







文章目录
数据描述
diamonds是包括近54000颗钻石的价格和其他属性的内置数据集,共
53940
53940
53940行
10
10
10个变量。每行数据代表一个不同的钻石的属性数据。本文对该数据集进行探索性分析,并做数据可视化处理,探索钻石的价格、重量分布,及钻石价格与重量、形状、切割状态、颜色、透明度之间的关系。接下来,进行非参数检验,探究不同切割类型、颜色和透明度的钻石,价格是否具有显著性差异。最后,利用钻石的各项属性,建立多元线性模型,对钻石的价格进行预测。
导入数据
导入数据并查看每个变量的类型。
library(readr)
library(dplyr)
library(kknn)
library(TTR)
library(AER)
library(pROC)
library(e1071)
library(nnet)
library(rpart)
library(tidyverse)
library(memisc)
data <- diamonds
head(data)
str(data)
## # A tibble: 6 x 10
## carat cut color clarity depth table price x y z
## <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
## 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
## 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
## 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
## 4 0.29 Premium I VS2 62.4 58 334 4.2 4.23 2.63
## 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
## 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
str(data)
## tibble [53,940 x 10] (S3: tbl_df/tbl/data.frame)
## $ carat : num [1:53940] 0.23 0.21 0.23 0.29 0.31 0.24 0.24 0.26 0.22 0.23 ...
## $ cut : Ord.factor w/ 5 levels "Fair"<"Good"<..: 5 4 2 4 2 3 3 3 1 3 ...
## $ color : Ord.factor w/ 7 levels "D"<"E"<"F"<"G"<..: 2 2 2 6 7 7 6 5 2 5 ...
