







 本文详细介绍了计算机视觉和深度学习课程中的关键概念,包括欠拟合和过拟合的定义,以及如何通过L2正则化来缓解过拟合问题。L2正则化通过惩罚大权重值来分散模型的注意力,提高泛化性能。此外,随机失活(dropout)也被讨论,作为另一种防止过拟合的策略,它通过以一定概率随机关闭神经元来降低模型复杂性。超参数如学习率的选择对模型性能至关重要,可以通过手动或策略调整来优化。文章还强调了在对数空间上随机采样超参数的建议。
本文详细介绍了计算机视觉和深度学习课程中的关键概念,包括欠拟合和过拟合的定义,以及如何通过L2正则化来缓解过拟合问题。L2正则化通过惩罚大权重值来分散模型的注意力,提高泛化性能。此外,随机失活(dropout)也被讨论,作为另一种防止过拟合的策略,它通过以一定概率随机关闭神经元来降低模型复杂性。超参数如学习率的选择对模型性能至关重要,可以通过手动或策略调整来优化。文章还强调了在对数空间上随机采样超参数的建议。
笔记:计算机视觉与深度学习-北邮-鲁鹏-2020年录屏
写在开头(重复的)
1.课程来源:B站视频.
2.笔记目的:个人学习+增强记忆+方便回顾
3.时间:2021年4月14日
4.同类笔记链接:(钩子:会逐渐增加20210428)
第一讲.第二讲.第三讲.第四讲.第五讲.第六讲.第七讲.第八讲.第九讲.第十讲.第十一讲.番外篇一个简单实现.第十二讲.第十三讲.第十四讲完结.
5.请一定观看视频课程,笔记是对视频内容的有限度的重现和基于个人的深化理解。
6.注意符号 SS:意味着我的个人理解,非单纯授课内容,有可能有误哦。
—以下正文—
(00:00-21:16)为复习内容
一、欠拟合与过拟合
(一)概念(略)
- 1.欠拟合:。。。
- 2.过拟合:。。。
(二)L2正则化
- 1.次优方案-正则化:调节模型允许存储的信息量或者对模型语序存储的信息加以约束,该方法也称为正则化。
- 1.1调节模型大小
- 1.2约束模型权重,既权重正则化(常用的有L1、L2正则化)
- 1.3随机失活(dropout)
- 2.使用L2正则化的损失函数为:(红字为L2正则项)

- 3.L2正则损失对于大数值的权值向量进行严厉惩罚,鼓励更加分散的权重向量,使模型倾向于使用所有输入特征做决策,此时的模型泛化性能好。
- 3.1 SS 泛化性能好,是指模型在验证集和真实情况中的性能更好。
(三)随机失活dropout
- 1.随机失活:让隐藏的神经元以一定概率不被激活。
- 2.【概念、超参数】随机失活比率(Dropout ratio):是被设定为0的特征所占的比例,通常在0.2—0.5范围内。
- 3.实现方式:训练过程中,对某一层使用Dropout,就是随机将该层的一些输出舍弃(输出值设置为0),这些被舍弃的神经元就好像被网络删除了一样。
- 4.随机失活为什么能够防止过拟合?
- 解释1:能够降低模型容量(不解释)
- 解释2:鼓励权重分散(从而实现与正则化一样的效果)
- 解释3:Dropout可以看作模型的集成
- 5.随机失活在使用中存在的问题(此例中使用dropout系数0.5)
- 5.1借用数学工具,期望值的计算:

- 5.2可以发现,用dropout训练时,训练阶段的模型对训练集所有图的输出的值的数学期望,系统性的低于实际使用中(这阶段没有随机失活)的输出值的数学期望。(至于具体低多少,与失活比率相同)
- 应用示例(python)(具体流程57:00)

