







Coggle 30 Days of ML【打卡】广告-信息流跨域ctr预估
任务介绍
赛题介绍
广告推荐主要基于用户对广告的历史曝光、点击等行为进行建模,如果只是使用广告域数据,用户行为数据稀疏,行为类型相对单一。而引入同一媒体的跨域数据,可以获得同一广告用户在其他域的行为数据,深度挖掘用户兴趣,丰富用户行为特征。引入其他媒体的广告用户行为数据,也能丰富用户和广告特征。
本赛题希望选手基于广告日志数据,用户基本信息和跨域数据优化广告ctr预估准确率。目标域为广告域,源域为信息流推荐域,通过获取用户在信息流域中曝光、点击信息流等行为数据,进行用户兴趣建模,帮助广告域CTR的精准预估。

比赛报名方法:https://shimo.im/docs/G9fZLTn1lbccQhkQ/read
数据说明
提供的数据包括目标域用户行为数据,源域用户行为数据, 以下按照这2个维度分别 说明。
- 目标域用户行为数据
| 序号 | 字段名称 | 字段含义 | 是 否 可 为空 | 字段类 型 | 取值样例 |
|---|---|---|---|---|---|
| 1 | label | 是否点击, 0:否, 1:是 | 否 | int | 0,1 |
| 2 | user_id | 用户 id | 否 | String | 1,2… |
| 3 | age | 年龄 | 是 | String | 1,2,3… |
| 4 | gender | 性别 | 是 | String | 1,2… |
| 5 | residence | 常住地-省份 | 是 | String | 1,2… |
| 6 | city | 常住地-市-编号 | 是 | String | 1,2… |
| 7 | city_rank | 常住地-市-等级 | 是 | String | 1,2… |
| 8 | series_dev | 设备系列 | 是 | String | 1,2… |
| 9 | series_group | 设备系列分组 | 是 | String | 1,2… |
| 10 | emui_dev | emui 版本号 | 是 | String | 1,2… |
| 11 | device_name | 用户使用的手机机型 | 是 | String | 1,2… |
| 12 | device_size | 用户使用手机的尺寸 | 是 | String | 1,2… |
| 13 | net_type | 行为发生的网络状态 | 是 | String | 1,2… |
| 14 | task_id | 广告任务唯一标识 | 是 | String | 1,2… |
| 15 | adv_id | 广告任务对应的素材 id | 是 | String | 1,2… |
| 16 | creat_type_cd | 素材的创意类型 id | 是 | String | 1,2… |
| 17 | adv_prim_id | 广告任务对应的广告主 id | 是 | String | 1,2… |
| 18 | inter_type_cd | 广告任务对应的素材的交 互类型 | 是 | String | 1,2… |
| 19 | slot_id | 广告位 id | 是 | String | 1,2… |
| 20 | site_id | 媒体 id | 是 | String | 1,2… |
| 21 | spread_app_id | 投放广告任务对应的应用 id | 是 | String | 1,2… |
| 22 | Tags | 广告任务对应的应用的标 签 | 是 | String | 1,2… |
| 23 | app_second_class | 广告任务对应的应用的二 级分类 | 是 | String | 1,2… |
| 24 | app_score | app 得分 | 是 | Int | 4 |
| 25 | ad_click_list_00 1 | 用户点击广告任务 id 列表 | 是 | [string,] | [1^2…] |
| 26 | ad_click_list_00 2 | 用户点击广告对应广告主 id 列表 | 是 | [string,] | [1^2…] |
| 27 | ad_click_list_00 3 | 用户点击广告推荐应用列 表 | 是 | [string,] | [1^2…] |
| 28 | ad_close_list_00 1 | 用户关闭广告任务列表 | 是 | [string,] | [1^2…] |
| 29 | ad_close_list_00 2 | 用户关闭广告对应广告主 列表 | 是 | [string,] | [1^2…] |
| 30 | ad_close_list_00 3 | 用户关闭广告推荐应用列 表 | 是 | [string,] | [1^2…] |
| 31 | pt_d | 时间戳 | 否 | String | 202205221430 |
| 32 | log_id | 样本 id | 否 | Int | 12345678 |
- 源域用户行为数据
| 序号 | 字段名称 | 字段含义 | 是 否 可 为空 | 字段类 型 | 取值样例 |
|---|---|---|---|---|---|
| 1 | u_userId | 用户标识 | 否 | String | 0001 |
| 2 | u_phonePrice | 用户手机价格 | 是 | String | 13 |
| 3 | u_browserLifeCycle | 浏览器用户活跃度 | 是 | String | 10 |
| 4 | u_browserMode | 浏览器业务类型 | 是 | String | 11 |
| 5 | u_feedLifeCycle | 信息流用户活跃度 | 是 | String | 12 |
| 6 | u_refreshTimes | 信息流日均有效刷新次数 | 是 | String | 16 |
| 7 | u_newsCatInterests | 信息流图文 点击 分类偏 好 | 是 | [string,] | [1^2…] |
