









一. 在Linux环境下,用Linux基本命令完成如下操作:
1、切换到/home/qqbook/script目录下 ;
2、在该目录下,查找包含有“feidu”文本内容的所有文件名。
cd /home/qqbook/scrip/
find /home/qqbook/script/ -type f -exec grep feidu {} \;find 命令 用于在文件树中查找文件,并作出相应的处理。
-exec: find命令对匹配的文件执行该参数所给出的shell命令。相应命令的形式为'command' { } \;
-type 查找某一类型的文件,诸如:
b - 块设备文件
d - 目录
c - 字符设备文件
l - 符号链接文件
p - 管道文件
f - 普通文件
二. 有两个文件,分别有20亿个QQ号(bigint类型,8字节),我们只有2G内存,如何找到两个文件交集?
步骤1:使用hash函数将第一个文件的所有整数映射到1000个文件中,每个文件有2000万个整数,大约160M内存,内存可以放下,把1000个文件记为 a1,a2,a3.....a1000;
步骤2:用同样的hash函数映射第二个文件到1000个文件中,这1000个文件记为b1,b2,b3......b1000;
步骤3:由于使用的是相同的hash函数,所以两个文件中一样的数字会被分配到文件下标一致的文件中,分别对a1和b1求交集,a2和b2求交集,ai和bi求交集;
步骤4;最后将步骤3的结果汇总,即为两个文件的交集。
三. QQ阅读的阅读行为日志的文件/home/log/aa.txt,占用存储1.5T,在Linux环境下,用Linux基本命令完成如下操作:
1、统计该文件具体有多少行记录;
2、查看第12行到第15行这四行记录。【提示:有非常多种方法:①使用管道;②使用awk;③使用sed。总之请1行搞定。】
wc -l /home/log/aa.txtsed -n '12,15p'/home/log/aa.txt
cat /home/log/aa.txt | tail -n +12 | head -n 4【一】从第3000行开始,显示1000行。即显示3000~3999行
cat filename | tail -n +3000 | head -n 1000
【二】显示1000行到3000行
cat filename| head -n 3000 | tail -n +1000
*注意两种方法的顺序
分解:
tail -n 1000:显示最后1000行
tail -n +1000:从1000行开始显示,显示1000行以后的
head -n 1000:显示前面1000行
【三】用sed命令
sed -n ‘5,10p’ filename 这样你就可以只查看文件的第5行到第10行。四. 我们知道Kimball的维度建模里面将事实表按粒度划分成了三种主要的事实表,包括:事务事实表,周期快照事实表和累积快照事实表。请问这三种事实表有什么区别?
【提示:可从定义、粒度、用途、事实表更新机制、使用场景等多个角度进行比较】
参考:
定义:
事务事实表
一条记录代表了业务系统中的一个事件。事务出现后,就会在事实中出现一条记录。以订单域举例:下单是一个事实;付款是一个事实;退款是一个事实。
周期快照事实表
记录指定周期内一些聚集事务值或者度量状态。如:库存日快照事实表。
累积快照事实表
用于研究业务过程中各里程碑事件之间的时间间隔,一般会用一个字段记录最后更新时间。如:订单各种状态的开始结束时间。
其他区别:
从用途角度:事务事实表,离散时间点记录事务;周期快照事实表,以规律的间隔产生实施快照;累积快照事实表,时间跨度不确定且不断变化的业务事实。
从时间/日期角度:事务事实表,时间;周期快照事实表,日期;累积快照事实表,时间跨度较短的多个时点。
从粒度角度:事务事实表,每行代表一个事务;周期快照事实表,每个代表一个时间周期内的事实;累积快照事实表,每行代表一个业务周期事务事实。
从事实角度:事务事实表,交易活动;周期快照事实表,时间周期内的绩效;累积快照事实表,限定多个业务阶段内的绩效。
从事实表更新角度:事务事实表,只插入、不更新;周期快照事实表,只插入、不更新;累积快照事实表,新事件产生时更新、可插入、可更新。
五. 谈谈数据倾斜是如何发生的?并给出优化方案
参考:
1)group by时倾斜
解决方式:hive.groupby.skewindata=true
2)join时倾斜。对于一些热点key,他们所在的reduce运行比较慢。
解决方式:过滤不正常的记录;数据去重;使用map join;打开set Hive.optimize.skewjoin = true;
3)无法从sql层面优化时,可以从业务算法角度提升
只读需要的列和分区;周,月任务按天累计计算;先聚合后join
4)reduce任务数不合理导致
set mapred.reduce.tasks=N
5)多维分析带来的低效
当含有rollup和cube语句的from子句中包含子查询或者join时,将子查询或join的结果放到临时表,然后从临时表中读取数据做多维分析
6)业务数据本身存在倾斜
配置参数,优化SQL语句,将数据值较多的数据分散到多个reducer中
六. hdfs存储机制是怎样的?
