







在信贷风控的建模领域里,我们接触最多的莫过于分类模型,尤其是二分类模型,例如违约预测、风险预警、流失分析等,这些场景自然是有监督模型的范畴,其场景应用目的较为明确。对于无监督的聚类算法,在信贷的机器学习建模过程中可能应用相对较少,实际上聚类模型的应用场景也是较为广泛,不仅仅局限于客户画像,而且可以围绕客群样本的聚类结果,来实现客户价值的评估、分群策略的挖掘、层次模型的开发等,这对于风控模型体系的优化具有很好的参考价值。
针对聚类模型,我们很了解这类无监督算法的整体实现过程,具体到Kmeans、DBSCAN等算子也是相对比较熟悉,尤其是Kmeans均值聚类,往往是聚类算法的典型代表,而且在实际场景中经常得到应用。但是,要掌握好聚类算法体系的各类方法,或者说围绕客户样本群体实现更有效的类别划分,仅仅熟悉Kmeans聚类方法是完全不够的,我们需要了解更多的方法,并将其应用到实践,这样可以更全面且更有效的解决样本聚类的问题。
围绕以上实际场景情况,本文将为大家介绍下常用的聚类算法,共包括10种实现方法,除了经典的Kmeans聚类、DBSCAN聚类、聚合聚类之外,还包括Mini-Batch Kmeans聚类、BIRCH聚类、均值漂移聚类、OPTICS聚类、光谱聚类、亲和力传播聚类、高斯混合聚类等,让大家全面掌握聚类模型的算法体系,在实际业务中玩转样本聚类的数据分析场景。在具体介绍过程中,为了便于大家的深入理解,我们会对每类算法的原理逻辑进行简要描述,同时结合实例样本数据,依次采用各种聚类算法,实现样本数据的簇类划分,并将模型聚类结果的样本分布情况通过图表形式实现可视化展示。
首先,我们来构建一份样本数据,采用随机方式生成一份包含1000条样本和2个特征的数据,同时赋予真实的类别标签,目的是为了验证后续各种聚类算法的模型分簇效果。样本数据的生成过程如图1所示,具体根据make_classification()函数来构建自变量X与因变量Y的测试数据(df_X、df_Y),其中目标类别定义为二分类,也就是当前样本数据的真实标签类型为2个群体,生成的样本数据部分样例如图2所示。针对样本数据的客群分布情况,通过散点图的可视化形式进行输出,具体分布结果如图3所示。
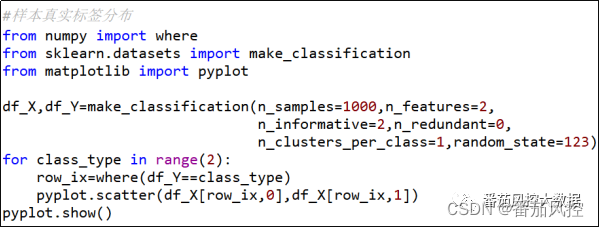
图1 样本测试数据生成
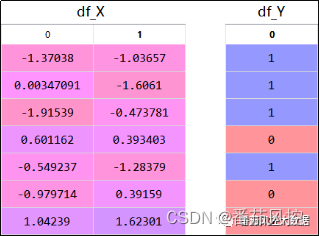
图2 样本测试部分样例
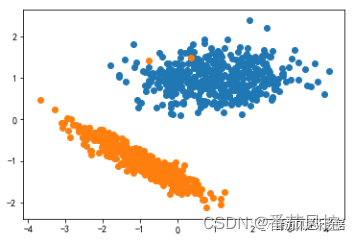
图3 样本真实标签分布
1、Kmeans聚类
