






代码和项目的组织
变量名覆盖
错误用法
func Test() (err error) {
if test() {
err := fmt.Error("error")
}
return err // 这里的err永远都会是nil
}
正确用法
func Test() (err error) {
if test() {
if err := fmt.Error("error"); err != nil {
return err // 出错及时返回
}
}
return err
}
减少不必要的嵌套代码
函数的嵌套越多,其复杂度就越高,可读性就越低,需要尽可能的较少不必要的if else循环
错误用法
if foo() {
...
return true
} else {
...
}
正确用法
if foo() {
...
return true
}
...
滥用 init 函数
Init 函数的缺点
- 限制了 error 处理
- 让测试更加复杂,因为一旦外部包引入对应的package,会先执行对应的 init 函数
- 如果init函数里面需要设置对应的状态,则必须使用全部变量来完成
什么时候才考虑使用init函数?
答:在定义一些静态的配置的时候,注意是静态配置,意味这些配置在初始化后永远不会被改变;否则大多数时候我们应该尽量避免使用init函数,而是手动定义函数调用来执行必要的操作
接口污染
记住一个谚语:接口中包含的方法越多,这个接口的抽象性就越低
接口中添加的方法越多就会降低其服用性,比如 io.Reader 和 io.Writer 就是一个很好的抽象因为其不能再简单了;但是我们可以将接口结合起来来创建更高级别的抽象,io.ReadWriter 就是一个很好的例子
type ReadWriter interface {
Reader
Writer
}
什么时候应该使用接口
- 抽象公共的行为
当多个类型都具有一个相同的行为的时候,这时候这个行为就应该抽象成接口
比如,标准库里面的 sort 使用
type Interface interface {
Len() int // Number of elements
Less(i, j int) bool // Checks two elements
Swap(i, j int) // Swaps two elements
}
这个接口的复用性就特别高,因为其包含了公共的行为用来排序任何的元素
- 解耦
如果我们依赖的是一个抽象,而不是一个具体的实现,那这个抽象行为实现我们后可能存在另外一种更方便的形式实现,使用抽象这样就不需要改动代码
比如下面这个例子
type CustomerService struct {
store mysql.Store // Depends on the concrete implementation
}
func (cs CustomerService) CreateNewCustomer(id string) error {
customer := Customer{id: id}
return cs.store.StoreCustomer(customer)
}
CustomerService 这个结构体依赖的是一个具体的实现,而不是一个抽象的interface,这就会带来两个问题
- 如果我想替换实现,岂不是代码改动很大
- 写单元测试的话,由于结构体里面是一个具体的实现,那么单测里面也必须实现这个结构体才行
我们尝试将上面的代码改写为如下:
type customerStorer interface { // Creates a storage abstraction
StoreCustomer(Customer) error
}
type CustomerService struct {
storer customerStorer // Decouples CustomerService from the actual implementation
}
func (cs CustomerService) CreateNewCustomer(id string) error {
customer := Customer{id: id}
return cs.storer.StoreCustomer(customer)
}
CustomerService 里面是一个抽象的接口而不是一个具体的实现,这样我们单测就可以直接mock接口进行测试,另外其他类型实现了这个接口,替换也很方便
- 限制行为
我们看下面这个例子
type IntConfig struct {
// ...
}
func (c *IntConfig) Get() int {
// Retrieve configuration
}
func (c *IntConfig) Set(value int) {
// Update configuration
}
我们实现的 IntConfig 有两个公有的方法 Get 和 Set
假定一种情况,我们接受到 IntConfig 结构体,但是在我们的逻辑里面只关心怎么获取对应的配置的具体的值,我们不想任何人修改或者更新,就是要禁用 Set 操作
这种情况下我们就可以通过 interface 来限制响应的行为,我们定义一个接口只包含Get 方法
type intConfigGetter interface {
Get() int
}
然后在我们的代码里面,我们可以只依赖 intConfigGetter 而无需具体的实现,构造NewFoo 的时候将 InitConfig 传入,然后整个 Foo 里面都通过接口来进行调用
type Foo struct {
threshold intConfigGetter
}
func NewFoo(threshold intConfigGetter) Foo { // Injects the configuration getter
return Foo{threshold: threshold}
}
func (f Foo) Bar() {
threshold := f.threshold.Get() // Reads the configuration
// ...
