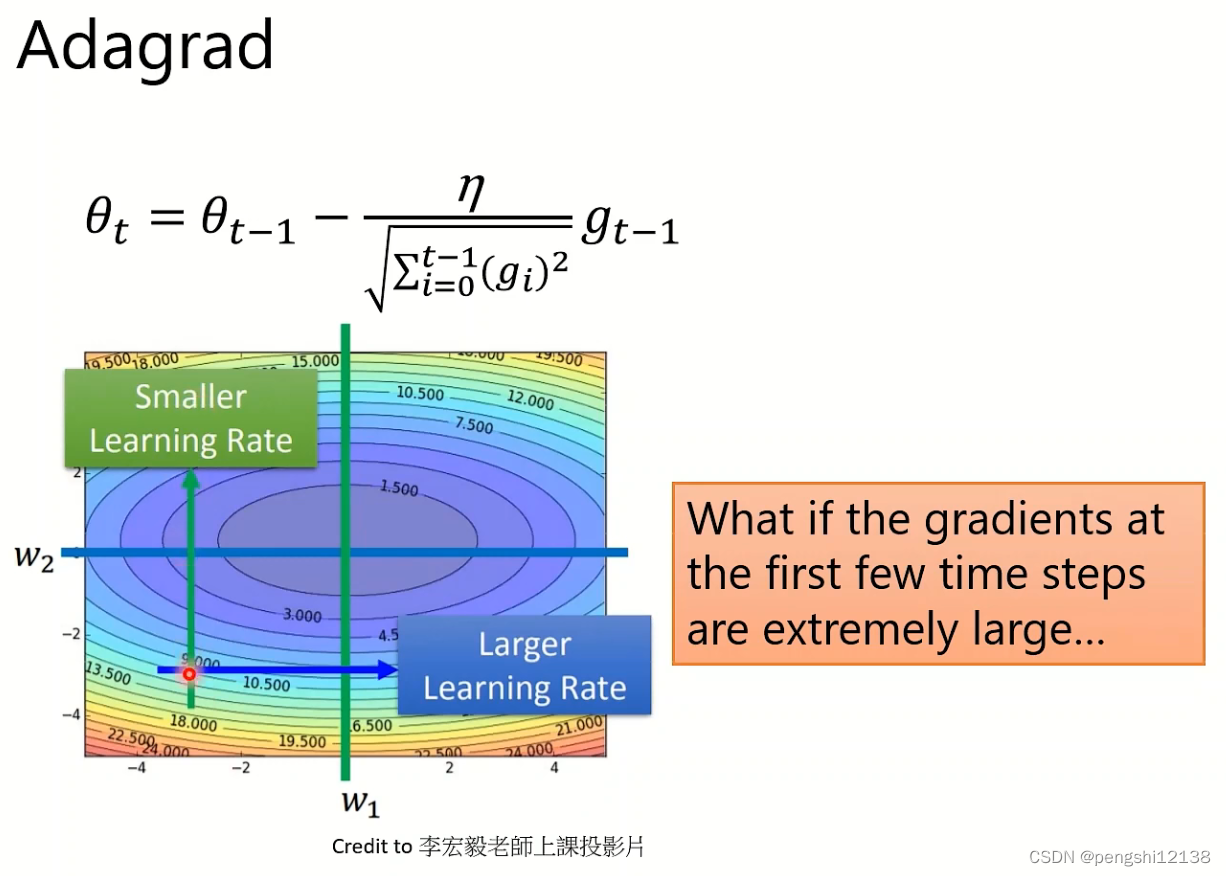
随着时间的累加,降低学习率。
(4) RMSProp
