







对于银行信用卡中心,存量用户群体的信用卡行为表现信息,是实际业务中有关风控模型或营销分析场景的主要数据来源,例如行为评分模型、营销价值模型、客户流失模型、客户画像描述等。因此,如何有效分析信用卡用户的交易行为数据,是很多数据分析或数据建模任务的关键内容。
信用卡用户根据银行赋予的卡信用额度,每月在当前授信额度下消费或取现,并在相应还款日进行还款,这样在银行内部数据库的相关信息表中会每月更新用户的交易数据,主要包括消费金融、取现金额、还款金额、逾期金额、还款日期、授信额度、消费次数、取现次数等特征维度,这些日常行为数据随着时间不断新增,并通常以月为单位形成消费信息、还款信息、逾期信息等不同维度的数据表,成为银行非常重要且极具价值的数据资产。
针对信用卡用户的多个维度数据,在建立相关模型的过程中,特征衍生是特征工程的一个必要环节,尤其是在时间序列维度下挖掘相关特征标签,是构建模型变量池的重要来源。为了说明信用卡数据的特征衍生思路,本文选取其中某一个特征维度信息,来介绍下在时间序列维度下的新字段加工方法,同时从建模过程的需求考虑,来具体分析下衍生字段的性能表现。
1、样本数据分析
我们通过一份信用卡消费的实例数据来展开分析,样本数据的部分观测如图1所示,包含3000条样本与15个特征字段,其中cust_id为客户号,value_status为客户价值状态(取值二分类1/0,1代表高价值用户,0代表低价值用户),credit_amount为月信用额度(假定为固定额度,即每月信用额度不变),amount_M1~amount_M12表示用户在过去1年的月消费金额,例如amount_M1代表1月份的消费金额、amount_M6代表6月份的消费金额等。

图1 样本数据
针对图1样本数据,首先简单了解下各特征变量的整体描述分布,在python环境中可采用describe()函数来输出特征数据的统计指标信息,结果如图2所示。
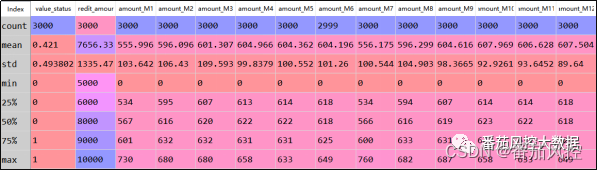
图2 特征分布
由上图可知,样本数据的特征字段均无缺失值情况(count为非缺失数量),且各字段从取值范围(min~max)来看无异常值分布,因此样本数据无需进行相关数据预处理,接下来我们从不同角度来依次研究特征衍生加工的主要思路与实现过程。
2、特征衍生加工
(1)每月额度使用率