}
函数返回参数不要接口类型
为了避免灵活性降低,一个好的函数返回参数应该避免是接口,而是一个具体的类型,因为如果返回的是接口类型,那么上层调用的所有客户端必须都依赖一个同样的抽象
但是函数的输入参数应该尽可能使用接口,这样可以给客户端更灵活的实现方式
any 使用注意
什么时候应该使用any?
答:当你确实需要接口或者返回任何类型,比如 json 序列化
json.Marshal(any)
一般情况下,我们应该避免过度概括我们编写的代码;甚至为了代码的可读性,有时候是可以牺牲写一些较重复的代码的
没有意识到字段嵌套可能带来的问题
什么是 Go 的类型嵌套
type Foo struct {
Bar // Embedded field
}
type Bar struct {
Baz int
}
在 Foo 结构体中,声明 Bar 类型时没有关联名称,所以 Bar 是 Foo 的一个嵌套字段
我们可以使用嵌套字段将底层类型的字段和方法提取到上层,比如 Foo 就可以直接使用 Baz 字段
首先注意,使用字段嵌套大多数情况都不是必须的,很多情况我们都可以使用通过不使用字段嵌套来解决
但是当需要使用字段嵌套的时,想清楚下面两个问题
- 字段嵌套不应该就是为了实现一些语法糖,比如 Foo.Baz() 而不用写成 Foo.Bar.Bac(); 如果是为了达到这个目的,不要使用内嵌的字段
- 字段嵌套不应该把结构体的一些私有的方法或者变量暴露到外面,比如允许上层调用通过字段嵌套访问到了一些应该对结构体私有的加锁或者释放锁的行为
错误使用
type Foo struct {
Bar
}
type Bar struct {
Baz int
}
func fooBar() {
foo := Foo{}
foo.Baz = 42
}
正确使用
type Logger struct {
writeCloser io.WriteCloser
}
func (l Logger) Write(p []byte) (int, error) {
return l.writeCloser.Write(p)
}
func (l Logger) Close() error {
return l.writeCloser.Close()
}
func main() {
l := Logger{writeCloser: os.Stdout}
_, _ = l.Write([]byte("foo"))
_ = l.Close()
}
多使用函数选项模式
函数式选项模式提供了一种方便且 API 友好的方式来处理选项
选项模式思路如下
- 未导出的结构体拥有对应的配置选项 options
- 每个选项是一个返回相同类型的函数:
type Option func(options *options) error,比如,WithPort接受一个int参数代表端口并且返回Option类型代表怎样更新 options 结构体
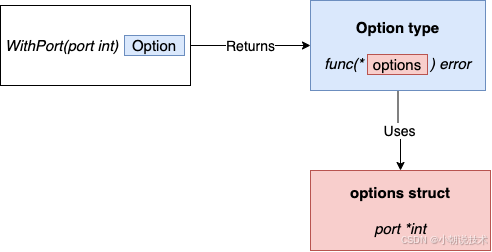
type options struct {
port *int
}
type Option func(options *options) error
func WithPort(port int) Option {
return func(options *options) error {
if port < 0 {
return errors.New("port should be positive")
}
options.port = &port
return nil
}
}
func NewServer(addr string, opts ...Option) (*http.Server, error) {
var options options
for _, opt := range opts {
err := opt(&options)
if err != nil {
return nil, err
}
}
// At this stage, the options struct is built and contains the config
// Therefore, we can implement our logic related to port configuration
var port int
if options.port == nil {
port = defaultHTTPPort
} else {
if *options.port == 0 {
port = randomPort()
} else {
port = *options.port
}
}
// ...
