







信贷反欺诈,是金融信贷领域的一个重要话题,围绕反欺诈场景的风险防范措施,也自然成为我们从事信贷风控工作的重点内容之一。在信贷产品业务中,欺诈风险与信用风险是风控体系的两大模块,虽然二者在风控策略或数据模型的开发流程上有很多相似之处,但在业务理解与实践应用中有着明显区别。因此,熟悉和理解信贷反欺诈场景的特点,并掌握好相关策略模型的开发方式与应用逻辑,是我们在信贷反欺诈工作中需要把握好的核心内容。本文将结合以上实际业务背景,给大家介绍下信贷反欺诈场景的特点,以及反欺诈策略与模型的应用。同时,我们围绕实际的样本数据,来构建一个完整的信贷反欺诈模型。
1、信贷欺诈类型与特点
互联网欺诈在实际场景中的表现方式有很多,如果对信贷欺诈的类型进行划分,比较常见的有欺诈主体、利益得失等维度。其中,从欺诈主体方面分析,可分为第一方欺诈、第二方欺诈、第三方欺诈,其特点具体如下:
(1)第一方欺诈:欺诈主体为申请者本人,欺诈主体知情且分享收益;
(2)第二方欺诈:欺诈主体为企业内部员工;
(3)第三方欺诈:欺诈主体为盗用别人身份信息欺诈的人群,非客户非企业。
此外,从利益得失方面分析,可分为C2B、B2C、B2B三种方式,B与C分别代表团体与个人,其特点具体如下:
(1)C2B:个人骗平台,属于第一方欺诈;
(2)B2C:团伙骗个人,欺诈主体为团伙,损失方为个人,平台信誉损失;
(3)B2B:团伙骗平台,互金欺诈团伙,损失方为平台。
在信贷风险中,欺诈风险与信用风险是风控全流程的两个主干内容,虽然同为风险防范的重要组成部分,但在很多方面有着较明显的差异,这也是我们在相关模型的开发与应用上需要特别注意的前提,这里我们从概念定义、风险主体、风控重点等维度,简单对比下二者表现的主要区别:
(1)概念定义:欺诈风险是恶意骗贷的风险,而信用风险是借款人因各种原因未能及时、足额还款而违约的可能性表现;
(2)风险主体:欺诈风险是故意骗贷的客群,而信用风险是非故意骗贷,因突发或暂时原因导致资金无法周转而逾期的客群;
