







对抗搜索
文章目录
1 为什么要学习对抗搜索?
上文开篇我们说了为什么要学习一点算法:不求能上天飞黄腾达,但至少得知道将来干掉自己的是谁,不能走的不明不白,是不?
李开复曾经把基础课程比拟为“内功”,把新的语言、技术、标准比拟为“外功”。 整天赶时髦的人最后只懂得招式,没有功力,是不可能成为高手的。真正学懂计算机的人(不只是“编程匠”)都对数学有相当的造诣,既能用科学家的严谨思维来求证,也能用工程师的务实手段来解决问题——而这种思维和手段的最佳演绎就是“算法”。

对抗搜索是一类算法的算法的总称,也是机器学习的一个分支。那我们为什么要学习对抗搜索呢?实在点,学它对我们有什么用?能增收或撩妹不?你总得给我个理由是不!
为了回答这个问题,我们先看一下这张图,也是AI的发展简史:
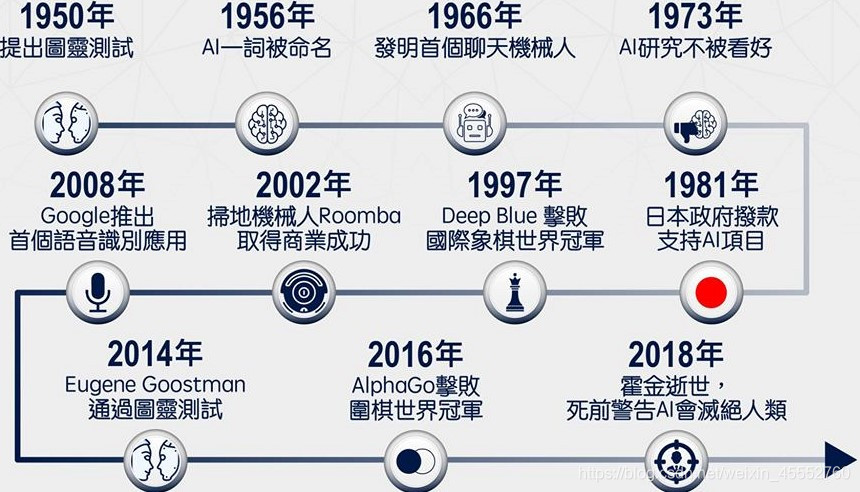
从图中可以看到,1997年Deep Blue世纪大战和2016年AlphaGo击败李世石,其中的关键技术即是对抗搜索技术。在棋类游戏里AI已经超过了人类,另外,在我们数学部分第一讲的概述中也提到了同样的问题,AI在计算机视觉领域(如ImageNet的识别)等也是远远优于人类的。**刺激不?危机不?**那怎么办呢?
成年人别问那么多,直接干学就完了!
再举一个棋类例子:设想你在玩井字棋:

井字棋是一种在3 * 3格子上进行的连珠游戏,和五子棋类似,分别代表O和X的两个游戏者轮流在格子里留下标记(一般来说先手者为X),任意三个标记形成一条直线,则为获胜。

2 什么是对抗搜索?
老规矩,为了方便描述,我们先介绍几个概念,有个先验印象,对抗搜索涉及几个常见概念:智能体、对抗搜索和博弈树。
智能体
智能体(agents):在信息技术尤其是人工智能和计算机领域,可以看作是能够通过传感器感知其环境,并借助于执行器作用于该环境的任何事物。以人类为例,我们是通过人类自身的五个感官(传感器)来感知环境的,然后我们对其进行思考,继而使用我们的身体部位(执行器)去执行操作。类似地,机器智能体通过我们向其提供的传感器来感知环境(可以是相机、麦克风、红外探测器),然后进行一些计算(思考),继而使用各种各样的电机/执行器来执行操作。现在,你应该清楚在你周围的世界充满了各种智能体,如你的手机、真空清洁器、智能冰箱、恒温器、相机,甚至你自己。
对抗搜索
对抗搜索也称为博弈搜索,在人工智能领域可以定义为:有完整信息的、确定性的、轮流行动的、两个游戏者的零和游戏(如象棋)。
游戏:意味着处理互动情况,互动意味着有玩家会参与进来(一个或多个);
确定性的:表示在任何时间点上,玩家之间都有有限的互动;
轮流行动的:表示玩家按照一定顺序进行游戏,轮流出招;
零和游戏:意味着游戏双方有着相反的目标,换句话说:在游戏的任何终结状态下,所有玩家获得的总和等于零,有时这样的游戏也被称为严格竞争博弈;
关于零和,也可以这样来理解:自己的幸福是建立在他人的痛苦之上的,二者的大小完全相等,因而双方都想尽一切办法以实现“损人利己”。零和博弈的结果是一方吃掉另一方,一方的所得正是另一方的所失,整个社会的利益并不会因此而增加一分。
例如下井字棋,一个游戏者赢了+1,则另一个一定输了-1,总和等于零。
博弈树
考虑两个游戏者:MIN和MAX,MAX先行,然后两人轮流出招,直到游戏结束。在游戏最后,给优胜者积分,给失败者罚分。
游戏可以形式地定义成含有下列组成部分的一类搜索问题:
- 初始状态,包含棋盘局面和确定该哪个游戏者出招。
- 后继状态,返回(move,state)对(两项分别为招数、状态)的一个列表,其中每一对表示一个合法的招数和其结果状态。
- 终止测试,测试判断游戏是否结束,游戏结束的状态称为终止状态。
- 效用(收益)函数,效用函数(又称为目标函数或者收益函数),对终止状态给出一个数值。在井字棋中,结果是赢、输或平,分别赋予数值+1、-1或0。有些游戏有更多的可能结果,例如双陆棋的收益范围从-192到+192。
每方的初始状态和合法招数定义了游戏的博弈树。上图给出了井字棋的部分博弈树。在初始状态,MIN有9个可能的走法。游戏交替执行,MAX下X,MIN下O,直到我们到达了树的叶节点对应的终止状态,也就是说一方的三个棋子连成一条直线或者所有棋位都填满了。叶节点上的数字指示了这个终止状态对于MAX来说的效用值;值越高被认为对MAX越有利,而对MIN则越不利。所以MAX的任务是利用搜索树(特别是终止状态的效用值)来确定最佳的招数,即求解终止状态为+1的招数。