| 8 | u_newsCatDislike | 信息流图文 负反馈 分类 偏好 | 是 | [string,] | [1^2…] |
| 9 | u_newsCatInteres tsST | 用户短时 兴趣 分类偏好 | 是 | [string,] | [1^2…] |
| 10 | u_click_ca2_news | 用户图文 类别 点击序列 | 是 | [string,] | [1^2…] |
| 11 | i_docId | 文章 docid | 是 | String | 0001 |
| 12 | i_s_sourceId | 文章来源的 sourceid | 是 | String | 0001 |
| 13 | i_regionEntity | 文章地域词 id | 是 | String | 0001 |
| 14 | i_cat | 文章类别 id | 是 | String | 0001 |
| 15 | i_entities | 文章实体词 id | 是 | [string,] | [1^2…] |
| 16 | i_dislikeTimes | 文章负反馈量 | 是 | String | 60 |
| 17 | i_upTimes | 文章点赞量 | 是 | String | 22 |
| 18 | I_dtype | 文章展现形式 | 是 | String | 20 |
| 19 | e_ch | 频道 | 是 | String | 1,2… |
| 20 | e_m | 事件来源设备机型 | 是 | String | 1,2… |
| 21 | e_po | 第几位 | 是 | String | 9 |
| 22 | e_pl | 拜访地 | 是 | String | 1,2… |
| 23 | e_rn | 第几刷 | 是 | String | 1 |
| 24 | e_section | 信息流场景类型 | 是 | String | 13 |
| 25 | e_et | 时间戳 | 否 | String | 202205221430 |
| 26 | label | 是否点击, -1:否, 1:是 | 否 | String | 1 |
| 27 | cilLabel | 是否点赞,-1:否, 1:是 | 否 | String | 1 |
| 28 | pro | 文章浏览进度 | 否 | String | 1,2… |
评估方式
评估方式: 统计广告域的样本 CTR 预估值, 计算 GAUC 和 AUC
评测指标: 本次比赛使用 GAUC 和 AUC 的加权求和作为评估指标, 具体公式如下:
x
A
U
C
=
α
∗
G
A
U
C
+
β
∗
A
U
C
x
xAUC=α∗GAUC+β∗AUCx
xAUC=α∗GAUC+β∗AUCx
xAUC 越高,代表结果越优,排名越靠前。其中,AUC为全体样本的 AUC 统计, GAUC 为分组 AUC 的加权求和, 以用户为维度分组,分组权值为分组内曝光量/总曝光)
G A U C = ∑ k = i n A U C i ∗ I m p r e s s i o n i ∑ k = i n I m p r e s s i o n i GAUC=\frac{\sum_{k=i}^nAUC_i*Impression_i}{\sum_{k=i}^nImpression_i} GAUC=∑k=inImpressioni∑k=inAUCi∗Impressioni
初赛:α 为 0.7,𝛽为 0.3
提交方式
选手提交结果为一个 submission.csv 文件, 编码采用无 BOM 的 UTF-8 ,格式如下:
log_id,pctr
其中 log_id 为对应测试样本中的 log_id,pctr 对应测试样本经由模型计算出的预 估 ctr 值, pctr 保留 6 位小数。提交文件参考如下示例:
log_id,pctr
1, 0.002345
2, 0.010456
学习打卡
| 任务名称 | 难度 |
|---|---|
| 任务1:比赛报名与尝试 | 低、1 |
| 任务2:比赛数据分析 | 中、2 |
| 任务3:验证集划分与树模型 | 中、2 |
| 任务4:特征工程入门 | 中、2 |
| 任务5:特征工程进阶 | 中、2 |
| 任务6:深度推荐模型 | 中、2 |
| 任务7:深度序列模型 | 中、2 |
| 任务8:多折训练与集成 | 高、3 |
赛题理解和思路
本赛题提供7天数据用于训练,1天数据用于测试,数据包括目标域(广告域)用户行为日志,用户基本信息,广告素材信息,源域(信息流域)用户行为数据,源域(信息流域)物品基本信息等。希望选手基于给出的数据,识别并生成源域能反映用户兴趣,并能应用于目标域的用户行为特征表示,基于用户行为序列信息,进行源域和目标域的联合建模,预测用户在广告域的点击率。所提供的数据经过脱敏处理,保证数据安全。
本次比赛是一个经典点击率预估(CTR)的数据挖掘赛,任务是构建一种模型,根据用户的测试数据来预测这个用户是否点击广告。这是典型的二分类问题,模型的预测输出为 0 或 1 (点击:1,未点击:0)
机器学习中,关于分类任务我们一般会想到逻辑回归、决策树等算法,在本文实践代码中,我们尝试使用逻辑回归来构建我们的模型。我们在解决机器学习问题时,一般会遵循以下流程: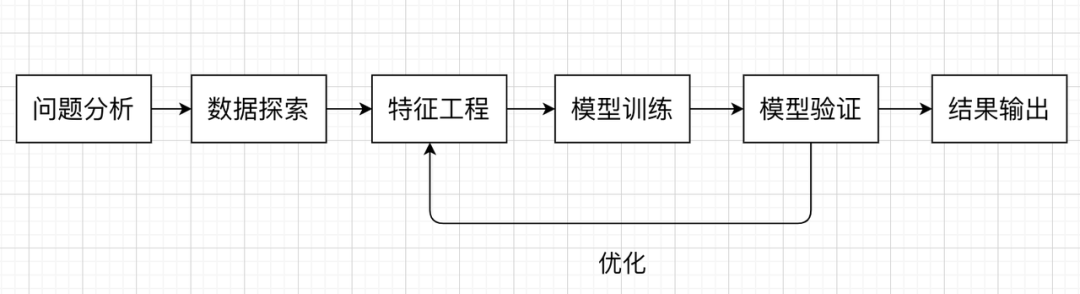
任务1:报名比赛
- 步骤1:报名比赛https://developer.huawei.com/consumer/cn/activity/digixActivity/digixdetail/101655281685926449?ha_source=co&ha_sourceId=89000234
- 步骤2:下载比赛数据(点击比赛页面的赛题数据)
- 步骤3:解压比赛数据,并使用pandas进行读取;
- 步骤4:使用逻辑回归模型完成建模并提交;
Baseline尝试
#安装相关依赖库 如果是windows系统,cmd命令框中输入pip安装,参考上述环境配置
#!pip install sklearn
#!pip install pandas
#---------------------------------------------------
