









干了一周的活,感想就是 SQL 能力要提高,原理要搞清楚。SQL 熟练才能快速写出业务代码。原理搞清楚才能调优。运行一次程序需要一两个小时,调优后可以大大缩短任务运行时间。所以基础很重要。今天继续学习 Spark 的基础——Spark 任务调度机制。
在生产环境下,Spark 集群的部署方式一般为 YARN-Cluster 模式,之后的内核分析内容就 基于 YARN-Cluster 模式。YARN-Cluster 模式以及任务提交流程可以看之前的文章。
之前的文章中提到:
原始的 RDD 通过一系列的转换就就形成了 DAG。RDD 任务会切分 Application、Job、Stage 和 Task。由 Application→Job→Stage→Task每一层都是 1 对 n 的关系。
- Application:初始化一个 SparkContext 即生成一个 Application;
- Job:一个 Application 中以 Action 算子划分 Job,如 collect、saveAsTexFile、show;
- Stage:一个 Job 中以 Shuffle 为边界划分 Stage,如 join、groupByKey、reduceByKey;
- Task:每个 Stage 有一组 Task组成(TaskSet),Task 个数由输入文件的切片(或者说分区数、并行度)决定,将 Stage 划分的结果发送到不同的 Executor 执行即为一个 Task。
于是 Spark 的任务调度总体来说分两路进行,一路是 Stage 级的调度,一路是 Task 级的调度。Spark 会创建两个调度器:DAGScheduler 和 TaskScheduler。
- DAGScheduler 负责 Stage 级的调度,主要是将 job 切分成若干 Stages,并将每个 Stage 打包成 TaskSet 交给 TaskScheduler 调度。
- TaskScheduler 负责 Task 级的调度,将 DAGScheduler 给过来的 TaskSet 按照指定的调度策略分发到 Executor 上执行,调度过程中 SchedulerBackend 负责提供可用资源,其中 SchedulerBackend 有多种实现,分别对接不同的资源管理系统。
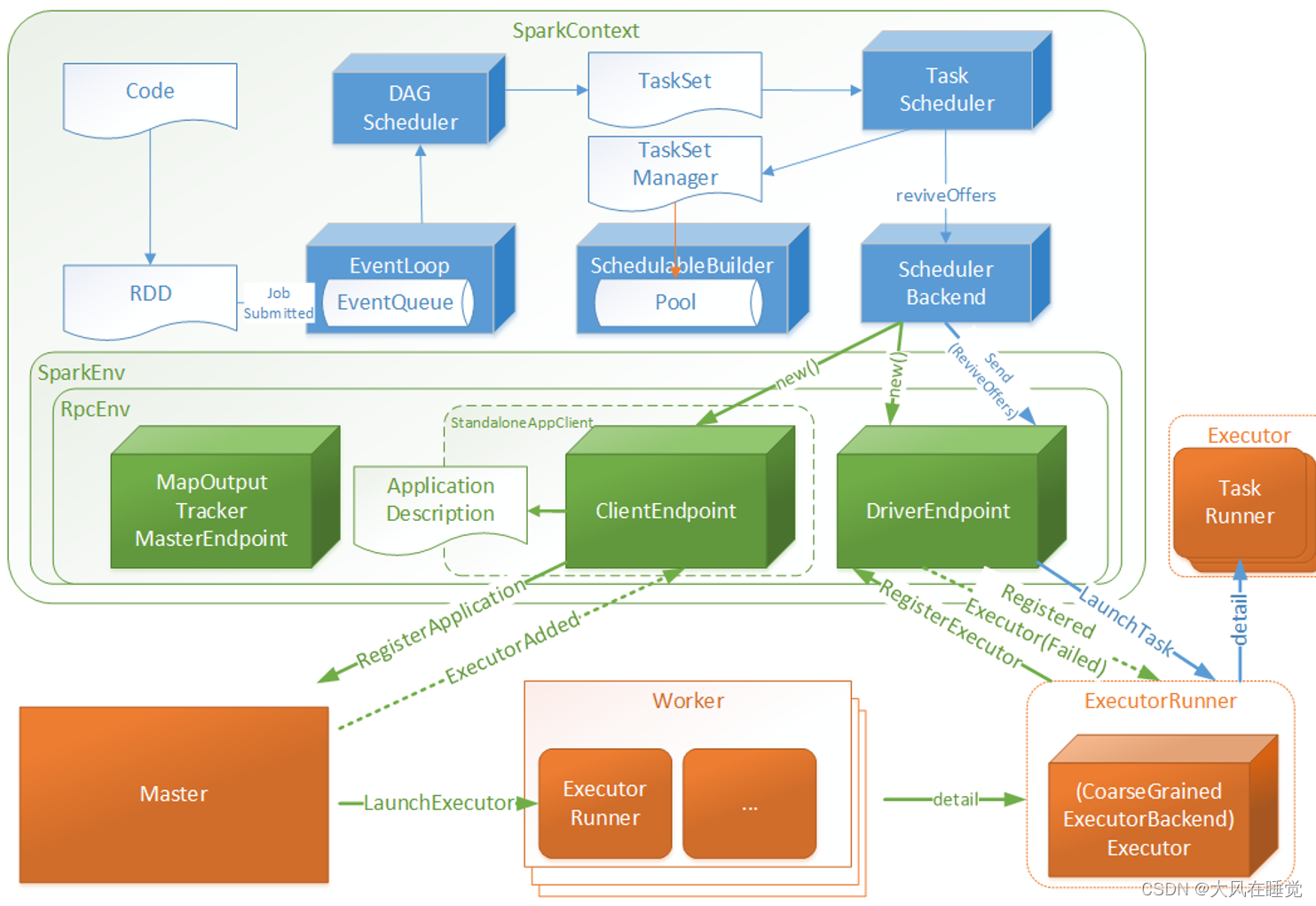
1.Spark Stage 级调度
Spark 的任务调度是从 DAG 切割开始,主要是由 DAGScheduler 来完成。当遇到一个 Action 操作后就会触发一个 Job 的计算,并交给 DAGScheduler 来提交。Job 由最终的 RDD 和 Action 方法封装而成。SparkContex t将 Job 交给 DAGScheduler 提交,它会根据 RDD 的血缘关系构成的 DAG 进行切分,将一个 Job 划分为若干 Stages,具体划分策略是,由最终的 RDD 不断通过依赖回溯判断父依赖是否是宽依赖,即以 Shuffle 为界,划分 Stage,窄依赖的 RDD 之间被划分到同一个 Stage 中,可以进行 pipeline 式的计算。划分的 Stages 分两类,一类叫做 ResultStage,为 DAG 最下游的 Stage,由 Action 方法决定,另一类叫做 ShuffleMapStage,为下游 Stage 准备数据,下面看一个简单的例子 WordCount。
