






前言:
在模型开发过程中,或多或少都会遇到在生产过程中非常常见的问题就是模型样本开发不足。特别是在一些数据策略的冷启动阶段,而关于这些我们之前的文章都有以下内容:
①讲解经典专家评分卡怎么实操
②两种专家经验评分卡的学习
…
而今天关于模型冷启动阶段的相关内容,本文再介绍了一种更实操落地的方法,详情请看。
正文:
新产品上线,往往只能使用规则进行审批与授信。能不能拦住风险是一回事,老板报以不信任的目光更使得风控从业人员倍受挫折。我们提供一个迁移学习风险评分开发方案,尝试在冷启动阶段就完成风险评分的开发。
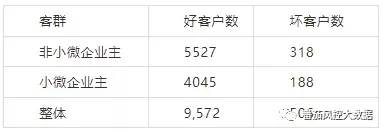
假定某家金融机构已有成熟贷款产品XFD,打算向市场投放面向小微企业主的新产品XWD。建模人员通过数据分析发现,已有借款客户里面,只有20%的客户是小微企业主。由于缺乏数据,模型应用效果不佳。
产品A数据样本:
一.开发过程:
1) 直接套用老模型
直接使用产品A的风险评分(评分A)应用到产品B客户中,KS有所下降。主要原因是小微企业主客户坏客户样本少,使用整体借款客户来开发风险评分,会让模型更多“关注“非小微企业主客群。


可以看到仅有小微企业主的客群的KS值就下降到45,所以直接加入风险评分后,反而使得模型失去使用价值。
2)推荐解决的思路
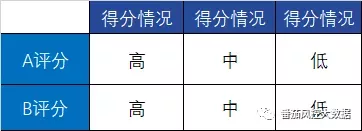
如果以上的思路不好,有没有更好的方法能解决上述难题。这里跟大家介绍我们在实操生产中用到的方法。推荐把评分A(整体客户)和评分B(小微企业主定制评分)计算分布,并交叉制作二维矩阵,对两个评分均处于高分段的非小微企业主好客户打标,并把打标客户加入到小微企业主样本中,一起开发定制评分C。
具体的思路如下:


二.细节问题
这里有个实操问题。不少同学会问为什么只能把两个评分均处于高分段的非小微企业主好客户打标,而不能把两个评分均处于低分段的非小微企业主坏客户打标,然后加入到小微企业主样本中。
答案是因为样本需要小心处理后才能使用。例如按照本数据样本,小微企业主坏客户标签只有2000个。而使用两个评分均处于低分段的非小微企业主坏客户打标,如果阈值设置较松,会有大量的非小微企业主坏样本加入到小微企业主样本中,把实际需要评价的小微企业主坏客户的浓度稀释了,导致模型应用效果不佳。
解决这个问题的方案是调整非小微企业主坏样本的浓度或调整打标阈值,另外上述问题也可以使用TrAdaBoost等迁移学习的方法解决,有需要深入了解的同学可以在知识星球提问。
本文中关于代码跟数据集的问题的,各位童鞋还可以到知识星球平台获取更全面的代码学习,希望本文对大家在模型开放的冷启动有借鉴。

~原创文章
…
end















 2038
2038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