(3)风控重点:欺诈风险是建立反欺诈策略与模型,而信用风险是通过合理风险定价、额度调整防范风险。
2、反欺诈策略与模型
在信贷风控的贷前、贷中、贷后全流程中,欺诈风险与信用风险类似,可以贯穿并体现在各个阶段,欺诈风险的具体表现环节可以有以下多种形式:
(1)贷前环节:活体识别、文字识别、环境安全、账户安全、批量攻击、多头借贷、团伙骗贷等;
(2)贷中环节:放款复审、信息更新、信息变动、信息复核等;
(3)贷后环节:贷后监控、逾期催收、关联网络、失联修复、资产保全等;
针对风控流程各个环节潜在的欺诈风险,我们在大数据风控上必然是策略与模型的综合应用,但对于策略规则与数据模型的开发与应用,在实际场景中有着较为显著的表现差异,我们对策略与模型的优缺点来做个简单分析,具体如下:
(1)策略优点:上手简单、性能较高、易于理解、部署简单、容易调整;
(2)策略缺点:一次切分、单规则覆盖度低、多规则易冲突、维护成本较高;
(3)模型优点:覆盖度较高、单变量敏感度低、整体稳定性好;
(4)模型缺点:需要一定算法能力、评价指标难以选择、建模调优耗费时间。
虽然策略与模型由于各自的本质属性特点,在开发与应用的场景表现中存在一定缺点,但这是客观必然存在的,而我们在具体实践中,需要结合实际场景特点与业务需求,来综合应用策略规则与数据模型,以有效发挥各自模块的性能优势,从而提升信贷风控的决策效果。
3、反欺诈目标的定义
无论采取策略或模型来实现反欺诈,欺诈目标的定义是我们开展业务的前提,而由于信贷欺诈的实际表现形式很多,而且随着当前互联网信息化的发展,欺诈特点也是层出不穷。但是,在信贷欺诈策略与模型开发的风控工作中,针对欺诈目标的定义,也逐渐形成一些常用的方法,主要表现为采用内部数据、外部数据,或者联合多维数据来定义欺诈目标。这里我们将从贷前申请、多头借贷、行为信息、贷后表现等数据维度,来简要介绍下常用的欺诈定义方式。
(1)贷前申请:身份要素核验不一致、活体检测结果不一致、通讯录信息异常等;