额度使用率是银行评估信用卡客户消费资质能力的重要变量,相比消费金额、取现金额、授信额度等维度字段更有全面性与针对性。额度使用率的加工逻辑为当月“消费金额/授信额度”,当然还有另外一种逻辑是当月“(消费金额+取现金额)/授信额度”,由于此样本数据暂无“取现金额”字段,因此额度使用率采用前者加工逻辑。每月额度使用率的实现过程如图3所示,其中分母“授信额度credit_amount”均假设为固定额度,而在实际场景中由于定期调额策略,用户的全年月授信额度可能不同。在生成的新字段中,amtpct_M1表示1月份的额度使用率、amtpct_M3表示3月份的额度使用率。
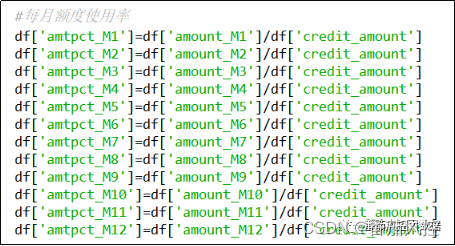
图3 特征衍生1
(2)近3/6/12个月总消费额度
距当前时点连续月份的消费额度总和可以反映信用卡用户的消费幅度,在时序维度下一般选取近3个月、近6个月、近12个月、近24个月、历史等颗粒度,由于本样例为全年12月消费数据,仅能加工近3/6/12个月的总消费额度字段,其逻辑为将一定周期月份的消费额度进行求和,实现过程如图4所示。
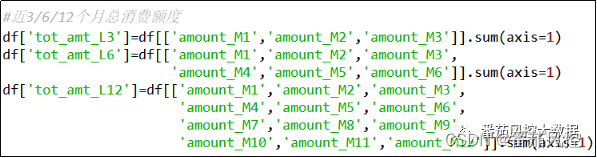
图4 特征衍生2
(3)近3/6/12个月最大消费额度
对于多个月份的消费额度取最大值,可以体现出信用卡客户在一定时期内的日常消费上限,仍然选取常用的时间维度近3/6/12个月,来加工时序周期下的月最大消费额度,实现过程如图5所示。
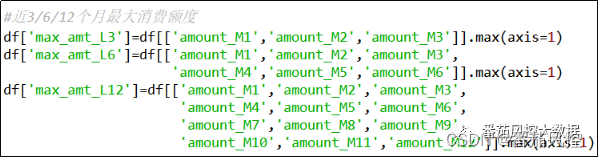
图5 特征衍生3
(4)近3/6/12个月最小消费额度
与(3)加工逻辑相反,对于多个月份的消费额度取最小值,可以体现出信用卡客户在一定时期内的日常消费下限,相对应常见时序周期下的月最小消费额度,其实现过程如图6所示。
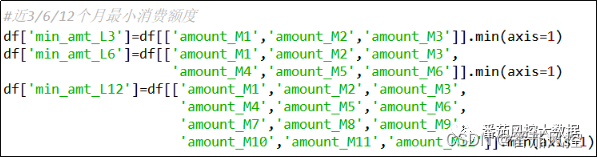
图6 特征衍生4
(5)近3/6/12个月平均消费额度
一定时序周期维度下的最大值、最小值仅能体现出局部上下限情况,但要从整体上说明信息的稳定性,需要以平均值来衡量,因此平均月消费额度可以直接说明信用卡用户的整体消费能力,相比最大最小值更有信息价值度,对固定时间窗多个月份的消费额度取平均的实现过程如图7所示。
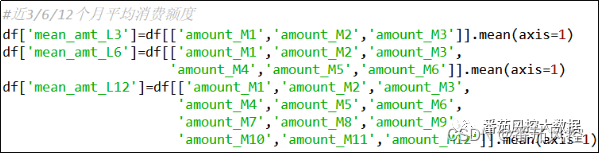
图7 特征衍生5
(6)近3/6/12个月最大额度使用率