}
项目错误组织(项目结构和包组织不正确)
参考 Golang官方给出的:https://go.dev/doc/modules/layout
创建 utility package
命名是应用设计的关键一环,创建包名比如 common、uitl 以及 shared 不会给读者带来太多的价值
根据包提供的内容(而不是包含的内容)来命名包可能是提高其表现力的有效方法
package stringset
type Set map[string]struct{}
func New(...string) Set { return nil }
func (s Set) Sort() []string { return nil }
比如上面这个 package 就应该叫 stringset,而不是叫什么 util
务必使用 linter 和 formatters
Linter 是一个自动化工具用来分析代码和捕捉错误,包括下面这几种
- https://golang.org/cmd/vet—A standard Go analyzer
- https://github.com/kisielk/errcheck—An error checker
- https://github.com/fzipp/gocyclo—A cyclomatic complexity analyzer
- https://github.com/jgautheron/goconst—A repeated string constants analyzer
formatters 工具是代码格式化工具,包括下面这几种
- https://golang.org/cmd/gofmt—A standard Go code formatter
- https://godoc.org/golang.org/x/tools/cmd/goimports—A standard Go imports formatter
除此之外,建立也打开golangci-lint,是一个能够允许并行运行 linters 的工具,能够提高分析的速率
数据类型
与其他进制混淆
通常情况下代码里面都是十进制居多,但是也会有其他进制存在
比如八进制以0开头,010代表十进制里面的8
为了提供可读性和避免潜在的错误,每个非是进制的表达应该开头要显示声明下,比如
- 二进制:使用 0b 或者 0B 前缀,比如 0b100
- 十六进制:使用 0x 或者 0X 前缀,比如 0xF
- 十进制:如果数字太长,为了提高可读性可使用下划线,比如 1_000_000_000
func main() {
sum := 100 + 0o10
fmt.Println(sum)
}
浮点数理解错误
在Go中,浮点数的计算其实是数学计算的近似值;比如
var n float32 = 1.0001
fmt.Println(n * n)
上面的输出期待结果是 1.0001 * 1.0001 = 1.00020001,但是实际的输出结果是 1.0002
因为 Go 语言中的 float32 和 float64 类型是近似值,我们使用浮点数需要牢记下面几点
- 当比较两个浮点数时,不应该使用 == ,而是做差取绝对值满足一个较小的值即可
- 执行加法或减法时,将具有相似数量级的运算分组以获得更高的准确性
- 为了保证准确性,如果一系列运算需要加法、减法、乘法或除法,请先执行乘法和除法运算
func f1(n int) float64 {
result := 10_000.
for i := 0; i < n; i++ {
result += 1.0001
}
return result
}
func f2(n int) float64 {
result := 0.
for i := 0; i < n; i++ {
result += 1.0001
}
return result + 10_000.
}
f1(10) 和 f2(10) 输出的结果是不一样的
不理解切片的长度和容量
s := make([]int, 3, 6) // Three-length, six-capacity slice
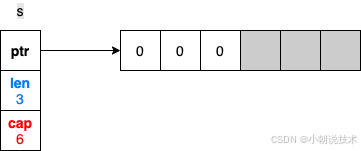
使用 make 构造切片时,第一个参数是长度,第二个是容量;如上图所示,会初始化一个六个空间的数组,但是只会有三个空间存在元素占位
对切片长度以外的位置进行赋值是违法的,比如
s[4] = 0
panic: runtime error: index out of range [4] with length 3
但是我们怎么使用切片剩下的空间呢,使用 append 即可,append 会使用已经分配但是还未使用的空间
s = append(s, 2)
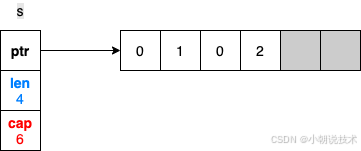
现在这个切片的长度已经是4了,如果我们继续append会发生什么
s = append(s, 3, 4, 5)
fmt.Println(s)
[0 1 0 2 3 4 5]
Slice 底层其实也是利用的数组,但是数组是一个固定的结果,也就是无法动态扩容,所以原来切片的底层数组只能存储到元素4空间就满了,当我们继续 append 新的元素时,就会触发数组的拷贝
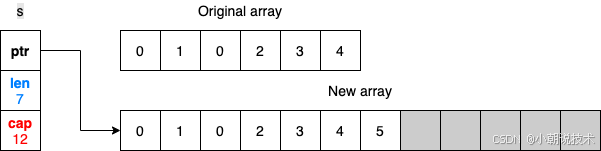
Go 语言会自动扩容到原来的容量的两倍,原来的切片如果没有被其他变量引用,则会自动被垃圾回收掉