(2)多头借贷:三方多头标签、多头欺诈名单、多头信用黑名单等;
(3)行为信息:运营商通讯信息、银联交易信息、电商网购信息等;
(4)贷后逾期:首逾且后期未还款、首逾3天以内还款但后期未还款等。
通过上文对信贷欺诈场景的介绍,我们大体理解了欺诈风险的表现形式与目标定义等,接下来我们将围绕实例样本数据,采用比较流行的随机森林机器学习算法来构建反欺诈模型。在具体数据建模之前,我们先简单熟悉下随机森林算法的原理逻辑与应用特点。
4、随机森林算法
随机森林(Random Forest)是一种经典的集成学习Bagging模型,其弱学习器为决策树模型。集成学习模型是使用一系列弱学习器(基础模型)进行学习,并将各个弱学习器的结果进行整合,从而获得比单个学习器更好的学习效果,集成学习模型的常见算法包括Bagging和Boosting两个类别,其中Bagging算法的典型模型代表便是随机森林,而Boosting算法的典型模型代表包括AdaBoost、GBDT、XGBoost、LightGBM等。
随机森林模型会在原始数据集中随机抽样,构成n个不同的样本数据集,然后根据这些数据集搭建n个不同的决策树模型,最后根据这些决策树模型的平均值(针对回归模型),或者投票结果(针对分类模型)来获取最终结果。随机森林模型与单独的决策树模型相比,由于集成了多个决策树,其预测结果会更准确,且不容易造成过拟合现象,泛化能力更强,随机森林的原理逻辑如图1所示:
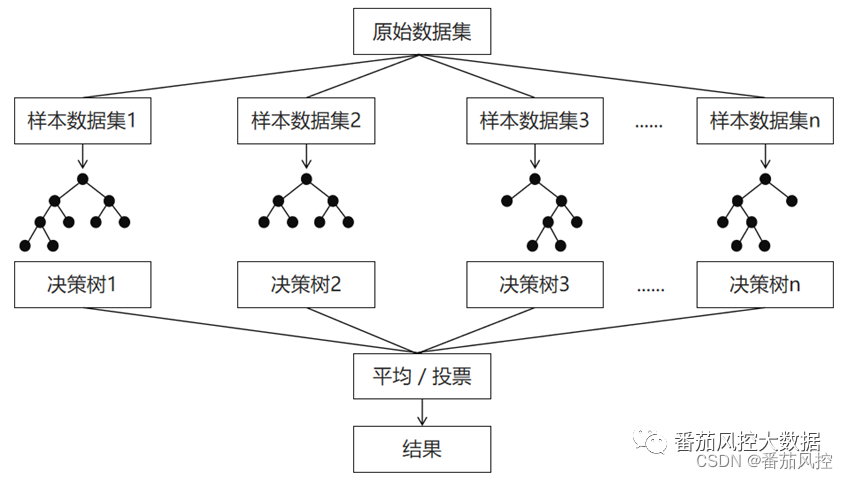
图1随机森林算法原理
随机森林模型为了保证模型的泛化能力(通用能力),在建立每棵树时往往会遵循“数据随机”和“特征随机”这两个基本原则。其中,样本随机是指从所有数据当中有放回的随机抽取数据作为其中一个决策树模型的训练数据;特征随机是指如果每个样本的特征维度为M,指定一个常数k<M,随机地从M个特征中选取k个特征(Python随机森林模型k默认取M的平方根)。