#导入库
import pandas as pd
# 目标域用户行为数据
train_ads = pd.read_csv('./train/train_data_ads.csv',
usecols=['log_id', 'label', 'user_id', 'age', 'gender', 'residence', 'device_name',
'device_size', 'net_type', 'task_id', 'adv_id', 'creat_type_cd'])
test_ads = pd.read_csv('./test/test_data_ads.csv',
usecols=['log_id', 'user_id', 'age', 'gender', 'residence', 'device_name',
'device_size', 'net_type', 'task_id', 'adv_id', 'creat_type_cd'])
# 数据采样
train_ads = pd.concat([
train_ads[train_ads['label'] == 0].sample(70000),
train_ads[train_ads['label'] == 1].sample(10000),
])
#----------------模型训练----------------
# 加载逻辑回归模型,训练
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf.fit(
train_ads.drop(['log_id', 'label', 'user_id'], axis=1),
train_ads['label']
)
#----------------结果输出----------------
# 模型预测
test_ads['pctr'] = clf.predict_proba(
test_ads.drop(['log_id', 'user_id'], axis=1),
)[:, 1]
# 写入文件
test_ads[['log_id', 'pctr']].to_csv('submission.csv',index=None)
- 利用baseline进行提交,得到了大概0.58的结果

任务2:比赛数据分析
对目标域用户行为进行分析
-
对于训练集 和 测试集,用户重合的比例是多少?
我们首先可以分别看看训练集和测试集的用户个数
train_data_ads = pd.read_csv('./train/train_data_ads.csv') test_data_ads = pd.read_csv('./test/test_data_ads.csv') train_id_ads = train_data_ads['user_id'].unique() test_id_ads = test_data_ads['user_id'].unique() len(train_id_ads), len(test_id_ads) # 在训练集和测试集中,去重的id个数(65297, 28771)除此之外,我们还查看一下,训练集和测试集相同的用户个数,这个很简单,我们可以通过利用集合的去重,然后再通过集合的与得到我们的结果
#统计两个数组相同元素个数 #方法一:前面用户id已经去重了,但是这里不加set会报错 dup_id_len = len(set(train_id_ads) & set(test_id_ads)) dup_id_len #方法二: #duplicate_id = [x for x in train_id_ads if x in test_id_ads] #dup_id_len = len(duplicate_id)27186我们还可以查看用户重合的比例,从得到的结果来看,测试集重合的比例比较高
#对于训练集 和 测试集,用户重合的比例是多少? ratio_dup_train = dup_id_len / len(train_id_ads) ratio_dup_test = dup_id_len / len(test_id_ads) ratio_dup_train, ratio_dup_test(0.41634378302219094, 0.9449098050119913) -
统计字段中有多少数值字段,多少非数值字段?
train_data_ads.dtypes # test_data_ads.dtypes从结果我们就可以看出来,其中object就不是数值字段,一共有7个是非数值字段
log_id int64 label int64 user_id int64 age int64 gender int64 residence int64 city int64 city_rank int64 series_dev int64 series_group int64 emui_dev int64 device_name int64 device_size int64 net_type int64 task_id int64 adv_id int64 creat_type_cd int64 adv_prim_id int64 inter_type_cd int64 slot_id int64 site_id int64 spread_app_id int64 hispace_app_tags int64 app_second_class int64 app_score float64 ad_click_list_v001 object ad_click_list_v002 object ad_click_list_v003 object ad_close_list_v001 object ad_close_list_v002 object ad_close_list_v003 object pt_d int64 u_newsCatInterestsST object u_refreshTimes int64 u_feedLifeCycle int64 dtype: object -
统计哪些用户属性(年龄、性别、手机设备等)与 标签相关性最强?