对现存的切片做 Slicing 会发生什么
s1 := make([]int, 3, 6) // Three-length, six-capacity slice
s2 := s1[ 1 : 3 ] // Slicing from indices 1 to 3
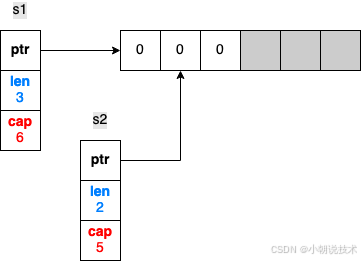
我们对 s2 是取 s1 的元素,所以现在 s1 和 s2 指向的是同一个底层数组
s1[1] = 2 或者 s2[2] = 1
s2 = append(s2, 2)
fmt.Println(s1, s2)
输出 s1=[0 1 0], s2=[1 0 2]
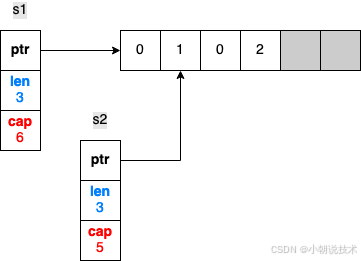
如果我们继续对 s2 做 append 操作会发生什么
s2 = append(s2, 3)
s2 = append(s2, 4) // At this stage, the backing is already full
s2 = append(s2, 5)
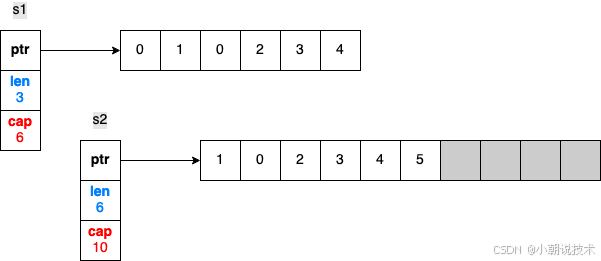
可以看到当append的元素个数已经超过原来的容量的时候,此时 s1 和 s2 则分别指向了两个不同的底层数组
s1 依然是一个长度为3,容量为 6 的切片
s2 由于是从旧的数组下标为1开始复制,所以新的数组是从 1 开头,而不是以 0 开头
切片的初始化
切片初始化一律使用 make 来进行,但是 make 存在两个参数可以指定长度和容量
通常分配切片的方式就是指定给定的容量或者给定的长度,如果指定容量然后使用append通常会更容易阅读,如果指定长度性能会更好更快
所以就按下面这种方式来,指定长度,不够再Append即可
type Foo struct{}
type Bar struct{}
func fooToBar(foo Foo) Bar {
return Bar{}
}
func convertGivenLength(foos []Foo) []Bar {
n := len(foos)
bars := make([]Bar, n)
for i, foo := range foos {
bars[i] = fooToBar(foo)
}
return bars
}
不理解切片为 nil 和空切片
nil 切片是空的,但是空切片不是 nil 的,nil 切片不需要分配任何空间,切片初始化的三种选择方式
var s []string如果我们不确定长度并且切片可以为空[]string(nil)创建 nil 和空切片的语法糖(不推荐使用)make([]string, length)如果这个切片的长度是明确知道的
空切片 & nil切片
var s []string
空切片 & nil切片
s = []string(nil)
空切片
s = []string{}
空切片
s = make([]string, 0)
未正确检查切片是否为空
检查切片是否包含任何元素,应该检查这个切片的长度,而不是检查这个切片是否为nil
与此同时在设计接口的时候,应该避免区分空切片和nil切片,这可能导致一些不易发现的错误
错误复制切片
将一个切片复制到另外一个切片,使用内置的 copy 函数即可,但是需要记住复制元素的数量对应于两个切片长度之间的最小值
func bad() {
src := []int{0, 1, 2}
var dst []int
copy(dst, src)
fmt.Println(dst) // 输出0,因为dst切片的长度是0
}
func correct() {
src := []int{0, 1, 2}
dst := make([]int, len(src))
copy(dst, src)
fmt.Println(dst) // 输出3
}
func main() {
bad()
correct()
}
Map 的初始化
创建map时,如果已知其长度,则使用给定长度对其进行初始化。这会减少了分配数量并提高了性能
Map 是一个k-v存储的无序集合,Go中的map是基于哈希表实现的
const n = 1_000_000
var global map[int]struct{}
func BenchmarkMapWithoutSize(b *testing.B) {
var local map[int]struct{}
for i := 0; i < b.N; i++ {
m := make(map[int]struct{})
for j := 0; j < n; j++ {
m[j] = struct{}{}
}
}
global = local
}
func BenchmarkMapWithSize(b *testing.B) {
var local map[int]struct{}
for i := 0; i < b.N; i++ {
m := make(map[int]struct{}, n)
for j := 0; j < n; j++ {
m[j] = struct{}{}
}
}
global = local
}
Slice 和 Map内存泄漏(重点)
不正确的比较
通常我们会使用 == 或者 != 来比较元素,但是这都是基于我们比较的元素类型是 comparable 的;否则我们应该使用 reflect.DeepEqual 来进行比较
下面这些类型比较可以使用 == 或者 !=