## $ clarity: Ord.factor w/ 8 levels "I1"<"SI2"<"SI1"<..: 2 3 5 4 2 6 7 3 4 5 ...
## $ depth : num [1:53940] 61.5 59.8 56.9 62.4 63.3 62.8 62.3 61.9 65.1 59.4 ...
## $ table : num [1:53940] 55 61 65 58 58 57 57 55 61 61 ...
## $ price : int [1:53940] 326 326 327 334 335 336 336 337 337 338 ...
## $ x : num [1:53940] 3.95 3.89 4.05 4.2 4.34 3.94 3.95 4.07 3.87 4 ...
## $ y : num [1:53940] 3.98 3.84 4.07 4.23 4.35 3.96 3.98 4.11 3.78 4.05 ...
## $ z : num [1:53940] 2.43 2.31 2.31 2.63 2.75 2.48 2.47 2.53 2.49 2.39 ...
可以看到总共有10个变量,其中3个为因子类型,1个为整数类型,6个为数值类型。
3个为因子类型的变量为cut、color和clarity;1个为整数类型的变量为price;6个数值类型的变量为carat、depth、table、x、y和z。
变量含义
diamonds是包括近54000颗钻石的价格和其他属性的数据集,共53940行10个变量。每行数据代表一个不同的钻石的属性数据。
names(data)
## [1] "carat" "cut" "color" "clarity" "depth" "table" "price"
## [8] "x" "y" "z"
| 变量 | 含义 | 范围 |
|---|---|---|
| price | 钻石的美元价格(单位:刀) | 326 − 18 , 823 326-18,823 326−18,823 |
| carat | 钻石的重量(单位:克拉) | 0.2 − 5.01 0.2-5.01 0.2−5.01 |
| cut | 切割质量 | Fair(一般), Good(好), Very Good(非常好), Premium(优质), Ideal(理想) |
| color | 钻石颜色 | J (最差)到 D (最好) |
| clarity | 测量钻石的透明度 | I1(最差) ,SI2,SI1,VS2,VS1,VS2,VS1,IF (最好) |
| x | 钻石长度(单位:毫米) | 0 − 10.74 0-10.74 0−10.74 |
| y | 钻石宽度(单位:毫米) | 0 − 58.9 0-58.9 0−58.9 |
