







之前番茄风控跟大家介绍了一些外部数据源的测试的相关内容:
①基础篇|信贷风控中的外部数据(百行)
②实操干货|对某征信数据的指标加工
…
但很明显各位同学对于,当下对于各家机构其外部的数据源具体如何测试跟运用还是不太熟悉,今天我们综合了星球同学的一些需求,给大家梳理了这样一篇关于外部数据的实操测试的内容。本次文章我们将结合具体的实操为大家带来具体的内容,文章详情共分成以下几个部分:
1.导入数据部分
2.查得率测试
3.模型分测试
4.测试效果排序性问题
5.测试效果的稳定性问题
以下为文章的详细内容:
1.导入数据部分
测试的数据为一份模拟的三方模型分数据,包含了用户id(user_id),申请日期(date),模型分(sf_score),y标签(label)。数据量为2w左右。
2.查得率测试
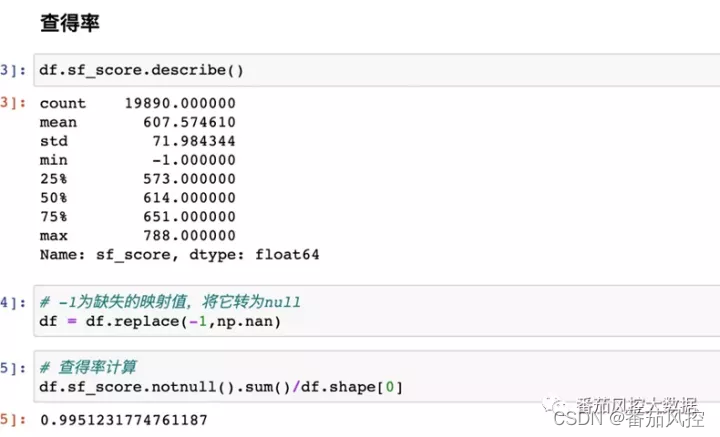
首先看一下数据的查得率,从分布上可看到三方把缺失映射为-1了,我们做一下转换,然后计算模型分字段的非空占比,即查得率为99.5%,接近100%,符合业务预期。
3.模型分测试
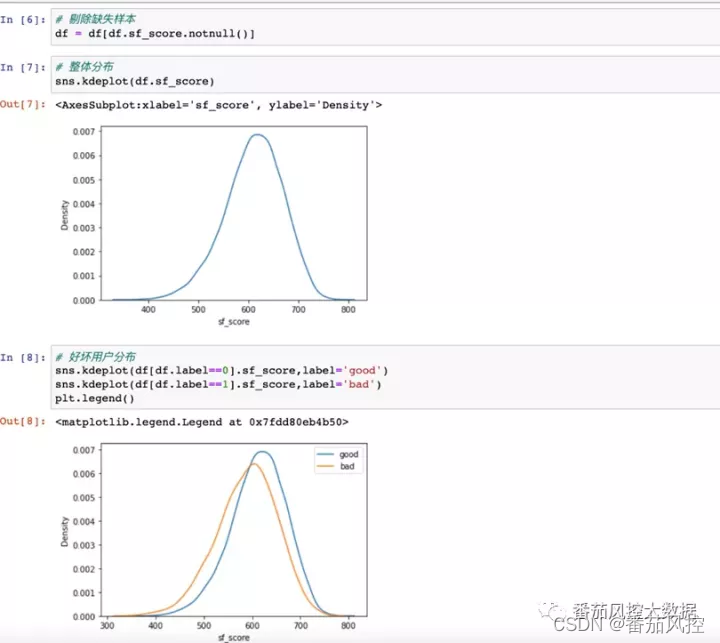
看一下模型分的整体分布和好坏用户分布,可看到整体呈正态分布,分数在400-800分之间,从好坏分布上可看出模型分有一定的区分能力,且分数越高,用户坏的概率越低。
4.测试效果排序性问题
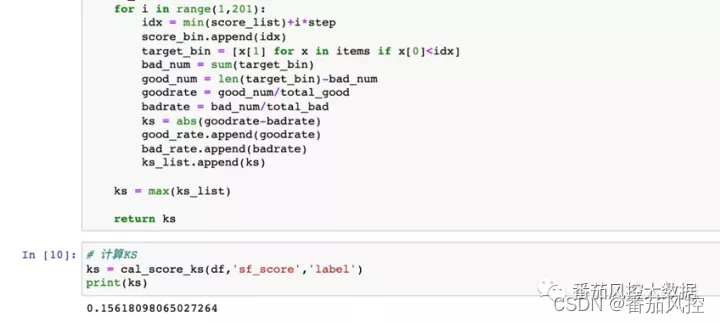
根据模型分接入的需求来评估准确性,如果用来做风险定价,则关注KS和整体的排序性,KS计算结果为0.156,效果一般,再看一下整体的排序性,这里用了等频分箱将模型分分为10等份,计算每组的lift值,观察随着分数升高,lift值是不是单调变小的,从lift的趋势图看符合我们的预期,模型分的整体排序性尚可。
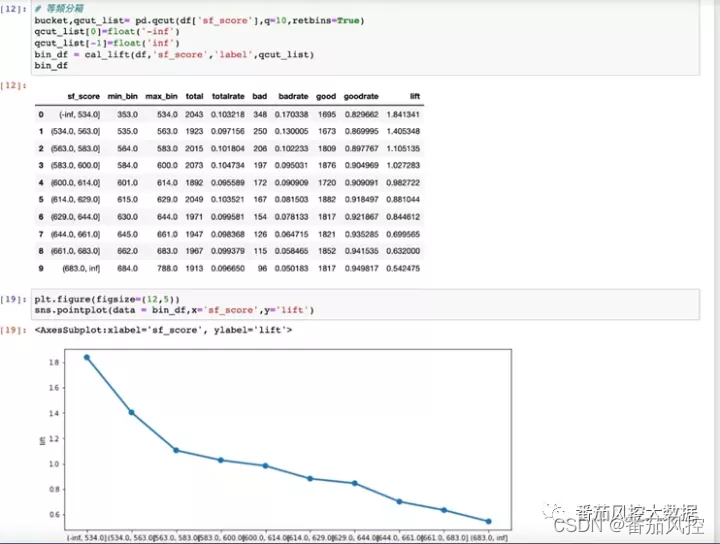