- Booleans—Compare whether two Booleans are equal.
- Numerics (int, float, and complex types) —Compare whether two numerics are equal.
- Strings—Compare whether two strings are equal.
- Channels—Compare whether two channels were created by the same call to make or if both are nil.
- Interfaces—Compare whether two interfaces have identical dynamic types and equal dynamic values or if both are nil.
- Pointers—Compare whether two pointers point to the same value in memory or if both are nil.
- Structs and arrays—Compare whether they are composed of similar types.
如果比较对象不是 comparable的,比如(slices 或者 maps),需要使用 reflect.DeepEqual 来进行比较,但是使用反射来比较会有一定的性能损失
所以最好的方式是尝试标准库里面的一些比较方法,比如使用 bytes.Compare函数来比较两个byte类型的切片
控制结构
Range 循环误用
Range 范围循环中的值元素是一个副本。因此,例如,要改变结构体,请通过其索引或经典的 for 循环访问它(除非要修改的元素或字段是指针)
Range loop 允许迭代遍历下面类型的元素
- String
- Array
- Pointer to an array
- Slice
- Map
- Receiving channel
但是需要注意range循环里面的值是拷贝的值,不能直接修改元素本身
func createAccounts() []account {
return []account{
{balance: 100.},
{balance: 200.},
{balance: 300.},
}
}
func main() {
错误用法
accounts := createAccounts()
for _, a := range accounts {
a.balance += 1000
}
fmt.Println(accounts)
正确用法
accounts = createAccounts()
for i := range accounts {
accounts[i].balance += 1000
}
fmt.Println(accounts)
}
Range 循环的值是一个短变量
func main() {
done := make(chan bool)
values := []string{"a", "b", "c"}
for _, v := range values {
go func() {
fmt.Println(v)
done <- true
}()
}
// wait for all goroutines to complete before exiting
for _ = range values {
<-done
}
}
在1.22版本之前,上面代码输出相同的值,“c”, “c”, “c”, 而不是 “a”, “b”, and “c” 或者其他顺序
Go 1.22 已经修复了这个问题,参考:https://go.dev/blog/loopvar-preview
不清楚 break 关键字的使用
记住 break 可以终止执行的内容有:for、switch、select 有且仅有这三种
错误用法:
for i := 0; i < 5; i++ {
fmt.Printf("%d ", i)
switch i {
default:
case 2:
break 这样是只会跳出当前的switch循环,不会跳出外层的for循环的
}
}
正确用法:
loop:
for i := 0; i < 5; i++ {
fmt.Printf("%d ", i)
switch i {
default:
case 2:
break loop 定义了一个label,直接跳出loop所在的部分
}
}
Defer 的使用注意事项
当主函数返回之后 defer 函数才会执行,for 循环里面执行 defer 延迟调用一定要注意
错误示例
func readFiles(ch <-chan string) error {
for path := range ch {
file, err := os.Open(path)
if err != nil {
return err
}
// 延迟调用不是在每次循环迭代期间执行,而是在 readFiles 函数返回时执行。如果 readFiles 不返回,文件描述符将永远保持打开状态,从而导致泄漏
defer file.Close()
// Do something with file
}
return nil
}
正确示例
func readFiles(ch <-chan string) error {
for path := range ch {
// 定义函数调用后来执行对应的defer操作