| z | 钻石深度(单位:毫米) | 0 − 31.8 0-31.8 0−31.8 |
| depth | 总深度百分比 | 43 − 79 43-79 43−79 |
| table | 钻石顶部相对于最宽点的宽度 | 43 − 95 43-95 43−95 |
数据清洗
检查缺失值及重复值
data %>% summarise(
across(everything(), ~ sum(is.na(.)))
)
## # A tibble: 1 x 10
## carat cut color clarity depth table price x y z
## <int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
## 1 0 0 0 0 0 0 0 0 0 0
data <- data %>%
distinct()
如上所述,diamonds数据集中,没有缺失项。在这些钻石数据中,重复值对于统计分析的意义不大,并且重复数据影响排序以及筛选等,需要把数据进行重复项删除,方便后续的统计分析工作。
探索性分析
钻石的形状
钻石总深度百分比及顶部相对于最宽点的宽度分布
data %>%
summarise(depth_median=median(depth),
table_median=median(table))
par(mfrow=c(1,2))
hist(data$depth,breaks = 40)
hist(data$table,breaks = 20)
## # A tibble: 1 x 2
## depth_median table_median
## <dbl> <dbl>
## 1 61.8 57
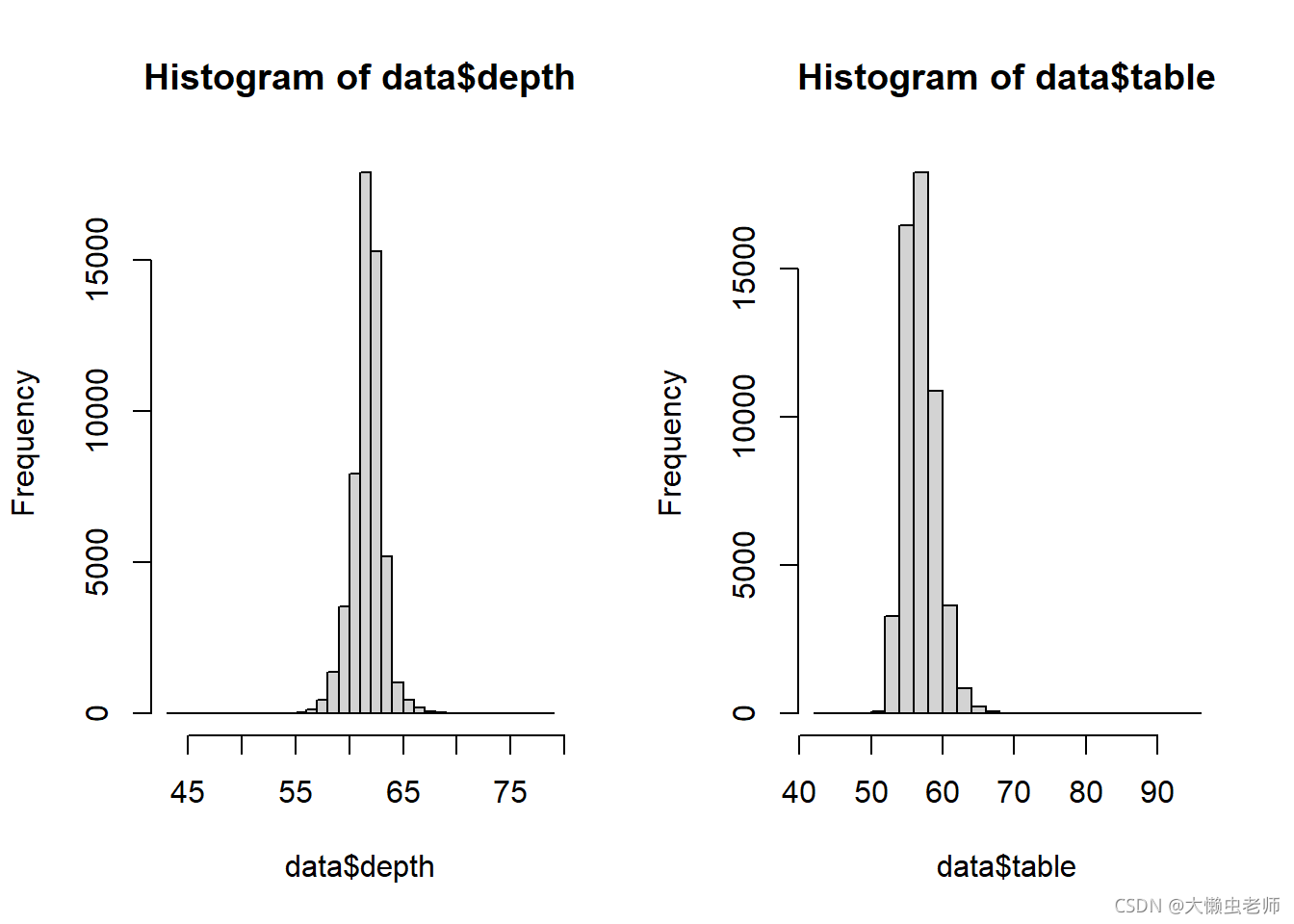
由数据统计可知,钻石总深度百分比的中位数为 61.8 % 61.8\% 61.8%;顶部相对于最宽点的宽度的中位数为 57 % 57\% 57%。
由图知,钻石总深度百分比及顶部相对于最宽点的宽度均符合正态分布。
钻石的重量分布
ggplot(data)+
geom_histogram(aes(x=carat),binwidth=0.1)
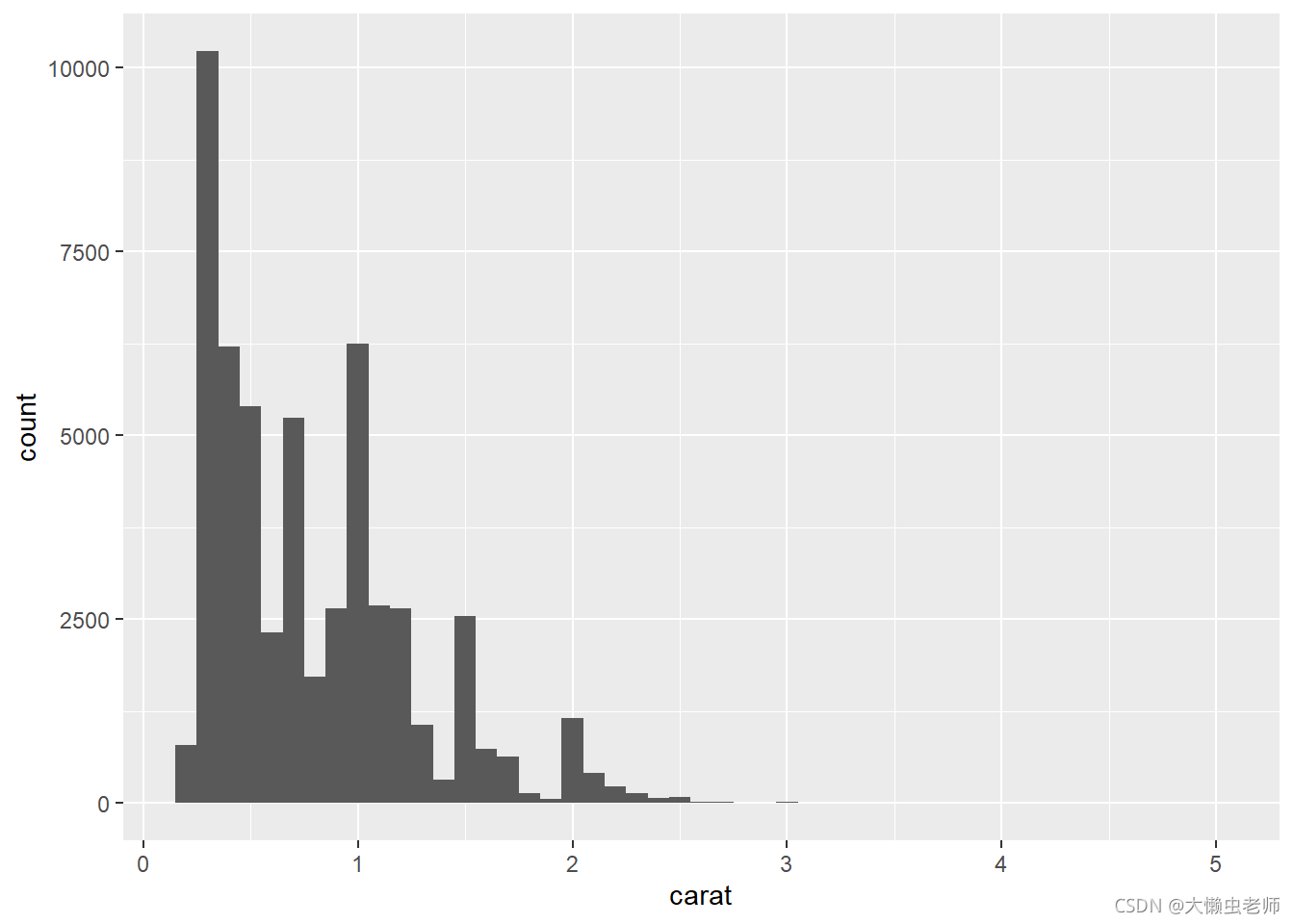
在钻石的重量分布上, 0 − 0.5 0-0.5 0−0.5克拉的钻石最多,超过 1.5 1.5 1.5克拉以上的钻石逐渐变少。
每种切割类型、颜色、清晰度的钻石分别有多少个
data %>%
count(cut, sort = T)
pie(table(data$cut),labels=names(table(data$cut)))
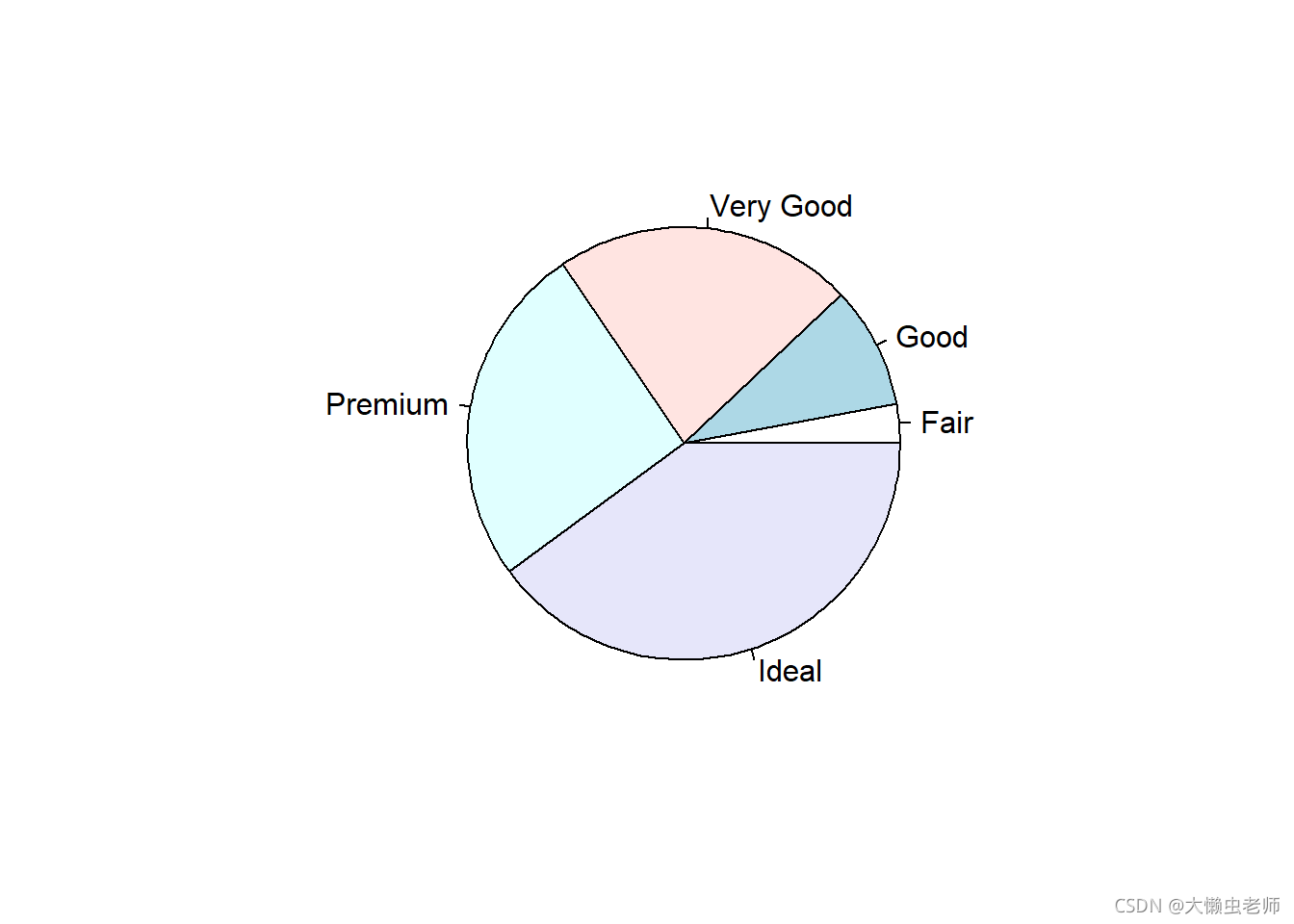
