




 本文介绍了计算机视觉领域中的目标检测技术,包括RCNN系列、YOLO4等算法,并探讨了影响检测精度的因素。同时,文章还讲解了实例分割技术,如Mask R-CNN及其应用场景。
本文介绍了计算机视觉领域中的目标检测技术,包括RCNN系列、YOLO4等算法,并探讨了影响检测精度的因素。同时,文章还讲解了实例分割技术,如Mask R-CNN及其应用场景。
笔记:计算机视觉与深度学习-北邮-鲁鹏-2020年录屏
写在开头(重复的)
1.课程来源:B站视频.
2.笔记目的:个人学习+增强记忆+方便回顾
3.时间:2021年4月19日
4.同类笔记链接:(钩子:会逐渐增加20210428)
第一讲.第二讲.第三讲.第四讲.第五讲.第六讲.第七讲.第八讲.第九讲.第十讲.第十一讲.番外篇一个简单实现.第十二讲.第十三讲.第十四讲完结.
5.请一定观看视频课程,笔记是对视频内容的有限度的重现和基于个人的深化理解。
6.注意符号 SS:意味着我的个人理解,非单纯授课内容,有可能有误哦。
—以下正文—
一、目标检测
(一)分类+定位两个任务
- 1.一个卷积网找特征,两套全连接神经网分别分类和定位
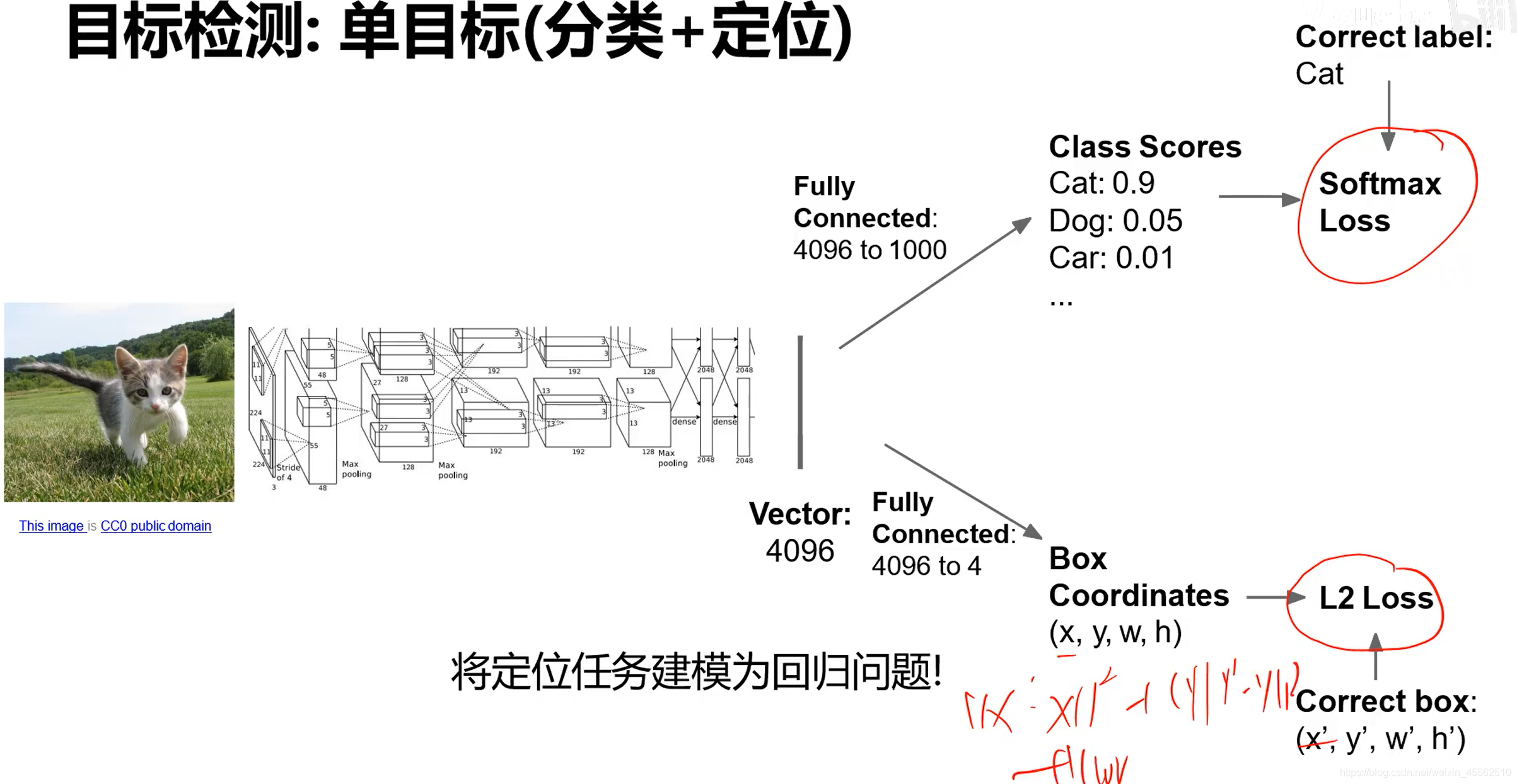
- 2.网络的训练流程:若标记卷积网为1,分类全连接神经网为2,定位全连接神经网为3;训练流程分为三个阶段,第一阶段为12,第二阶段不使用2,使用但不训练1,只训练3,第三阶段训练123。
- 3.这种两个分支的网络,损失如何传递:
- 3.1定位网络的损失计算:使用相对距离
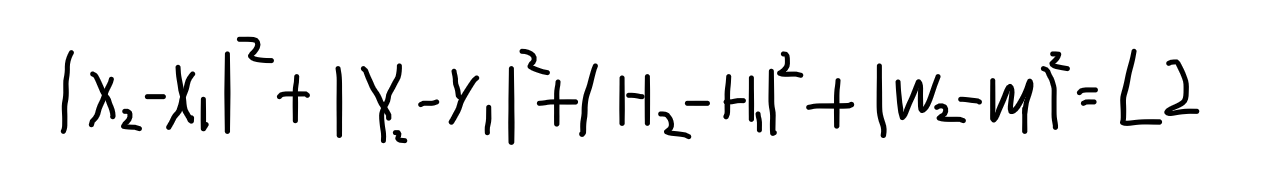
- 3.2多任务损失(第三阶段中)
- 3.1定位网络的损失计算:使用相对距离
(二)目标检测中的多目标问题