数据相关性分析中,经常用到data.corr()函数,data.corr()表示了data中的两个变量之间的相关性,取值范围为[-1,1],取值接近-1,表示反相关,类似反比例函数,取值接近1,表正相关。
DataFrame.corr(self, method=‘pearson’, min_periods=1) → ‘DataFrame’
参数:
method: 可选值为{‘pearson’, ‘kendall’, ‘spearman’}
pearson:标准相关系数,Pearson相关系数来衡量两个数据集合是否在一条线上面,即针对线性数据的相关系数计算,针对非线性数据便会有误差。
kendall:Kendall Tau相关系数,用于反映分类变量相关性的指标,即针对无序序列的相关系数,非正太分布的数据
spearman:非线性的,非正太分布的数据的相关系数
min_periods: 每对列必须具有有效结果的最小观察数。目前仅适用于皮尔逊和斯皮尔曼相关返回: 各类型之间的相关系数DataFrame表格。
注意: 变量与自身的相关性为1。
可以看到最大的相关性为 lot_id 字段,其次为series_group,还有就是app_second_class
corr = train_data_ads.corr(method = 'kendall')['label'] corr.sort_values()u_feedLifeCycle -0.084677 u_refreshTimes -0.071523 creat_type_cd -0.043874 adv_prim_id -0.013145 age -0.009950 city_rank -0.007258 gender -0.005801 hispace_app_tags -0.003057 device_name -0.002123 task_id -0.001353 residence -0.001055 city -0.000617 log_id -0.000555 user_id -0.000428 inter_type_cd 0.000284 device_size 0.001004 pt_d 0.001009 adv_id 0.001220 emui_dev 0.002263 series_dev 0.003079 spread_app_id 0.006494 net_type 0.007469 app_score 0.007539 app_second_class 0.010145 series_group 0.014230 slot_id 0.031366 label 1.000000 site_id NaN Name: label, dtype: float64除此之外,我们还可以画热力图更直观的可视化我们的相关性系数
import seaborn as sns sns.heatmap(train_data_ads.corr(),linewidths=0.1,vmax=1.0, square=True,linecolor='white', annot=True)
对源域用户行为进行分析
-
源域用户行为与目标域用户行为训练集和测试集用户重合的比例分别是多少?首先和前面对目标域方法一样,读入文件后查看用户的id
train_data_feeds = pd.read_csv('./train/train_data_feeds.csv') test_data_feeds = pd.read_csv('./test/test_data_feeds.csv') train_id_feeds = train_data_feeds['u_userId'].unique() test_id_feeds = test_data_feeds['u_userId'].unique() len(train_id_feeds), len(test_id_feeds) # 在训练集和测试集中,去重的id个数(180123, 51162)其次,我们计算一下,
源域用户行为与目标域用户行为的训练集的用户重合比例dup_id_len_train = len(set(train_id_ads) & set(train_id_feeds)) dup_id_len_test = len(set(test_id_ads) & set(test_id_feeds)) ratio_dup_train = dup_id_len_train / len(train_id_feeds) ratio_dup_test = dup_id_len_test / len(test_id_feeds) ratio_dup_train, ratio_dup_test(0.36251339362546703, 0.5623509636058012) -
统计字段中有多少数值字段,多少非数值字段?