在切割类型上,理想切割的钻石为 21488 21488 21488只,优质切割的钻石为 13748 13748 13748只,切割得非常好的钻石为 12069 12069 12069只,切割得好的钻石为 4891 4891 4891只,切割得一般的钻石为 1598 1598 1598只。
如图所示,理想切割及优质切割的钻石占比超过一半以上。联系现实原因而言,因为钻石为奢侈品,切割水平高可以使钻石达到更好的视觉效果。所以理想切割及优质切割的钻石占比较高。
data %>%
count(color, sort = T)
pie(table(data$color),labels=names(table(data$color)))
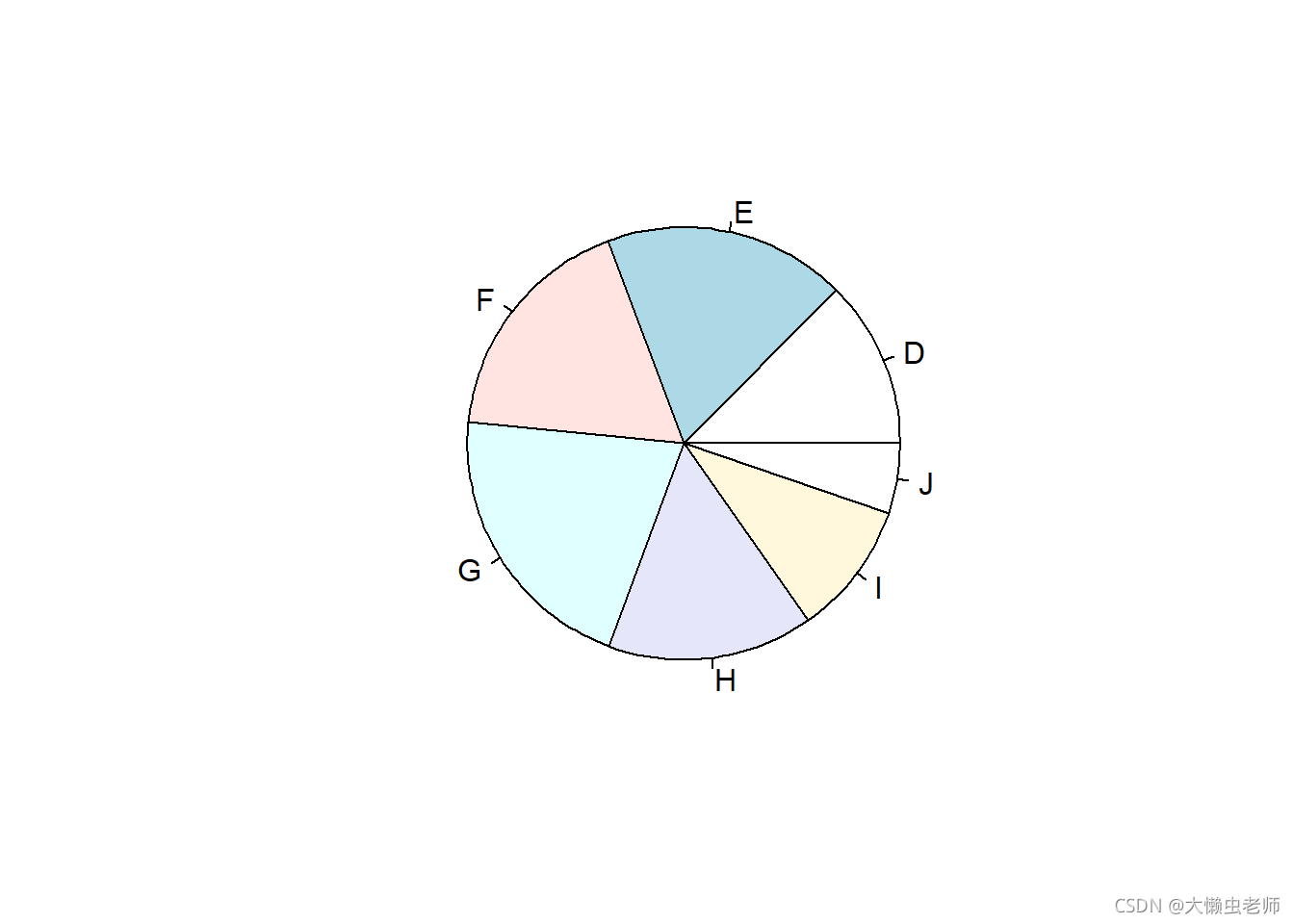
在钻石的颜色上, J (最差)到 D (最好)。其中 G 的数量最高,为 11262 11262 11262。D、I和J的数量最少,分别为 6755 6755 6755、 5407 5407 5407和 2802 2802 2802。说明钻石颜色一般的数量最少,颜色最差和颜色最好的钻石数量都不多。
data %>%
count(clarity, sort = T)
pie(table(data$clarity),labels=names(table(data$clarity)))
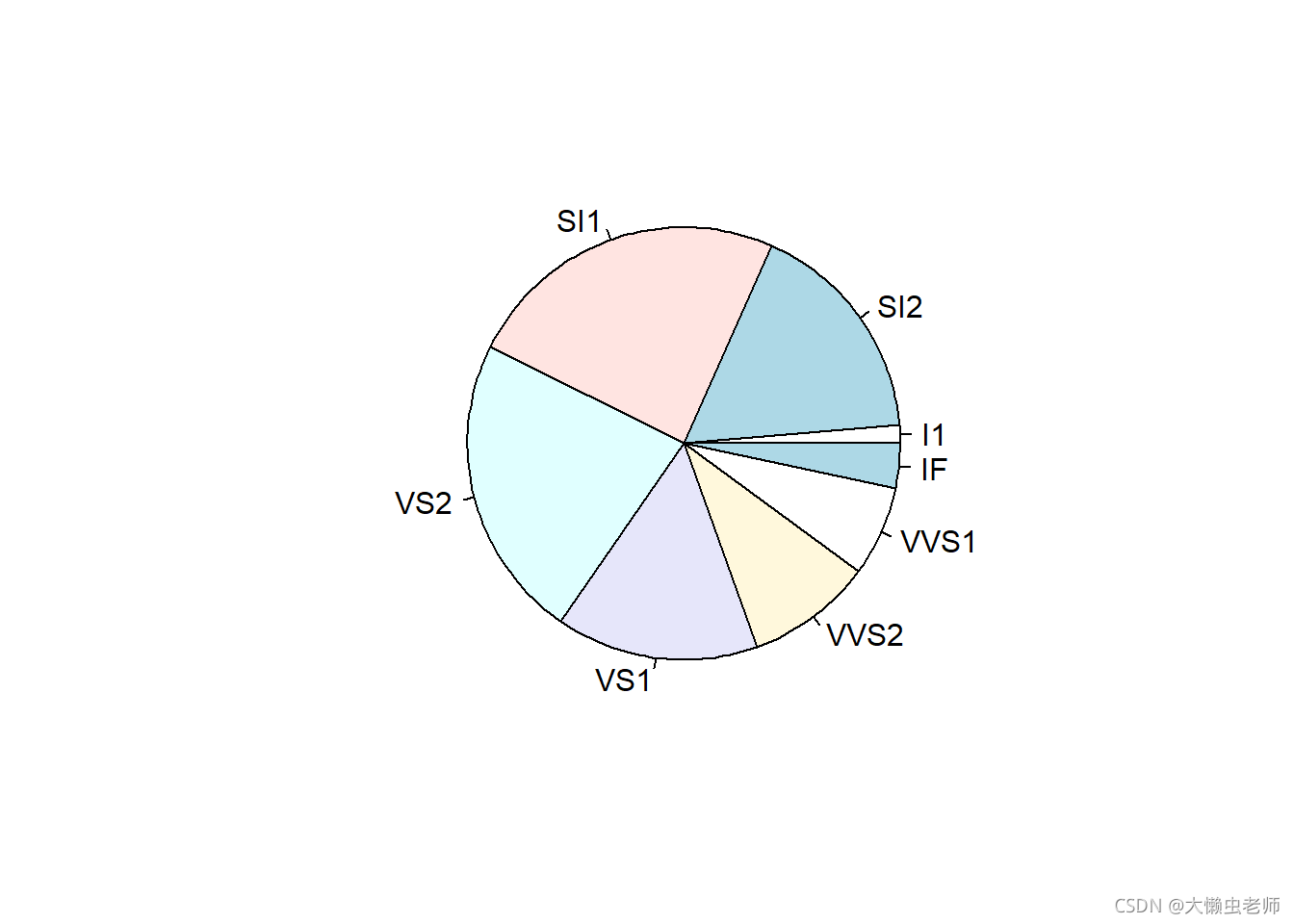
在钻石透明度上,I1(最差) ,SI2,SI1,VS2,VS1,VS2,VS1,IF (最好)。观察其统计数据,发现钻石透明度一般的占比最高,钻石透明度最差和最好的比例都比较低。
钻石的价格
最昂贵的10只钻石的属性信息
data %>%
arrange(desc(price)) %>%
slice_max(price, n = 10)
## # A tibble: 10 x 10
## carat cut color clarity depth table price x y z
## <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
## 1 2.29 Premium I VS2 60.8 60 18823 8.5 8.47 5.16
## 2 2 Very Good G SI1 63.5 56 18818 7.9 7.97 5.04
## 3 1.51 Ideal G IF 61.7 55 18806 7.37 7.41 4.56
## 4 2.07 Ideal G SI2 62.5 55 18804 8.2 8.13 5.11
## 5 2 Very Good H SI1 62.8 57 18803 7.95 8 5.01
## 6 2.29 Premium I SI1 61.8 59 18797 8.52 8.45 5.24
## 7 2.04 Premium H SI1 58.1 