额度使用率相比消费额度更能体现出信用卡用户的消费资质能力,因此从时序周期考虑,也可以对连续多个月份的额度使用率进行极值分析,其中近3/6/12个月最大额度使用率的实现过程如图8所示。
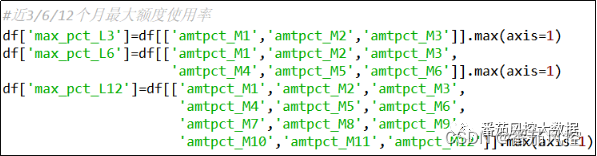
图8 特征衍生6
(7)近3/6/12个月最小额度使用率
同(6)加工逻辑相类似,对近3/6/12个月的额度使用率取最小值,实现过程如图9所示。
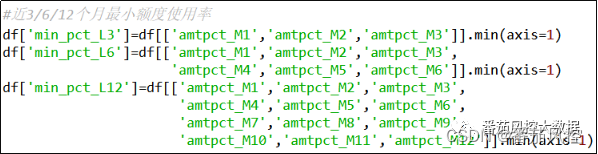
图9 特征衍生7
(8)近3/6/12个月平均额度使用率
平均额度使用率从整体上可以进一步体现出信用卡客户对额度的使用情况,往往在B卡行为评分、客户价值预测等模型中作为入模变量来使用,而且在是实际业务中具有很好的解释性,对于额度调整有着很高的参考价值,近3/6/12个月平均额度使用率的实现过程如图10所示。
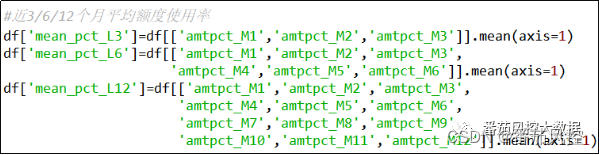
图10 特征衍生8
(9)近3/6/12个月消费额度为0的月份数
在时序维度下的月消费数据,并不是所有用户的月账单信息是稳定的,很可能存在中间某几个月无消费额度,也就是没有使用月授信额度,这种情况针对不同客户自然也有不同的且无规律的表现。但是,从数据分析考虑,在某段时间周期的月消费额度信息中,探究有消费和无消费的月份属性分布,可以较大程度说明信用卡客户的消费频率与稳定价值,现对近3/6/12个月消费额度为0的月份数量进行汇总,具体实现过程如图11所示。
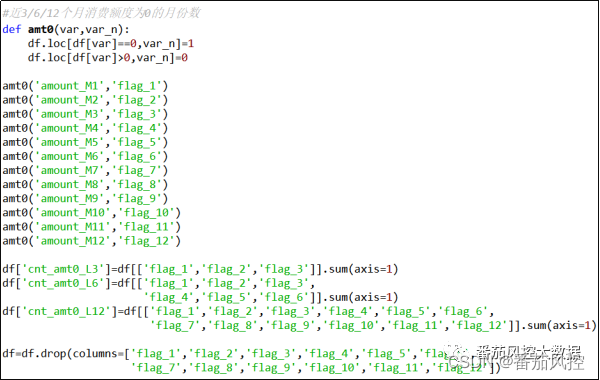
图11 特征衍生9
(10)近3/6/12个月消费额度大于600的月份数
在某段时间段的月消费信息中,如果每个月份都有消费,但消费金额太小也并不能反映出信用卡客户的消费能力,因此对于月消费金额的数据中,结合实际业务来判断是否大于某个金额数值,可以较大程度说明客户的潜在价值,根据本文数据样例的数值分布,我们以金额600为判断阈值(具体需要结合业务情况),来汇总时序维度近3/6/12个月的消费金额大于600的月份数,具体实现过程如图12所示。
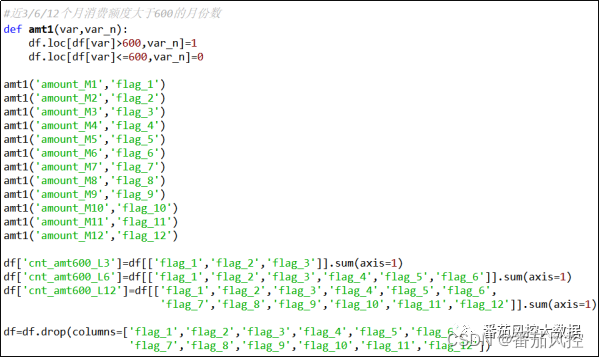
图12 特征衍生10
(11)近3/6/12个月额度使用率大于0.1的月份数