- 1.多目标问题的难点在于:目标个数不确定。由上部目标识别的定位部分可知,一个目标识别框要有一条神经网络的链路,两个框意味着两个链路,框的个数未知,无法设计网络。
- 2.换一种思路,只设计一个框,框可以滑动,循环识别图中的所有可能位置,数目会达到上百万。但是这样做的计算量显然是不可接受的。

- 3.区域建议【selective search】:
- 3.1相关论文:“measuring the objectness of image windows”2012;“selective search for object recognition”2013;“BING:binarized normed gradients for objectness estimation at 300fps”2014;“edge boxes:locating object proposals from edges”2014;
- 3.2优势:再CPU上运行,仅需几秒,产生2000左右可能区域。
- 4.RCNN(SS基于区域建议的卷积神经网络)
- 4.1论文基础:“Rich feature hierarchies for accurate oject detection and semantic segmentation”2014
- 4.2基本工作流程
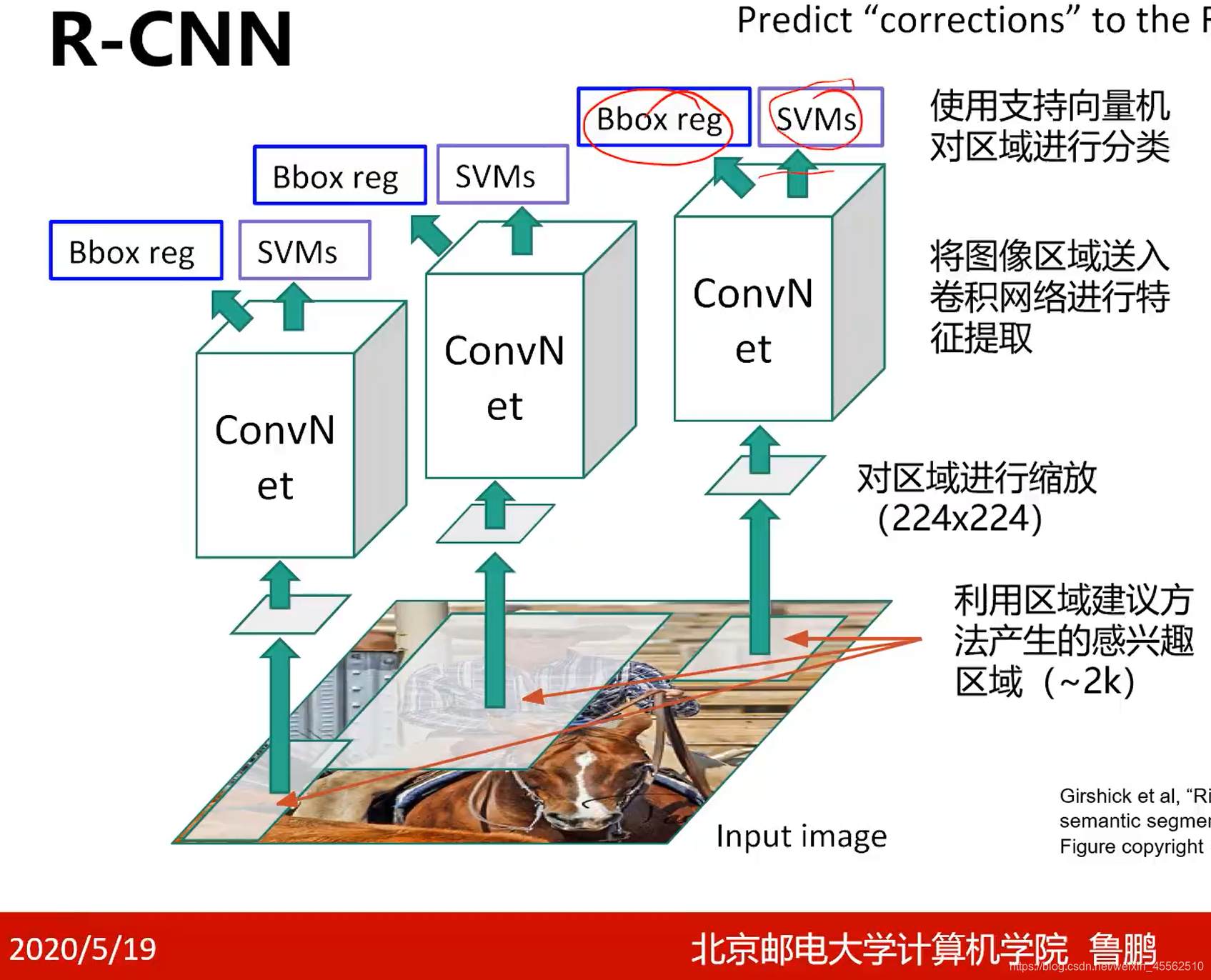
- 4.3其中的ConvN et单纯的作为特征提取使用;SVMs支撑向量机对提取到的特征进行分类。
- 4.4需要单独解释Bbox reg模块,称为边界框回归,用于对比正确的边界框和之前计算出的边界框的差距,学习这种差距,以此修正selective search给出的答案(注意是修正答案,不是翻过去修正selective search中的参数)
- 4.5效率低下,只能研究用,不能实际使用。
- 5.fast R-CNN