5、反欺诈模型的实现
在熟悉了随机森林的算法原理思想之后,我们将通过具体的样本数据来构建信贷反欺诈模型。本文选取的实例样本数据包含20000条样本与22个特征,部分数据样例如图2所示,其中ID为样本主键;X01~X20为特征变量,取值类型均为数值型;Y为目标变量,代表欺诈标签,取值二分类,其中1/0分别为欺诈与非欺诈,这里假设欺诈是根据存量客户贷后表现的首逾来定义的,字段标签Y的取值分布具体如图3所示。
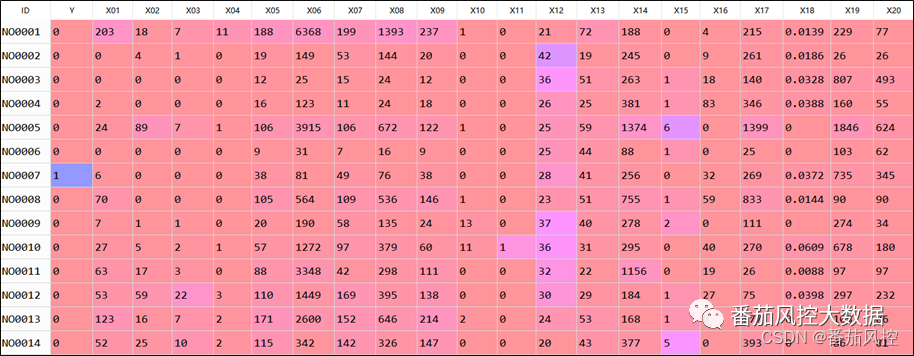
图2样本数据样例

图3欺诈目标分布
从上图结果可知,目标变量的欺诈占比仅有3.115%,数据分布极为不平衡,这种情况也完全符合实际业务表现,毕竟在信贷业务中,欺诈行为是一种少数行为,相比信用违约行为是明显偏少的。但是,对于数据建模的开发流程,针对目标数据不平衡的情形,我们必须采用相关处理方法(例如过采样、欠采样等)来解决目标分布不均衡的问题,这样才能有效保证模型训练的效果,稍后我们会有相应介绍。
在模型训练之前,对于建模数据的特征工程分析处理是一个必然过程,这样可以有助于我们对特征变量进行筛选,从而提升模型训练的精度与效率。这里我们采用比较常用的特征相关性、特征预测性,来完成较优特征字段的选择。针对特征相关性分析,我们采用了pearson相关系数来实现,其结果如图4所示,由于样本字段较多,这里仅显示部分进行说明。
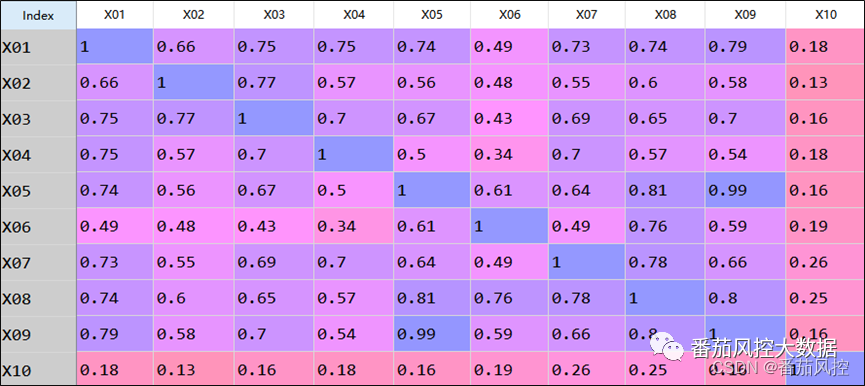
图4特征相关系数分布
由图中信息可知,部分特征字段的相关性系数高于0.7,说明相关特征变量之间的相关性程度较高。我们将对特征pearson相关系数大于0.7的字段进行剔除,这里需要注意的是,对于相关系数大于0.7的两个特征,我们将算出每个特征与其他所有特征的平均相关系数,通过比较二者大小而保留平均系数取值较小的字段,具体实现过程如图5所示。
