







多线程爬取免费代理ip池 (给我爬)
天网恢恢疏而不漏,有时候爬太多数据的时候会把自己的ip给封掉,所以呢,我左思右想,就想能不能把自己的ip给换掉,换成那种高匿ip,这样的话,就找不到我的真实ip,这样我就可以好好隐藏自己了哈哈哈。 (注意:本博客和代码仅可用于计算机技术学习及数据抓取、爬虫采集等合法行为)
安装的库
首先我们可以打开我们的命令行,输入以下代码安装这些库,这样才能保证我们的结果能够正确运行。
pip install lxml requests pathos
IP 隐藏
在我们用python进行爬虫操作的时候,如何影藏自己的ip地址呢,众所周知,如果我们在我们的百度上直接查询ip地址几个字,我们就可以得到我们自己的ip地址
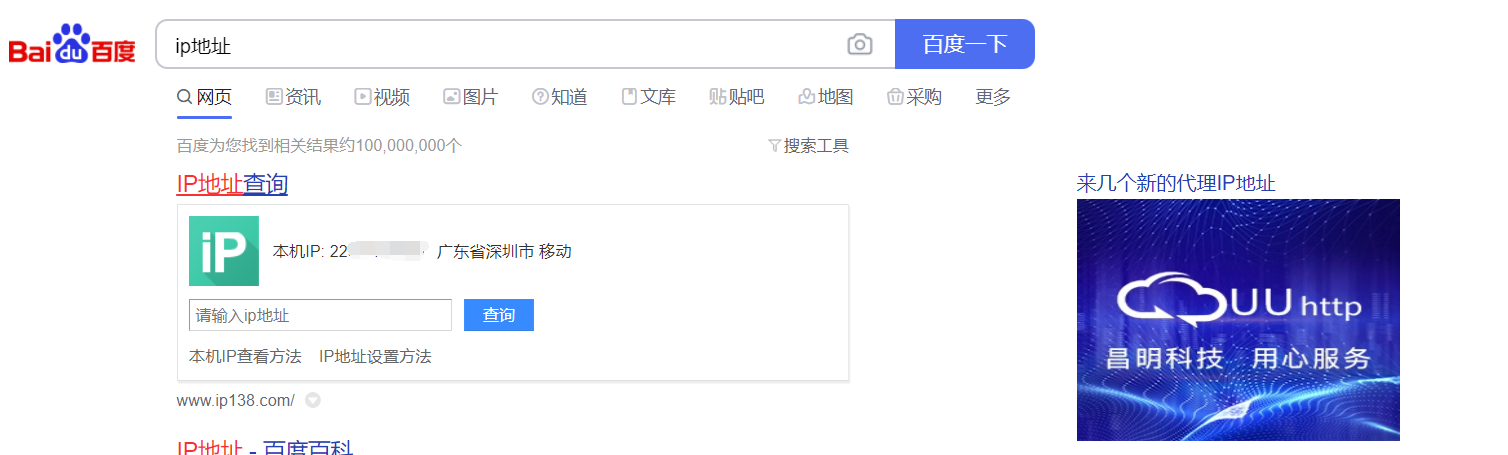
那如何将我们的ip地址改掉呢,其实有很多种方法,我们可以直接就把本机ip改掉,这样的话,他做什么事情我们的ip都被改掉了,当然,我们也可以利用代码进行修改,只需要多加一个参数proxies即可
比如现在我们找到了另一个有效的ip,我拿此来用,我只需要设置我们的proxies参数即可
# 用到的库
import requests
# 写入获取到的ip地址到proxy
proxy = {
'https':'221.178.232.130:8080'
}
# 用百度检测ip代理是否成功
url = 'https://www.baidu.com/s?'