从结果可以看到,我们只有7个非数值字段-,一共有28个字段,21个为数值字段
train_data_feeds.dtypes # test_data_feeds.dtypesu_userId int64 u_phonePrice int64 u_browserLifeCycle int64 u_browserMode int64 u_feedLifeCycle int64 u_refreshTimes int64 u_newsCatInterests object u_newsCatDislike object u_newsCatInterestsST object u_click_ca2_news object i_docId object i_s_sourceId object i_regionEntity int64 i_cat int64 i_entities object i_dislikeTimes int64 i_upTimes int64 i_dtype int64 e_ch int64 e_m int64 e_po int64 e_pl int64 e_rn int64 e_section int64 e_et int64 label int64 cillabel int64 pro int64 dtype: object
理解数据字段的逻辑,并尝试对数据字段进行分组
这一部分是需要对我们目标域和源域的数据的数据字段进行逻辑上的理解,首先分析的是目标域
-
首先可以分出城市,这一部分表示了所在的地区的繁荣程度,以及地理位置
1 residence 常住地-省份 2 city 常住地-市-编号 3 city_rank 常住地-市-等级 -
其次我们可以根据设备的类型和版本,包括手机的机型,以及手机的尺寸,这些都代表着用户使用的设备的参数
1 series_dev 设备系列 2 series_group 设备系列分组 3 emui_dev emui 版本号 4 device_name 用户使用的手机机型 5 device_size 用户使用手机的尺寸 -
其次就是广告的设计也可以分为一个组,这些代表着广告创作时使用的创意和素材 以及 面向的对象和创建方式
1 adv_id 广告任务对应的素材 id 2 creat_type_cd 素材的创意类型 id 3 adv_prim_id 广告任务对应的广告主 id 4 inter_type_cd 广告任务对应的素材的交 互类型 -
还有广告的投放,广告投放的媒体和各个应用也是比较重要的一环,面对的应用的面向用户,以及还有投放的app的应用的得分
最重要的就是slot_id,它与标签的相关性系数最大,所以说明广告位id是非常重要的一环。
1 slot_id 广告位 id 2 site_id 媒体 id 3 spread_app_id 投放广告任务对应的应用 id 4 Tags 广告任务对应的应用的标 签 5 app_second_class 广告任务对应的应用的二 级分类 6 app_score app 得分
任务3:验证集划分与树模型
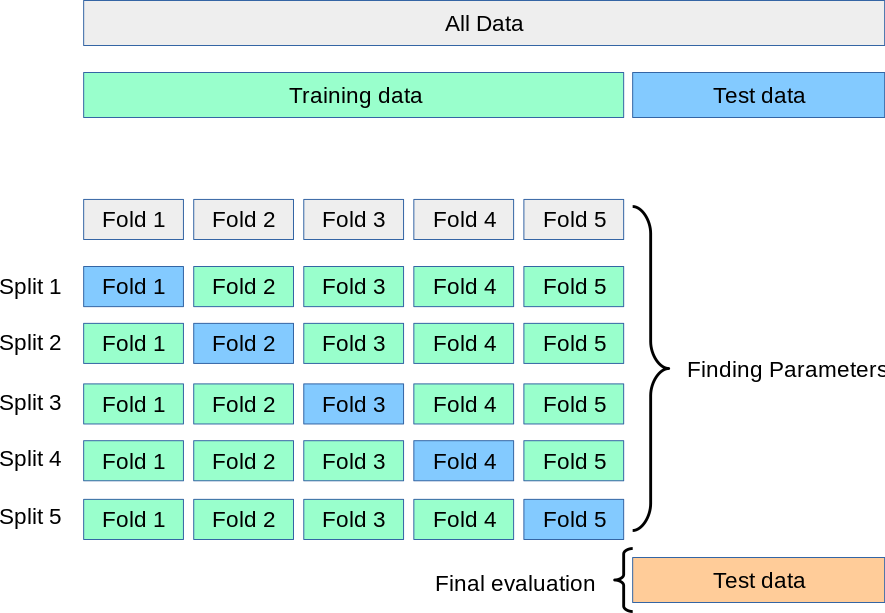
学习KFold数据划分逻辑
在sklearn中,有一个KFold函数,用来进行k折交叉验证,这里简单介绍一下cross-validation (CV for short),交叉验证
基本的思路是:k-fold CV,也就是我们下面要用到的函数KFold,是把原始数据分割为K个子集,每次会将其中一个子集作为测试集,其余K-1个子集作为训练集。
下图是官网提供的一个介绍图
class
sklearn.model_selection.KFold(n_splits=5, **,shuffle=False,*random_state=None)
参数:**n_splits:**int, default=5 要分割为多少个K子集
shuffle: bool, default=False 是否要洗牌(打乱数据)
random_state: int or RandomState instance, default=None 如果shuffle是True,指定的种子值
import numpy as np
from sklearn.model_selection import KFold
X = np.random.randint(1,100,20).reshape((10,2))
kf = KFold(n_splits=3)
for X_train,X_test in kf.split(X):
print(X_train,X_test)
我们可以看到,我们把数据分为了5份,每份都分别作为测试器,其余k-1份作为训练集,这里返回的是数据集的划分后的索引
[2 3 4 5 6 7 8 9] [0 1]
[0 1 4 5 6 7 8 9] [2 3]
[0 1 2 3 6 7 8 9] [4 5]
[0 1 2 3 4 5 8 9] [6 7]
[0 1 2 3 4 5 6 7] [8 9]
这里我们就可以通过索引得到我们划分后的训练集和测试集
for X_train_i,X_test_i in kf.split(X):
print(X[X_train_i],X[X_test_i])
[[49 41]
[54 35]
[53 86]
[65 21]
[39 72]
[68 58]
[19 46]
[91 55]] [[30 33]
[32 87]]
[[30 33]
[32 87]
[53 86]
[65 21]
[39 72]
[68 58]
[19 46]
[91 55]] [[49 41]
[54 35]]
[[30 33]
[32 87]
[49 41]
[54 35]
[39 72]
[68 58]
[19 46]
[91 55]] [[53 86]
[65 21]]
[[30 33]
[32 87]
[49 41]
[54 35]
[53 86]
[65 21]
[19 46]
[91 55]] [[39 72]
[68 58]]
[[30 33]
[32 87]
[49 41]
[54 35]
[53 86]
[65 21]
[39 72]
[68 58]] [[19 46]
[91 55]]
使用Pandas和sklean完成下属数据划分操作:
-
训练集和验证集用户不重合的情况我们可以尝试得到共有多少个user_id,也就是用户
user_id = train_data_ads['user_id'].unique() print('一共有 {} 种 user_id'.format(len(user_id))) user_id一共有 65297 种 user_id array([100005, 100006, 100009, ..., 286534, 286715, 286999])我们如果确定了user_id以后,可以通过以下方法得到结果,取列表中的user_id作为dataframe