<一>. HDFS写数据流程
1.客户端向Namenode请求上传文件
2. Namenode受到请求后首先检查权限,再检查是否有该目录,给客户端回复
3. 请求上传Block,请求返回DataNode
4. 返回dn1,dn2,dn3结点,表示用这三个结点存储数据
5. 客户端选择一个DataNode,建立Block传输(最小传输大小为64k的Packet(Packet里最小是Chunk)),然后此结点与其他DataNode建立传输,传输成功后会返回ACK
<二>. HDFS读数据流程
1. 客户端向NameNode请求读数据
2. Namenode对客户端的群贤进行判断,并检查是否有相应文件,最后返回文件的元数据
3. 客户端创建流对象,考虑负载的情况,读取结点距离最近副本和的DataNode
4. 若第一个对象负载太大,可以到第二个DataNode读取数据,注意,只能串行读。
七. 请列出你所知道的hadoop调度器,并简要说明其工作方法
三种调度器分别是FIFO(先入先出调度器),hadoop1.x默认用的就是FIFO。FIFO采用队列的方式将一个一个job任务按照时间先后顺序进行服务。
capacity scheduler(容量调度器),hadoop2.x默认使用的是容量调度器。支持多个队列,每个队列配备一定的资源。每个队列采用FIFO方式调度。
公平调度器(Fair Scheduler),支持多个队列,每个队列配备一定的资源,每个队列内部job公平共享队列内部的所有资源。
八. Hive中两大表连接,发生了数据倾斜,有一个reduce无法完成,检查发现t1中guid=''的记录有很多,其他guid都不重复,这条语句该怎样优化?
select t1.*,nvl(t2.x,1)
from t1 left join t2
on t1.guid = t2.guid对guid字段中的空串加随机数,打散到其他的reducer中,避免这个reducer的压力太大
select t1.*, nvl(t2.x,1)
from t1 left join t2
on (case when t1.guid='' then concat('yuewen', rand()) else t1.guid end)=t2.guid;
九. 某种产品中,合格品率为0.96.一个合格品被检查成次品的概率是0.02,一个次品被检查成合格品的概率为0.05. 问题:求一个被检查成合格品的产品确实为合格品的概率.
合格率0.96 那么不合格率0.04
次品被检查成合格品0.05
合格品被检查成次品0.02
一个被检查成合格品的产品:0.96*(1-0.02)+0.04*0.05
确实为合格品:0.96*(1-0.02)
ans=0.96*(1-0.02)/(0.96*(1-0.02)+0.04*0.05)十. 有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M,要求返回频数最高的100个词
参考:
1). 顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为f0 ,f1 ,… ,f4999)中,这样每个文件大概是200k左右,如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M;
2). 对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100词及相应的频率存入文件,这样又得到了5000个文件;
3). 把这5000个文件进行归并(类似与归并排序);
另:先用hash进行分文件,每个文件不超过1M,对每个文件进行wordcount,最后再对结果文件进行汇总,得到词频最高的top100
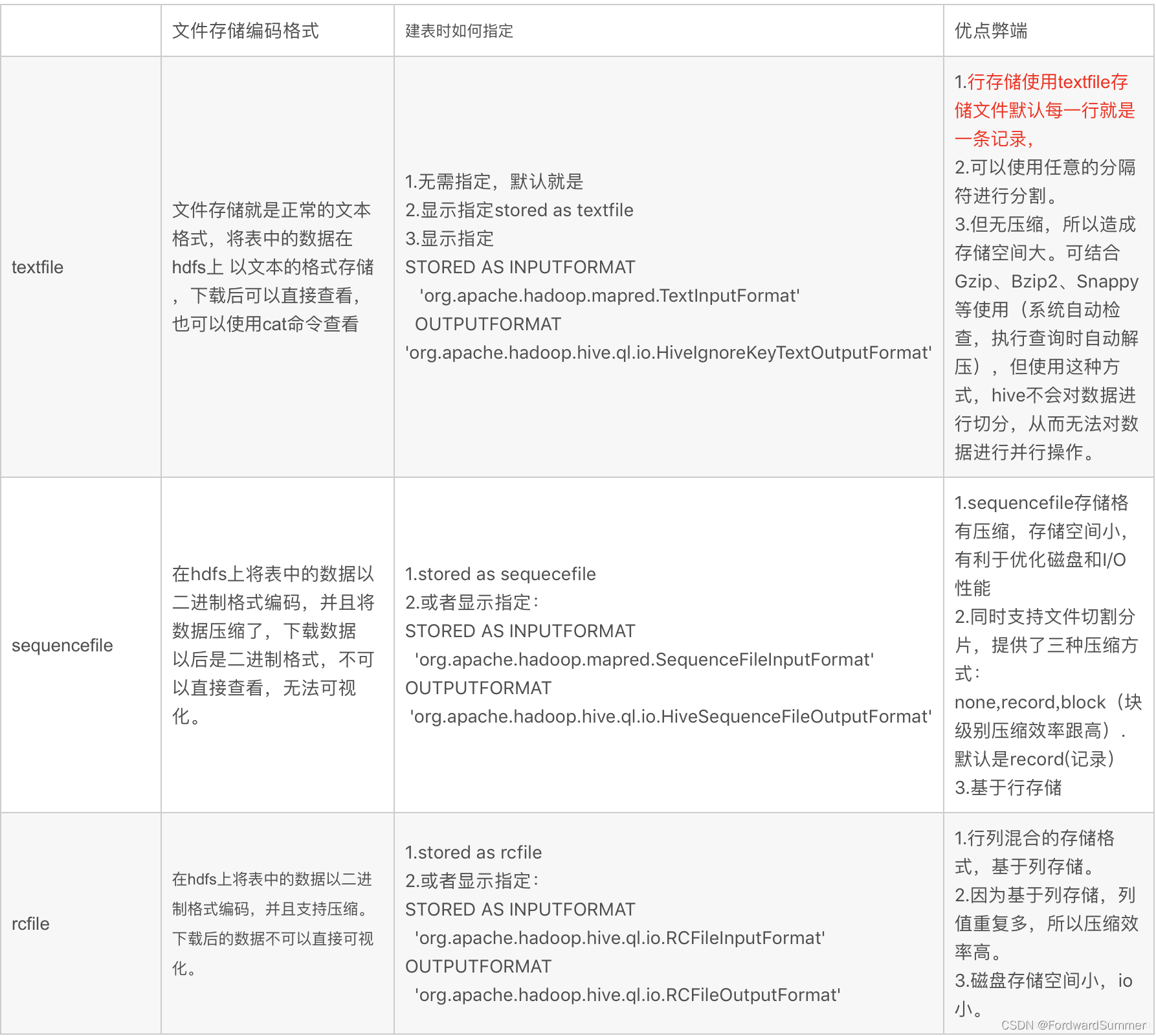