err := func() error {
file, err := os.Open(path)
if err != nil {
return err
}
defer file.Close()
// Do something with file
return nil
}()
if err != nil {
return err
}
}
return nil
}
字符串
不理解 rune
记住下面这几条
- 字符集是一组字符,而编码则描述如何将字符集转换为二进制
- Go 的字符串就是一组不允许修改的字节切片
- rune 是 Unicode 编码的概念
- 在 UTF-8 编码下,一个 Unicode 字符可能会被编码成 1~4 字节
- len() 方法返回的是字节数,而不是 runes 的数量
func main() {
s := "hello"
fmt.Println(len(s)) // 输出5
s = "汉"
fmt.Println(len(s)) // 输出3
s = string([]byte{0xE6, 0xB1, 0x89})
fmt.Printf("%s\n", s) // 输出"汉"
}
字符串错误遍历
字符串遍历请不要使用下标
错误例子如下:
s := "hêllo"
for i := range s {
fmt.Printf("position %d: %c\n", i, s[i])
}
fmt.Printf("len=%d\n", len(s))
输出结果:
position 0: h
position 1: Ã
position 3: l
position 4: l
position 5: o
len=6
可以看到上面让人疑惑的有三个点:
- 第二个字符是 Ã 而不是 ê
- 打印顺序直接从1->3,跳过了第2个字符?
- len() 返回的是6,而不是5
我们尝试将上面字符串的字符编码如下
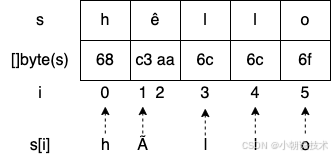
需要注意 fmt.Printf("position %d: %c\n", i, s[i]) 的 s[i] 不是打印第 i 个 rune 字符,打印的是 index 为 i 处字节的 UTF-8 编码格式的字符
所以字符串遍历不应该使用下标
正确用法:
s := "hêllo"
runes := []rune(s)
for i, r := range runes {
fmt.Printf("position %d: %c\n", i, r)
}
注意:有的时候字符串打印,有的人会把字符串转化成 rune 的切片之后再输出,类似下面这种形式
s := "hêllo"
runes := []rune(s)
for i, r := range runes {
fmt.Printf("position %d: %c\n", i, r)
}
非常不推荐这种做法;首先, 字符串转化成rune类型的切片会分配额外的空间,而且遍历又会存在 O(n) 的时间复杂度
Trim 理解有误
strings.TrimRight/strings.TrimLef 删除所有的左前缀或右前缀中包含在指定集合里面的所有元素
strings.TrimSuffix/strings.TrimPrefix 删除给定的前缀或者后缀
fmt.Println(strings.TrimRight("123oxo", "xo"))

func main() {
fmt.Println(strings.TrimRight("123oxo", "xo"))
输出: 123
fmt.Println(strings.TrimSuffix("123oxo", "xo"))
输出: 123o
fmt.Println(strings.TrimLeft("oxo123", "ox"))
输出:123
fmt.Println(strings.TrimPrefix("oxo123", "ox"))
输出:o123
fmt.Println(strings.Trim("oxo123oxo", "ox"))
输出:123
}
字符串拼接
少量字符串拼接使用 += 即可
大量字符串拼接请务必使用 strings.Builder
func concat1(values []string) string {
s := ""
for _, value := range values {
s += value
}
return s
}
func concat2(values []string) string {
sb := strings.Builder{}
for _, value := range values {
_, _ = sb.WriteString(value)
}
return sb.String()
}
func concat3(values []string) string {
total := 0
for i := 0; i < len(values); i++ {
total += len(values[i])
}
sb := strings.Builder{}
sb.Grow(total)
for _, value := range values {
_, _ = sb.WriteString(value)
}
return sb.String()
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