3 对抗搜索算法
上节提到的#字棋游戏,我们可以大概画出它的博弈树:
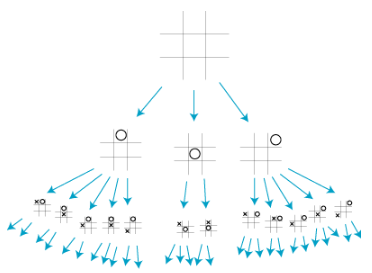
有了这样一棵博弈树之后,有没什么方法找到最优解呢?我们介绍三种常见算法: 极小极大值算法、α-β剪枝、 蒙特卡罗树搜索算法。
3.1 极小极大值算法
本节我们以例子形式展开介绍极小极大算法。
3.1.1 分硬币游戏
虽然就算是井字棋这样的简单游戏,但是想要画出它的整个博弈树对我们而言也太复杂了,所以我们将转而讨论一个更简单的游戏:分硬币游戏。
假设我们已经有一个评价每种决策的收益的估值函数。对于极大层节点,如果我们知道了它的每一步决策的收益值,那么它总是会选择收益最大的那个决策,作为它的节点的收益值;反过来,对于极小层节点,它总是会选择收益最小的(对我方收益最小,就是对方收益最大)那个决策。
游戏规则是:一堆硬币,双方轮流将它分成大小不能相等的两堆,然后下一个人挑选任意一堆继续分下去,双方交替游戏,直到其中一个人无法继续分下去,则对方获得胜利。
假设我们刚开始有一堆7枚硬币,轮到我方先分。我需要找到我当前应该怎么样分这堆硬币。或者说,需要找到当前能够获得最优收益的决策,我们通过构造出一棵极大极小树来做到。
首先,我们穷举所有的可能的状态。用矩形代表轮到我方做决策的极大层节点,用圆形代表轮到对方做决策的极小层节点,列举出所有的状态:
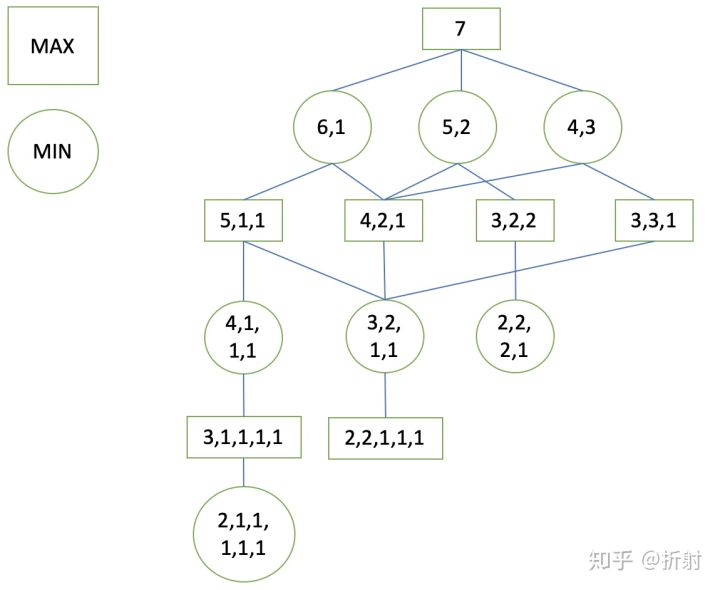
注意,到这里我们还没有进行估值 ,因此这还不算是极大极小树。下面
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1456
1456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