- 5.1借用数学工具,期望值的计算:
二、神经网络中的超参数
- 1.网络结构:隐层神经元个数、网络层数、非线性单元选择等
- 2.优化相关:学习率、dropout比率、正则项强度等
(一)学习率的调整
- 1.基于经验的手动调整(常用)
通过尝试不同的固定学习率,如3、1、0.5、0.1、0.05、0.01、0.005,0.005、0.0001、0.00001等,观察迭代次数和loss的变化关系,找到loss下降最快关系对应的学习率。 - 2.基于策略的调整
- 2.1 fixed 、exponential、polynomial
- 2.2自适应动态调整:adadelta、adagrad、ftrl、momentum、RMSProp、sgd
- 3.超参数选择时的标尺空间(无论手动还是随机选择)
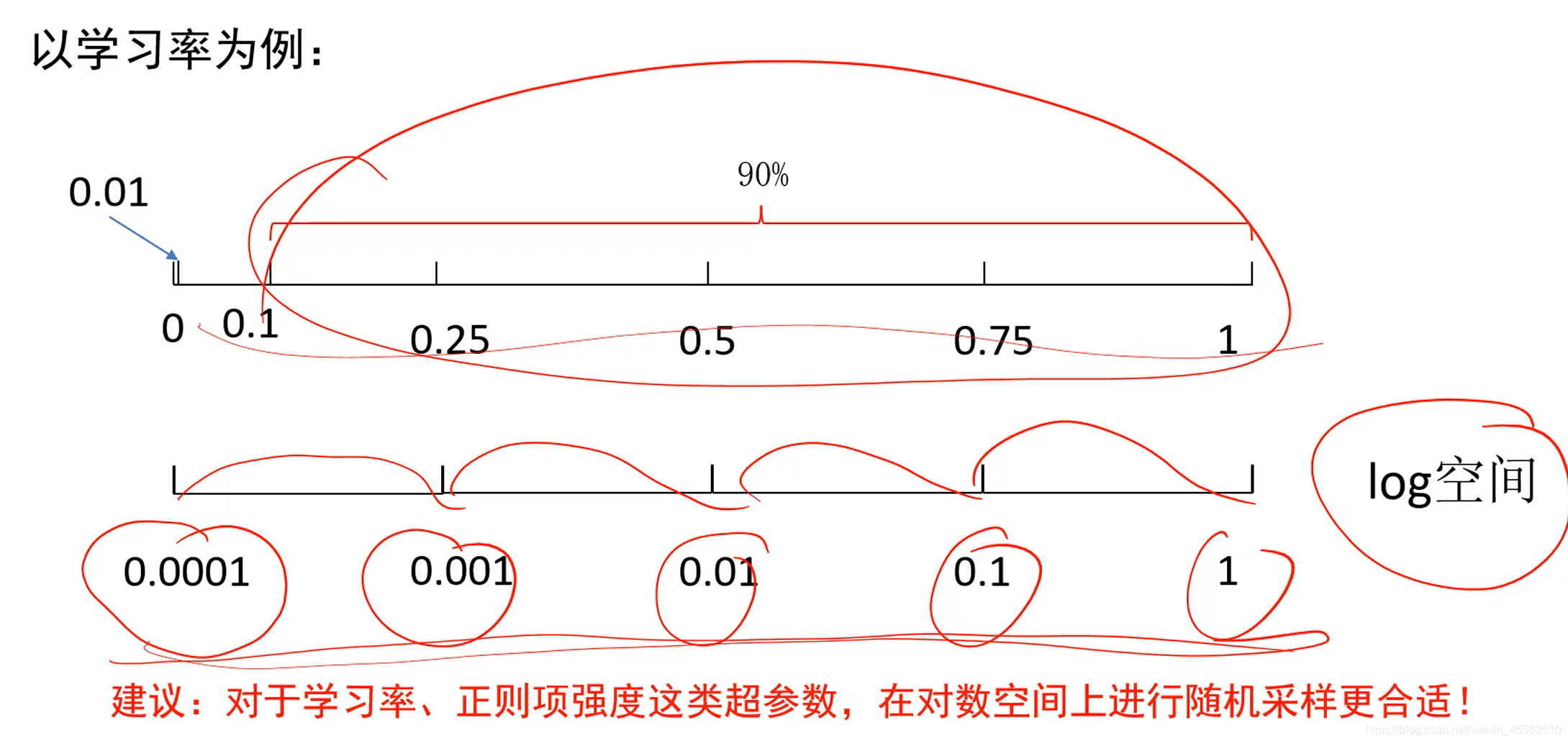
- 3.1建议(经验):在对数空间上进行随机采样更合适。
(79:20-结束)是对以上三章内容的串讲,有较好的连贯性和总结性,建议反复听。

















 1163
1163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