Kmeans均值聚类是最常见的聚类方法,应用也较为广泛,具体是通过设定合适的K值,来聚类不同的样本标签。通常情况下,聚类数K值可以通过“肘部法”来实现,也可以结合实际业务需求来指定。下面我们根据图1生成的样本X数据(df_X),采用Kmeans算法来进行聚类分析,这里的样本数据不包含Y标签(df_Y)。Kmeans聚类模型的实现过程如图4所示,这里为了与上文的真实标签分布进行对比,模型聚类数量设置为2类。同时,围绕模型聚类的标签结果,通过散点图的可视化形式进行展现,具体如图5所示。对于聚类数2的设定,以及聚类效果的标签分布展示,下文各种模型算法均采用这样逻辑来展开分析。
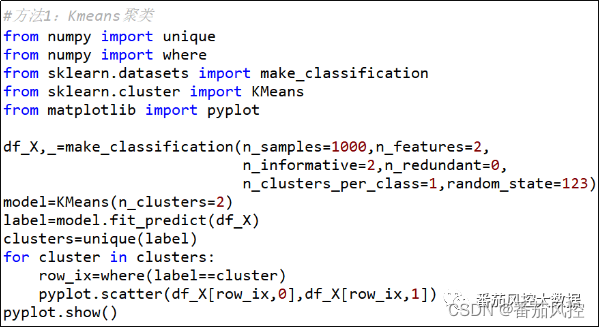
图4 Kmeans聚类过程
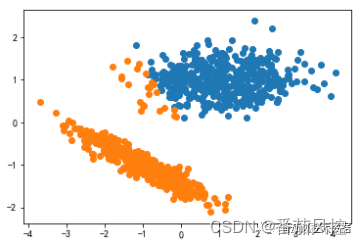
图5 Kmeans聚类可视化
通过Kmeans聚类模型的簇类分布结果可以直观看出,样本聚类后的簇类效果是比较好的,与图2的样本真实标签分布非常接近,说明在当前测试样本数据的情况下,Kmeans聚类的效果是较为合理的。
2、DBSCAN聚类
DBSCAN聚类是根据样本密度的空间聚类方法,在实际场景应用中也较为广泛,DBSCAN的原理是识别特征空间的密集区域,从而形成簇类,而相对较空的区域将各簇进行分隔。DBSCAN聚类无需提前设置聚类数量,而是通过指定参数eps(邻域半径)与min_samples(最小样本数)来定义样本聚类条件,具体实现过程如图6所示,簇类分布可视化结果如图7所示。
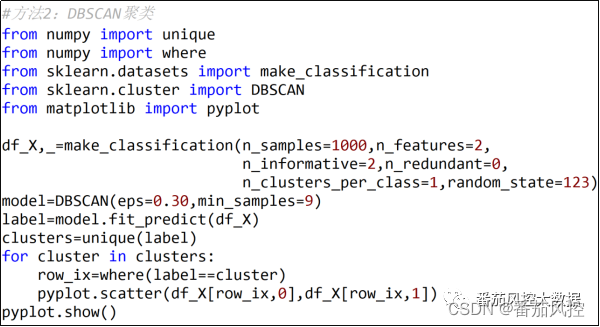
图6 DBSCAN聚类过程
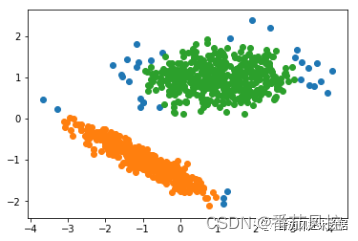
图7 DBSCAN聚类结果
通过DBSCAN聚类的样本簇类分布结果可知,DBSCAN的聚类数量结果为3,各簇分布效果表现一般,虽然绿色样本点与橙色样本点代表的簇类聚合效果较好,但蓝色样本点代表的簇类较为分散。
3、聚合聚类
聚合聚类是层次聚类中最经典且应用最为广泛的聚类方法,原理是通过不同类别样本数据点之间的相似度,来创建一棵有层次的嵌套聚类树。在聚类树的结构中,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点。层次聚类通过AgglomerationClustering()类来完成,聚类数量可以根据参数n_clusters来指定,具体实现过程如图8所示,簇类分布可视化结果如图9所示。
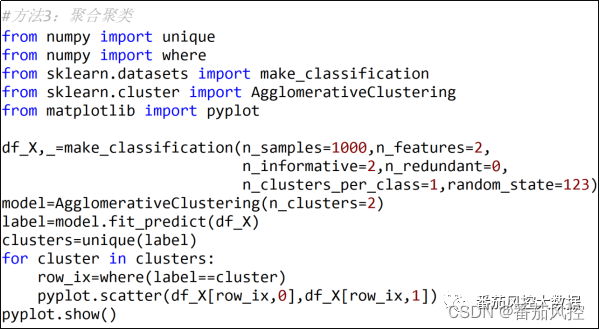
图8 聚合聚类过程
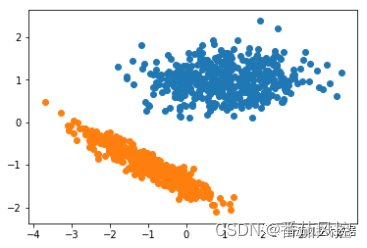
图9 聚合聚类结果
通过聚合聚类的样本簇类分布结果可知,聚类效果表现很好,蓝色与橙色两个簇类的区分度非常明显,与样本的真实标签分布情况基本是一致的。
4、Mini-Batch Kmeans聚类
Mini-Batch Kmeans聚类是Kmeans聚类的衍生版本,采用小批量的样本数据对样本群体的质心进行更新,而非对整个样本数据集处理,这样可以有效减少模型的收敛时间,提高聚类任务的效率。Mini-Batch Kmeans聚类通过MiniBatchKMeans()类来完成,并根据参数n_clusters指定聚类数量,具体实现过程如图10所示,簇类分布可视化结果如图11所示。