十一. hive 中的压缩格式 RCFile、TextFile、SequenceFile各有什么区别?
参考:
TextFile:Hive默认格式,不作压缩,磁盘及网络开销较大。可以结合Gzip, Bzip2使用,但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
SequenceFile: SequenceFile 是Hadoop API提供支持的一种二进制文件,具有使用方便,可分割,可压缩的特点,支持三种压缩选择:NONE, RECORD, BLOCK。RECORD压缩率低,一般建议使用BLOCK压缩。
RCFILE: RCFILE是一种行列存储相结合的的存储方式。首先,将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩。
十二. hive 内部表和外部表的区别?
参考:
内部表:建表时会在 hdfs 创建一个表的存储目录,增加分区的时候,会将数据复制到此location下,删除数据的时候,将表的数据和元数据一起删除。
外部表:一般会建立分区,增加分区的时候不会将数据移到此表的 location下,删除数据的时候,只删除了表的元数据信息,表的数据不会删除。
另:
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table);
区别:
1.内部表数据由Hive自身管理,外部表数据由HDFS管理;
2.内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己指定;
3.删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
4.对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
5.Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
十三. Hive 的 sort by 和 order by 的区别?
order by 会对输入数据做全局排序,只有一个reduce,数据量较大时,很慢。
sort by 不是全局排序,只能保证每个reduce有序,不能保证全局有序,需设置mapred.reduce.tasks>1。
十四. 常见的聚类算法可以分为几类?
参考:
聚类分析的算法可以分为划分法、层次法、基于密度的方法、基于网格的方法、基于模型的方法。
1、划分法,给定一个有N个元组或者纪录的数据集,分裂法将构造K个分组,每一个分组就代表一个聚类,K<N。
2、层次法,这种方法对给定的数据集进行层次似的分解,直到某种条件满足为止。
3、基于密度的方法,基于密度的方法与其它方法的一个根本区别是:它不是基于各种各样的距离的,而是基于密度的。这样就能克服基于距离的算法只能发现“类圆形”的聚类的缺点。
4、图论聚类方法解决的第一步是建立与问题相适应的图,图的节点对应于被分析数据的最小单元,图的边(或弧)对应于最小处理单元数据之间的相似性度量。
5、基于网格的方法,这种方法首先将数据空间划分成为有限个单元的网格结构,所有的处理都是以单个的单元为对象的。
6、基于模型的方法,基于模型的方法给每一个聚类假定一个模型,然后去寻找能够很好的满足这个模型的数据集。
十五. 常见分类算法有哪些?
参考:
1、决策树分类
2、基于规则分类
3、最邻近分类(K-NN)
4、朴素贝叶斯分类器
5、人工神经网络
6、支持向量机(SVM)
参考来源:
【1】牛客 公司真题















 1827
1827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









