







人工智能专栏文章汇总:人工智能学习专栏文章汇总-CSDN博客
本篇目录
8.1.1 一些本机CPU可运行的飞桨预训练简单模型(亲测可用)
八、百度飞桨套件使用
深度学习的探索目标:
- 需要针对业务场景提出建模方案;
- 探索众多的复杂模型哪个更加有效;
- 探索将模型部署到各种类型的硬件上。
基于飞桨的开发套件进行开发和学习,可以解决模型资源,二次开发和工业部署的问题:

8.1 飞桨预训练模型套件PaddleHub
PaddleHub属于预训练模型应用工具,集成了最优秀的算法模型,开发者可以快速使用高质量的预训练模型结合Fine-tune API快速完成模型迁移到部署的全流程工作。
8.1.1 一些本机CPU可运行的飞桨预训练简单模型(亲测可用)
注意代码运行前,需要安装相应的Paddle包(代码最开始的几行注释即为安装过程)
8.1.1.1 人脸检测模型
#pip install paddle
#pip install paddlehub==2.1
#hub install ultra_light_fast_generic_face_detector_1mb_640==1.1.2
import paddlehub as hub
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
module = hub.Module(name="ultra_light_fast_generic_face_detector_1mb_640")
res = module.face_detection(paths = ["./test.jpg"], visualization=True, output_dir='test_face_detection_output')
res_img_path = './test_face_detection_output/test.jpg'
img = mpimg.imread(res_img_path)
plt.figure(figsize=(10, 10))
plt.imshow(img)
plt.axis('off')
plt.show()8.1.1.2 中文分词模型
#pip install paddle
#pip install paddlehub==2.1
#hub install ultra_light_fast_generic_face_detector_1mb_640==1.1.2
import paddlehub as hub
lac = hub.Module(name="lac")
test_text = ["1996年,曾经是微软员工的加布·纽维尔和麦克·哈灵顿一同创建了Valve软件公司。他们在1996年下半年从id software取得了雷神之锤引擎的使用许可,用来开发半条命系列。"]
res = lac.lexical_analysis(texts = test_text)
print("中文词法分析结果:", res)8.1.2 预训练模型Fine-tune
研究神经网络模型层间特征图可视化的工作表明,模型最前端的神经网络层倾向于提取一些普遍的、共有的视觉特征,如纹理、边缘等信息。越往后则越倾向于任务相关的特征。涉及计算机视觉图像分类的模型,在特征提取功能上,更多的依赖模型的前端的神经层,而将特征映射到标签的功能则更多的依赖于模型末端的神经层。
也就是说,越靠近输出的神经网络层越具有任务相关性。NLP领域的第三范式(pre-trained + fine tune)便是采用了这种思想。语言模型在大规模语料上进行预训练之后,便具有了强大的语义表征能力。将PLM接上后续任务相关的神经网络层进行微调,便可以在下游任务中获得更好的效果。
因此我们可以基于预训练模型,通过使用私有数据对模型进行Fine-tune,从而实现模型的迁移。
要实现迁移学习,包括如下步骤:
- 安装PaddleHub
- 数据准备
- 模型准备
- 训练准备
具体做法可以参考:飞桨AI Studio星河社区-人工智能学习与实训社区
8.2 飞桨开发套件
如果说PaddleHub提供的是AI任务快速运行方案(POC),飞桨的开发套件则是比PaddleHub提供“更丰富的模型调节”和“领域相关的配套工具”,开发者基于这些开发套件可以实现当前应用场景中的最优方案(State of the Art)。
PaddleHub属于预训练模型应用工具,集成了最优秀的算法模型,开发者可以快速使用高质量的预训练模型结合Fine-tune API快速完成模型迁移到部署的全流程工作。但是在某些场景下,开发者不仅仅满足于快速运行,而是希望能在开源算法的基础上继续调优,实现最佳方案。如果将PaddleHub视为一个拿来即用的工具,飞桨的开发套件则是工具箱,工具箱中不仅包含多种多样的工具(深度学习算法模型),更包含了这些工具的制作方法(模型训练调优方案)。如果工具不合适,可以自行调整工具以便使用起来更顺手。
飞桨提供了一系列的开发套件,内容涵盖各个领域和方向:
- 计算机视觉领域:图像分割 PaddleSeg、目标检测 PaddleDetection、图像分类 PaddleClas、海量类别分类 PLSC,文字识别 PaddleOCR;
- 自然语言领域:语义理解 ERNIE;
- 语音领域:语音识别 DeepSpeech、语音合成 Parakeet;
- 推荐领域:弹性计算推荐 ElasticCTR;
- 其他领域:图学习框架 PGL、深度强化学习框架 PARL。

下面以PaddleSeg为例,介绍飞桨开发套件的使用方式。其余开发套件的使用模式相似,均包括快速运行的命令、丰富优化选项的配置文件和与该领域问题配套的专项工具。如果读者对其他领域有需求,可以查阅对应开发套件的使用文档。
8.2.1 PaddleSeg - 图像分割
图像分割任务是对每个像素点进行分类,需要给出每个像素点是什么分类的概率。
一般图像分割网络结构:

(1)网络的输入是H×W(H为高、W为宽)像素的图片,输出是N×H×W的概率图。输出的概率图大小和输入一致(H×W),而这个N就是类别。
(2)中间的网络结构分为Encoder(编码)和Decoder(解码)两部分。Encoder部分是下采样的过程,这是为了增大网络感受野,类似于缩小地图,利于看到更大的区域范围找到区域边界;Decoder部分是上采样的过程,为了恢复像素级别的特征地图,以实现像素点的分类,类似于放大地图,标注图像分割边界时更精细。
PaddleSeg覆盖了DeepLabv3+、U-Net、PSPNet、HRNet和Fast-SCNN等20+主流分割模型,并提供了多个损失函数和多种数据增强方法等高级功能,用户可以根据使用场景从PaddleSeg中选择出合适的图像分割方案,从而更快捷高效地完成图像分割应用。
实例:医学视盘分割
使用过程包括PaddleSeg环境安装,数据处理,模型选择和训练,模型评估,模型导出,模型部署等。具体过程可参考:飞桨AI Studio星河社区-人工智能学习与实训社区
8.2.2 PaddleNLP - 自然语言处理
PaddleNLP是基于Paddle框架开发的自然语言处理 (NLP) 开源项目,项目中包含工具、算法、模型和数据多种资源。PaddleNLP通过丰富的模型库、简洁易用的API,提供飞桨2.0的最佳实践并加速NLP领域应用产业落地效率。
GitHub链接:https://github.com/PaddlePaddle/PaddleNLP
丰富的模型库:涵盖了NLP主流应用相关的前沿模型,包括中文词向量、预训练模型、词法分析、文本分类、文本匹配、文本生成、机器翻译、通用对话、问答系统等。
实例:基于ERNIE模型的新闻标题分类
下面,我们将展示如何基于PaddleNLP中的预训练模型ERINE来实现另外一个文本分类的任务:对新闻标题进行分类。文本分类是指人们使用计算机将文本数据进行自动化归类的任务,是自然语言处理(NLP)中的一项重要任务。
本案例的模型实现方案如下图所示, 模型的输入是新闻标题的文本,模型的输出就是新闻标题的类别。在建模过程中,对于输入的新闻标题文本,首先需要进行数据处理生成规整的文本序列数据,包括语句分词、将词转换为id,过长文本截断、过短文本填充等等操作;然后使用预训练模型ERNIE对文本序列进行编码,获得文本的语义向量表示;最后经过全连接层和softmax处理得到文本属于各个新闻类别的概率。方案中不仅会使用ERNIE预训练模型,还会使用大量PaddleNLP的API,更便捷的完成数据处理和模型评估等工作。
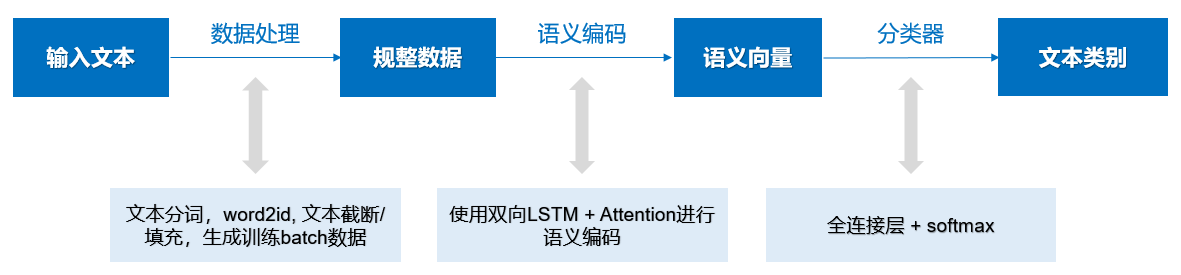
ERNIE是基于Transfomer模型进行的改进,Transfomer模型是一种比LSTM更加复杂的、适合处理序列数据的模型,它使用Self-attenion的方法,将RNN变成每个输入与其他输入部分计算匹配度来决定注意力权重的方式,使得模型引入了Attention机制的同时也具备了并行化计算的能力。以这种Self-attention结构为核心,设计Encoder-Decoder的结构形成Transformer模型。BERT和ERNIE均是将Transformer的Encoder部分结构单独取出,用多个的非标记语料(转成标记数据,如填空/判断句子连续性等)的任务训练,并将得到的Encoder向量作为词汇的基础语义表示用于多种NLP任务(如阅读理解)的模型。
关于Transfomer模型可参考:Transfomer模型详解
使用过程包括PaddleSeg环境安装,数据处理,模型选择和训练,模型评估,模型导出,模型部署等。具体过程可参考:飞桨AI Studio星河社区-人工智能学习与实训社区
——————————————————————————————————————
关注微信公众号【数字众生】即刻获取干货满满的 “AI学习大礼包” 和 “AI副业变现指南”
















 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