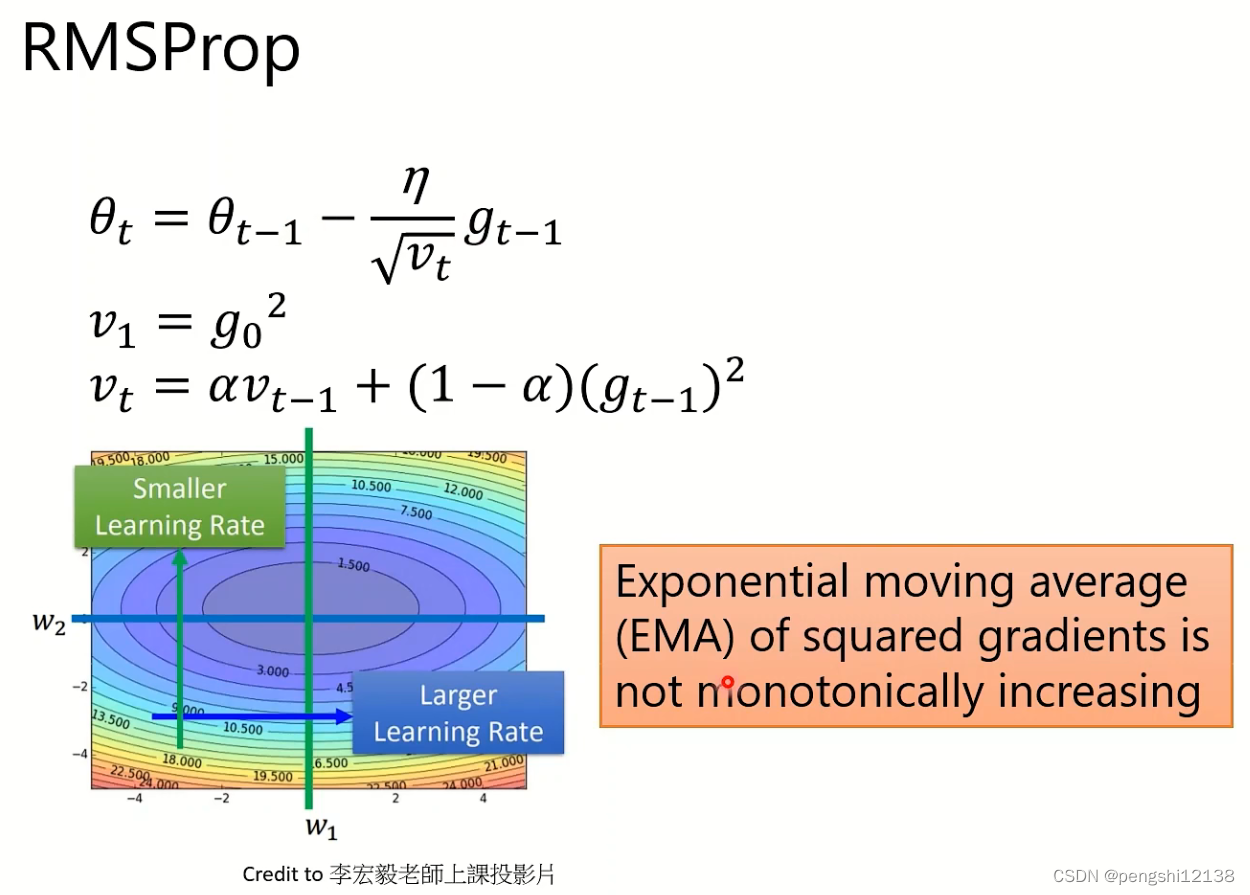
改善上面的存在的问题,对于过大的累计梯度导致学习率变得很低。
(5) Adam

