







样本异常值处理是建模过程数据清洗的一个比较重要环节,可以有效提升后续模型训练拟合的精准度。对于数据异常值的识别,具体实现的方法可以分为统计分析和模型算法两个维度,其中统计分析方法主要是箱线图分布、标准差检测,这是实际场景中最常采用也是我们比较熟悉的方式,而模型算法包括DBSCAN聚类、孤立森林模型等,其原理过程相对前边几种方法较为复杂,但在实际应用后的数据处理效果也表现不错。
结合以上异常值处理方法的应用情况,本文介绍目前在应对黑产,反洗钱领域用得最多的算法,即其中较为经典的孤立森林识别异常值方法。本次对其进行详细介绍,从孤立森林的算法本质、实现方法、参数配置等方面进行全面解读,同时围绕具体的场景案例与样本数据,以实操角度来完成孤立森林识别异常值的完整过程。
1、算法原理
孤立森林(Isolation Forest):采用二叉决策树的方法对样本特征数据进行分裂,整个过程的样本选取、特征选取、分裂点选取都是随机化的方式,对于样本数据中的异常值,较大概率可以通过很少的次数将其切分判断出来。因此,孤立森林的核心思想是根据特征数据分割的次数来衡量某个样本点是否异常。如果划分的次数越多,说明样本点分布较为聚集,基本属于正常数据;如果划分的次数越少,说明样本点分布较为孤立,很大概率属于异常数据。
孤立森林是根据给定数据集的决策树集成建立起来的,与随机森林的算法思想很类似,但是孤立森林是将树上平均路径较短的样本数据点识别为异常值,对于“森林”中的每一棵孤立的“树”,其算法应用过程都是一致的,也就是随机选择m个样本和n个特征,然后在所选特征的最大值与最小值之间随机选择一个值来分割数据点,样本观测值的划分不断递归重复,直到当前树的所有样本观测值都被孤立。这个实现过程我们通过一个可视化流程示意图来表示,具体如图1所示,此决策树的特征变量为X1与X2。
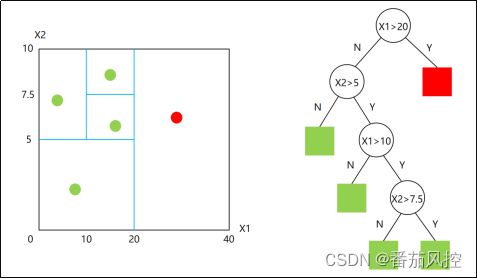
图1 孤立森林决策树
通过以上对孤立森林算法思想的简单整体描述,我们大体可以了解到,异常特征样本点在决策树上与根节点的距离相比正常值更近。孤立森林与Kmeans、DBSCAN等聚类算法识别异常值的原理有很大区别,实现过程不需要借助类似距离、密度等指标的数值大小,来衡量异常样本与正常样本的差异,而是直接通过决策树算法的理念,直接来刻画描述样本数据分布的疏散程度,从而判断样本特征数据的异常可能性大小。因此,孤立森林算法的原理较为简单,且实现效果也较好,在实际场景中的应用度也逐步变得广泛。
2、实现方式
采用python语言实现孤立森林模型算法,可以通过直接调用sklearn库中的IsolationForest(),现简要介绍下模型的重要参数,具体如图2所示。

图2 孤立森林模型参数
(1)n_estimators:森林中生成随机树的数量,默认100;
(2)max_samples:构建子树的样本数量,默认auto=min(256,samples_all);
(3)contamination:异常数据占所有数据的比例,默认0.1;
(4)max_features:构建子树的特征数量,默认1;
(5)bootstrap:采样是否放回抽样,默认False;
(6)random_state:随机种子,默认None。
在配置模型参数时,可以根据样本情况与实际经验进行设置,或者简单直接采取模型函数的默认值。此外,模型训练与模型预测相关函数主要如下(其中X为样本特征数据):
(1)fit(X):训练拟合模型;
(2)predict(X):预测模型(返回1或-1,其中-1为异常值);
(3)fit_predict(X):训练模型+预测模型;
(4)decision_function(X):特征异常分数。
3、案例分析
通过以上内容介绍,我们对孤立森林的原理逻辑与模型实现已经有了大概的认识,接下来我们围绕一个实际场景案例,从实操角度来描述下采用孤立森林算法识别样本异常值的完整过程。我们根据图3代码简单构建一份样本数据如图4所示,具体包括20个样本和3个特征,下面则采用孤立森林模型算法来判断特征X1、X2、X3的异常值分布。