- 5.1结构如下所示
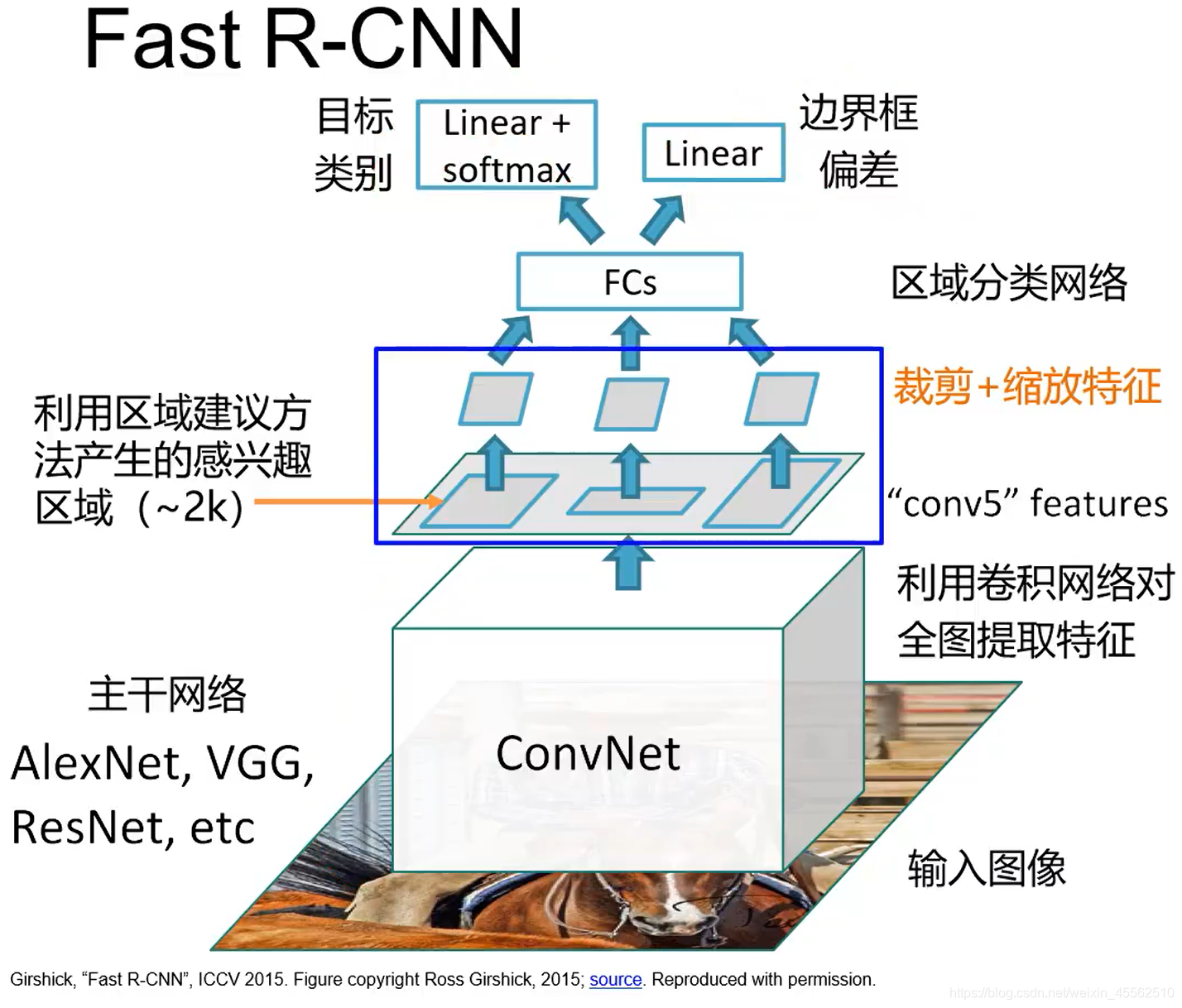
- 5.2改进一:卷积网络对全图提取特征,之后再针对“感兴趣”的区域进行裁剪缩放。改变了次序,避免了先划分区域后提取特征出现的重复卷积计算。
- 5.3改进二:创建了ROI POOL机制,使得裁剪和缩放步骤可到,使得上层的梯度可以向下的卷积层传导。(这个机制后面专门讲)
- 5.4改进三:使用了FC。
- 5.1结构如下所示
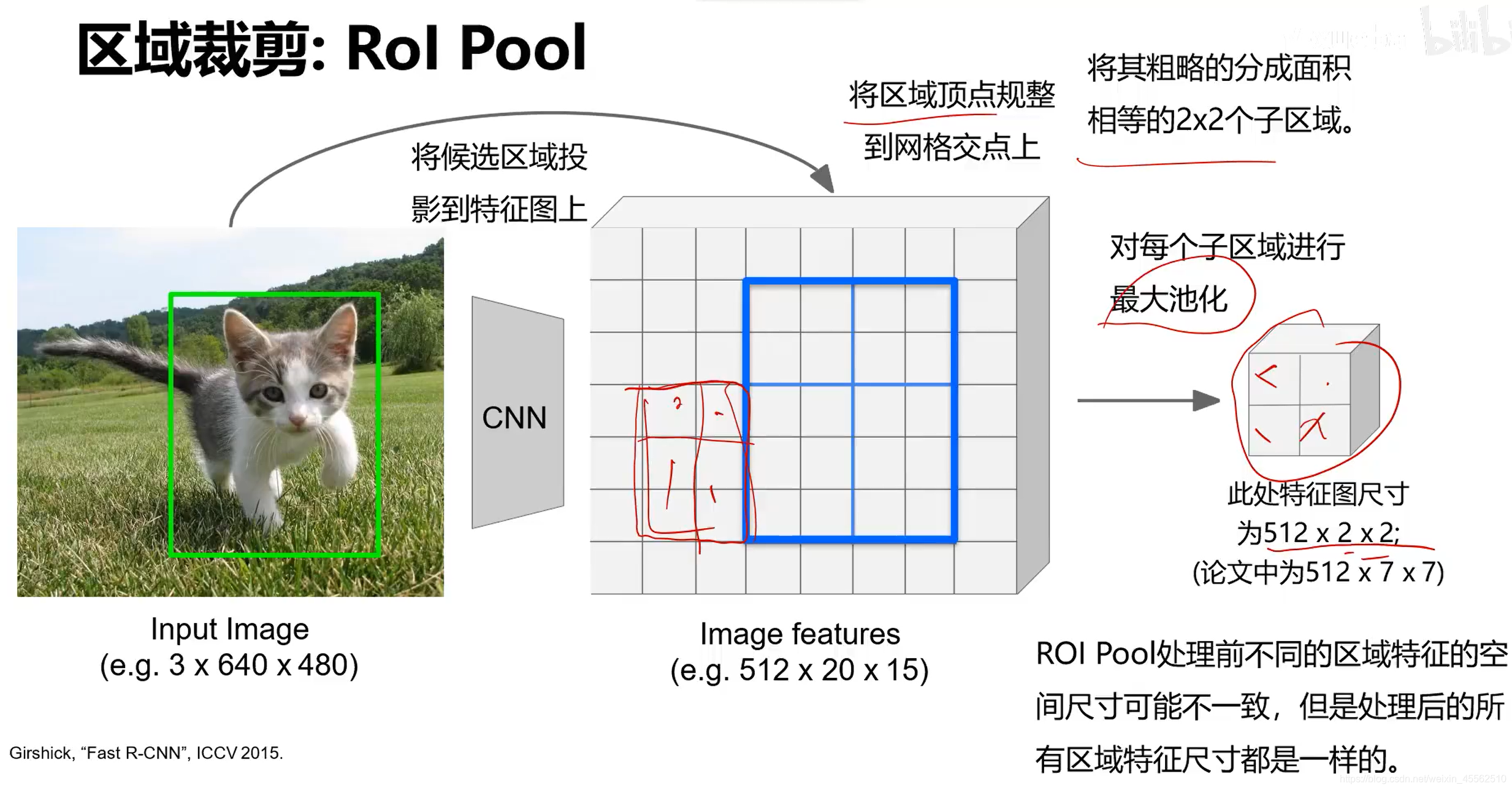
- 6.区域裁剪之ROI POOL:
- 6.1该方法解决的问题,不同尺寸的特征图的维数不同,没法传递给同一套全连接神经网络。通过pool操作解决这一问题。
- 6.2该方法面临问题,候选区投影到特征图上时不能完全对齐。给全连接神经网络的处理带来了一定麻烦。
- 7.区域裁剪之ROL Align