# 请求网页传的参数
params={
'wd':'ip地址'
}
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
# 发送get请求
response = requests.get(url=url,headers=headers,params=params,proxies=proxy)
print(response.text)
# 获取返回页面保存到本地,便于查看
with open('ip.html','w',encoding='utf-8') as f:
f.write(response.text)
可以查看页面是否ip地址变了,如果变了说明成功了,当然,其实我们测试的时候,只是需要看看我们的状态码是否是200,如果是200,就说明我们其实已经成功了
代理ip
为了隐藏自己的ip,我们就需要用代理ip了
从IP代理的隐蔽性级别进行划分,代理可以分为三种,即高度匿名代理、普通匿名代理和透明代理。
| 代理类型 | 代理服务器端的配置 | 描述 |
|---|---|---|
| 透明代理 | REMOTE_ADDR = Proxy IP;HTTP_VIA = Proxy IP;HTTP_X_FORWARDED_FOR = Your IP | 透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以从HTTP_X_FORWARDED_FOR来查到你是谁。 |
| 匿名代理 | REMOTE_ADDR = proxy IP;HTTP_VIA = proxy IP;HTTP_X_FORWARDED_FOR = proxy IP | 匿名代理比透明代理进步了一点:别人只能知道你用了代理,无法知道你是谁。 |
| 高匿代理 | REMOTE_ADDR = Proxy IP;HTTP_VIA = Proxy IP;HTTP_X_FORWARDED_FOR = Random IP address | 高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。 |
接下来我们来介绍一下,如何去自动爬取代理ip,因为有时候手动去调proxy太麻烦了
我们首先给出几个免费代理ip的网址
http://www.ip3366.net/
http://www.feidudaili.com/index/gratis/index
https://proxy.ip3366.net/free/
https://www.89ip.cn/index.html
http://www.66ip.cn/1.html
如果我们打开这些网站,我们可以看到有很多免费代理ip和他们的端口,比如
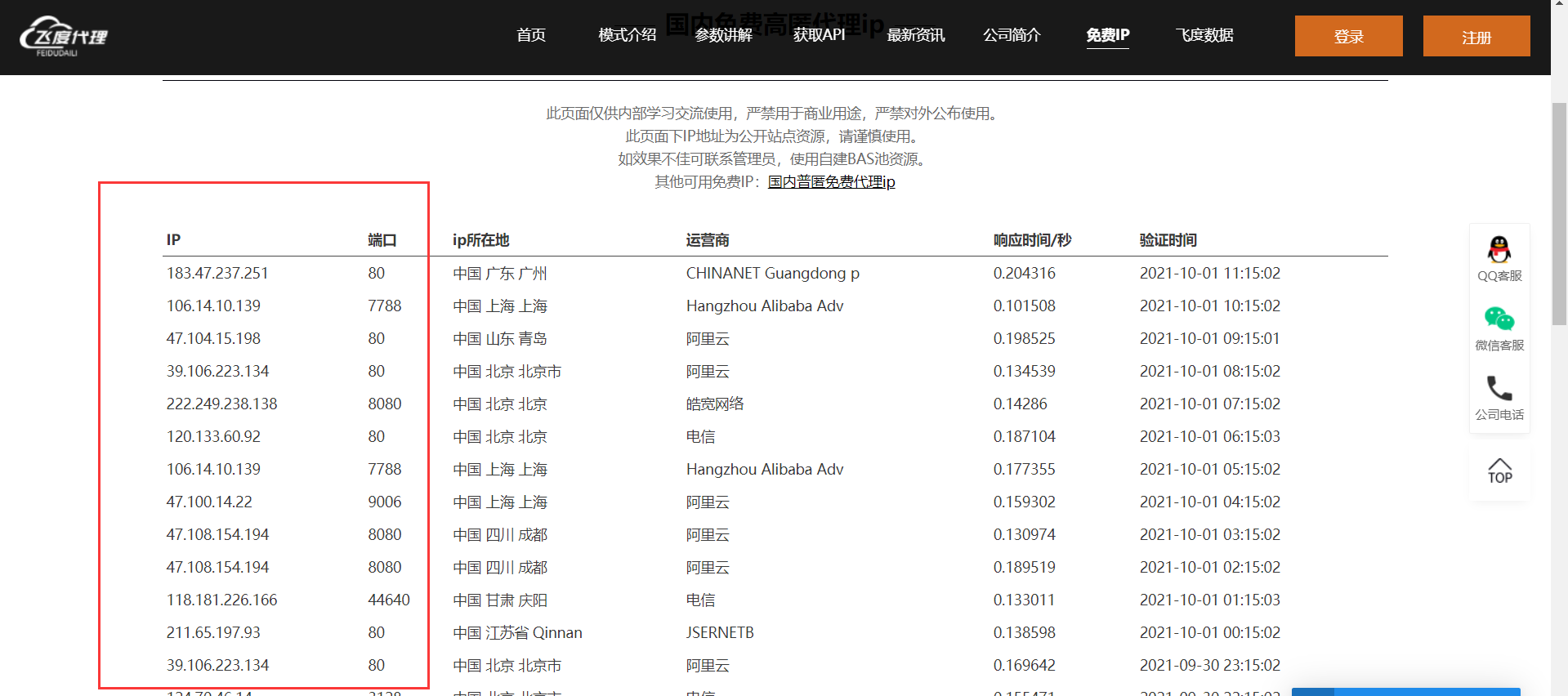
在这里面我们可以利用这些代理ip,但是有时候,这些代理ip是有问题的,所以我们在用的时候又要进行测试,因为毕竟这些是免费的ip,是很不稳定的,我们也可以出钱买ip,这样我们得到的ip就是稳定的,免费ip是很难稳定的。
多线程爬取
接下来,我就想对其进行爬取,批量爬取,一个一个测试,将正确的存入文件中,我们可以下次进行使用
读入代理ip
目的其实很简单,如果我们的文件本身有这个ip,我们就不必要继续写入相同的,这样会比较浪费时间
def read_proxy(path='ip_proxy.txt'):
if not os.path.exists(path):
f = open(path,'w')
f.close()
with open(path,'r') as f:
PROXY = f.readlines()
PROXY = [proxy.replace('\n', '') for proxy in PROXY]
return PROXY
写入代理ip
这个也就更显而易见了吧,就是将正确的代理ip写入我们的文件中,还是比较简单的。
# 将代理ip写入文件
def write_proxy(proxy,path='ip_proxy.txt'):
if proxy not in PROXY:
with open('ip_proxy.txt','a+') as fp:
fp.write(proxy + '\n')
print("正在写入 ip: {1} ".format(proxy))
print("录入完成")
else:
print("文件中已有相同ip,未录入")
验证代理ip
这里有一个很重要的代码也就是,验证代理ip,因为我们的ip地址并不是所有都是可用的,所以我们应该验证他们,如果是正确的,我们再进行写入,如果是错误的,那我们不会进行写入操作。
# 验证已得到IP的可用性
def test_proxies(proxies):
url = "https://www.1688.com/"
header = {
"User-Agent": random.choice(my_headers),
'Connection': 'close'
}
for proxy in proxies:
try:
response = requests.get(url,headers=header,proxies={"http":proxy,'https':proxy},timeout=2)