图3 样本构建
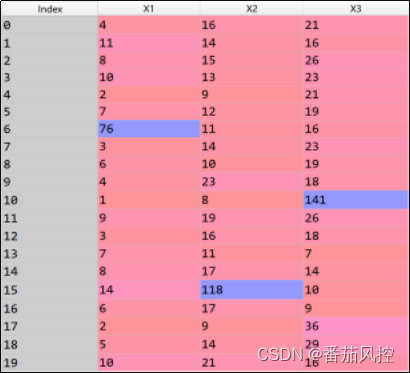
图4 样本数据
模型训练与模型预测如下图5所示,依次对特征X1、X2、X3的异常值情况进行判断,并最终返回各特征异常值的判断标签“flag”与异常分数“score”(图6)。
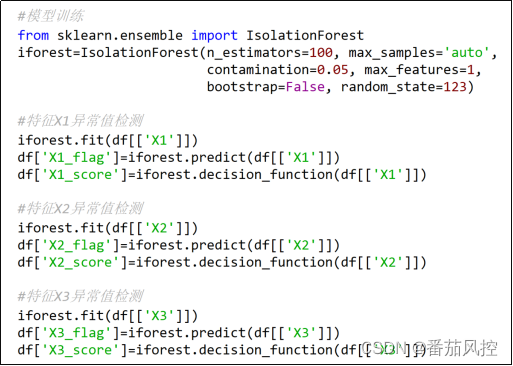
图5 模型训练与预测
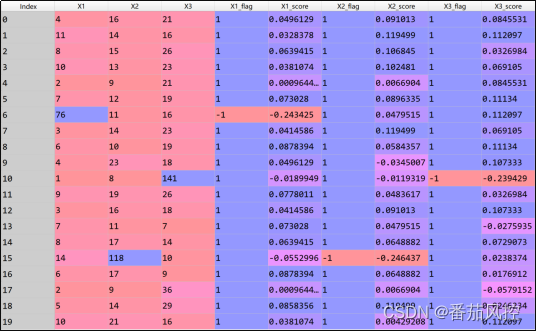
图6 特征异常结果
由上图结果可知,异常值标签列X1_flag、X2_flag、X3_flag取值为-1代表对应的特征原始值为异常值,取值为1代表对应的特征原始值为正常值。例如X1_flag=-1,说明X1=76为异常值。因此,本样本数据的特征X1、X2、X3各存在1个异常值。同时,从对应异常值分数score也能进一步看出,异常值的分数结果明显比正常值低很多,现将各特征的异常值分数通过可视化图进行展现,具体如图7所示
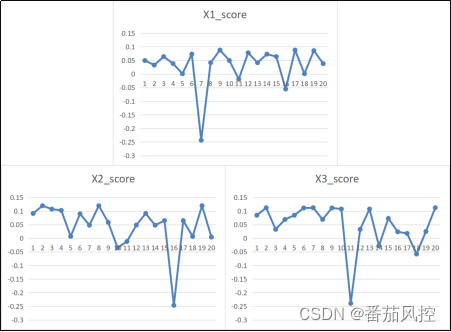
图7 特征异常分数
上内容便是孤立森林算法在建模样本异常值检测的场景实现,可以看出这种采用模型方法来识别特征异常值的过程,与箱线图分布、标准差检测等方式有着明显区别,但最终处理分析结果也依然有着不错的表现。同时,由于孤立森林的每棵树都是通过随机采样独立生成的,也不需要通过样本距离、密度等指标来衡量数据的异常情况,因此在数据分析过程中相比KMeans、DBSCAN等方法的处理速度更为高效,这也是孤立森林模型算法的一个独特之处。
在实际建模过程中,样本数据的异常值检测方法包括箱线图分布、标准差检测、DBSCAN聚类、孤立森林等,各位小伙伴可以结合样本数据与场景需求等情况进行应用,尤其是孤立森林算法,在数据处理高效方面能够表现出很好的效果。此外,为了便于大家对孤立森林模型算法识别样本异常值的进一步理解与掌握,本文附带了与以上内容同步的python代码,供大家参考学习,详情请移至知识星球查看相关内容。
…
原创文章














 1309
1309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