- 7.1步骤如下图
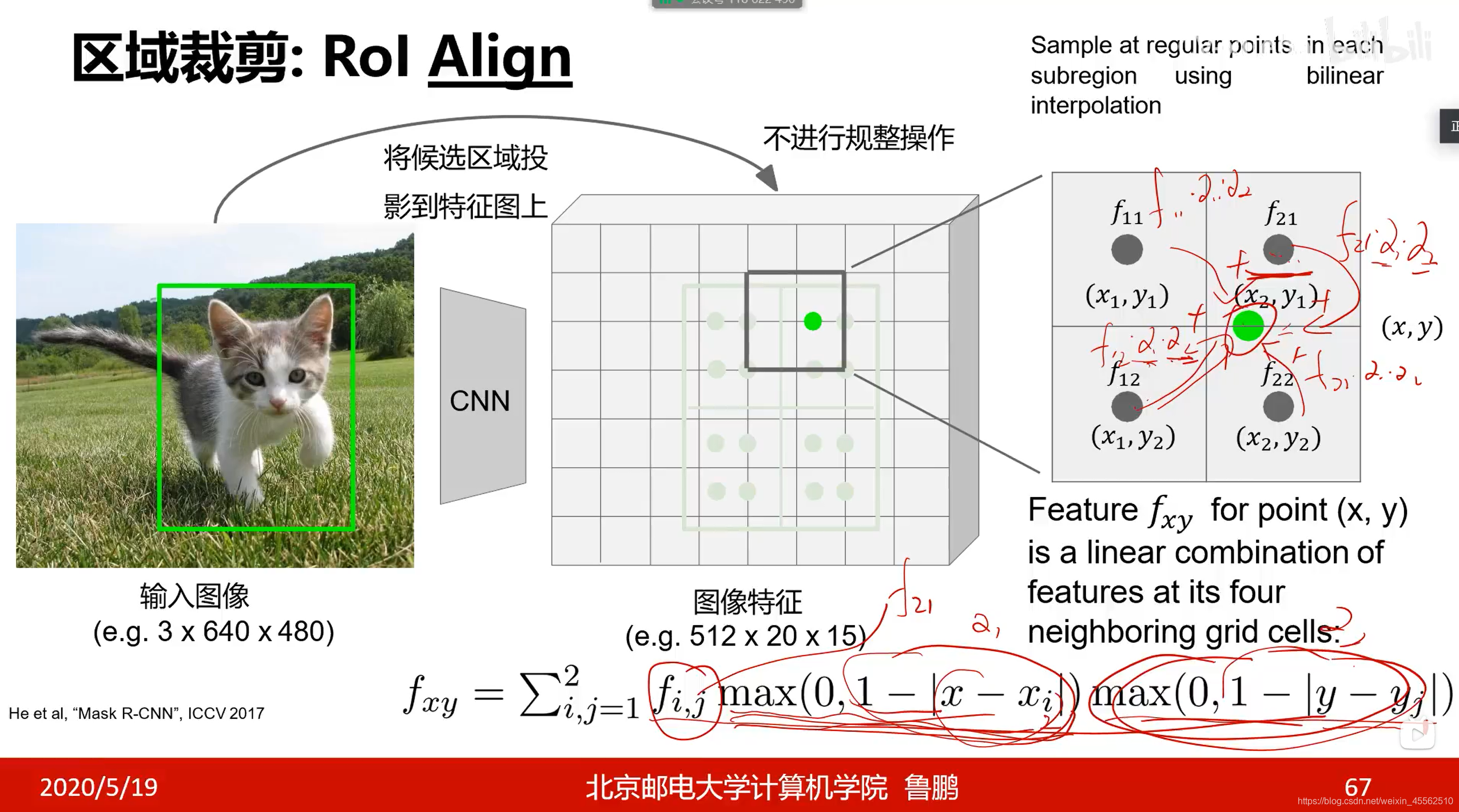
- 7.2(SS有点类似插值法)不进行规整操作,则我们想要的裁剪区域难以用一个区域的特征值代表。因此在裁剪的区域内等间隔取四个点。每一个点又依据它与周边特征值的距离决定特征值的权重取得加权平均。(此步见下图)之后对四个点进行最大池化。
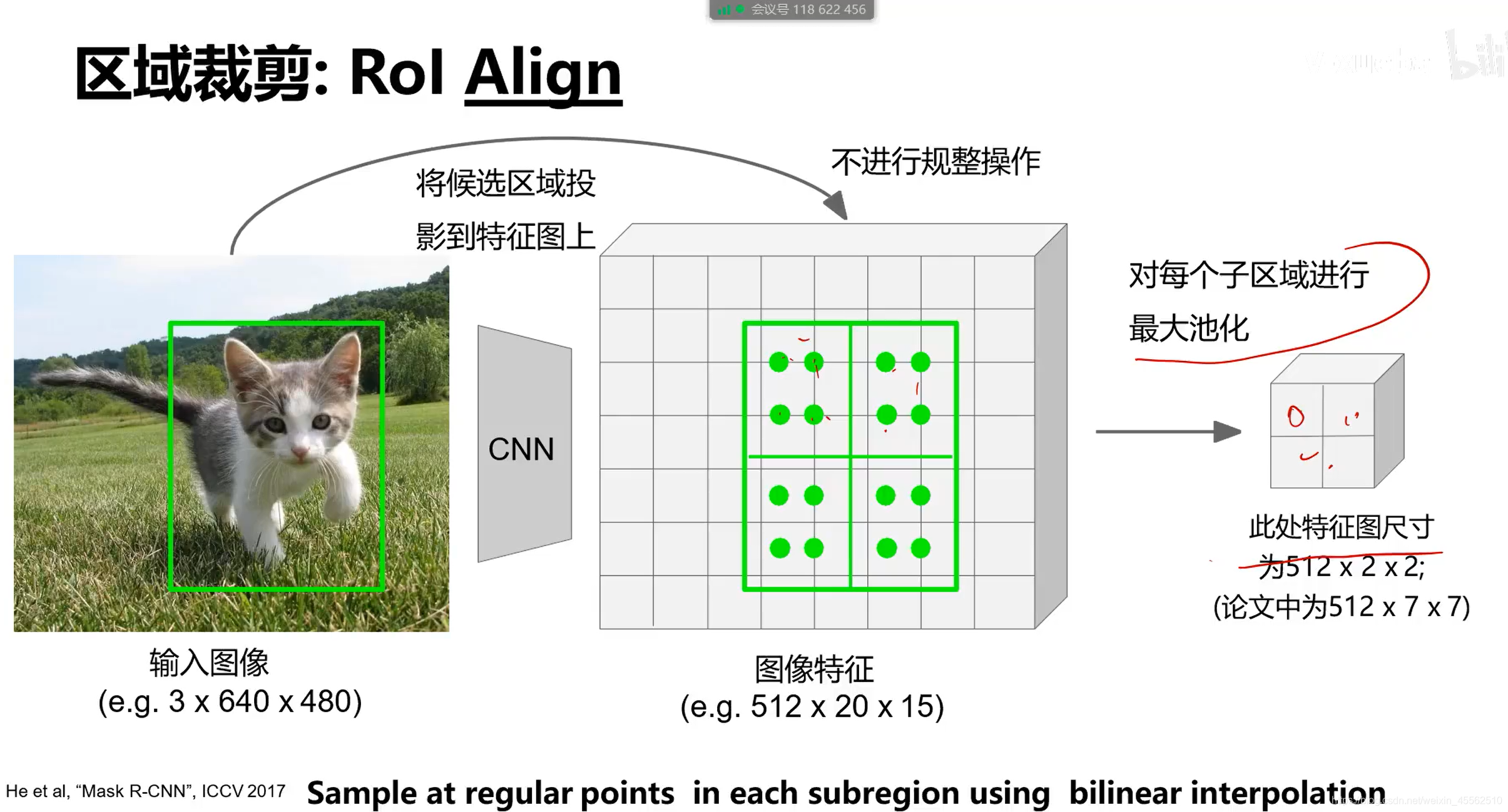
- 7.1步骤如下图
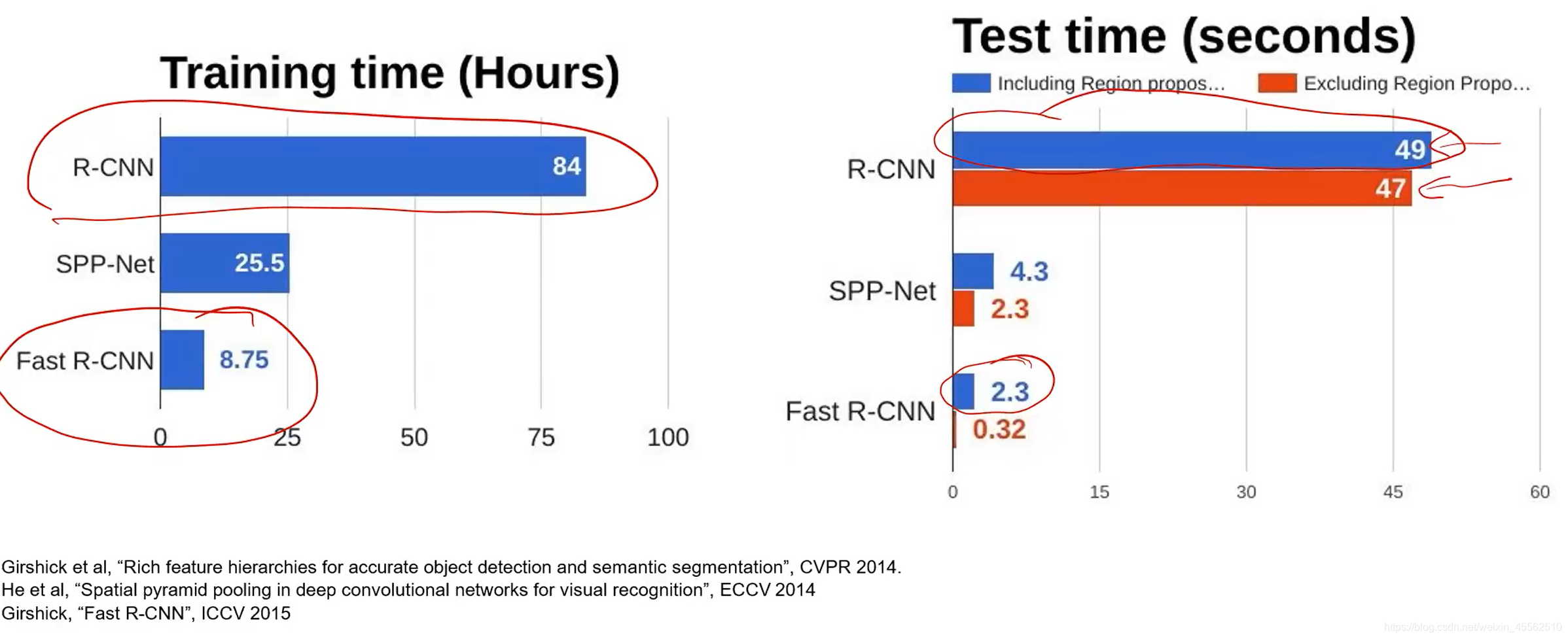
- 8.R-CNN VS Fast R-CNN
- 9、Faster R-CNN(快在make CNN do proposals)
- 9.1在中间特征层后加入区域建议网络RPN(region proposal network)产生候选区域。其他部分与fast R-CNN保持一致。