# time = response.elapsed.total_seconds()
# print(time)
if response.status_code == 200:
print('-'*15,"该代理IP可用: {0}".format(proxy),'-'*15)
write_proxy(proxy)
else:
print("该代理IP不可用: {0}".format(proxy))
except Exception as e:
print("该代理IP无效: {0}".format(proxy))
解析网页得到代理ip
对于我们的网页来说,里面有很多的代理ip,他们的格式都是类似的,所以我们需要从解析我们的网页得到代理ip,然后进行我们的测试,如果成功就会写入进行,这里我们就需要用我们的xpath解析我们的网页,当然,也可以用BeautifSoup
# 解析网页,并得到网页中的代理IP
def get_proxy(html,xpath):
selector = etree.HTML(html)
proxies = []
XPATH = xpath
for each in selector.xpath(XPATH):
# ip.append(each[0])
ip = each.xpath('./td[1]/text()')[0].strip()
port = each.xpath('./td[2]/text()')[0].strip()
proxy = ip + ':' + port
proxies.append(proxy)
# print('ip 有' ,len(proxies) , '条')
test_proxies(proxies)
获取网页响应
这个就更简单了,实际上就是对我们的网页进行响应,在用以上代码进行解析,也是比较简单的,不过这里面有两个参数
# 营造请求头,获取网页响应
def get_html(url_xpath,page):
header = {
"User-Agent": random.choice(my_headers),
'Connection': 'close'
}
url,xpath = url_xpath['url'],url_xpath['xpath']
# print(url,xpath)
response = requests.get(url%page, headers=header,proxies=proxies)
# print(response.text)
get_proxy(response.text ,xpath)
测试已有文件的ip是否正确
由于我们毕竟是免费的ip,所以来说,我们就需要对其进行再一次测试,因为可能他很快就要失效了
def test_files(path):
proxies = read_proxy(path)
proxies = list(set(proxies))
url = "https://www.1688.com/"
header = {
"User-Agent": random.choice(my_headers),
'Connection': 'close'
}
f = open(path,'w')
for proxy in proxies:
try:
response = requests.get(url,headers=header,proxies={"http":proxy,'https':proxy},timeout=2)
# time = response.elapsed.total_seconds()
# print(time)
if response.status_code == 200:
print('-'*15,"该代理IP可用: {0}".format(proxy),'-'*15)
f.write(proxy + '\n')
else:
print("该代理IP不可用: {0}".format(proxy))
except Exception as e:
print("该代理IP无效: {0}".format(proxy))
f.close()
多线程爬取
其实对于这一块来说,我们可以一个一个爬取的,但是我觉得太慢了,在这个时间效率为王的时代,我觉得我们还是有必要用一些多线程的,这里我们就需要用一下pathos库,用里面的线程池进行一个多线程的爬取
pool = Pool(30)
for name,ip in ip_url.items():
# print(name,ip)
e_pages = ip['page']
total_page = [i for i in range(s_pages,e_pages + 1)]
url_xpath = [ip]*(e_pages-s_pages + 1)
pool.map(get_html,url_xpath,total_page)
print('\n'*3,name,'已经被爬完','\n'*3)
time.sleep(30)
pool.close()
pool.join()
我这里还用了30个线程去爬取,这样可能极大的提高了效率,相当于一次性爬30个页面,我觉得这可能能很大的提高我们的效率吧
不过这里关于多线程的知识还是需要大家去努力看看,我这里还是不详细讲了

