






 本文介绍了如何在Python中使用Pandas库的sample方法对DataFrame进行随机排序,包括参数解释和示例,如n、frac、replace、weights等,以及不同场景下的应用。
本文介绍了如何在Python中使用Pandas库的sample方法对DataFrame进行随机排序,包括参数解释和示例,如n、frac、replace、weights等,以及不同场景下的应用。
在Python中,可以使用Pandas库来操作DataFrame。要打乱DataFrame的顺序,可以使用sample方法来实现。以下是一个示例代码:
import pandas as pd
# 创建一个示例DataFrame
data = {'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
# 打乱DataFrame的顺序
df_shuffled = df.sample(frac=1).reset_index(drop=True)
print(df_shuffled)
在上面的示例中,sample(frac=1)会按照随机顺序对DataFrame进行抽样,实现了打乱DataFrame的顺序。reset_index(drop=True)会重置索引,使得索引按照新的顺序重新排列。
初始df:

打乱顺序后的df:
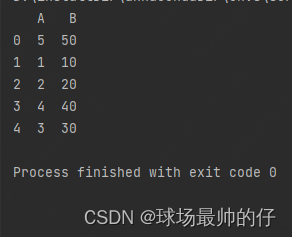
可以根据自己的实际情况调整代码中的DataFrame和列名。
此外,pandas的sample还有一些其他参数和用法。DataFrame中的sample()方法用于从DataFrame中随机抽取指定数量或比例的行或列。下面是sample()方法的一些常用参数和详细介绍:
- n:要抽取的行数或列数,可以是整数。默认为1。
- frac:要抽取的行数或列数占原DataFrame的比例,取值范围为[0, 1]。n和frac参数只能同时指定一个,如果同时指定了两个,优先使用n参数。
- replace:是否允许重复抽样,默认为False。如果设为True,则抽取的样本中可能包含重复的行或列。
- weights:行或列的权重列表,用于指定每行或每列被抽取的概率。
- axis:抽取的方向,0表示按行抽取,1表示按列抽取,默认为0。
- random_state:随机数种子,用于控制随机抽样的结果可以重现。
例如,假设有一个DataFrame df,你可以使用以下代码来随机抽取其中的一行:
sample_row = df.sample(n=1)
或者按照一定比例抽取其中的30%行:
sample_rows = df.sample(frac=0.3)

















 1088
1088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