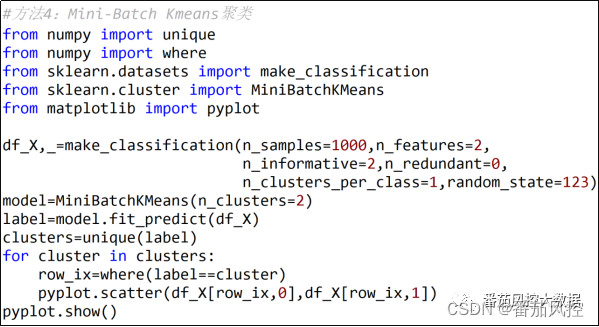
图10 Mini-Batch Kmeans聚类过程
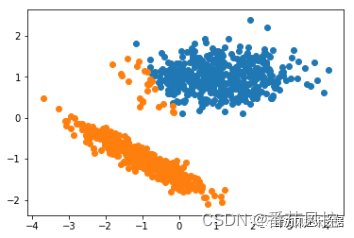
图11 Mini-Batch Kmeans聚类结果
通过Mini-Batch Kmeans聚类的样本簇类分布结果可知,模型的整体聚类效果较好,尽管少部分橙色样本点偏向蓝色样本点的对应簇,但两个簇的整体区分效果是较为明显的。
5、BIRCH聚类
BIRCH聚类是层次聚类的一种拓展算法,通过构建一个树状结构,并从中提取聚类质心。BIRCH聚类通过Birch()类完成,并根据指定参数threshold和n_clusters来定义聚类任务,具体实现过程如图12所示,簇类分布可视化结果如图13所示。
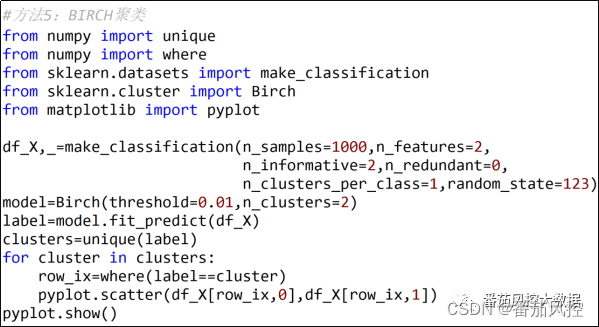
图12 BIRCH聚类过程
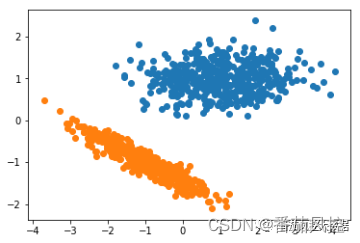
图13 BIRCH聚类结果
通过BIRCH聚类的样本簇类分布结果可知,聚类效果表现很好,蓝色与橙色两个簇类的区分度非常明显,与样本的真实标签分布情况基本是一致的。
6、均值漂移聚类
均值漂移聚类是根据滑动窗口的算法,试图寻找样本数据点的密集区域,其目标是定位每个类的中心点,通过将中心点的候选点更新为滑动窗口内点的均值来完成,然后在处理阶段对这些候选窗口进行过滤以消除近似重复,从而形成最终中心点及其相应的簇。均值漂移聚类通过MeanShift()类来完成,具体实现过程如图14所示,簇类分布可视化结果如图15所示。
图14 均值漂移聚类过程
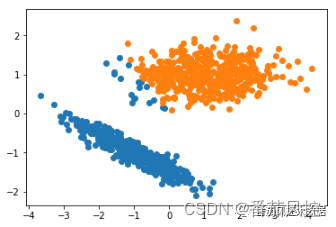
图15 均值漂移聚类结果
通过均值漂移聚类的样本簇类分布结果可知,聚类效果较好,尽管少部分蓝色样本点偏向橙色样本点的对应簇,但两个簇类的整体区分效果是非常明显的。
7、OPTICS聚类
OPTICS聚类是DBSCAN聚类的衍生版本,属于密度聚类的一种方法,通过OPTICS()类来完成,可以根据配置参数eps(半径)与min_samples(最小样本数)确定聚类对象,具体实现过程如图16所示,簇类分布可视化结果如图17所示。
图16 OPTICS聚类过程
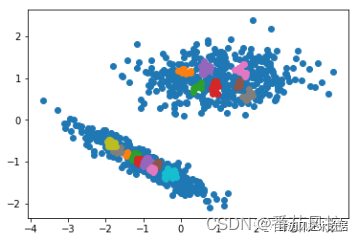
图17 OPTICS聚类结果
通过OPTICS聚类的样本簇类分布结果可知,聚类效果表现较差,不同颜色的样本点混合程度较复杂,说明样本数据没有得到较好的分簇。
8、亲和力传播聚类
亲和力传播聚类无需指定聚类的数量,且簇类结果的中心点为已有数据点,通过AffinityPropagation()类来完成,可以定义参数damping来确定拟合条件,具体实现过程如图18所示,簇类分布可视化结果如图19所示。