这里出现有时候print奇奇怪怪的原因是,我们利用了多线程,所以每一个线程都是独立的,有时候更快导致了,我们输出有时候也会有一点点乱,但是在我们的文件中不会,只是看起来有点奇怪哈哈
做好心理准备,爬取下来的IP,可能立马就失效了,毕竟免费的(便宜没什么好货对吧,而且可能大家都在爬爬爬)
完整代码
最后的最后呢,我还是给出完整的代码,每个人在自己的电脑上都可以运行的,只要安装正确那些库,有什么问题都可以跟我讨论,我最后再多嘴一句**(注意:本博客和代码仅可用于计算机技术学习及数据抓取、爬虫采集等合法行为)**
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# @File : ip.py
# @Time : 2021/09/30 19:32:52
# @Author : DKJ
# @Contact : 1016617094@qq.com
# @Software: VScode
# here put the import lib
import requests
from lxml import etree
import random
import os
from pathos.multiprocessing import ProcessingPool as Pool
import time
my_headers = [
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "
]
PROXY = []
proxies = {}
def read_proxy(path='ip_proxy.txt'):
if not os.path.exists(path):
f = open(path,'w')
f.close()
with open(path,'r') as f:
PROXY = f.readlines()
PROXY = [proxy.replace('\n', '') for proxy in PROXY]
return PROXY
# 将代理ip写入文件
def write_proxy(proxy,path='ip_proxy.txt'):
if proxy not in PROXY:
with open('ip_proxy.txt','a+') as fp:
fp.write(proxy + '\n')
print("正在写入 ip: {1} ".format(proxy))
print("录入完成")
else:
print("文件中已有相同ip,未录入")
# 验证已得到IP的可用性
def test_proxies(proxies):
url = "https://www.1688.com/"
header = {
"User-Agent": random.choice(my_headers),
'Connection': 'close'
}
for proxy in proxies:
try:
response = requests.get(url,headers=header,proxies={"http":proxy,'https':proxy},timeout=2)
# time = response.elapsed.total_seconds()
# print(time)
if response.status_code == 200:
print('-'*15,"该代理IP可用: {0}".format(proxy),'-'*15)
write_proxy(proxy)
else:
print("该代理IP不可用: {0}".format(proxy))
except Exception as e:
print("该代理IP无效: {0}".format(proxy))
# 解析网页,并得到网页中的代理IP
def get_proxy(html,xpath):
selector = etree.HTML(html)
proxies = []
XPATH = xpath
for each in selector.xpath(XPATH):
# ip.append(each[0])
ip = each.xpath('./td[1]/text()')[0].strip()
port = each.xpath('./td[2]/text()')[0].strip()
proxy = ip + ':' + port
proxies.append(proxy)
# print('ip 有' ,len(proxies) , '条')
test_proxies(proxies)
# 营造请求头,获取网页响应
def get_html(url_xpath,page):
header = {
"User-Agent": random.choice(my_headers),
'Connection': 'close'
}
url,xpath = url_xpath['url'],url_xpath['xpath']
# print(url,xpath)
response = requests.get(url%page, headers=header,proxies=proxies)
