







系列文章目录
上一篇:【Python Onramp】 0. 卷首语:项目导向,或Learn by doing
下一篇:【Python Onramp】2. Python简单数据分析pandas、matplotlib、Excel:Mac 平台几款软件的反汇编指令统计
本文目录
项目描述
Python初体验!github仓库见https://github.com/Honour-Van/CS50/tree/master/PythonOnramp
这个练习中我们将进行2018年中国机场吞吐数据的处理,以及朴素的展示
项目中你将:
- 熟悉Python基本语法、数据结构和方法的使用。
- 基于简单的任务描述建立程序原型。
文件ChinaAirport.txt 是一份存在一定格式问题的数据文件,其内容是2018 年中国235 个机场吞吐量。数据由三列组成,第一列是序号,第二列是机场名称,第三列是年度累计吞吐量,第四列是同比增速(同2017 年相比)。另外,部分机场没有2018 年数据(原因未知)。请根据数据完成练习。注意:数据中有千分位逗号且逗号也是数据列分隔符。
任务1
编写一个名为DataArrage.py的程序,用于消除第三列中千分位的分隔符(不能手工删除,要考虑大量数据时),并删除缺失2018 年数据的机场数据(不能手工删除,判断
标志是该行第三列数据缺失)。将整理后的数据存储为cnAirport.txt。后续问题都是基于该数据。
任务2
编写一个名为DataDeep.py程序,用于完成如下功能:
- 读入清洗好的数据文件,将数据整理成list,每个list 成员为tuple,包含机场名称(字符串),2018 吞吐量(浮点数)、2017 吞吐量(浮点数)、同比增量(浮点数);
- 以1)数据为基础,输出按2017 年吞吐量降序排名的数据,每个机场一行,第一列为序号(按排序后的顺序编号,从1 开始计数)、第二列为机场,第三列为2018 年吞吐量、第四列为2017 年吞吐量,没有标题行,列之间用英文逗号间隔;
- 以1)数据为基础,输出按2018 年增量(2018 年减去2017 年吞吐量)降序排名的数据,每个机场一行,第一列为序号(按排序后的顺序编号,从1 开始计数)、
第二列为机场,第三列为2018 年吞吐量、第四列为2017 年吞吐量,没有标题行,列之间用英文逗号间隔; - 以1)数据为基础,输出按2018 年增长率(2018 年减去2017 年吞吐量除以2017 年吞吐量)降序排名的数据,每个机场一行,第一列为序号(按排序后的顺序编号,
从1 开始计数)、第二列为机场,第三列为2018 年吞吐量、第四列为2017 年吞吐量,没有标题行,列之间用英文逗号间隔;
语法讲解
语法点1:数据类型和数据类型转换
https://www.runoob.com/python3/python3-data-type.html
https://www.liaoxuefeng.com/wiki/1016959663602400/1017063826246112
在实际的Python使用过程当中,要格外小心数据类型的问题
- 数字类型之间才能进行四则运算
- 字符串拼贴只能发生在字符串类型变量之间
- 索引只能使用int类型
语法点2:切片(slice):列表(list)、字符串(str/string)
https://www.liaoxuefeng.com/wiki/1016959663602400/1017269965565856
https://zhuanlan.zhihu.com/p/79541418
list和字符串是python中常见的序列型变量,要取出其中的“一段”就可以使用切片的方法。
- 注意左闭右开的特性。
- 生成器(generator)不能切片
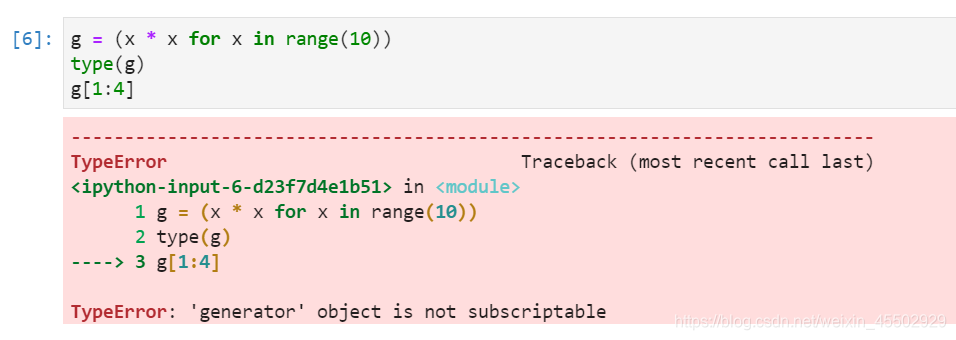
语法点3:列表的常用方法(method):
python3列表:https://www.runoob.com/python3/python3-list.html
使用list和tuple:https://www.liaoxuefeng.com/wiki/1016959663602400/1017092876846880
迭代:https://www.liaoxuefeng.com/wiki/1016959663602400/1017316949097888
排序自定义和lambda函数:https://www.cnblogs.com/zle1992/p/6271105.html
列表在抽象结构上类似于C-like中的数组,但在使用时更接近vector。
这个工程中我们要用到增删改查,排序,元素数量,遍历输出等。
- append:用于向list中添加一个元素,注意list中各个元素的类型可以不相同,这和C-like语言中是不一样的
- sort:排序,可以增加一些参数对排序方式进行自定义