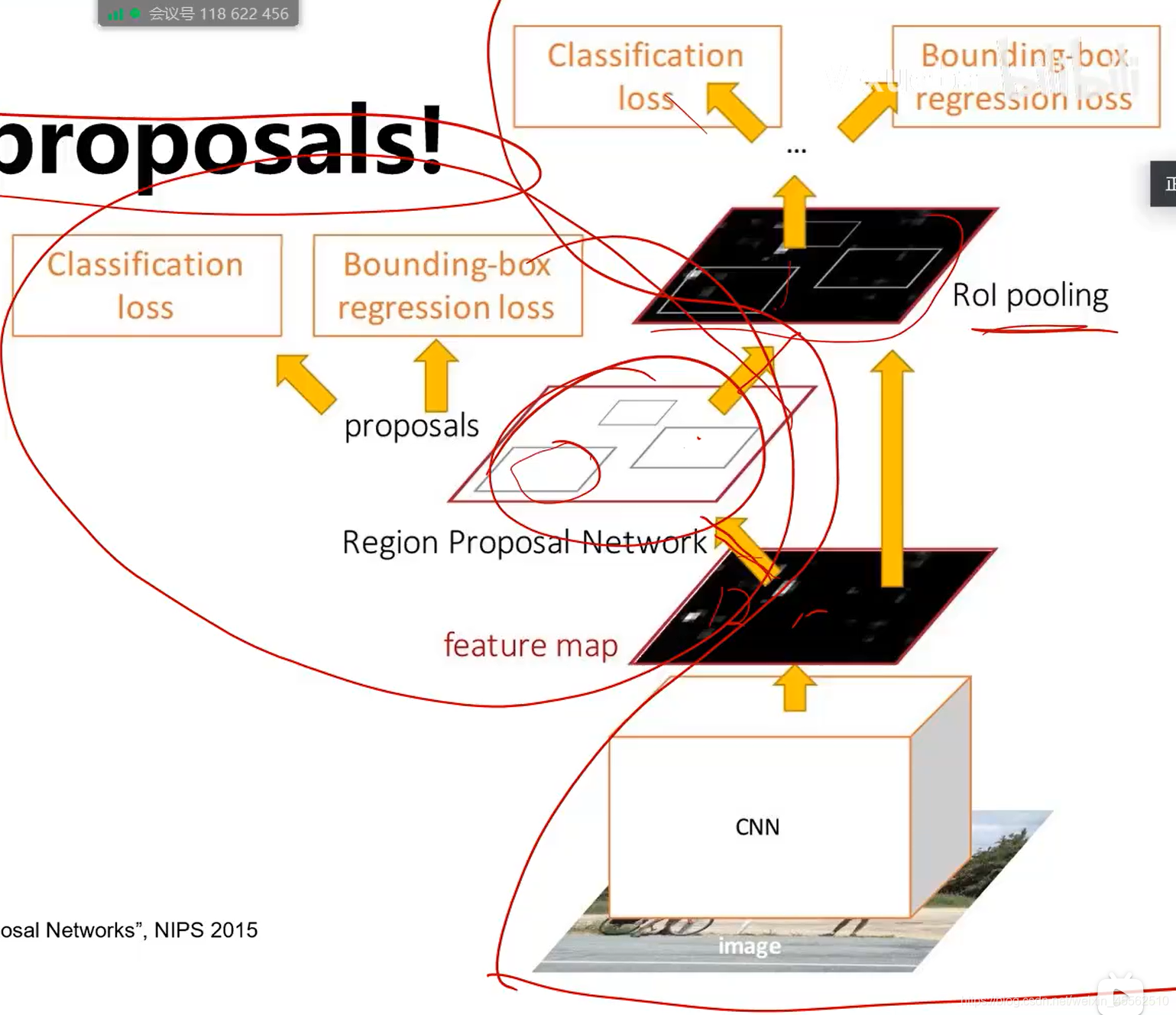
- 9.2 region proposal network(自带一个卷积层和一个FC,有自己的损失函数,自己的反向梯度传递方法)
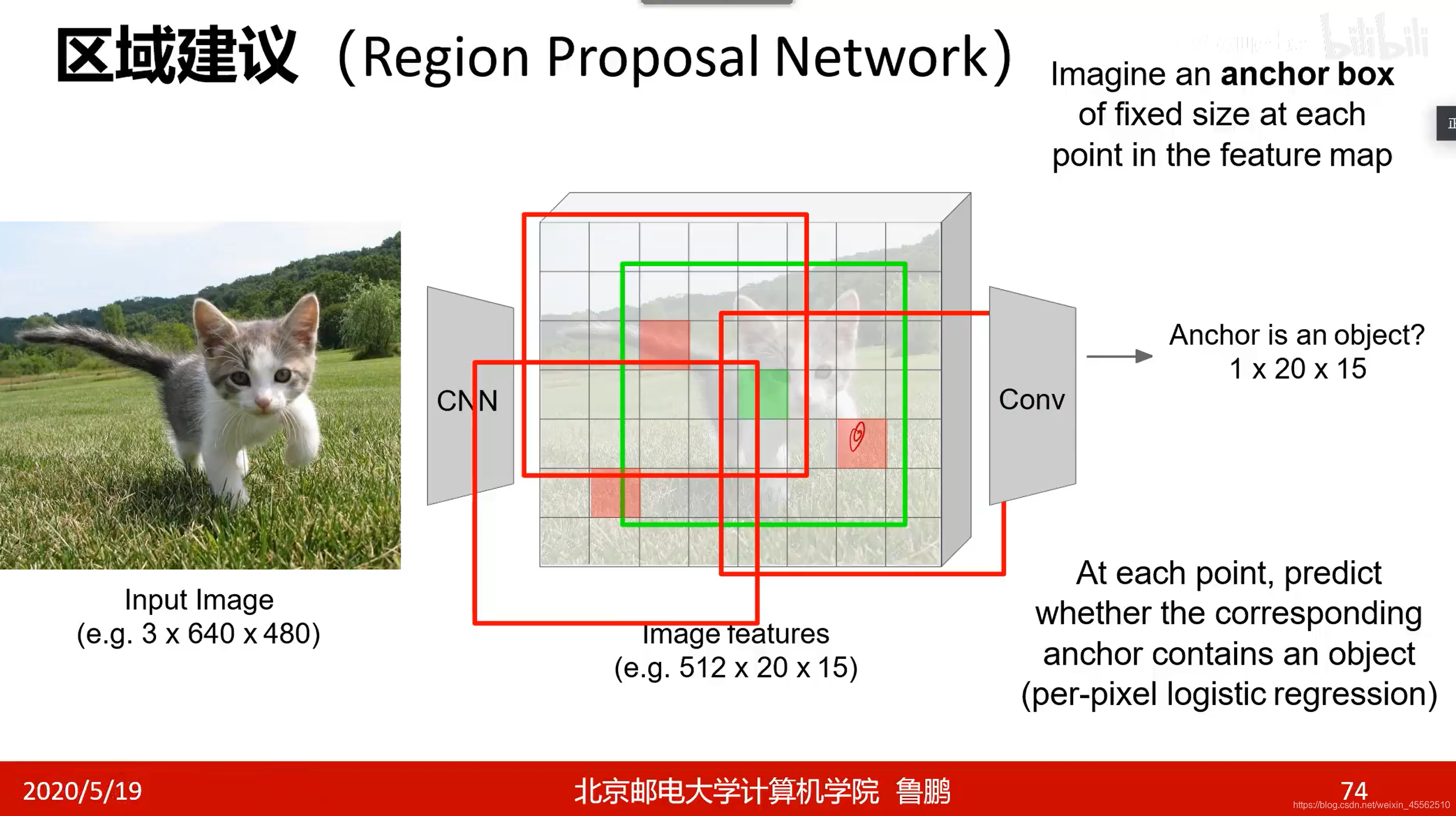
- 9.2.1先寻找anchor(锚)大致锁定以锚为中心的固定区域内有个可识别的物体(锚从图像左上到右下扫一遍,每个锚点实验几个不同的框,就能确定几个可能的位置)(其中1×20×15的意思是,在画幅为20×15的图上的每一个锚点,问一下自己这是不是A物体。注意这里只问了是不是A,所以乘以1,后面问K次是不是特定物体,就是K×20×15。)
- 9.2.2再在锚的基础上,进行框变换,输出精确的框(在画幅20×15的图上的每个点为1次是不是A物体,得到锚的向量的维度是1×20×15。不妨设框有4种变换形式,得到盒子变换向量维度4×20×15。)