为了更大程度体现出客户在不同月份的额度使用情况,采用与(10)类似的加工逻辑,来汇总近3/6/12个月的额度使用率大于某个阈值的月份数,这里考虑到样本数据的分布情况,采用0.1为判断阈值,在实际建模特征衍生过程中可以尝试0.1~0.9等距的衍生思路,现加工不同时序周期下额度使用率大于0.1的月份数,具体实现过程如图13所示。
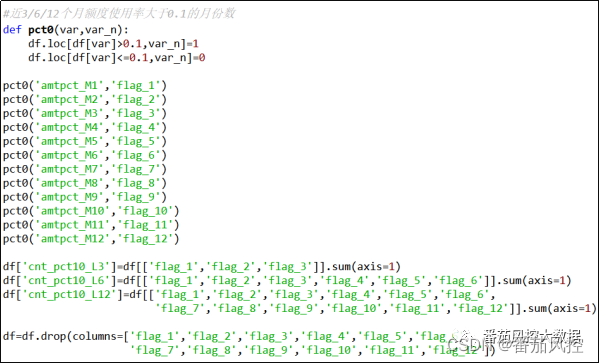
图13 特征衍生11
(12)近3/6/12个月消费额度上升的月份数
对于时序性的特征数据,波动情fef7046249dfd137215e6b16f.png)
往往是聚焦的重点内容之一,包括频次、幅度、长度等,而信用卡的月消费数据自然也会体现出相关特点,例如消费额度的上升、下降、变化幅度等。因此,这里选取连续月份的变化趋势,来分析下月消费额度的波动情况,这可以很大程度体现出客户的消费稳定能力与发展趋势,现获取近3/6/12个月消费额度上升的月份数,具体实现过程如图14所示。
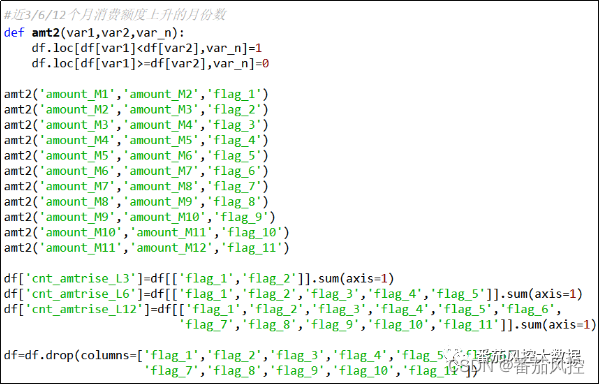
图14 特征衍生12
(13)近3/6/12个月消费额度下降的月份数
与(12)相邻月消费额度的上升状态相反,加工近3/6/12个月消费额度下降的月份数字段,具体实现过程如图15所示。
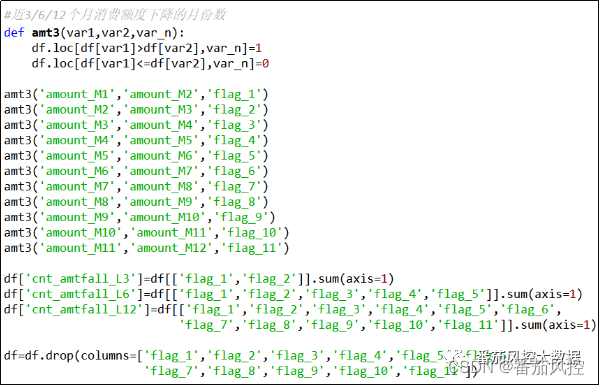
图15 特征衍生13
(14)近3/6/12个月额度使用率上升的月份数
时序维度下相邻月份的消费额度有上升、下降、不变的表现,而对于月额度使用率同样可以衍生以上逻辑字段,现获取近3/6/12个月额度使用率上升的月份数,具体实现过程如图16所示。
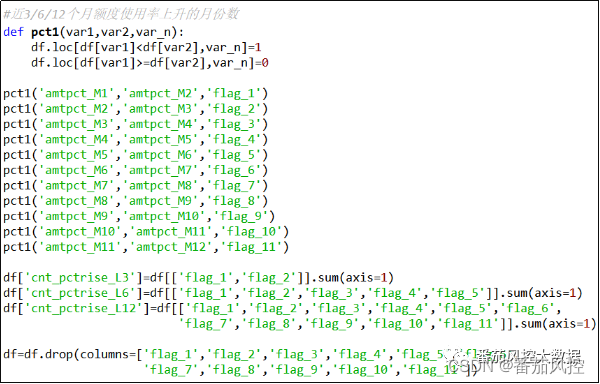
图16 特征衍生14
(15)近3/6/12个月额度使用率下降的月份数
近3/6/12个月额度使用率下降的月份数,具体实现过程如图17所示。
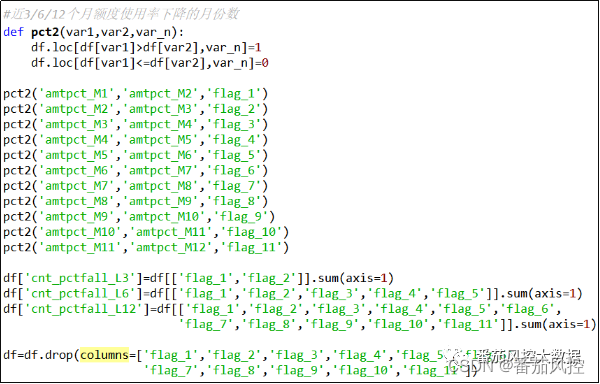
图17 特征衍生15
通过以上15个维度,我们在时间窗口下围绕“消费额度”衍生加工了共54个新特征,当然还有其他统计学或算法维度来进一步衍生,这里仅介绍相对较为常用的特征衍生维度与方法。在信用卡建模的实际场景中,可以复制以上衍生思路构造出更丰富的变量字段,包括还款金额、取现金额、逾期金额、消费次数、取现次数、还款日期等,再结合不同时间窗口与加工逻辑,特征衍生的范围是非常大的,但是我们往往在加工新变量的过程中,要同时考虑到业务场景,以保证特征衍生的字段更有针对性,例如本文介绍的15个常用衍生维度。下面我们汇总下最终生成的特征衍生变量信息,通过df.columns将其特征列信息进行输出,具体结果如图18所示。