60 18795 8.37 8.28 4.84
## 8 2 Premium I VS1 60.8 59 18795 8.13 8.02 4.91
## 9 1.71 Premium F VS2 62.3 59 18791 7.57 7.53 4.7
## 10 2.15 Ideal G SI2 62.6 54 18791 8.29 8.35 5.21
选择数据集中价格前十的钻石,观察其属性信息。在这些价格最为昂贵的钻石中:
-
重量:8颗钻石的重量超过2克拉。有2颗钻石重量超过1.5克拉。
-
切割:其切割工艺普遍在理想和优质水平。
-
颜色:其颜色在一般及一般以上。
-
透明度:其透明度在一般及一般以上。
综上,可知这些钻石的重量大,其中2颗重量较低的钻石的颜色及切割工艺出众。
理想切割、颜色和清晰度最好的钻石的价格
data %>%
filter(cut=='Ideal',color=='D',clarity=='IF') %>%
summarise(average_price=mean(price),
median_price=median(price),
max_price=max(price),
min_price=min(price)
)
ggplot(data %>%
filter(cut=='Ideal',color=='D',clarity=='IF'))+
geom_histogram(aes(x=price),bins=28)
## # A tibble: 1 x 4
## average_price median_price max_price min_price
## <dbl> <dbl> <int> <int>
## 1 6567. 4184. 17590 893
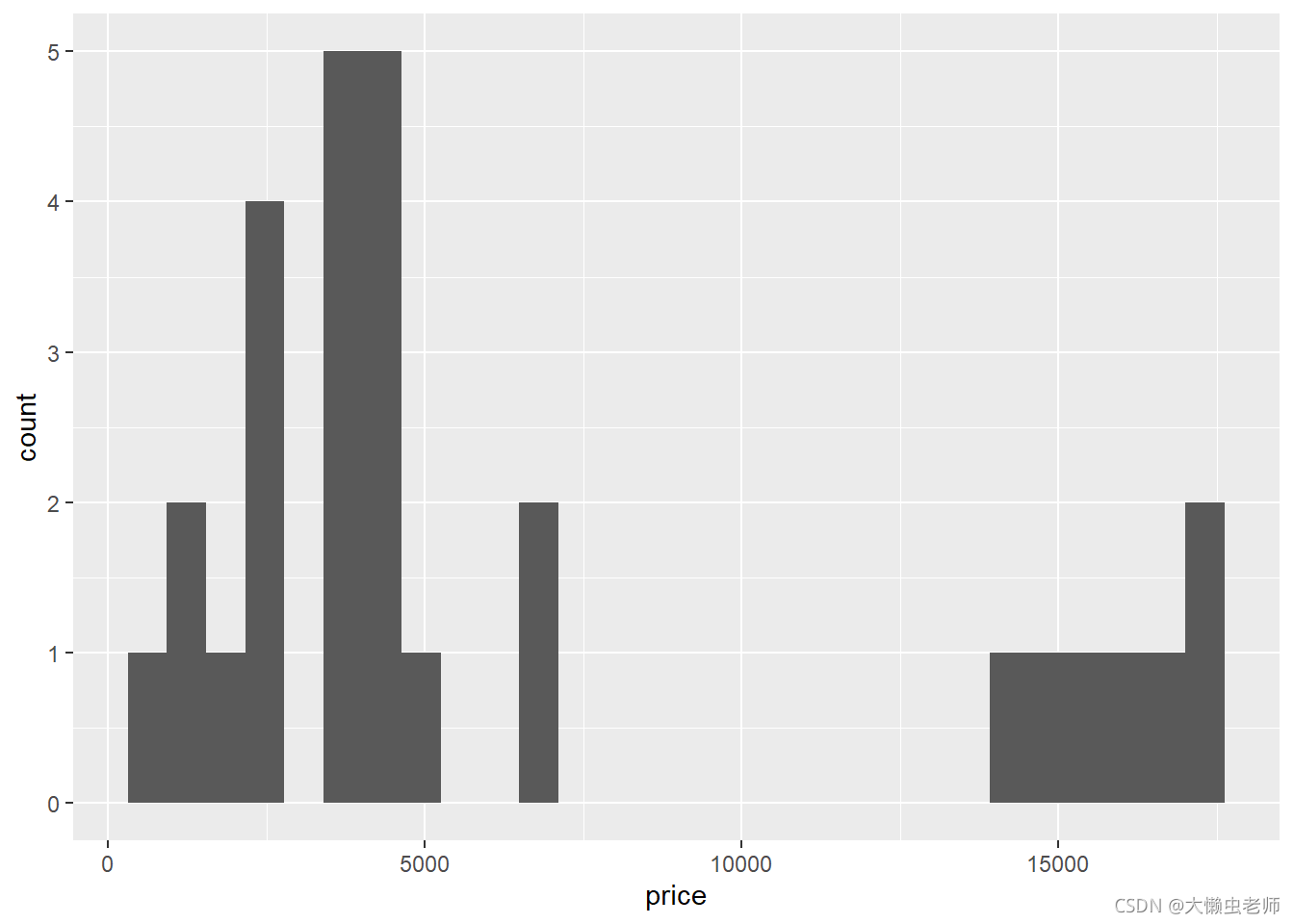
计算理想切割、颜色和清晰度最好的钻石的平均价格、价格中位数、最高价和最低价,可知平均价格为
6567
6567
6567左右,价格中位数在
4184
4184
4184左右,最高价为
17590
17590
17590,最低价为
893
893
893。
可知虽然都是理想切割、颜色和清晰度最好的钻石,但是其价格的差异较大,钻石的价格并不只和切割状态、颜色和清晰度有关。
钻石各属性与价格的关系
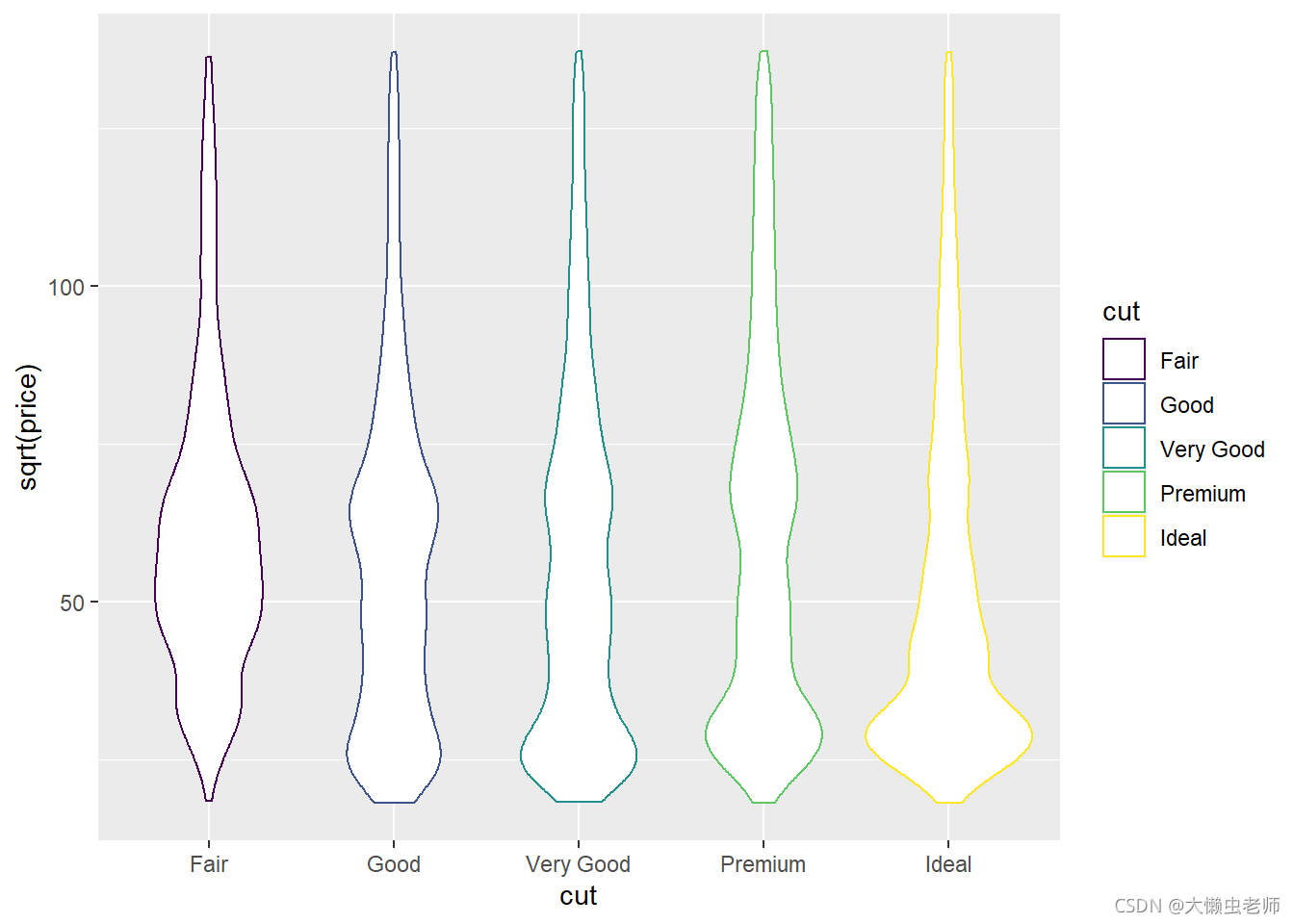
绘制钻石切割状态与价格的小提琴图,此处价格取开方值,便于观察各组之间的不同。
与普遍认知不同,在此数据集中,理想切割的钻石,仍有很大一部分价格处于较低的水平。
ggplot(data)+
geom_violin(aes(x=cut,y=sqrt(price),color=cut))
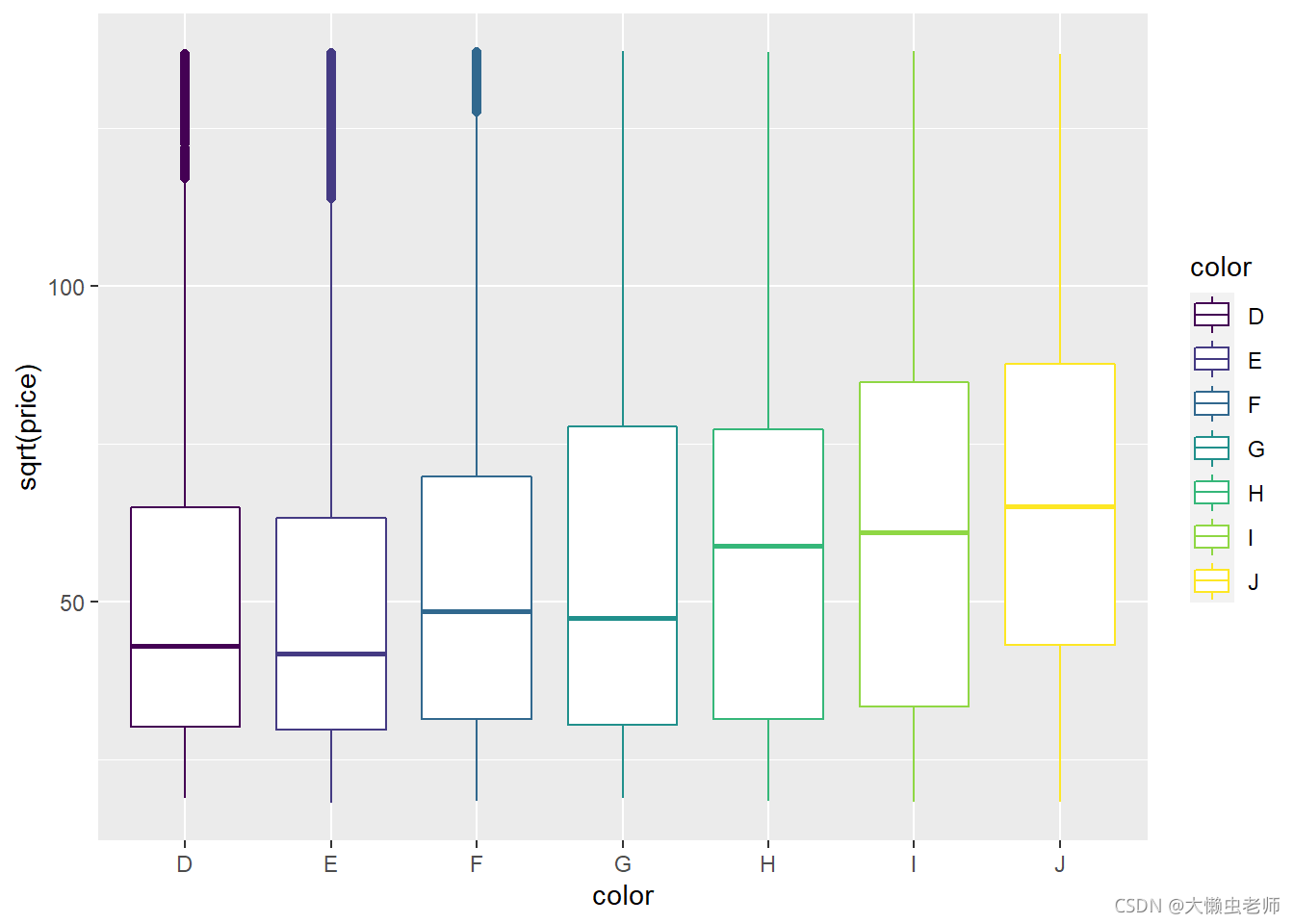