- len:列表中元素数量
- for in 遍历:list是可迭代的,因而可以直接遍历。这个很像C++中的for auto
语法点4:pandas入门,以及因地制宜
这个项目中有两个小的子任务。其中任务1特别强调了一点,即数据中有千分位逗号且逗号也是数据列分隔符。pandas虽然给我们提供了非常好的API直接读入CSV文件,但是由于这样的限制,其实并不比直接写方便。
但在任务2中,我们完全可以将清洗后的文件(这时可以算是CSV了)利用pandas进行处理。
这就是这个系列当中的第一个重要的思想,即因地制宜,任务是目的,工具是手段。
如果这个清洗好的CSV文件可以读入excel,那么用excel进行原型分析(比如绘图看趋势)会比用python更好。当然自媒体可以说“python杀死了excel”。
语法点5:文件读写和上下文(context)
利用with语句的文件读写:https://www.cnblogs.com/ymjyqsx/p/6554817.html
上下文:https://www.cnblogs.com/wongbingming/p/10519553.html
利用with的读写是一种更加pythonic的写法。
这里只有一个需要特别注意的点,就是上下文中缩进的部分(我叫它with block)并不是局部性的,如果在其中读入文件后得到的变量仍然是全局的。这一点将在具体实现时细说。
readline和readlines是两个在实际处理表格型数据、文本文件时常用的方法,前者只读一行,后者读出一个可迭代(切片)的对象。
具体实现
任务1
首先从https://github.com/Honour-Van/CS50/blob/master/PythonOnramp/ChinaAirportData.txt上下载任务所需的数据文件。
首先我们尝试读入数据文件
with open('./ChinaAirportData.txt', 'r', encoding='utf-8') as f:
在遍历结构开始之前,我们先把源文件的表头读进去:
with open('./ChinaAirportData.txt', 'r', encoding='utf-8') as f:
with open('./cnAirport.txt', 'w', encoding='utf-8') as fw:
fw.write(f.readline())
注意这里的两层with使用了不同的读写模式。里层为了写,使用的是代表write的’w’,外层是用于读入的’r’(read),后面我们还会使用到用于追加的’a’(append)
readline只读一行,将表头取出并放到新的文件中。
其余的工作都是数据处理,我们需要做的,就是描述清楚初始文件和目标格式之间的差异。首先我们来观察一下这个文件:
1,北京/首都,10,098.3,5.4
2,上海/浦东,7,405.40,5.8
3,广州/白云,6,979.00,6.1
4,成都/双流,5,287.70,6.2
5,深圳/宝安,4,934.90,8.2
6,昆明/长水,4,708.80,5.3
7,西安/咸阳,4,465.30,6.7
8,上海/虹桥,4,362.80,4.2
9,重庆/江北,4,159.60,7.4
10,杭州/萧山,3,824.20,7.5
消除第三列中千分位的分隔符,但各列之间也使用了逗号作为分隔符。那我们的目标可以转换为“如果有五列,我们就把第三列和第四列合起来”,是不是就清楚很多了呢?
在遍历过程中,使用split进行分列,返回的是一个列表,各个元素是字符串,是原字符串按照指定分隔符分开之后的子串,不包括分隔符
for line in f.readlines():
content = line.split(',')
利用长度进行判断,我们可以做这样一个判断:
if len(content) == 5:
fw.write(content[0] + ',' + content[1] + ',' + content[2] + content[3] + ',' + content[4])
else:
fw.write(line)
当然我们还可以使用列表切片的方法,因为python的切片提供了“倒数第几个”的表述。我们可以将这个过程表述为,取content列表中下标为2的直到倒数第二个合并起来。如下:
for piece in content[2:-1]:
resline += piece
最后将resline读入为“本年累计”列的数据即可。
另外不要忘记去除无该列的数据的行,比如:
235,安康,,-100
当然这对于这一步不会出错,但任务2中就会有较大的影响,表格中的空位对应的None对象将会对初学者造成很大的麻烦。
判断方法当然也不复杂,如果那一列的数值为空,就跳过:
if len(content[2]) == 0:
continue