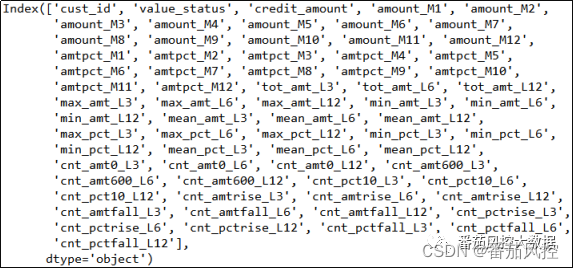
图18 特征衍生字段
3、特征性能分析
当经过特征衍生获取了相关新变量后,接下来重点是需要评估下新特征的性能,这不仅是验证特征衍生的有效性,也是后续特征筛选的必要环节。因此,我们通过最常用的几个特征工程方法,来评估下新衍生变量的性能表现,具体评估方法分别为特征相关性、特征预测性、特征重要性。
(1)特征相关性
特征相关性是分析各变量之间的相关程度,由于新变量的取值类型均为连续型,因此可以采用pearson系数来量化评估,实现过程如图19所示。

图19 特征pearson系数
根据以上方式获取的最终相关性结果是一个二维系数矩阵表,由于特征变量较多,这里仅展示其中部分字段的取值系数,具体如图20所示,单元格数值代表纵向与横向字段交叉变量组合的相关性系数,取值范围[-1,1],正值代表正相关,负值代表负相关,绝对值越大说明相关性越强。其中,纵向的特征字段amount_M1amount_M10为原始字段,表示1月10月的消费额度;横向的特征字段amtpct_M1amtpct_M7为衍生字段,表示1月7月的额度使用率。从系数结果可以看到,新衍生加工的字段与原始字段的相关性普遍不是很强,一般情况下,pearson系数大于0.7认为相关性很强,而表中的系数分布大多数都远低于0.7,这也很直观证明了在特征相关性分析的维度上,特征衍生的新字段是非常有效的。
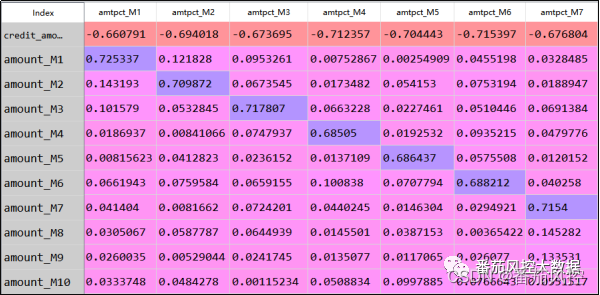
图20 特征pearson系数
(2)特征预测性
特征预测性是对各特征变量进行离散分箱从而获取每个字段的信息值IV,为了对比说明新衍生字段的区分能力,我们分别输出原始字段与衍生字段的IV值信息,由于新衍生字段较多,这里选取时窗近3个月的相关新特征来进行说明,具体实现过程分别如图21、图22所示。
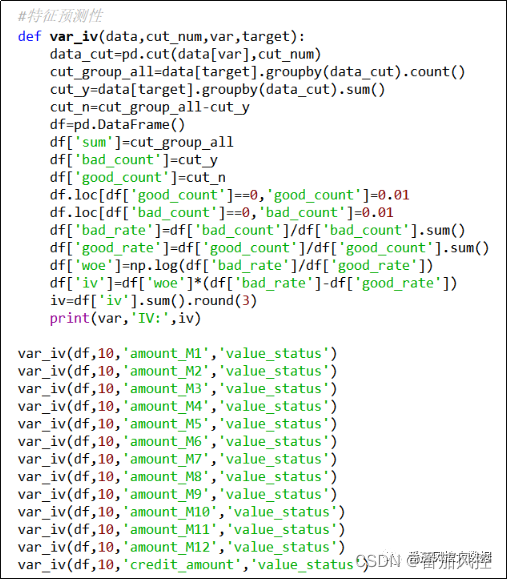
图21 原始特征IV值获取
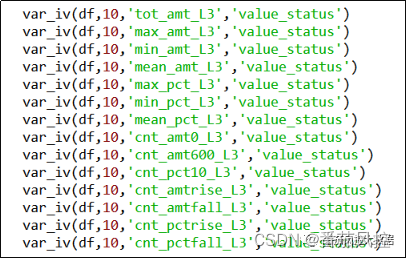
图22 衍生特征IV值获取