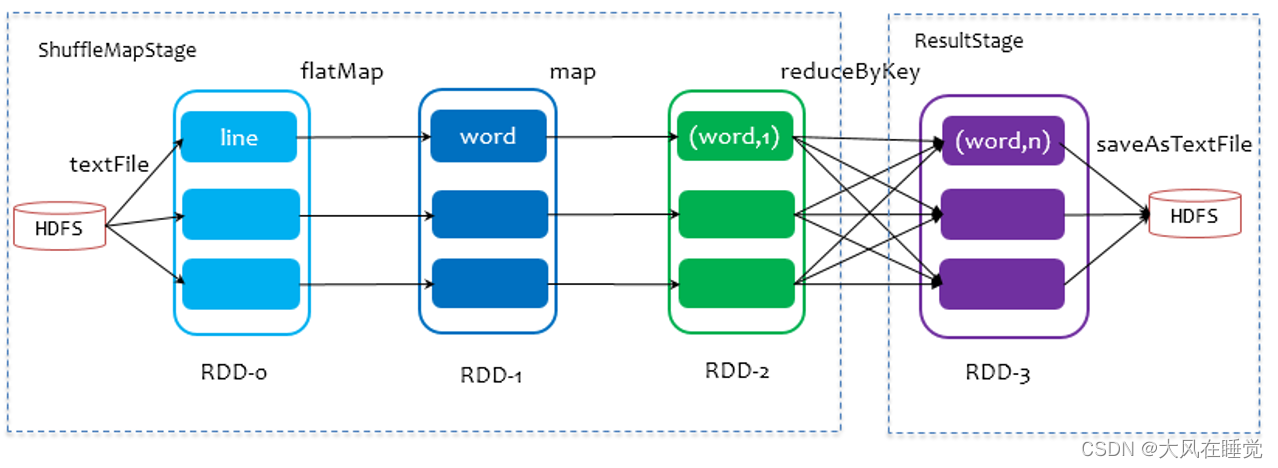
步骤如下:
- Job 由 saveAsTextFile 触发,该 Job 由 RDD-3 和 saveAsTextFile 方法组成;
- 从 RDD-3 开始回溯搜索,RDD-3 依赖 RDD-2,并且是宽依赖,所以在 RDD-2 和 RDD-3 之间划分 Stage;
- RDD-2 依赖 RDD-1,RDD-1 依赖 RDD-0,这些依赖都是窄依赖,所以将 RDD-0、RDD-1 和 RDD-2 划分到同一个 Stage。
一个 Stage 是否被提交,需要判断它的父 Stage 是否执行,只有在父 Stage 执行完毕才能提交当前 Stage,如果一个 Stage 没有父 Stage,那么从该 Stage 开始提交。Stage 提交时会将 Task 信息(分区信息以及方法等)序列化并被打包成 TaskSet 交给 TaskScheduler,一个 Partition 对应一个 Task,另一方面 TaskScheduler 会监控 Stage 的运行状态,只有 Executor 丢失或者 Task 由于 Fetch 失败才需要重新提交失败的 Stage 以调度运行失败的任务,其他类型的 Task 失败会在 TaskScheduler 的调度过程中重试。
总结一下就是 DAGScheduler 仅仅是在 Stage 层面上划分 DAG,提交 Stage 并监控相关状态信息。
2.Spark Task 级调度
DAGScheduler 将 Stage 打包到交给 TaskScheduler,TaskScheduler 会将 TaskSet 封装为 TaskSetManager 加入到调度队列中。TaskSetManager 负责监控管理同一个 Stage 中的 Tasks,TaskScheduler 就是以 TaskSetManager 为单元来调度任务。
TaskScheduler 初始化后会启动 SchedulerBackend,它负责跟外界打交道,接收 Executor 的注册信息,并维护 Executor 的状态,它在启动后会定期地去“询问” TaskScheduler 有没有任务要运行,TaskScheduler 在 SchedulerBackend“询问”它的时候,会从调度队列中按照指定的调度策略选择 TaskSetManager 去调度运行。TaskScheduler 支持两种调度策略,一种是 FIFO,另一种是 FAIR。
- FIFO调度策略直接简单地将 TaskSetManager 按照先来先到的方式入队,出队时直接拿出最先进队的 TaskSetManager;
- FAIR 模式中有一个 rootPool 和多个子 Pool,各个子 Pool 中存储着所有待分配的 TaskSetMagager。具体方法单独写一篇文章。
欢迎关注。
【Spark】Spark任务调度
















 930
930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