一个完整的示例代码见https://github.com/Honour-Van/CS50/blob/master/PythonOnramp/DataArrange.py
任务2
做完任务1之后,其实应该对于文件读写、列表遍历已经有了基本的认识,我们接下来要做一点和简单的计算。
第一步是将清洗好的数据文件读入,由于任务1中的工作,这已经是一个正则的CSV了。我们完全可以使用pandas。这才是第一篇文章,还是先熟悉一下list。
像之前一样读入每一行,并分列:
with open('./cnAirport.txt', 'r', encoding='utf-8') as f:
f.readline()
for line in f.readlines():
content = line.split(',')
接下来要涉及到文件读写的一个常见初学错误,文件读入之后仍然是以字符串形式存在的,如果要计算,需要首先转换为数字类型。
val18 = float(content[2])
growth = float(content[3])
val17 = val18 / (1 + growth/100) # 反求17年的数据
这个项目里我们规定同比增速=同比增量=增长率。
注意这个数据文件中的一些小问题,比如有几地的增长率为-100,直接将其去除,
最后使用list的append语句即可,生成数据变量的完整代码如下:
# subtask 1:读入数据生成“机场名称+18年吞吐量+17年吞吐量+同比增速”
# (这个项目里我们规定同比增速=同比增量=增长率)
data = []
with open('./cnAirport.txt', 'r', encoding='utf-8') as f:
f.readline()
for line in f.readlines():
content = line.split(',')
val18 = float(content[2])
growth = float(content[3])
if growth == -100:
continue
val17 = val18 / (1 + growth/100)
data.append(tuple([content[1], val18, val17, growth]))
# print(data)
而后是排序的用法,三种的方法相同
# substask 2:按17年吞吐量降序
print('\n---------subtask #2: 按照17年吞吐量降序-----------')
data.sort(key=lambda X: X[2], reverse=True)
for i in range(len(data)):
print(i+1, data[i][0], data[i][1], data[i][2], sep=',')
# subtask 3:按增量降序
print('\n---------subtask #3: 按照吞吐量增量降序-----------')
data.sort(key=lambda X: X[1]-X[2], reverse=True)
for i in range(len(data)):
print(i+1, data[i][0], data[i][1], data[i][2], sep=',')
# subtask 4: 按增长率降序
print('\n---------subtask #4: 按照吞吐量增长率降序-----------')
data.sort(key=lambda X: X[3], reverse=True)
for i in range(len(data)):
print(i+1, data[i][0], data[i][1], data[i][2], sep=',') # sep是输出各变量之间的分隔符
另外有两个点,这里输出时,可以使用迭代输出方法:
for i,item in enumerate(data):
print(i+1,item[0], item[1], item[2], sep=',')
同时,由于python计算的浮点精度很高,可能会影响展示效果,
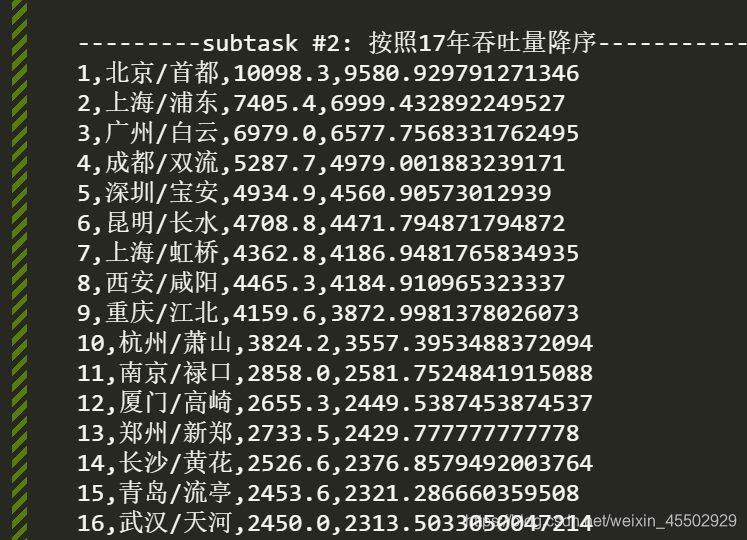
所以我们在计算过程中加入精度限制:
val17 = round(val18 / (1 + growth/100),1)
得到的结果如下,看起来更干净些了。
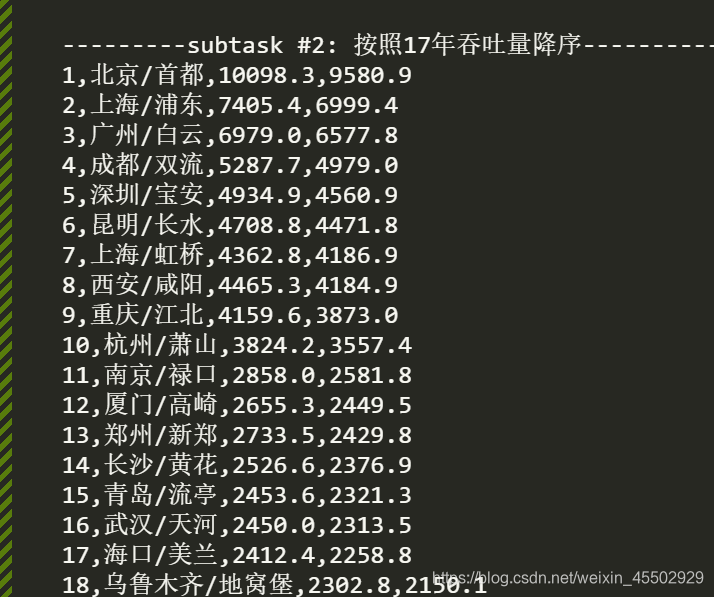
后续如何让输出的表格更好看,还有很多方法,这是第一节,就先到这里了。
总结
一个思想:因地制宜
语法点:list的使用,数据类型,文件读写














 2114
2114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