绘制钻石颜色与价格的箱线图,此处价格取开方值,便于观察各组之间的不同。
可知,随着颜色从差到好,钻石的价格基本处于上升的趋势。
ggplot(data)+
geom_boxplot(aes(x=color,y=sqrt(price),color=color))
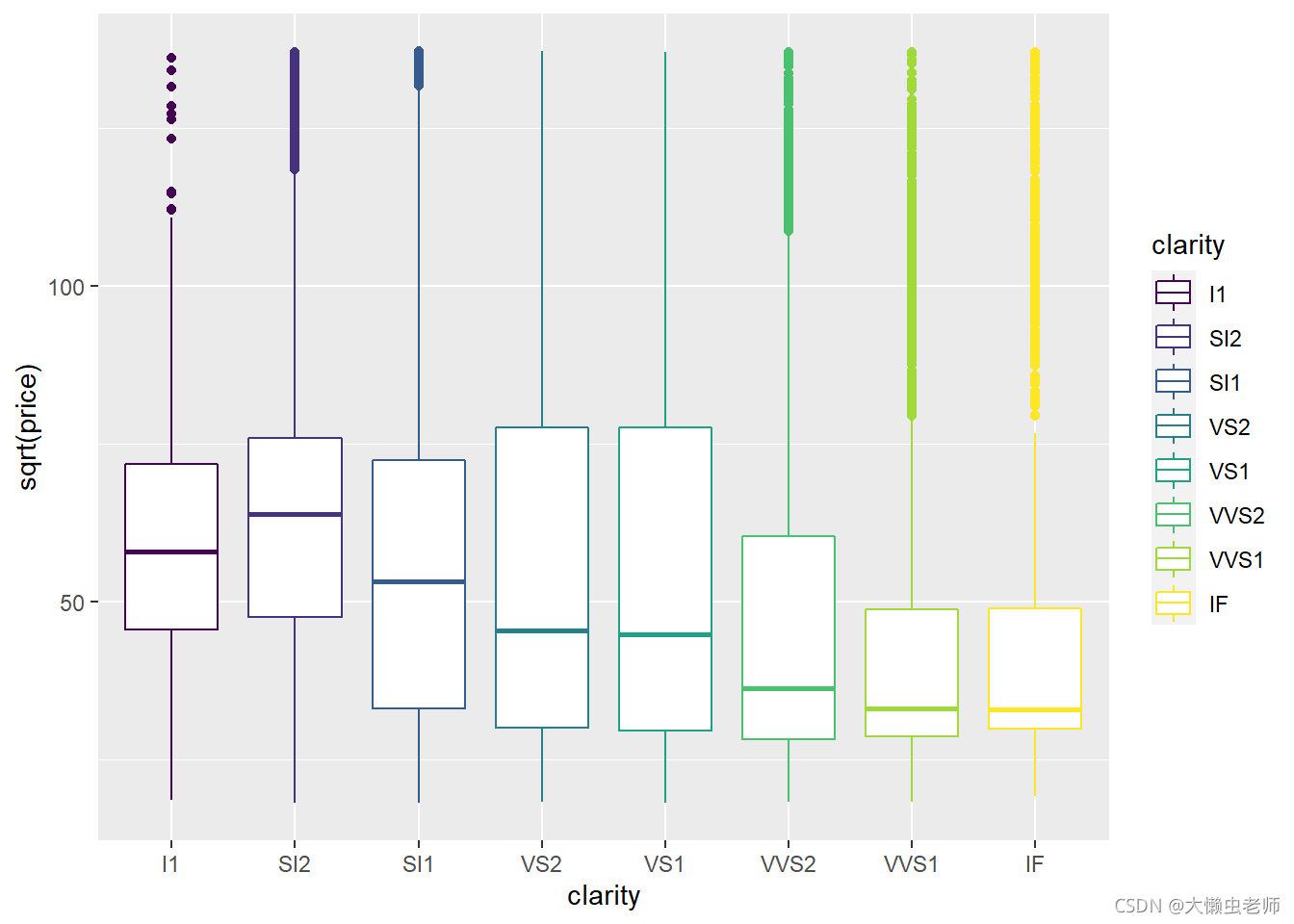
绘制钻石透明度与价格的箱线图,此处价格取开方值,便于观察各组之间的不同。
可知,随着透明度从差到好,钻石的价格基本处于上升的趋势。其中透明度I1比SI2高,但是价格中位数却不如其高。说明透明度到达优质的状态后,区分钻石价格的维度更多。钻石价格受到各个状态的影响,并不是其中某一特质就能使其价格到达最高。
ggplot(data)+
geom_boxplot(aes(x=clarity,y=sqrt(price),color=clarity))
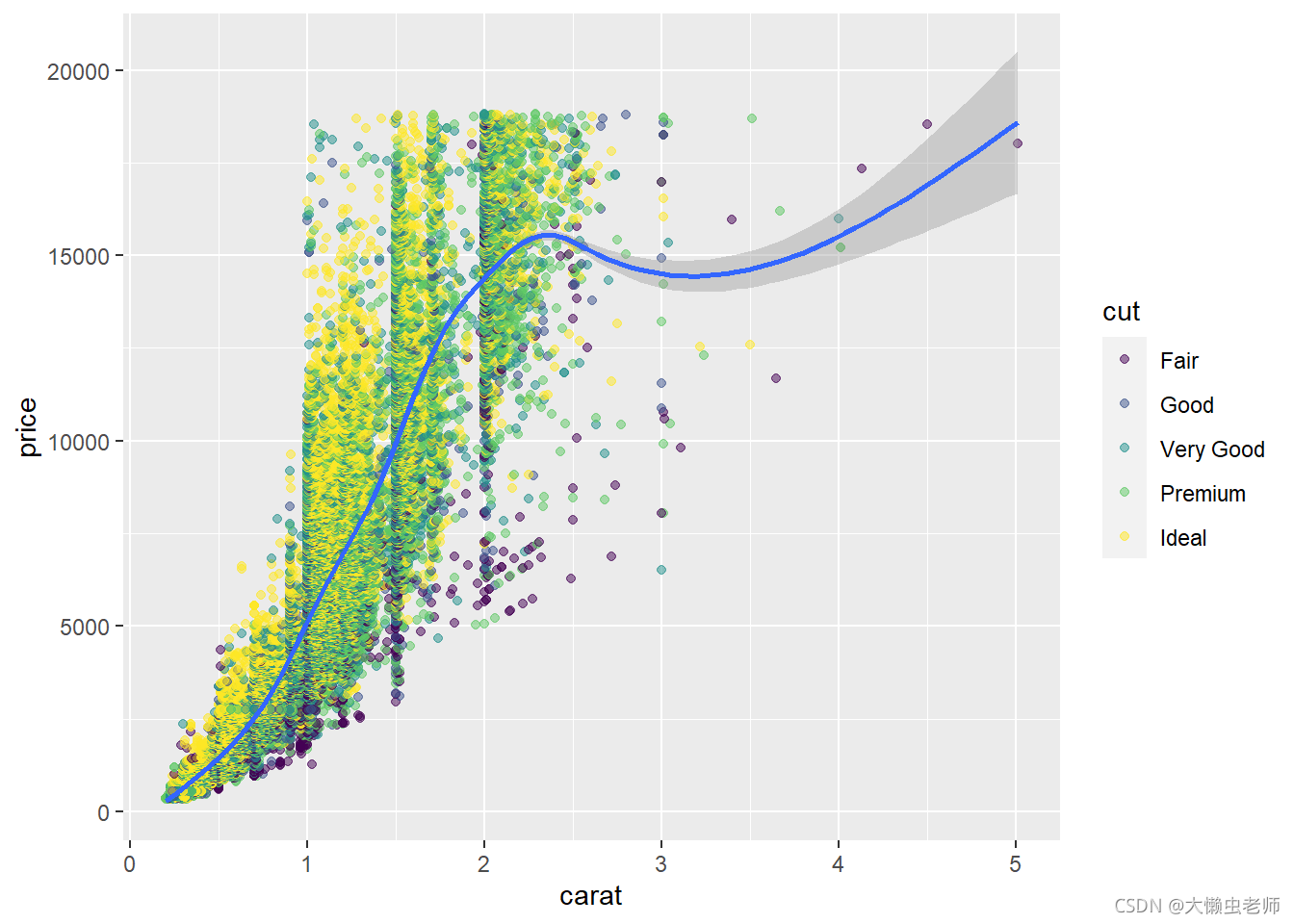
#### carat
ggplot(data)+
geom_point(aes(x=carat,y=price,color=cut),alpha=0.5)+
geom_smooth(aes(x=carat,y=price))
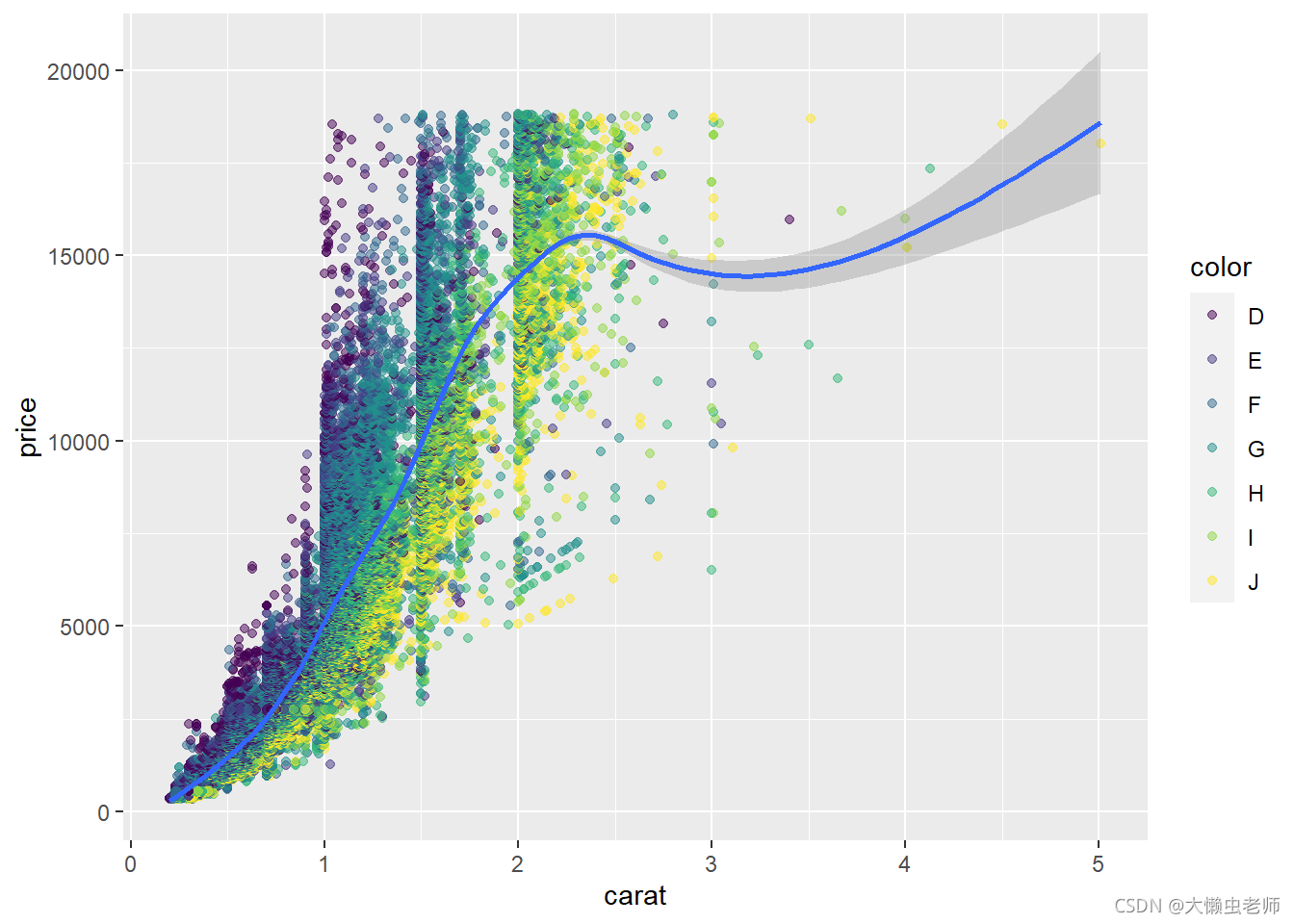
ggplot(data)+
geom_point(aes(x=carat,y=price,color=color),alpha=0.5)+
geom_smooth(aes(x=carat,y=price))
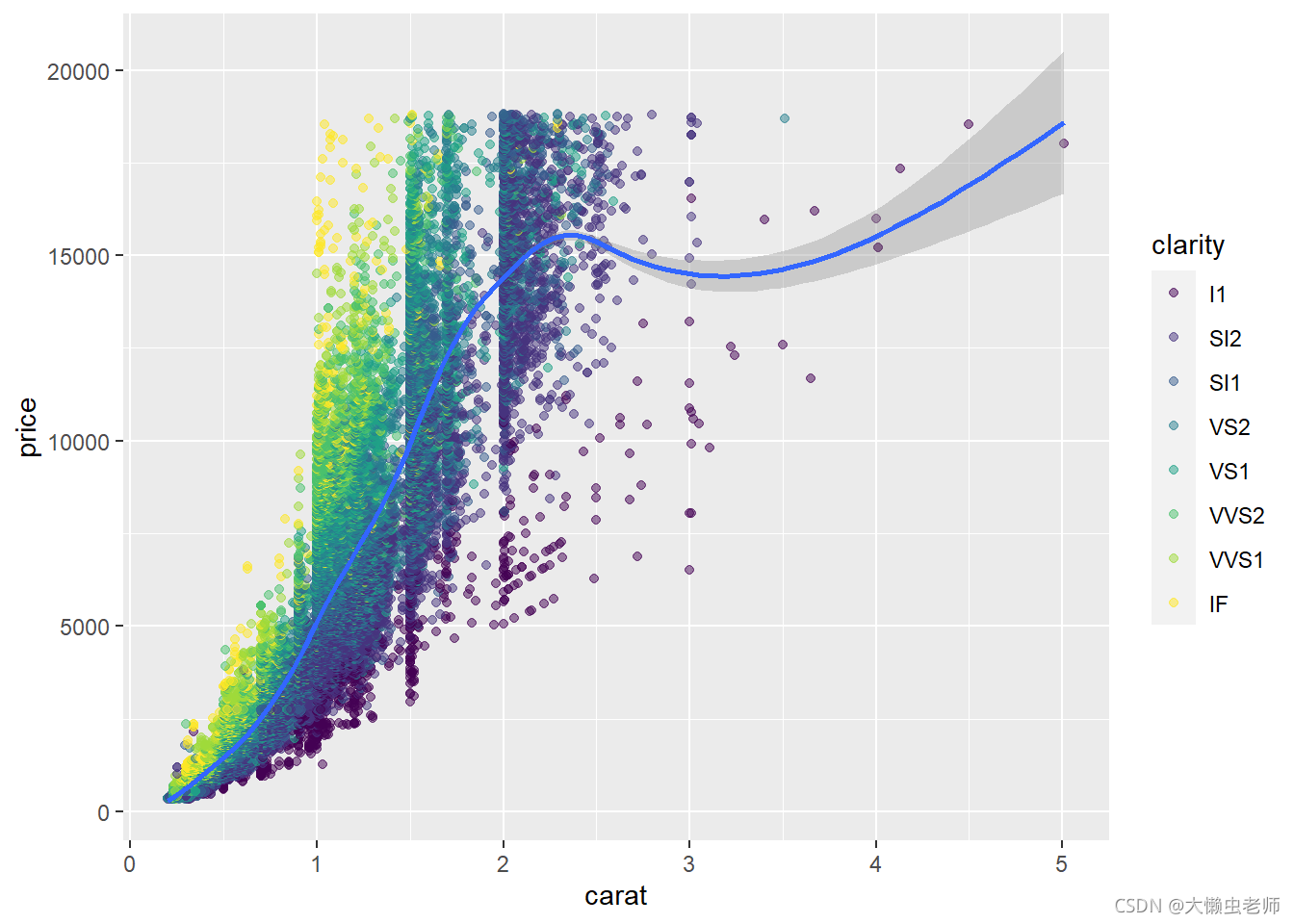
ggplot(data)+
geom_point(aes(x=carat,y=price,color=clarity),alpha=0.5)+
geom_smooth(aes(x=carat,y=price))
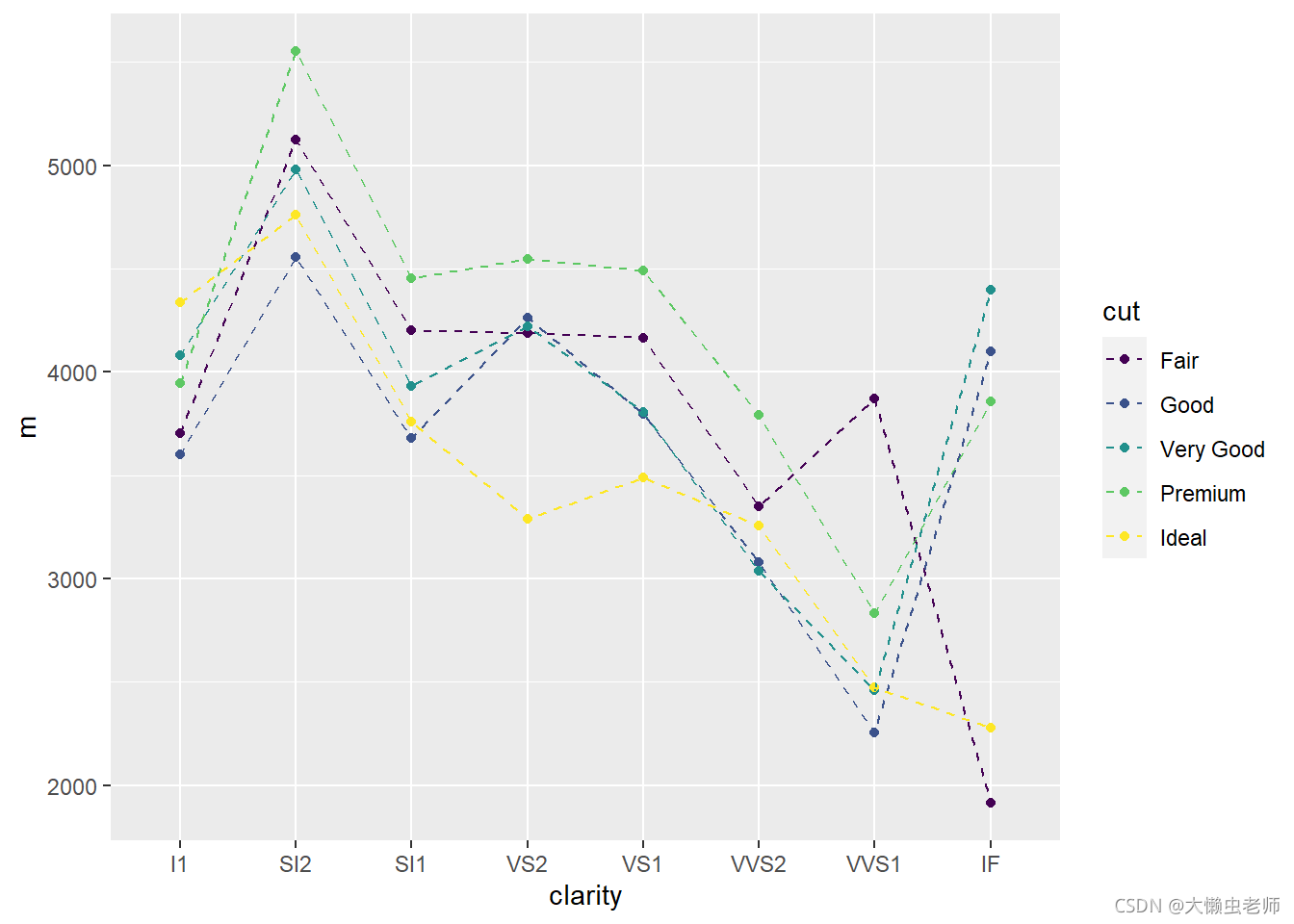
data %>%
group_by(clarity, cut) %>%
summarize(m = mean(price)) %>%
ggplot(aes(x = clarity, y = m, group = cut, color = cut)) +
geom_point() +
geom_line(linetype = 2)
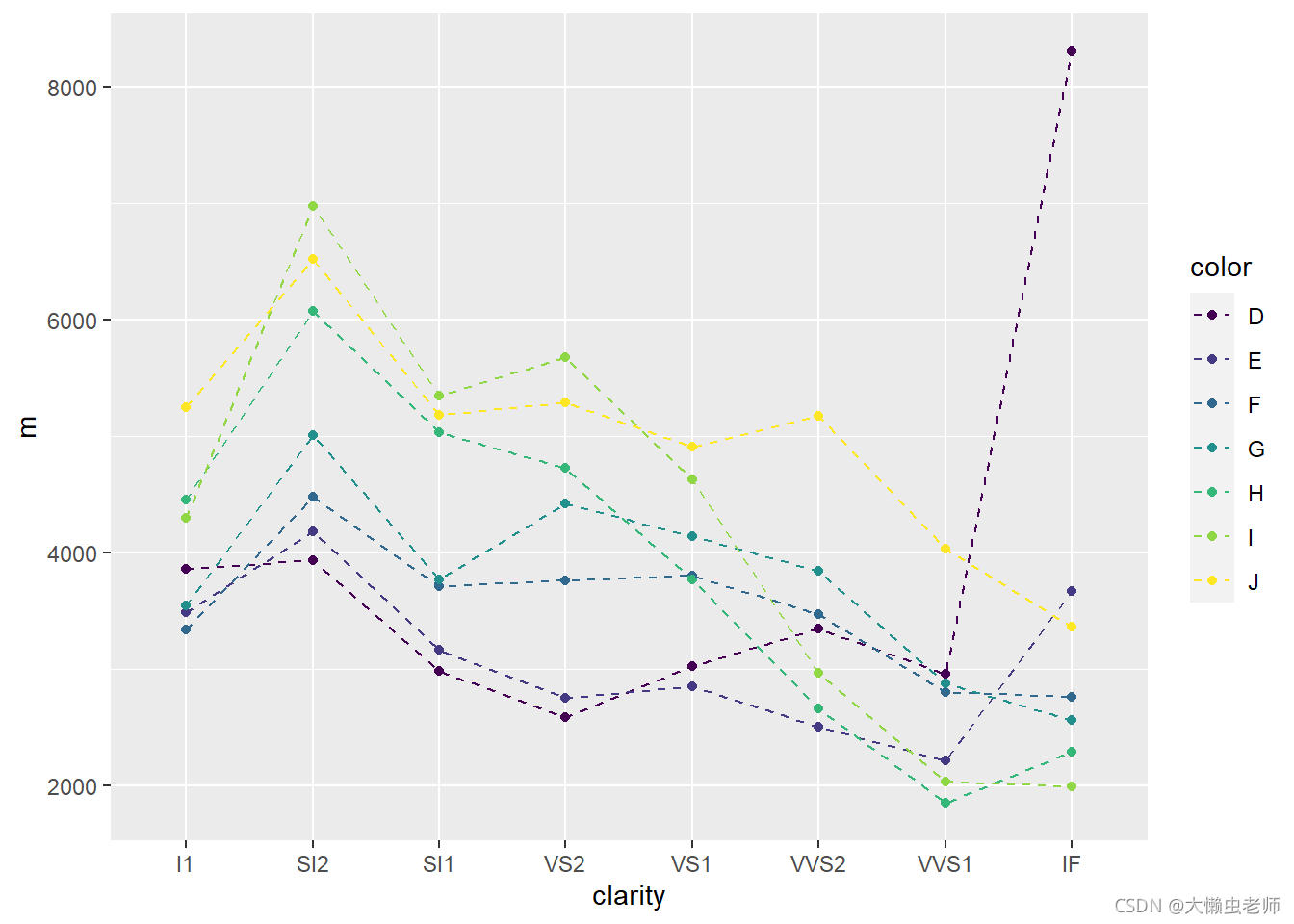
data %>%
group_by(clarity, color) %>%
summarize(m = mean(price)) %>%
ggplot(aes(x = clarity, y = m, group = color, color = color)) +
geom_point() +
geom_line(linetype = 2)