train_data_ads.loc[train_data_ads['user_id'].isin(user_id)] # train_data_ads[train_data_ads['user_id'].isin(userid_name)]log_id label user_id age gender residence city city_rank series_dev series_group … ad_click_list_v001 ad_click_list_v002 ad_click_list_v003 ad_close_list_v001 ad_close_list_v002 ad_close_list_v003 pt_d u_newsCatInterestsST u_refreshTimes u_feedLifeCycle 0 373250 0 100005 3 2 16 147 2 32 6 … 301573064814278^31706 206617761036 114219312 24107 1218 173 202206030326 3922016 0 15 1 373253 1 100005 3 2 16 147 2 32 6 … 301573064814278^31706 206617761036 114219312 24107 1218 173 202206030326 3922016 0 15 2 373252 1 100005 3 2 16 147 2 32 6 … 301573064814278^31706 206617761036 114219312 24107 1218 173 202206030326 3922016 0 15 3 373251 0 100005 3 2 16 147 2 32 6 … 301573064814278^31706 206617761036 114219312 24107 1218 173 202206030326 3922016 0 15 4 373255 0 100005 3 2 16 147 2 32 6 … 301573064814278^31706 206617761036 114219312 24107 1218 173 202206030328 3922016 0 15 … … … … … … … … … … … … … … … … … … … … … … 7675512 650508 0 287180 6 4 33 319 3 27 2 … 2148934426229293405726384 18581717115620561058 190^208 24107 1218 173 202206090848 19920715721986 7 17 7675513 650492 0 287180 6 4 33 319 3 27 2 … 2148934426229293405726384 18581717115620561058 190^208 24107 1218 173 202206090848 19920715721986 7 17 7675514 650509 0 287180 6 4 33 319 3 27 2 … 2148934426229293405726384 18581717115620561058 190^208 24107 1218 173 202206091012 19920715721986 7 17 7675515 650491 1 287180 6 4 33 319 3 27 2 … 2148934426229293405726384 18581717115620561058 190^208 24107 1218 173 202206091119 19920715721986 7 17 7675516 650499 0 287180 6 4 33 319 3 27 2 … 2148934426229293405726384 18581717115620561058 190^208 24107 1218 173 202206090846 19920715721986 7 17 7675517 rows × 35 columns
接着,我写了一个函数,相当于分开验证集和训练集的用户
def train_val_split(data, ratio = 0.8): np.random.shuffle(data) Len = len(data) train = data[:int(Len*ratio)] val = data[int(Len*ratio):] return train, val # 随机取一部分userid作为训练集,其余全部作为验证集 # 比例大约是 训练集:验证集 = 8:2 user_id_train,user_id_val = train_val_split(user_id) len(user_id_train),len(user_id_val),user_id_train,user_id_val(52237, 13060, array([104773, 117348, 183842, ..., 252764, 136365, 212255]), array([250682, 240767, 271978, ..., 109581, 186293, 115990]))train_data_ads_userid = train_data_ads.loc[train_data_ads['user_id'].isin(user_id_train)] val_data_ads_userid = train_data_ads.loc[train_data_ads['user_id'].isin(user_id_val)] -
验证集用户时间戳 晚于训练集用户时间戳这一部分,我们可以对数据集进行操作,可以以用户时间戳进行排序,最后取即可
train_data_ads.sort_values(by = 'pt_d', ignore_index=True)log_id label user_id age gender residence city city_rank series_dev series_group … ad_click_list_v001 ad_click_list_v002 ad_click_list_v003 ad_close_list_v001 ad_close_list_v002 ad_close_list_v003 pt_d u_newsCatInterestsST u_refreshTimes u_feedLifeCycle 0 652402 0 157067 7 2 17 215 4 11 8 … 30794 1633 162 24107 1218 173 202206020123 1121092122039 4 17 1 259393 0 144249 8 2 24 431 5 30 3 … 3098814584142233200016382 143312361535^1036 168^312 