通过以上过程获取原始特征与衍生特征(部分)的IV值分布结果如图23所示,对比结果可知,原始特征的IV值普遍较低,13个字段的IV值大于等于0.02以上的变量仅有4个,且最大值只有0.055,而衍生特征其中14个字段的IV值有8个大于0.02,且其余多数字段接近于0.02,此外IV最大值为0.086。因此,无论从整体IV值较高表现来衡量,还是从局部IV值最优来考虑,新衍生特征的IV值明显比原始特征要好很多,这里进一步说明特征衍生在特征预测性维度上也是非常有效的。

图23 特征IV值结果对比
(3)特征重要性
特征重要性是从模型的角度来分析各变量在模型拟合的贡献程度,具体实现方法是通过决策树模型来输出特征的重要性系数importances,这里采用XGBoost决策树分类模型来获取,具体实现过程如图24所示。
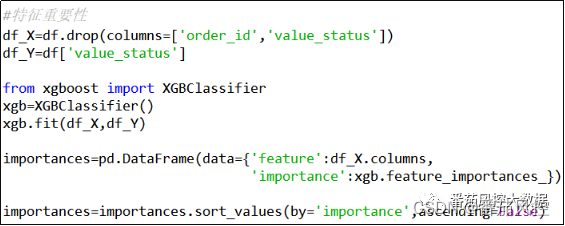
图24 特征重要性系数获取
通过以上过程获取的特征重要性importances系数结果如图25所示,这里根据特征重要性排序并取前10个字段分布来说明,从结果可以直观了解到,对当前模型重要度较大的前10个特征中,仅有“amount_M6”为原始字段,其余字段均为新衍生加工的特征,这里再次说明了特征衍生在特征重要性维度上的有效性。
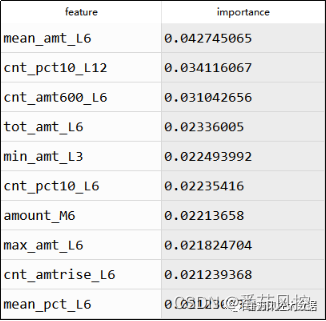
图25 特征importances系数分布
综合以上内容,我们围绕信用卡用户“消费金额”的特征维度数据,通过多种方式在时序维度下对原始变量进行了衍生加工,将特征变量池进行了针对性扩大。同时,我们通过特征相关性、特征预测性、特征重要性3个主要特征工程维度,对新衍生加工的特征进行了性能分析,结果证明了衍生字段相比原始字段在各个方面都有较好效果表现,从而体现出了特征衍生的合理性与有效性,这对于数据建模的特征工程环节是非常必要的,为模型训练的变量选择、模型应用的效果提升等方面有着很重要的贡献价值。
为了便于大家熟悉并掌握关于特征衍生加工及其字段性能分析的详细内容,本文额外附带了与以上介绍同步的样本数据与python代码,供大家参考学习,详情请移至知识星球查询相关内容。
更多详细内容,可关注:

…
~原创文章

















 1705
1705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