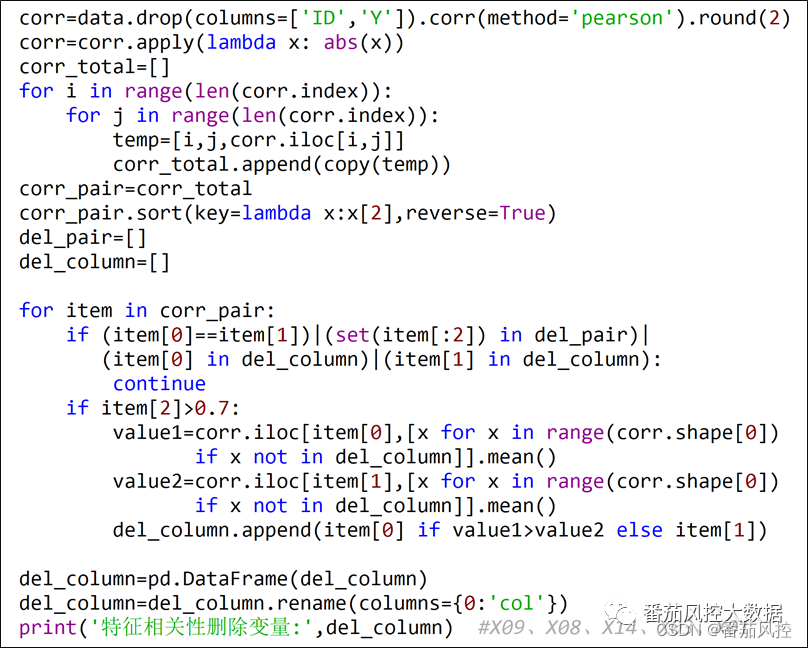
图5特征相关性筛选
通过以上特征相关性筛选的方法,我们从原始特征变量池的20个字段(X01~X20)中,删除了5个特征(X09、X08、X14、X03、X01)。为了更进一步保证模型变量的效果,我们采用特征预测性IV指标来分析各个特征对目标变量的贡献能力,具体实现过程如图6所示,最终得到的特征变量IV值分布如图7所示。
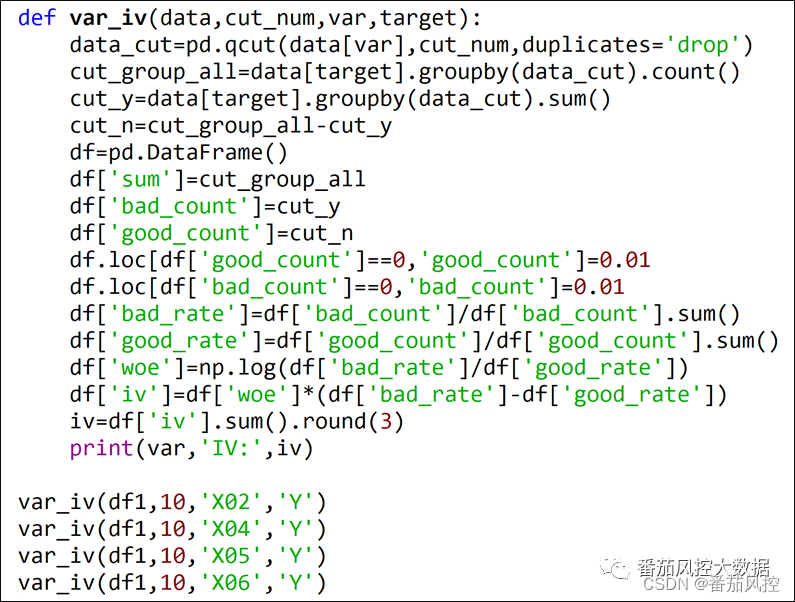
图6特征预测性分析
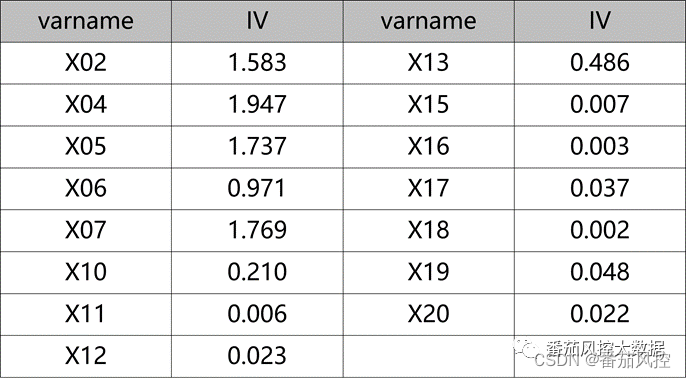
图7特征IV值分布
从以上特征IV值分布结果可知,对于部分特征的预测性能是表现较弱的,例如X11(0.006)、X15(0.007)、X16(0.003)、X18(0.002)都明显低于0.02,因此这里可以考虑将其剔除。这样经过特征相关性与特征预测性分析,我们在模型训练前得到变量池仅包含11个特征。当然,在实际建模场景中,若特征字段的数量较多,还可以采用其他特征工程方法来实现字段的筛选。
当完成对建模数据的特征工程处理后,为了有效保障模型拟合训练的效果,我们需要解决前边提到的目标样本不平衡问题,这里采用随机过采样的方法来实现,具体过程如图8所示。此外,这里特别需要说明的是,针对建模样本的重采样,是对训练样本数据集进行采样,而不需要对测试样本处理,理由是将目标样本数据转变为较平衡状态是为了促进模型的拟合,测试样本数据集是为了验证模型的效果,无需额外进行采样处理,若全部采样反而让测试样本的真实数据分布发生了变化,从而得到的模型测试效果也是无效的。因此,若建模过程需要数据拆分,则务必在建模样本数据拆分为训练集与测试集后,再对训练样本数据进行随机过采样即可,采样后训练样本的目标(0/1)分布比例为1:1,具体实现过程如图8所示。

图8数据拆分与随机过采样