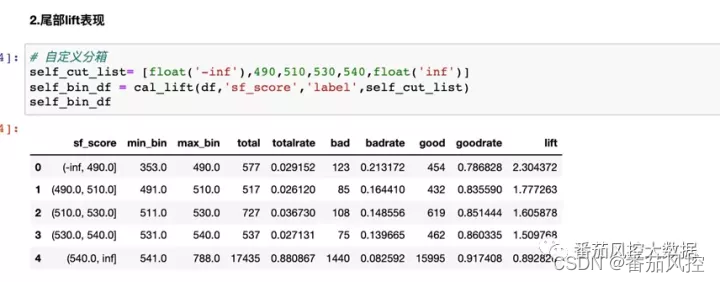
如果模型分用来做拒绝规则,则更关注它尾部的lift表现,即低分段的区分能力,这里对低分段采取自定义分箱,低分段每个箱的占比设置的都比较小,来模拟如果卡掉尾部少量人群,模型分对这些人的识别精准度。从结果中可看出低分段的lift也是呈单调变化,最低的一个分段lift为2.3,说明模型分相比随机挑选能识别出2.3倍的坏用户。如果要确定一个拒绝阈值,那设置在<=490 比较合适。
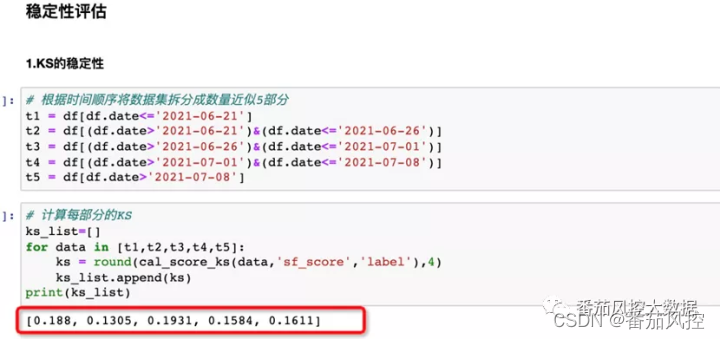
5.测试效果的稳定性问题
如果模型分整体的KS和尾部lift表现尚可,我们还要评估它的准确性在时间维度上是否稳定,这里根据申请时间的先后顺序将数据集分为了5部分,每部分的数据量在4k左右(计算ks和lift时数据量不能太少,一般至少要3k,这样才有统计意义)。先评估下ks的稳定性,可以看到ks不是很稳定,最高有0.19,最低才0.13,在时间上有点波动。
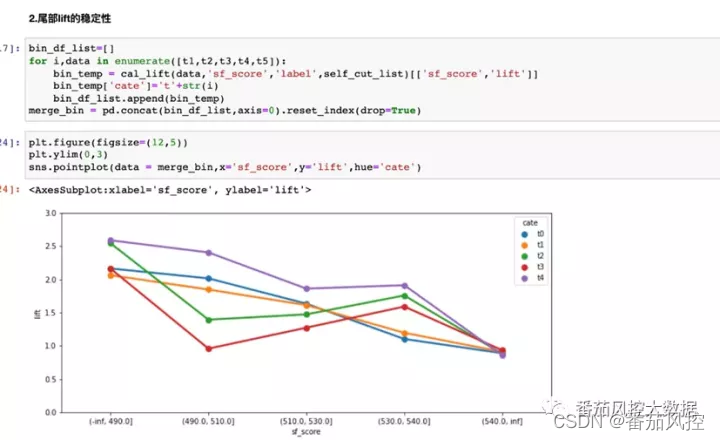
下面评估下尾部lift的一个稳定性,也是分为5部分,对每部分的lift表现画了折线图来作比较,从折现图上可以看到有两部分数据尾部lift不是单调变化的,表现为在(490,510)这段上lift降到最低点,在(510,530)和(530,540)上lift反而上升了。说明尾部lift的排序性不太稳定。但5部分数据最低分段上的lift都有2以上,说明对于最低分段的区分能力还是比较稳定的。
希望本文能帮助到各位做风控的同学!
关于本文涉及内容,因为(公众号)此处无法传输数据集,我们会将整体内容以文件包(数据集+代码)同步到知识星球平台,实操内容请大家移步知识星球:
希望本次文章,对各位童鞋有帮助~对于变量相关的衍生内容,系统性相关的知识欢迎大家关注:

~原创文章
…
end


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