# print(response.text)
get_proxy(response.text ,xpath)
def test_files(path):
proxies = read_proxy(path)
proxies = list(set(proxies))
url = "https://www.1688.com/"
header = {
"User-Agent": random.choice(my_headers),
'Connection': 'close'
}
f = open(path,'w')
for proxy in proxies:
try:
response = requests.get(url,headers=header,proxies={"http":proxy,'https':proxy},timeout=2)
# time = response.elapsed.total_seconds()
# print(time)
if response.status_code == 200:
print('-'*15,"该代理IP可用: {0}".format(proxy),'-'*15)
f.write(proxy + '\n')
else:
print("该代理IP不可用: {0}".format(proxy))
except Exception as e:
print("该代理IP无效: {0}".format(proxy))
f.close()
if __name__ == "__main__":
requests.DEFAULT_RETRIES = 5 # 增加重试连接次数
s = requests.session()
s.keep_alive = False # 关闭多余连接
# 代理ip的爬取源地址
PATH = 'ip_proxy.txt'
test_files(PATH)
print('测试完毕')
# time.sleep(10)
PROXY = read_proxy(PATH)
if len(PROXY) != 0:
proxy = random.choices(PROXY)
proxies['https'],proxies['http'] = proxy,proxy
ip_url = {'飞度代理':{'url':'http://www.feidudaili.com/index/gratis/index?page=%s',
'xpath':'//div[@class="section clearfix"]//table[@class="data_table"]/tbody/tr',
'page':24},
'89代理':{'url':'http://www.89ip.cn/index_%s.html',
'xpath':'//table[@class="layui-table"]/tbody/tr',
'page':11},
'齐云代理':{'url':'https://proxy.ip3366.net/free/?action=china&page=%s',
'xpath':'//*[@id="content"]/section/div[2]/table/tbody/tr',
'page':10},
'UU http代理':{'url':'http://www.uuhttp.com/index/free/index?page=%s',
'xpath':'//div[@class="dial_left fadeInLeft free_page"]//div[@class="price_table"]//tbody/tr',
'page':'600'},
'66免费代理':{'url':'http://www.66ip.cn/%s.html',
'xpath':'//div[@class="layui-row layui-col-space15"]//table/tbody/tr',
'page':1000},
'云代理':{'url':'http://www.ip3366.net/?stype=1&page=%s',
'xpath':'//div[@id="container"]//div[@id="list"]/table/tbody/tr',
'page':10}
}
# get_html(ip_url['89代理'],1)
s_pages = 1
pool = Pool(30)
for name,ip in ip_url.items():
# print(name,ip)
e_pages = ip['page']
total_page = [i for i in range(s_pages,e_pages + 1)]
url_xpath = [ip]*(e_pages-s_pages + 1)
pool.map(get_html,url_xpath,total_page)
print('\n'*3,name,'已经被爬完','\n'*3)
time.sleep(30)
pool.close()
pool.join()
最后祝大家生活愉快,国庆节快乐咯!!!
















 852
852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