结合了SGDM和RMSProp算法。
Adam的缺陷和对应的提升手段

对于突然上升的梯度,动量影响会很小。

对应的解法就是 AMSGrad

记住最大的梯度,但是对于前期很大的梯度时候,增长又会很缓慢。解决的方式就是使用AdaBound。

对于SGDM算法的提升
对于SGDM中梯度更新过于缓慢,使用周期性的学习率进行设计。

设定周期,最大的学习率和最小的学习率。
同时对于周期可以使用One-cycle LR进行设计,学习先变大后期变小,也就是warm-up。

EMA 估计出对应的阈值,最大记忆大小,通过这个阈值进行计算选择 SGDM还是ADAM,同时计算出v的方差进行设计对应的学习率倍率大小。
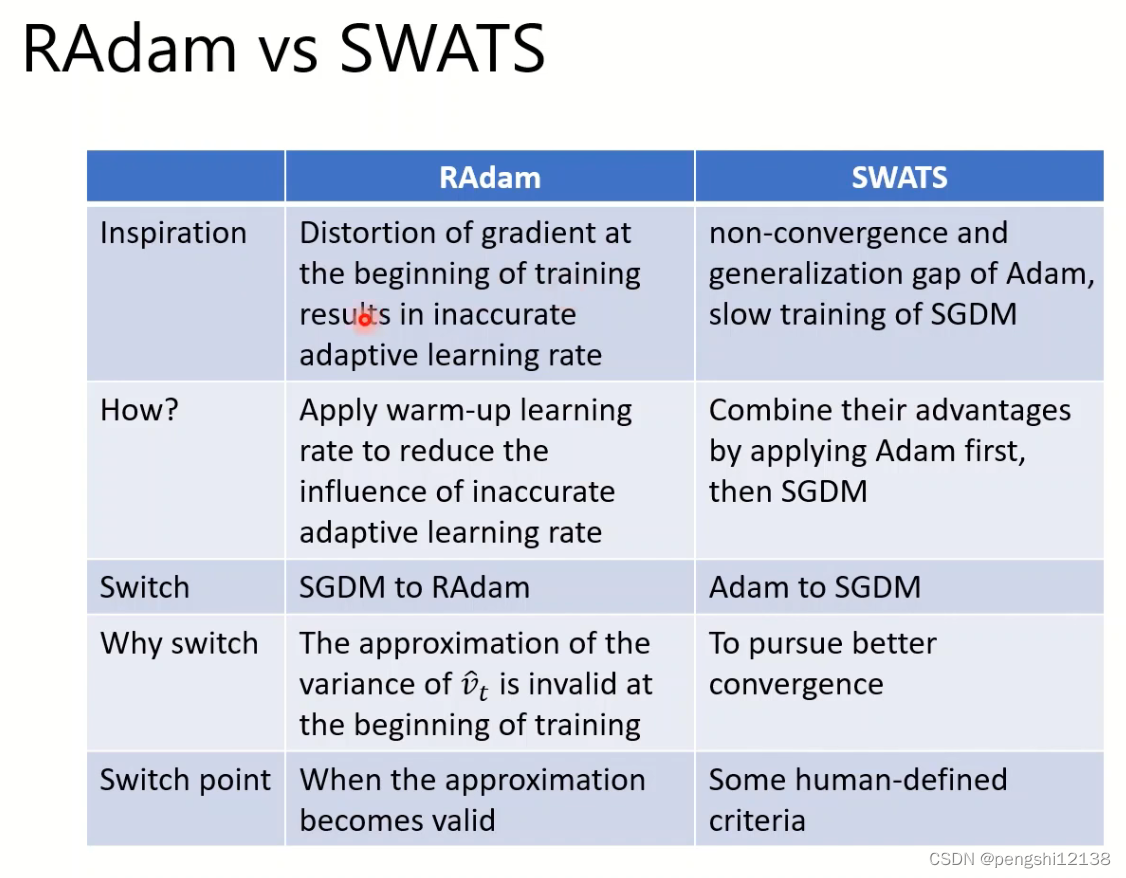
其中还有另一种warm-up方式SWATS,对比如下:
对于优化器,外面再包含一层,进行查看过去几次梯度的值进行设计。如下方式Lookahead。

优化器对于未来趋势future的计算
主要是对于动量增加的过程中,防止回滚到往过大梯度的地方,所以使用预测未来的梯度的方式,其实就是在当前公式中添加已经计算得到的梯度,进行遏制梯度往不好的方向进行。
对于看到未来趋势的梯度采用NAG算法


下面是Adam的超前部署操作,区别就是mt和mt-1的区别,表示是不是未来的值。
优化器中的正则化过程
优化器中存在正则化,但是再训练过程中,就算动量m和累计梯度v不需要添加正则化L2。同时已经证明再这些计算中添加了正则化效果会变差。

其他对于优化器具有帮助的事情
对于数据进行乱序
对于层上进行dropout层随即除去神经元
梯度噪音


warm-up层
从简单到复杂的训练集训练
迁移学习,移动别人好的模型

归一化操作
总结

lookahead可以和上面的算法进行结合,更好的预测下一步的梯度。
对于不同的梯度下降算法可以对应不同的应用场景。

















 936
936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











