









为什么要用堆不用数组?
使用数组的核心问题是:数组自身不带排序功能,只能用 sort() 函数,导致时间复杂度过高。
因此我们考虑使用自带排序功能的数据结构——堆。
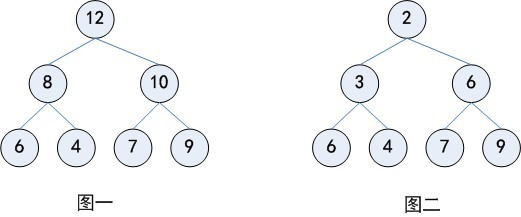
图二是最小堆
思路:
- 题目是求在一组数据里面,求第k大的值,为了减少循环次数(时间复杂度),里面巧妙地运用了python的第三方库heapq,运用最小堆,控制堆的大小,比如k=3,那么堆只能有三个节点,这样可以保证堆顶元素是第k大元素
- 在每次 add() 的时候,将新元素 push() 到堆中(堆会自动排序),如果此时堆中的元素超过了 K,那么需要把堆中的最小元素(堆顶)pop() 出来。
- 此时堆中的最小元素(堆顶)就是整个数据流中的第 K大元素。
class KthLargest(object):
def __init__(self, k, nums):
"""
:type k: int
:type nums: List[int]
"""
self.k = k
self.que = nums
heapq.heapify(self.que)
def add(self, val):
"""
:type val: int
:rtype: int
"""
heapq.heappush(self.que, val)
while len(self.que) > self.k:
print(self.que)
heapq.heappop(self.que)
return self.que[0]
# Your KthLargest object will be instantiated and called as such:
# obj = KthLargest(k, nums)
# param_1 = obj.add(val)















 1718
1718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