图18 亲和力传播聚类过程
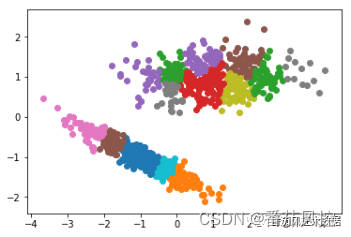
图19 亲和力传播聚类结果
通过亲和力传播聚类的样本簇类分布结果可知,聚类效果表现较差,不同颜色的样本点混合程度较为复杂,说明样本数据没有得到较好分簇。
9、光谱聚类
光谱聚类通过Spectral()类实现的,取自线性代数,根据参数n_clusters指定聚类数量,具体实现过程如图20所示,簇类分布可视化结果如图21所示。
图20 光谱聚类过程
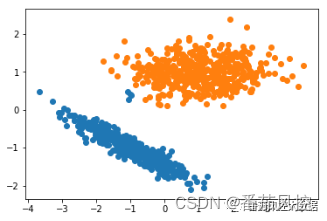
图21 光谱聚类结果
通过光谱聚类的样本簇类分布结果可知,聚类效果较好,仅有个别蓝色样本点偏向橙色样本点,但整体的区分效果是非常明显的。
10、高斯混合聚类
高斯混合聚类是一个多变量概率密度函数,混合了高斯概率分布,通过Gaussian Mixture()类实现的,根据参数n_clusters指定聚类数量,具体实现过程如图22所示,簇类分布可视化结果如图23所示。
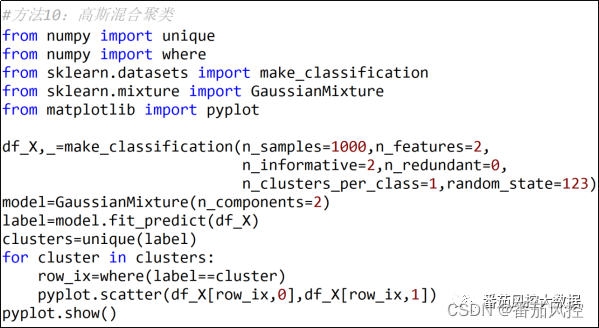
图22 高斯混合聚类过程
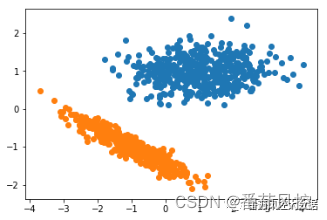
图23 高斯混合聚类结果
通过高斯混合聚类的样本簇类分布结果可知,聚类效果表现很好,蓝色与橙色两个簇类的区分度非常明显,与样本的真实标签分布情况基本是一致的。
综合以上内容,我们依次介绍了样本聚类模型的10大算法,虽然围绕本文测试样本数据,各种方法下聚类效果有一定区别,但整体上分簇效果是比较好的。当然,以上分析过程并不能反映其中哪些算法是最佳聚类方法,具体聚类效果的好坏是由样本数据分布、算法参数配置、业务场景需求等情况综合决定的。因此,在实际业务中,针对客户分层、客户画像等场景,我们应学会采用不同的聚类方法来进行对比分析,这样才能获得较好的聚类结果。其中,我们优先可以采用Kmeans聚类、DBSCAN聚类、层次聚类、Mini-Batch Kmeans聚类等,同时要熟悉各算法的原理逻辑与参数应用。总之,聚类模型并非重点在于某种方法,而是通过不同方法的尝试与验证获取较好的聚类效果。
本文已为大家梳理了数据分析领域常见的聚类方法,而且实现过程也非常方便,仅需要调用sklearn库的相关类函数,然后配置好合适的算法参数,接下来根据模型训练与预测的标签结果,结合实际场景来评价模型聚类的效果。为了便于大家对以上各种聚类算法的进一步了解与熟悉,本文额外附带了与以上内容同步的python代码与样本数据,详情请移至知识星球查看相关内容。
更多详细内容,有兴趣的童鞋可关注:

…
~原创文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