24107 1218 173 202206020127 168157579898 5 17 2 116539 0 213863 8 2 25 117 2 16 5 … 1853628624183261433219416 20091206120913441290 346111309 24107 1218 173 202206020131 26169119762 0 16 3 101201 0 217209 7 2 37 312 2 31 3 … 1701926564155391979010321 17231417169020511597 186246162190312 24107 1218 173 202206020138 2718627112168 8 17 4 508547 0 113066 3 2 11 415 2 32 6 … 332572622725635^34210 103620661914^1005 312114190^309 24107 1218 173 202206020147 0 2 11 … … … … … … … … … … … … … … … … … … … … … … 7675512 580385 0 150395 5 2 20 440 2 23 6 … 16739 1654 210 24107 1218 173 202206101209 0 2 17 7675513 739230 0 270125 8 2 46 301 2 23 6 … 2570728290340241299936287 16951036111215571633 190312162372305 24107 1218 173 202206101209 259410711227 9 14 7675514 910308 0 272475 6 4 33 319 3 27 2 … 2043617020317062941219714 11121036206618301005 312114162^309 24107 1218 173 202206101209 21921811211236 9 17 7675515 434262 0 195940 7 2 20 399 2 34 7 … 3613214587226372104124505 10411306182310321774 199246190114367 24107 1218 173 202206101209 219112112112108 9 17 7675516 405329 0 223268 7 2 20 328 5 16 5 … 2149316068145843556313330 10361234123615221636 312191190^208 24107 1218 173 202206101209 19962981025 6 17 7675517 rows × 35 columns
-
联合
目标域用户行为和源域用户行为,并使用时间戳和用户划分验证集接着利用目标域数据集的用户的不同,以大概8:2的比例划分了训练集和验证集
对时间戳来说,这一部分我个人会有些疑惑,既要用户不同,又要时间戳前后,那只有相同的用户,才会有时间戳前后的概念
所以最后我这一部分先不进行时间戳的划分,而是单单对不同用户划分了训练集和验证集
# ----------------数据集划分------------- # 划分训练集和测试集 cols = [f for f in train_data_ads.columns if f not in ['label']] train_data_ads_userid = train_data_ads.loc[train_data_ads['user_id'].isin(user_id_train)] val_data_ads_userid = train_data_ads.loc[train_data_ads['user_id'].isin(user_id_val)] x_train = train_data_ads_userid[cols] y_train = train_data_ads_userid['label'] x_val = val_data_ads_userid[cols] y_val = val_data_ads_userid['label'] x_test = test_data_ads[cols] #--------------------------------------
使用树模型、随机森林、LightGBM或CatBoost完成模型多折训练
- catboost
接着利用了Catboost进行训练,并没有进行多折训练,得到初步的分数是0.716975
params = {'learning_rate': 0.3, 'depth': 5, 'l2_leaf_reg': 10, 'random_seed':2022,
'od_type': 'Iter', 'od_wait': 100, 'allow_writing_files': False}
clf = CatBoostClassifier(iterations=20000,eval_metric='AUC',task_type='GPU',**params)
model = clf.fit(x_train,y_train, eval_set=(x_val, y_val),metric_period=100,use_best_model=True)
0: test: 0.7024544 best: 0.7024544 (0) total: 26.4ms remaining: 8m 48s
100: test: 0.7895933 best: 0.7895950 (99) total: 2.36s remaining: 7m 44s
200: test: 0.7926059 best: 0.7926413 (195) total: 4.67s remaining: 7m 40s
300: test: 0.7938464 best: 0.7938464 (300) total: 7s remaining: 7m 37s
400: test: 0.7945357 best: 0.7945357 (400) total: 9.32s remaining: 7m 35s
500: test: 0.7945496 best: 0.7946053 (480) total: 11.6s remaining: 7m 33s
600: test: 0.7945190 best: 0.7946548 (556) total: 14s remaining: 7m 30s
700: test: 0.7945854 best: 0.7946799 (656) total: 16.3s remaining: 7m 28s
bestTest = 0.7946799397
bestIteration = 656
Shrink model to first 657 iterations.