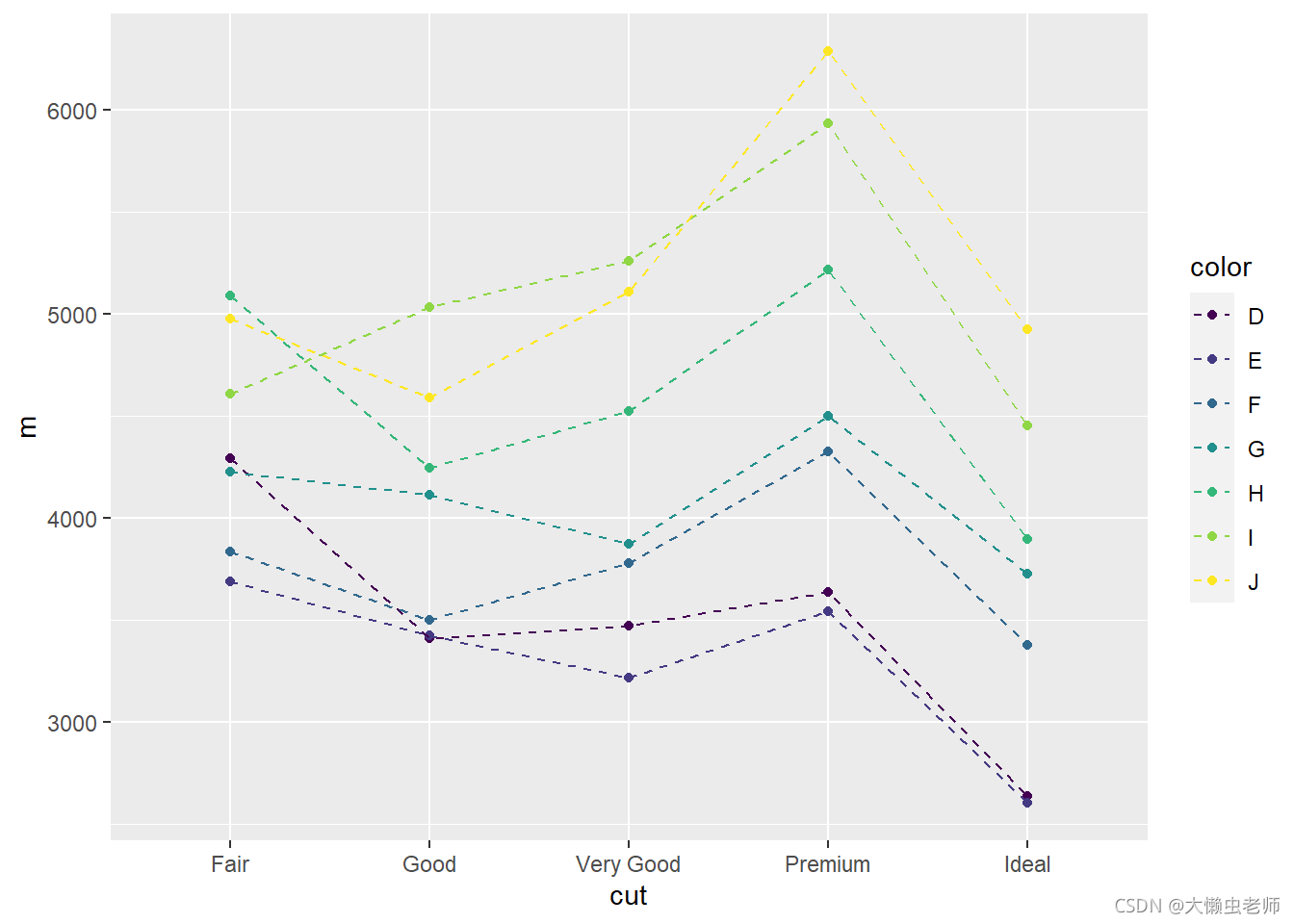
data %>%
group_by(cut, color) %>%
summarize(m = mean(price)) %>%
ggplot(aes(x = cut, y = m, group = color, color = color)) +
geom_point() +
geom_line(linetype = 2)
整体价格分布情况
ggplot(data)+
geom_histogram(aes(x=price,y=..density..),fill="#247BA0",binwidth=300)+
geom_density(aes(x=price),size=1,alpha=.5,ajust=4,col='grey',fill='grey')
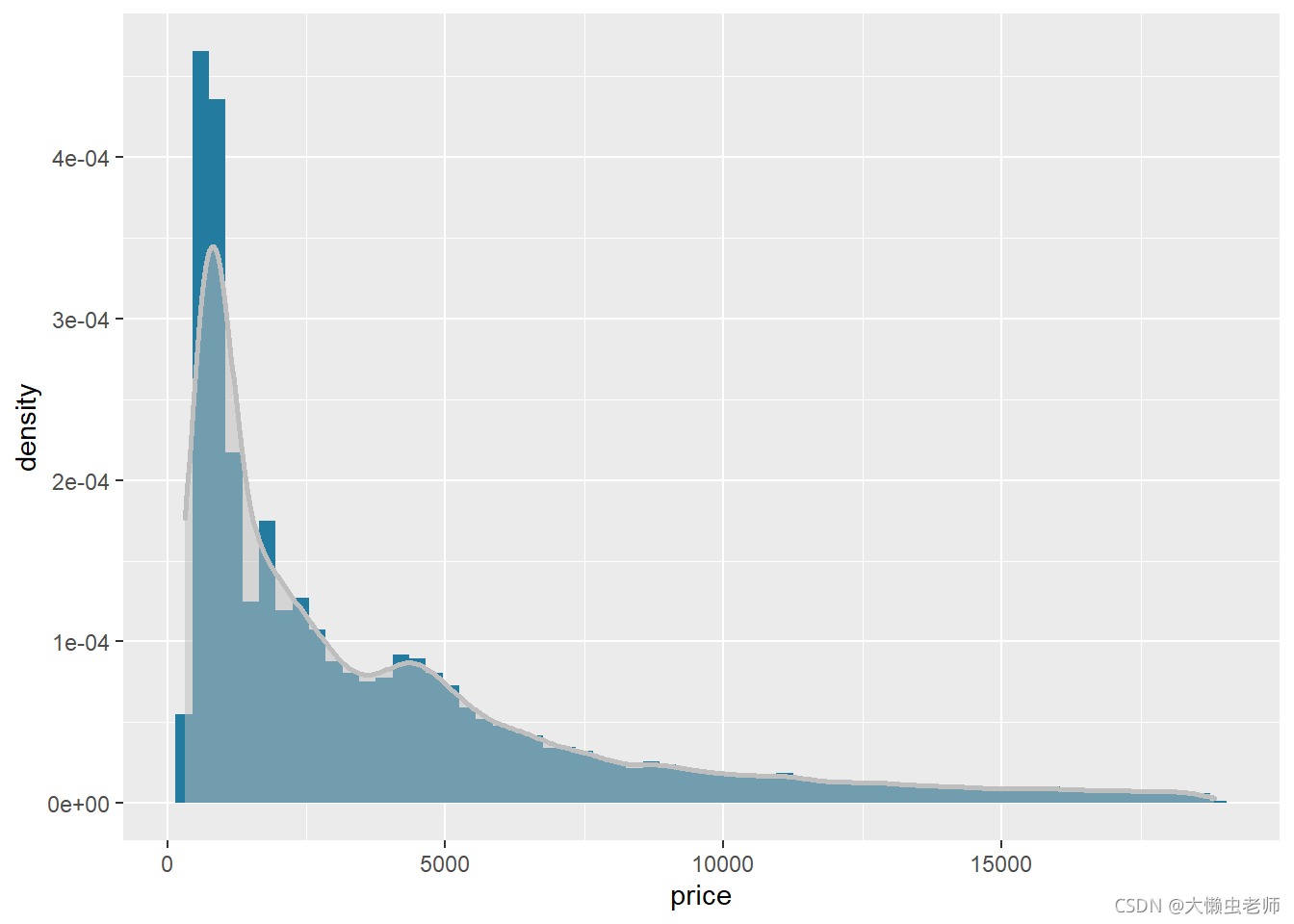
如图可知,价格在0-5000的钻石占绝大多数。随着价格越来越高,钻石的数量越来越少。
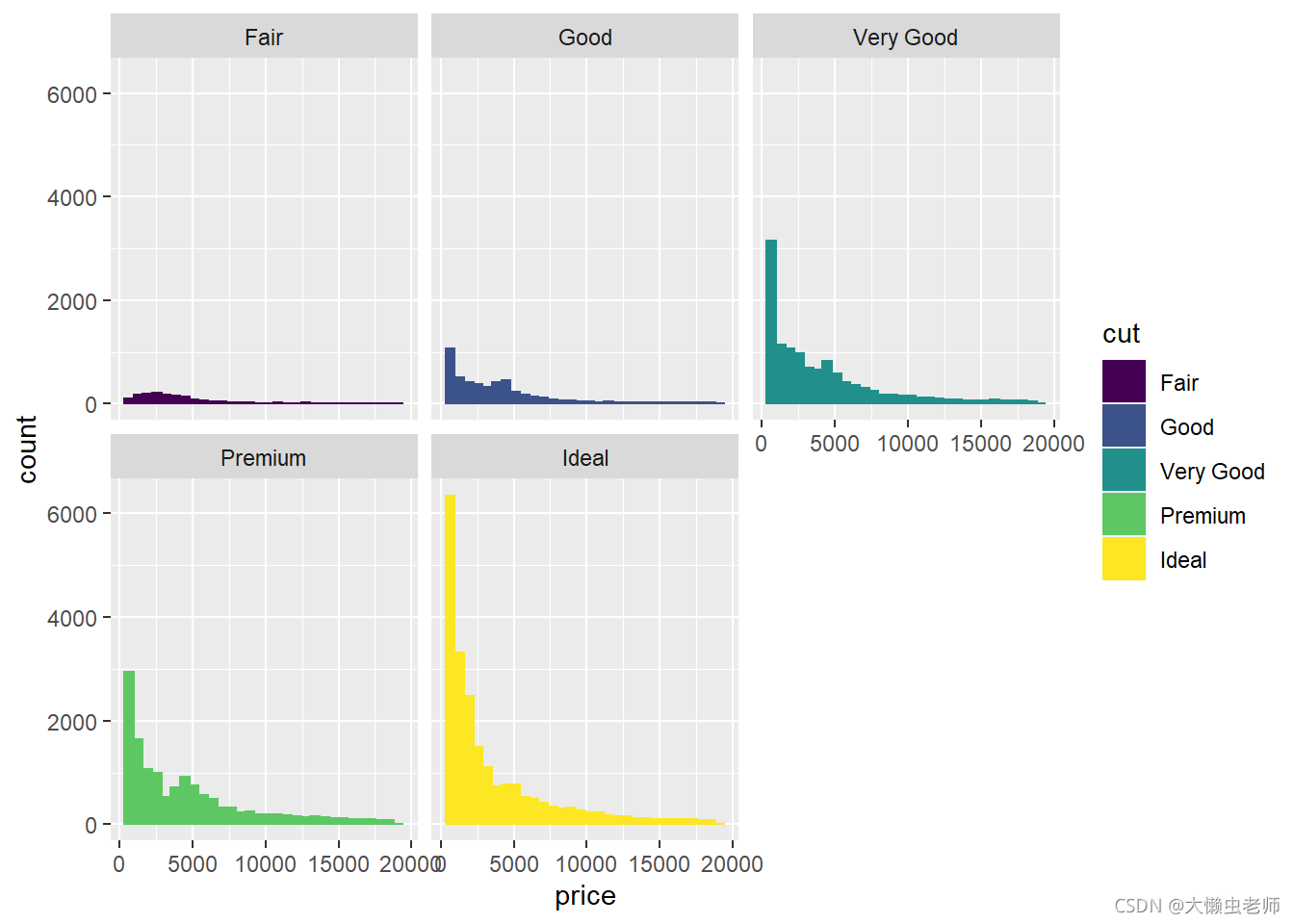
不同切割状态钻石的价格分布
ggplot(data)+
geom_histogram(aes(x=price,fill=cut,color=cut))+
facet_wrap(~cut)
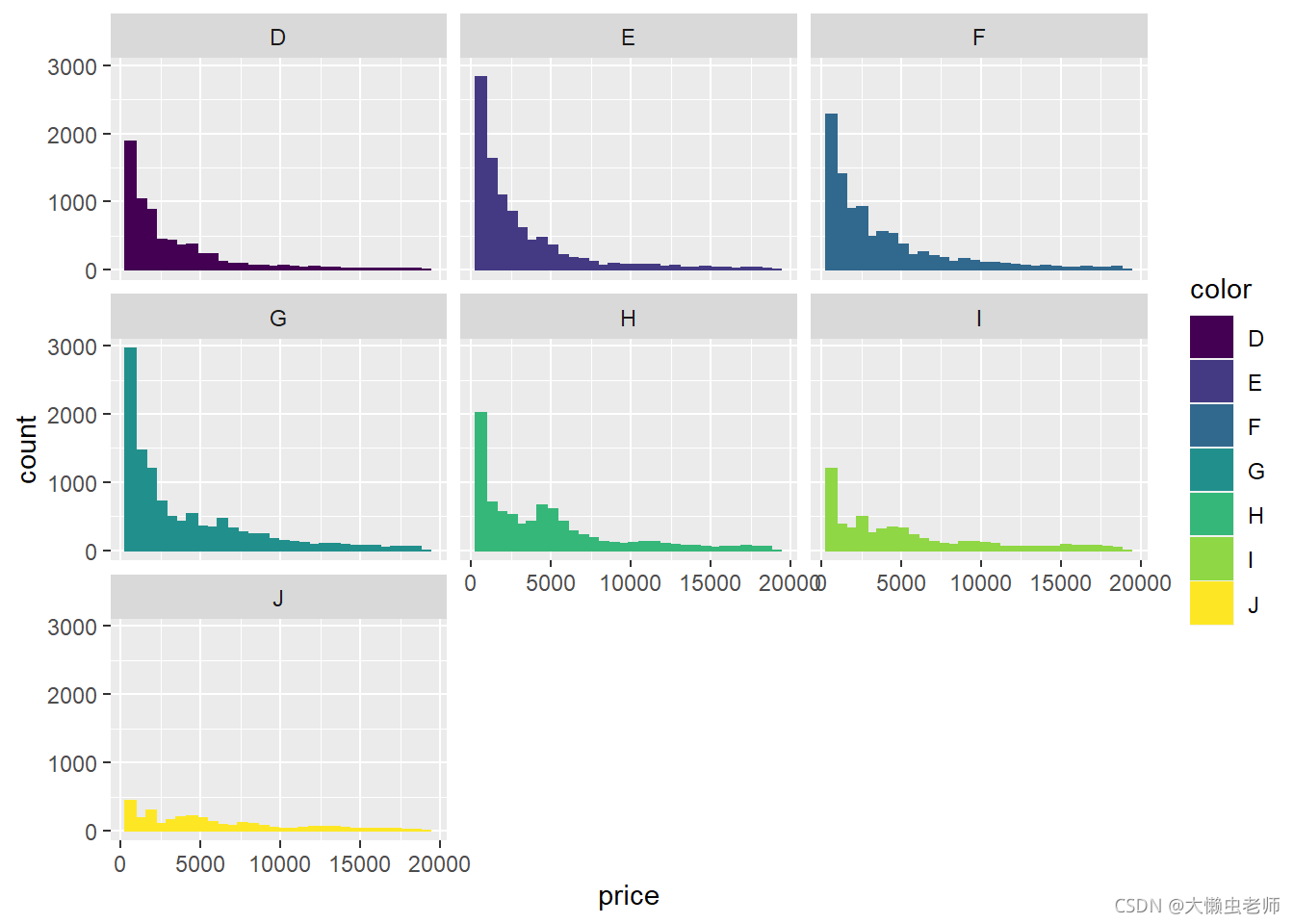
不同颜色钻石的价格分布
ggplot(data)+
geom_histogram(aes(x=price,fill=color,color=color))+
facet_wrap(~color)
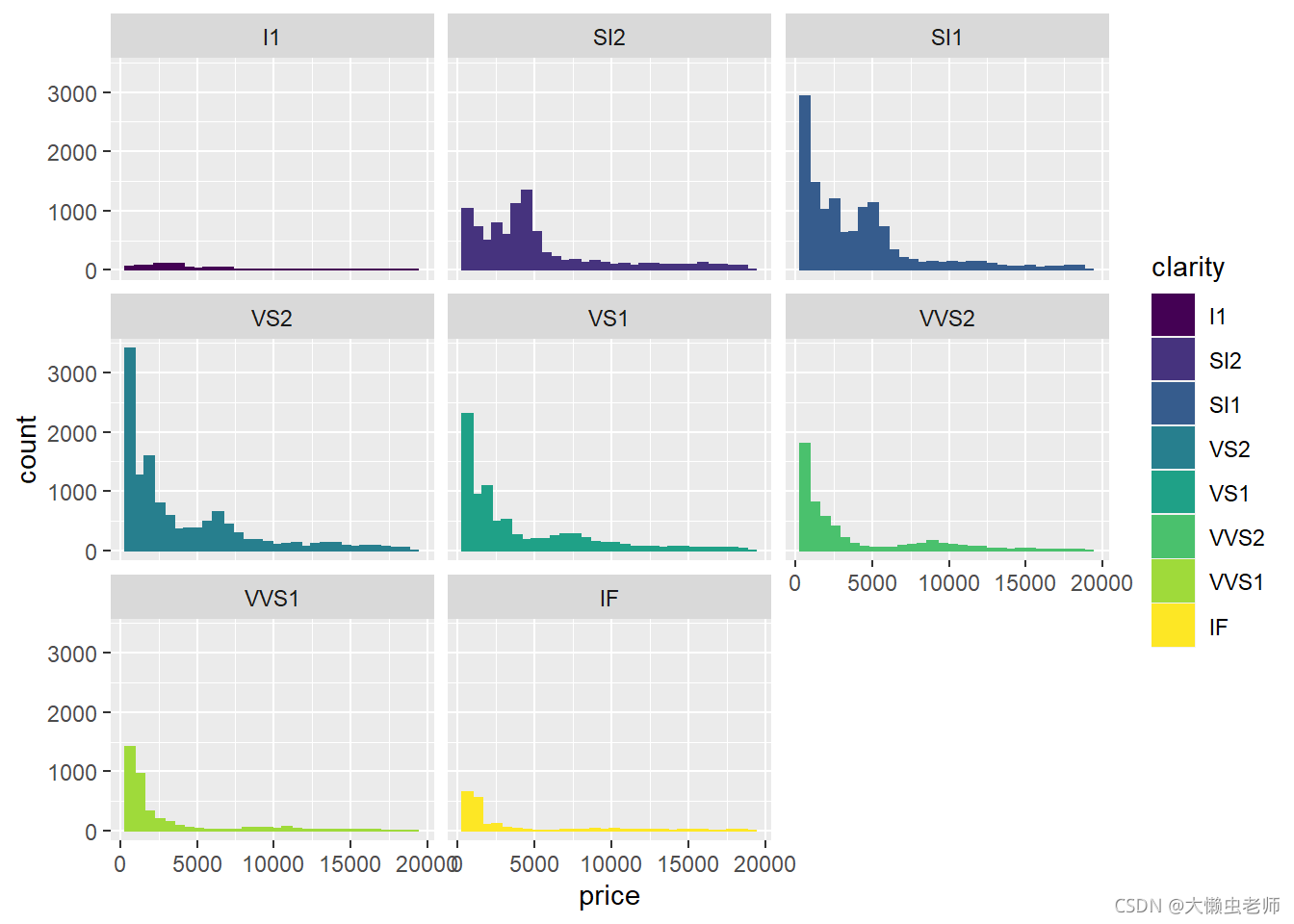
不同透明度的价格分布
ggplot(data)+
geom_histogram(aes(x=price,fill=clarity,color=clarity))+
facet_wrap(~clarity)
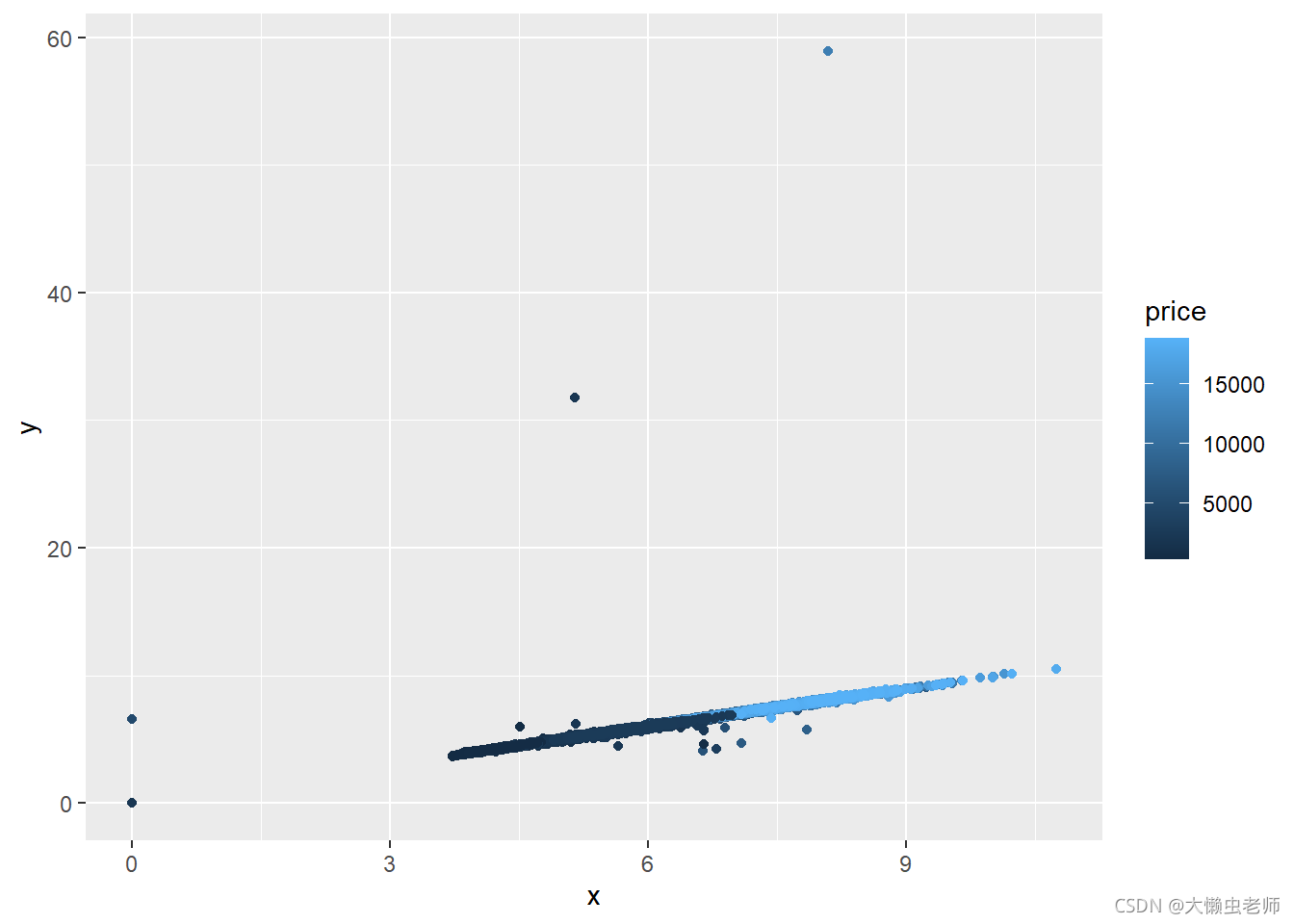
钻石长宽深与价格之间的关系
ggplot(data)+
geom_point(aes(x=x,y=y,col=price))
ggplot(data)+
geom_point(aes(x=x,y=z,col=price))
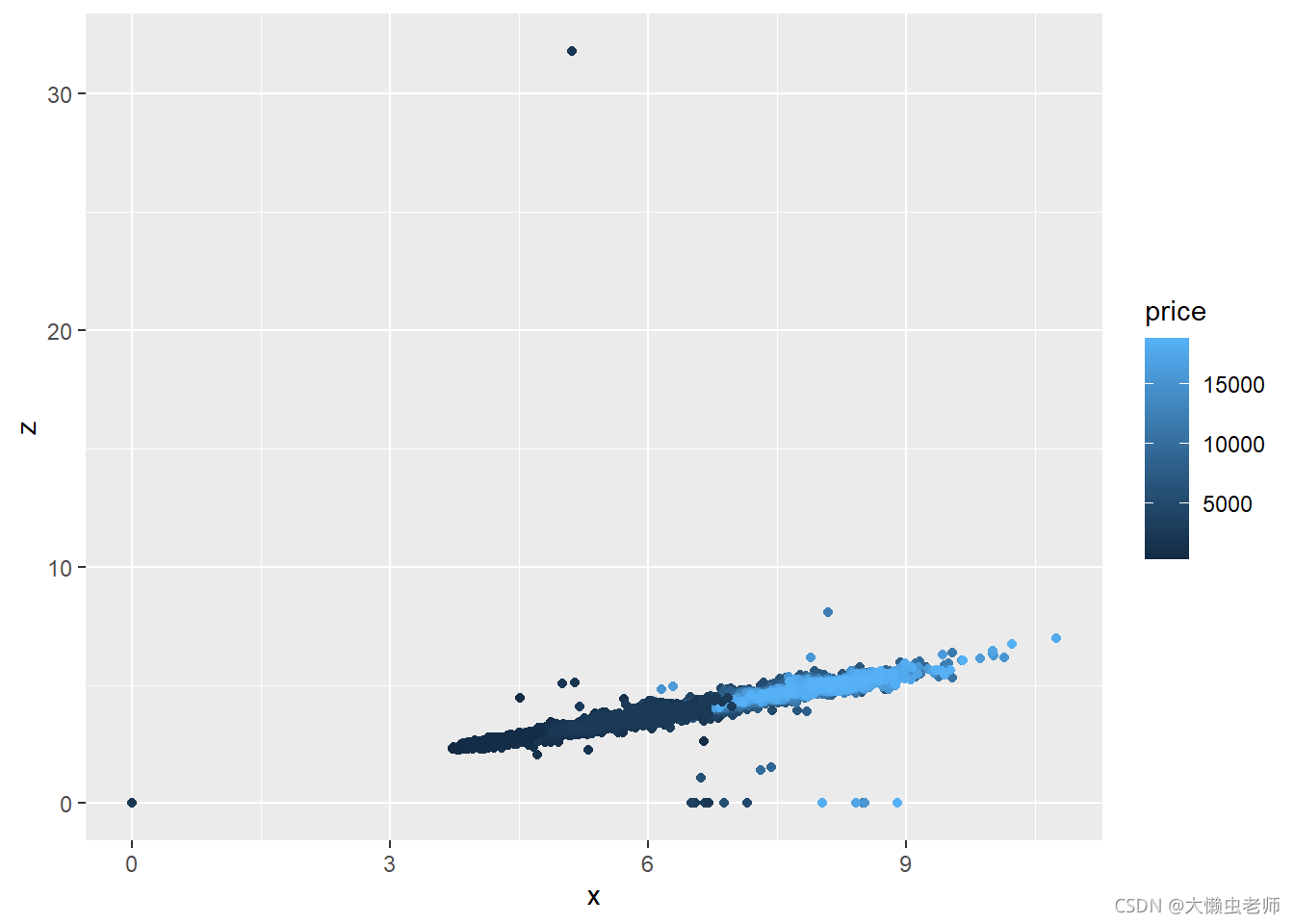
ggplot(data)+
geom_point(aes(x=y,y=z,col=price))
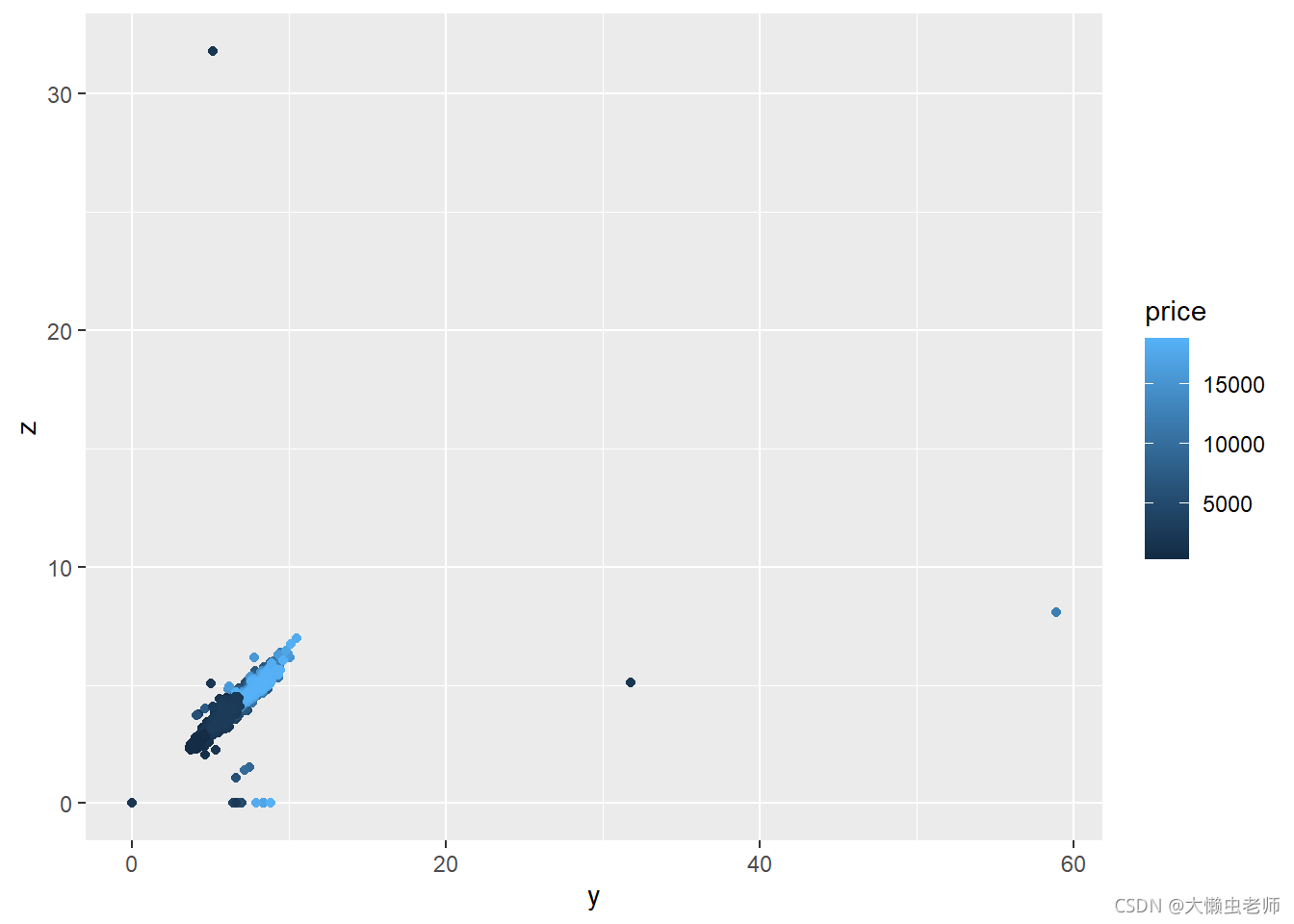
如图可知,外形越大(长、宽、深数值越大)的钻石,价格越高。说明钻石价格和外形大小有关联。
不同切割类型的钻石,价格是否具有显著性差异?