图9随机森林模型训练与测试样,我们得到了模型训练需要的数据集,下面采用随机森林分类算法(RandomForestClassifier),对训练数据进行模型拟合,而测试数据进行模型验证,具体实现过程如图9所示。
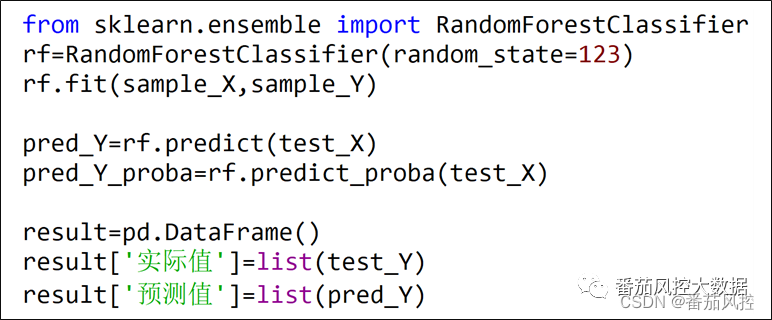
图9随机森林模型训练与测试
为了评估模型的性能效果,我们通过分类模型常用的评价指标来进行分析,包括AUC、KS、Accuracy、Precision、Recall、F1_score等。此外,为了模型进行解释,我们将模型变量的重要性参数输出,具体实现过程如图10所示。
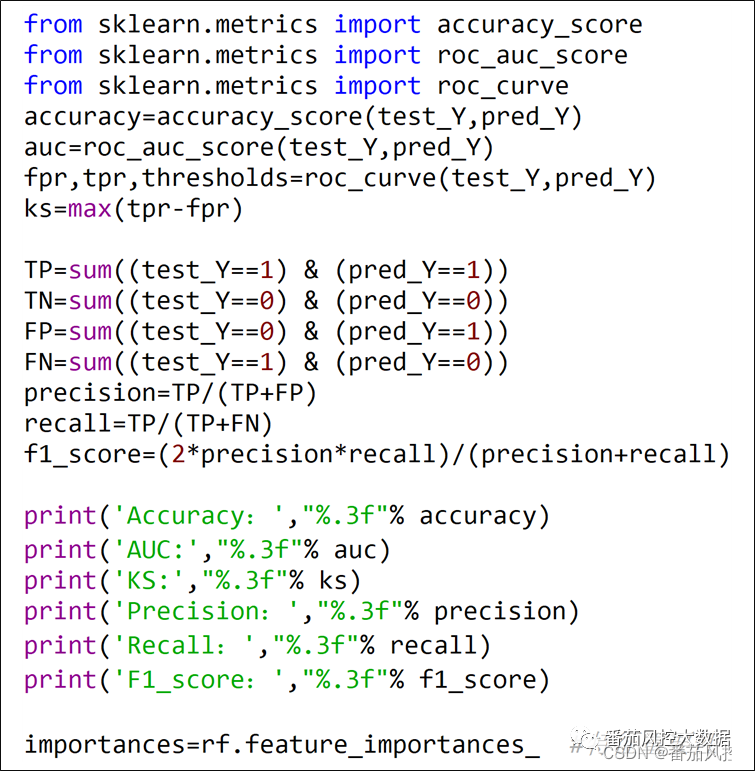
图10模型评估与解释
通过以上方法,得到模型的评价指标如图11所示,同时输出的模型变量的特征重要性系数结果转化为可视化分布如图12所示。
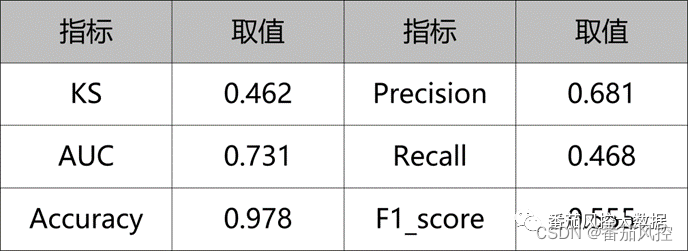
图11模型评价指标
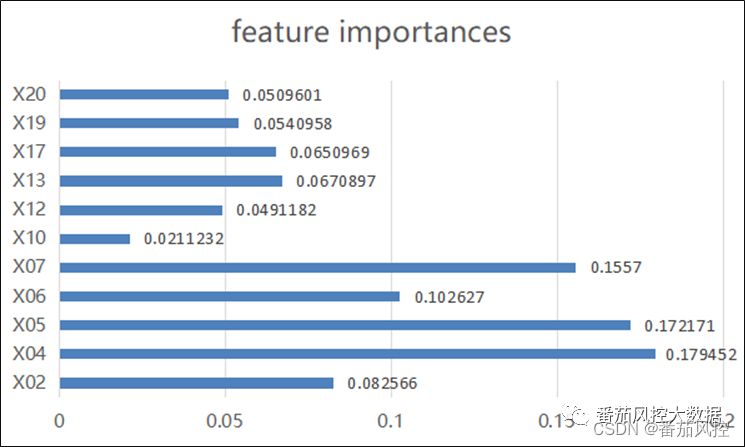
图12特征重要性分布
由以上模型结果可知,本文采用随机森林算法建立的反欺诈模型效果表现较好,同时也能了解到模型内部各个特征变量的贡献能力,这为后续的模型监测也有很好的参考价值。当然,为了保证模型的稳定性能,可以采用交叉验证与网格搜索的方法,来进一步对模型进行调优,以获得性能更优的模型,从而实现反欺诈模型在实际场景欺诈风险识别的效果。
综合以上内容,我们围绕信贷欺诈场景,介绍了欺诈风险的类型特点、风控流程以及欺诈目标的定义逻辑等,并结合实例样本数据,采用随机森林算法完整构建了反欺诈模型,同时对模型的效果进行了评估。
为了便于大家对反欺诈建模过程的进一步理解与熟悉,本文额外附带了与以上内容同步的python代码与样本数据,供大家参考学习,详情请移至知识星球参考相关内容。
…
~原创文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









