







番茄风控之前跟大家讲解了征信相关的内容:
①二代征信的解读、规则衍生等来罗
②关于进一步解释二代征信表结构,数据结构的内容
③二代征信|番茄风控全网最全
④二代征信的深度解读
关于征信报告的指标加工跟衍生,相信也是大家比较关注的内容,今天的文章,跟大家讲解如何进行相关的征信内容的指标加工,文章的内容一共分成四个部分:
1.导入数据
2.拆分报告的组成内容
3.指标加工
4.对原始指标做二次衍生
以下为今天文章的正文部分:
1.导入数据
如果接入某外部征信个人报告,我们可以用python做指标的开发,首先导入该数据的接口传入的json数据。

2.拆分报告的组成内容
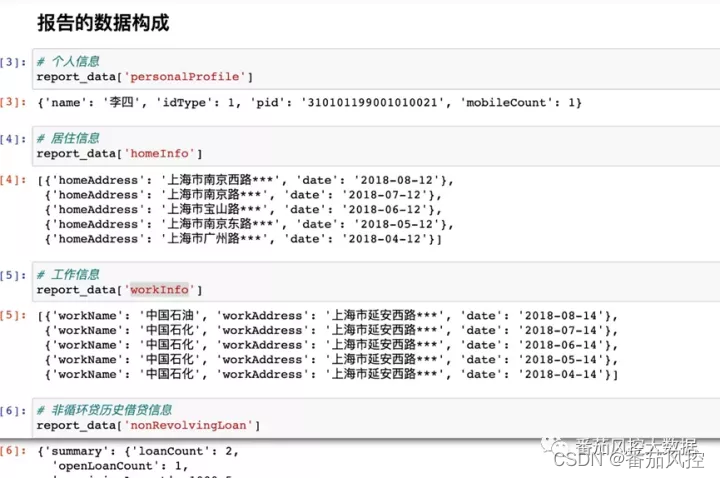
下面是报告的组成部分,包括个人信息,居住信息,工作信息,非循环贷和循环贷的借贷信息。
3.指标加工
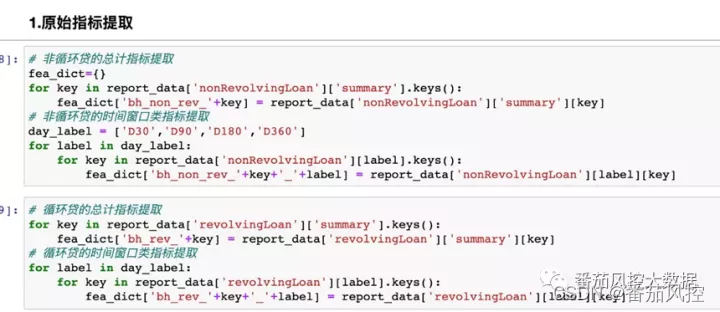
这里罗列了json里字段的含义,首先对原始指标进行提取,包括非循环贷和循环贷的summary指标和时间窗口指标。

4.对原始指标做二次衍生
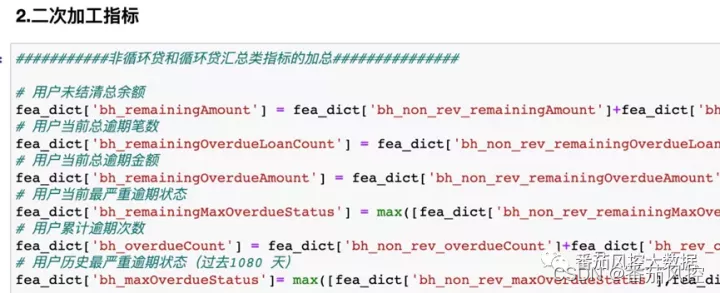
- 非循环贷和循环贷summary指标和时间窗口指标的加总,可以反映用户在百行报告上整体的借贷情况。
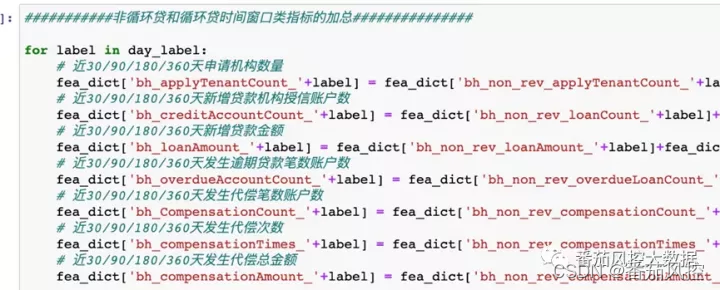
2)对于时间窗口类的指标做占比类,趋势类的指标衍生,可反映用户在多头,放款,逾期上的短期集中风险。
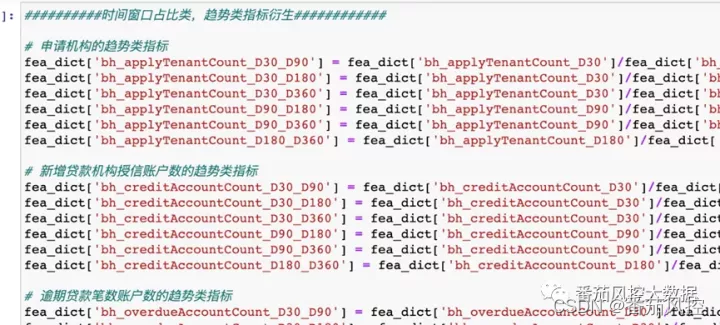
3)对居住地址,工作地址做指标衍生,可以衡量用户工作生活的稳定性
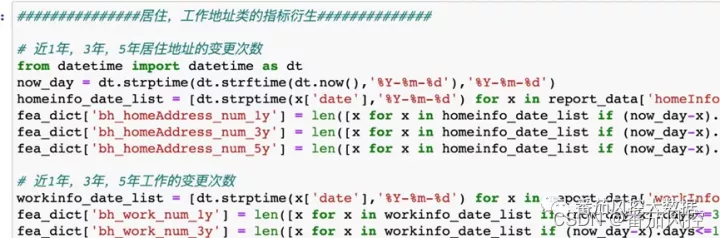
希望本文能帮助到各位做风控的童鞋!
关于本文涉及内容,因为(公众号)此处无法传输数据集,我们会将整体内容以文件包(数据集+代码)同步到知识星球平台,实操内容请大家移步知识星球:
~原创文章
…
end


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