选择非参数检验的方式,分析不同切割类型的钻石,价格是否具有显著性差异。
首先,分组计算价格的均值。可知不同切割类型的钻石价格的中位数不同。
data %>%
group_by(cut) %>%
summarise(
count = n(),
price_average = mean(price),
price_sd = sd(price))
## # A tibble: 5 x 4
## cut count price_average price_sd
## <ord> <int> <dbl> <dbl>
## 1 Fair 1598 4342. 3540.
## 2 Good 4891 3919. 3671.
## 3 Very Good 12069 3981. 3935.
## 4 Premium 13748 4584. 4348.
## 5 Ideal 21488 3463. 3811.
价格分布的正态性检验
对各组切割类型的钻石作正态性检验。画图可知,各组的分布并不完全相同。因此,选择非参数检验。
ggplot(data)+
geom_histogram(aes(price))+
facet_wrap(~cut)
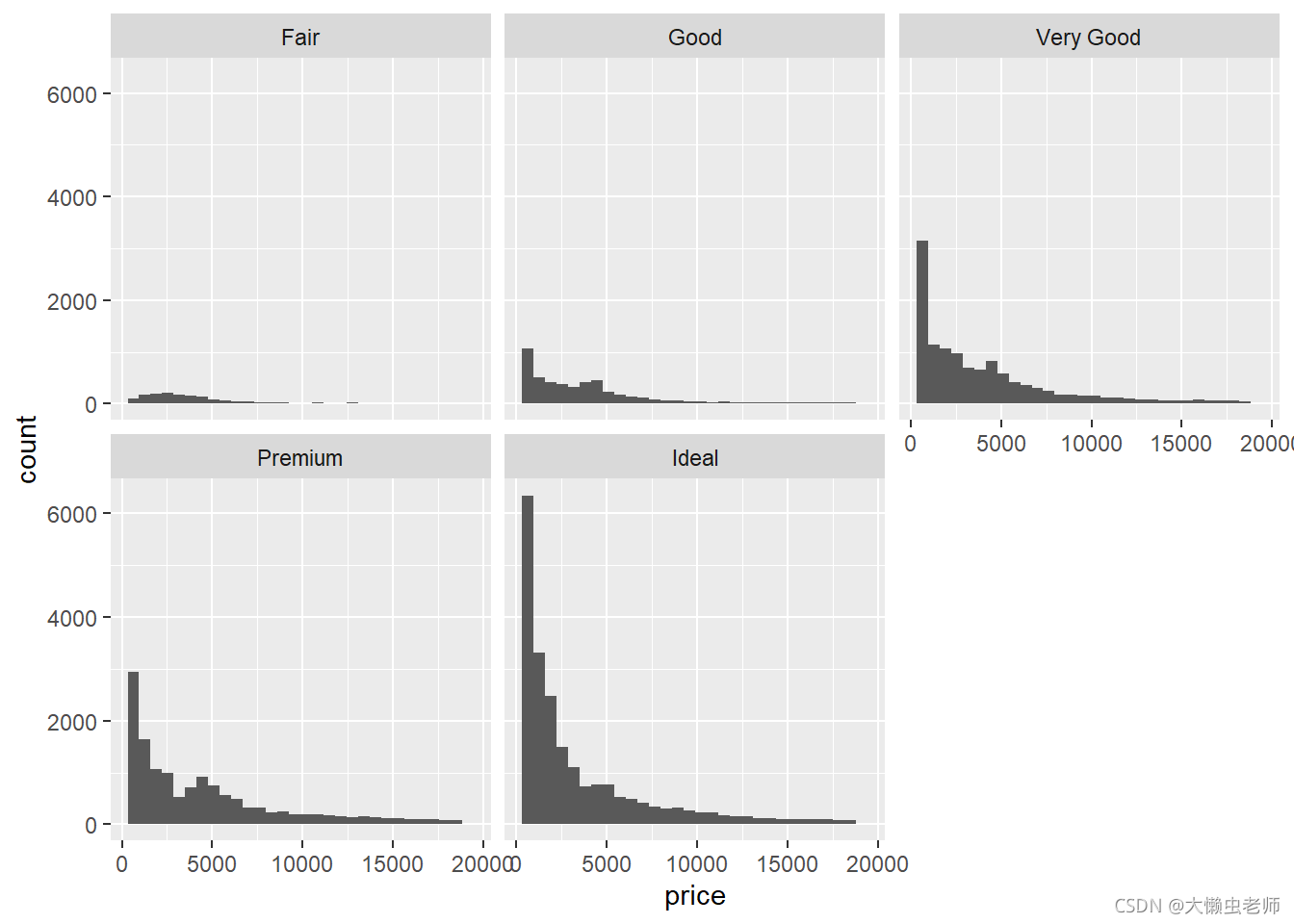
非参数检验
kruskal.test(price ~ cut, data = data)
data %>%
ggstatsplot::ggbetweenstats(
x = cut,
y = price,
type = "nonparametric",
mean.ci = TRUE,
pairwise.comparisons = TRUE,
pairwise.display = "all",
p.adjust.method = "fdr",
messages = FALSE
)

p-value 很小,说明不同切割水平的钻石之间价格是有显著差异的。由非参数检验可知,不同切割类型的钻石,价格具有显著性差异。
同理,对不同颜色的钻石、不同透明度的钻石,做非参数检验,分析其价格是否具有显著性差异。
不同颜色的钻石,价格是否具有显著性差异?
kruskal.test(price ~ color, data = data)
##
## Kruskal-Wallis rank sum test
##
## data: price by color
## Kruskal-Wallis chi-squared = 1325.6, df = 6, p-value < 2.2e-16
可知,p-value 很小,说明不同颜色的钻石之间价格是有显著差异的。
不同透明度的钻石,价格是否具有显著性差异?
kruskal.test(price ~ clarity, data = data)
##
## Kruskal-Wallis rank sum test
##
## data: price by clarity
## Kruskal-Wallis chi-squared = 2696.9, df = 7, p-value < 2.2e-16
可知,p-value 很小,说明不同透明度的钻石之间价格是有显著差异的。
建立模型
建立多元线性模型,利用钻石的各项属性对钻石的价格进行预测。
准备数据
首先,将数据集中价格变量取对数。划分学习数据集和测试数据集,进行数据标准化。
在53794条数据中,划分40000作为学习数据集,命名为train,剩下的作为测试数据集,命名为test。
多元线性模型
建立多元线性模型,响应变量为price,预测变量为数据集中除price之外其他变量。绘制模型检测图。
利用学习数据集拟合模型,利用测试数据集对钻石价格进行预测。
自定义函数RMSE,用于计算均方误差。计算得知,均方误差为
0.2606446
0.2606446
0.2606446。
data$price <- log(data$price)
set.seed(1)
pre <- sort(sample(53794,40000))
train <- data[pre,]
test <- data[-pre,]
m1 <- lm(price ~., data = train)
m1_pre <- predict(m1,test)
plot(m1)
RMSE=function(t,p){
return(sqrt(mean((t-p)^2)))
}
RMSE(test$price,m1_pre)
## [1] 0.3760066
讨论
总结
本文对diamonds数据集进行探索性分析,并做数据可视化处理,探索钻石的价格、重量分布,及钻石价格与重量、形状、切割状态、颜色、透明度之间的关系。接下来,进行非参数检验,探究不同切割类型、颜色和透明度的钻石,价格是否具有显著性差异。最后,利用钻石的各项属性,建立多元线性模型,对钻石的价格进行预测。
由探索性分析可知,
-
在钻石的重量分布上, 0 − 0.5 0-0.5 0−0.5克拉的钻石最多,超过 1.5 1.5 1.5克拉以上的钻石逐渐变少。
-
在钻石透明度上,I1(最差) ,SI2,SI1,VS2,VS1,VS2,VS1,IF (最好)。观察其统计数据,发现钻石透明度一般的占比最高,钻石透明度最差和最好的比例都比较低。
-
理想切割及优质切割的钻石占比超过一半以上。联系现实原因而言,因为钻石为奢侈品,切割水平高可以使钻石达到更好的视觉效果。所以理想切割及优质切割的钻石占比较高。
-
钻石总深度百分比及顶部相对于最宽点的宽度均符合正态分布。
改进方向
本文建立了预测钻石价格的多元线性模型,响应变量为price,预测变量为数据集中除price之外其他变量,模型均方误差为 0.2606446 0.2606446 0.2606446(价格已取对数)。下一步可考虑使用交叉验证对模型参数进行调整,取最优方案对钻石价格进行预测。
代码
library(readr)
library(dplyr)
library(kknn)
library(TTR)
library(AER)
library(pROC)
library(e1071)
library(nnet)
library(rpart)
library(tidyverse)
library(memisc)
data <- diamonds
head(data)
str(data)
names(data)
data %>% summarise(
across(everything(), ~ sum(is.na(.)))
)
data <- data %>%
distinct()
data %>%
summarise(depth_median=median(depth),
table_median=median(table))
par(mfrow=c(1,2))
hist(data$depth,breaks = 40)
hist(data$table,breaks = 20)
ggplot(data)+
geom_histogram(aes(x=carat),binwidth=0.1)
data %>%
count(cut, sort = T)
pie(table(data$cut),labels=names(table(data$cut)))
data %>%
count(color, sort = T)
pie(table(data$color),labels=names(table(data$color)))
data %>%
count(clarity, sort = T)
pie(table(data$clarity),labels=names(table(data$clarity)))
data %>%
arrange(desc(price)) %>%
slice_max(price, n = 10)
data %>%
filter(cut=='Ideal',color=='D',clarity=='IF') %>%
summarise(average_price=mean(price),
median_price=median(price),
max_price=max(price),
min_price=min(price)
)
ggplot(data %>%
filter(cut=='Ideal',color=='D',clarity=='IF'))+
geom_histogram(aes(x=price),bins=28)
ggplot(data)+
geom_violin(aes(x=cut,y=sqrt(price),color=cut))
ggplot(data)+
geom_boxplot(aes(x=color,y=sqrt(price),color=color))
ggplot(data)+
geom_boxplot(aes(x=clarity,y=sqrt(price),color=clarity))
#### carat
ggplot(data)+
geom_point(aes(x=carat,y=price,color=cut),alpha=0.5)+
geom_smooth(aes(x=carat,y=price))
ggplot(data)+
geom_point(aes(x=carat,y=price,color=color),alpha=0.5)+
geom_smooth(aes(x=carat,y=price))
ggplot(data)+
geom_point(aes(x=carat,y=price,color=clarity),alpha=0.5)+
geom_smooth(aes(x=carat,y=price))
data %>%
group_by(clarity, cut) %>%
summarize(m = mean(price)) %>%
ggplot(aes(x = clarity, y = m, group = cut, color = cut)) +
geom_point() +
geom_line(linetype = 2)
data %>%
group_by(clarity, color) %>%
summarize(m = mean(price)) %>%
ggplot(aes(x = clarity, y = m, group = color, color = color)) +
geom_point() +
geom_line(linetype = 2)
data %>%
group_by(cut, color) %>%
summarize(m = mean(price)) %>%
ggplot(aes(x = cut, y = m, group = color, color = color)) +
geom_point() +
geom_line(linetype = 2)
ggplot(data)+
geom_histogram(aes(x=price,y=..density..),fill="#247BA0",binwidth=300)+
geom_density(aes(x=price),size=1,alpha=.5,ajust=4,col='grey',fill='grey')
ggplot(data)+
geom_histogram(aes(x=price,fill=cut,color=cut))+
facet_wrap(~cut)
ggplot(data)+
geom_histogram(aes(x=price,fill=color,color=color))+
facet_wrap(~color)
ggplot(data)+
geom_histogram(aes(x=price,fill=clarity,color=clarity))+
facet_wrap(~clarity)
ggplot(data)+
geom_point(aes(x=x,y=y,col=price))
ggplot(data)+
geom_point(aes(x=x,y=z,col=price))
ggplot(data)+
geom_point(aes(x=y,y=z,col=price))
data %>%
group_by(cut) %>%
summarise(
count = n(),
price_average = mean(price),
price_sd = sd(price))
ggplot(data)+
geom_histogram(aes(price))+
facet_wrap(~cut)
kruskal.test(price ~ cut, data = data)
data %>%
ggstatsplot::ggbetweenstats(
x = cut,
y = price,
type = "nonparametric",
mean.ci = TRUE,
pairwise.comparisons = TRUE,
pairwise.display = "all",
p.adjust.method = "fdr",
messages = FALSE
)
kruskal.test(price ~ color, data = data)
kruskal.test(price ~ clarity, data = data)
data$price <- log(data$price)
set.seed(1)
pre <- sort(sample(53794,40000))
train <- data[pre,]
test <- data[-pre,]
m1 <- lm(price ~., data = train)
m1_pre <- predict(m1,test)
plot(m1)
RMSE=function(t,p){
return(sqrt(mean((t-p)^2)))
}
RMSE(test$price,m1_pre)

















 1114
1114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