- lightgbm
还尝试了利用LGB的模型进行训练,也得到了不错的结果,这里本来尝试利用GPU,但是环境一直不可以
from lightgbm import LGBMClassifier
clf = clf = LGBMClassifier(feature_fraction = 0.8,
learning_rate = 0.1,
max_depth= 10,
num_leaves = 16,
metric='auc',
num_iteration = 1000,
is_unbalance=True,
# boosting='gbdt',
# num_boost_round=300,
early_stopping_round=30,
# device='gpu',
# gpu_platform_id=0,
# gpu_device_id=0,
verbose=1,
)
model = clf.fit(x_train,y_train, eval_set=(x_val, y_val))

- xgboost
还尝试利用了xgboost,得到了不错的结果
from xgboost import XGBClassifier
xgb_params = {'n_estimators':20000,
'max_depth':5,
'learning_rate':0.1,
'eval_metric':'auc',
'seed':2022,
'verbose':True,
'objective':'reg:logistic',
"gpu_id":0,
"tree_method":"gpu_hist",
}
clf = XGBClassifier(**xgb_params)
model = clf.fit(x_train,y_train, eval_set=[(x_val, y_val)],early_stopping_rounds=50,eval_metric='auc')

- catboost + kfold
再接着利用多折训练的方式,设置折数为3个,所以是3折模型训练。
这一部分像前面单独分清楚训练集和验证集,因为KFold会从整个数据集中提取index,一部分作为训练集,一部分作为验证集进行训练
seed = 2022
train_x = train_data_ads[cols]
train_y = train_data_ads['label']
kf = KFold(n_splits=3, shuffle=True, random_state=seed)
cv_scores = []
test = np.zeros(x_test.shape[0])
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} {}************************************'.format(str(i+1), str(seed)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
params = {'learning_rate': 0.3, 'depth': 5, 'l2_leaf_reg': 10, 'bootstrap_type':'Bernoulli','random_seed':seed,
'od_type': 'Iter', 'od_wait': 50, 'allow_writing_files': False}
model = CatBoostClassifier(iterations=20000, **params, eval_metric='AUC', task_type ='GPU')
model.fit(trn_x, trn_y, eval_set=(val_x, val_y),
metric_period=200,
cat_features=[],
use_best_model=True,
verbose=1)
val_pred = model.predict_proba(val_x)[:,1]
test_pred = model.predict_proba(x_test)[:,1]
test += test_pred / kf.n_splits
cv_scores.append(roc_auc_score(val_y, val_pred))
print(cv_scores)
************************************ 1 2022************************************
0: test: 0.7065597 best: 0.7065597 (0) total: 22.1ms remaining: 7m 22s
200: test: 0.7975476 best: 0.7975476 (200) total: 4.04s remaining: 6m 38s
400: test: 0.8002338 best: 0.8002338 (400) total: 8.07s remaining: 6m 34s
600: test: 0.8010459 best: 0.8010792 (595) total: 12.1s remaining: 6m 30s
800: test: 0.8016420 best: 0.8016428 (798) total: 16.1s remaining: 6m 25s
1000: test: 0.8021788 best: 0.8021788 (1000) total: 20.1s remaining: 6m 22s
1200: test: 0.8025397 best: 0.8025480 (1192) total: 24.2s remaining: 6m 18s
1400: test: 0.8026709 best: 0.8027424 (1357) total: 28.2s remaining: 6m 14s
bestTest = 0.8027424216
bestIteration = 1357
Shrink model to first 1358 iterations.
[0.8027424283302532]
************************************ 2 2022************************************
0: test: 0.7099740 best: 0.7099740 (0) total: 21.9ms remaining: 7m 18s
200: test: 0.7987009 best: 0.7987009 (200) total: 4.03s remaining: 6m 37s
400: test: 0.8011493 best: 0.8011587 (386) total: 8.05s remaining: 6m 33s
600: test: 0.8020754 best: 0.8020836 (599) total: 12.1s remaining: 6m 29s
800: test: 0.8025443 best: 0.8025546 (793) total: 16.1s remaining: 6m 25s
1000: test: 0.8032209 best: 0.8032209 (1000) total: 20.1s remaining: 6m 21s
bestTest = 0.803391844
bestIteration = 1112
Shrink model to first 1113 iterations.
[0.8027424283302532, 0.8033918763632052]
************************************ 3 2022************************************
0: test: 0.7065725 best: 0.7065725 (0) total: 21.1ms remaining: 7m 2s
200: test: 0.7976198 best: 0.7976198 (200) total: 4.03s remaining: 6m 36s
400: test: 0.7997762 best: 0.7997762 (400) total: 8.03s remaining: 6m 32s
600: test: 0.8010272 best: 0.8010328 (592) total: 12.1s remaining: 6m 29s
800: test: 0.8015802 best: 0.8015901 (799) total: 16.1s remaining: 6m 25s
bestTest = 0.8017456532
bestIteration = 858
Shrink model to first 859 iterations.
[0.8027424283302532, 0.8033918763632052, 0.8017456522533244]
最后提交查看结果,从结果可以看到,多折训练的结果会比正常训练更好,能达到0.80+的AUC,最后提交得到0.718
因为多折训练在某一方面对我们的数据的过拟合进行了一定的抑制,所以在大数据中往往会表现的不错,后续也可以尝试多加一部分折数

任务4:特征工程入门
使用Pandas完成下列统计【目标域】:
- 统计用户历史行为次数
- 统计用户历史点击的广告分类
- 统计每类广告被点击的概率
将提取的特征加入树模型重新训练
任务5:特征工程进阶
使用gensim和Pandas完成下列统计【目标域 + 原域】:
- 使用word2vec训练广告序列和实体序列
- 聚合得到用户word2vec编码
- 计算用户与当前广告序列的相似度



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