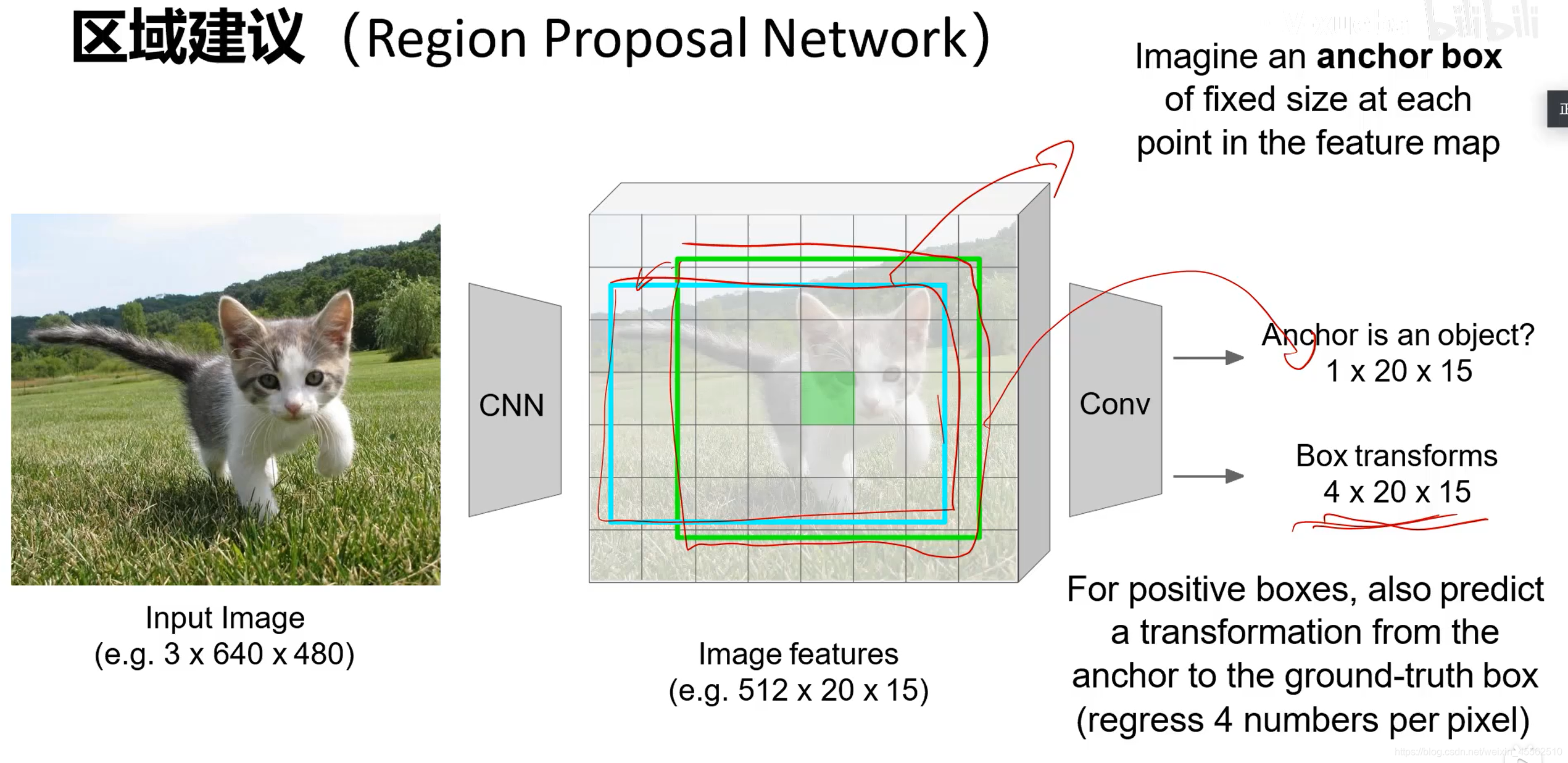
- 9.2.3当我们对每一个区域逐项问是不是A?是不是B?重复K次,则有锚点的维度K×20×15,盒子变换的维度4K×20×15。(这里的描述和PPT中的写法略有不同,这是因为对“锚点区域”这个名词的理解略有不同,不影响背后的工作原理。)(之后送入RPN自己的FC,取得分前300作为建议提交给神经网络。)

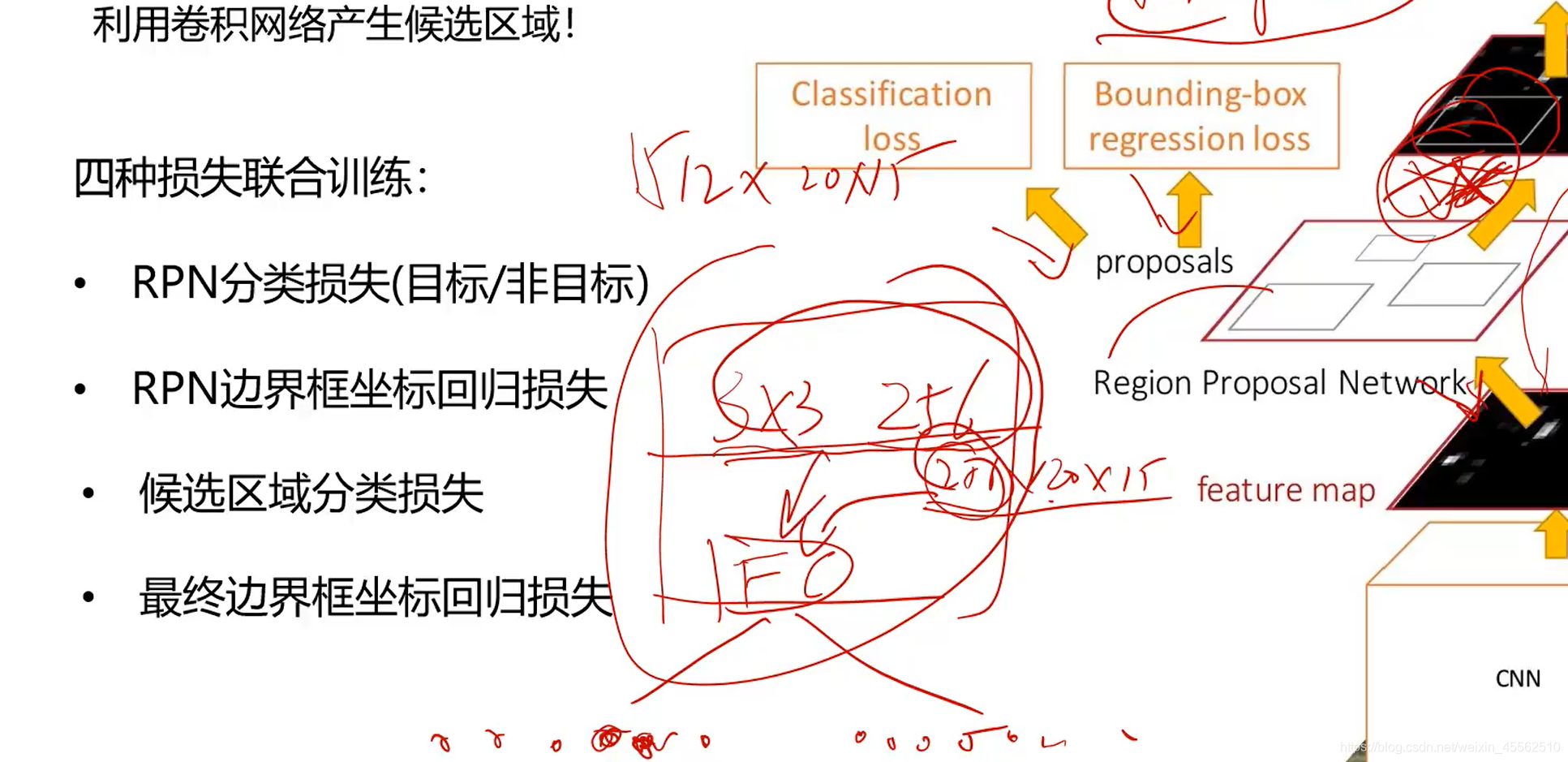
- 9.2.4RPN通过四种损失联合训练:RPN分类损失(目标/非目标)、RPN边框坐标回归损失、候选区域分类损失、最终边界框坐标回归损失。(主干的CNN特征提取和详细的分类网络训练和梯度反向传递与RPN网络无关,两者独立。)
- 9.2.5由此得到Faster R-CNN的运行流程
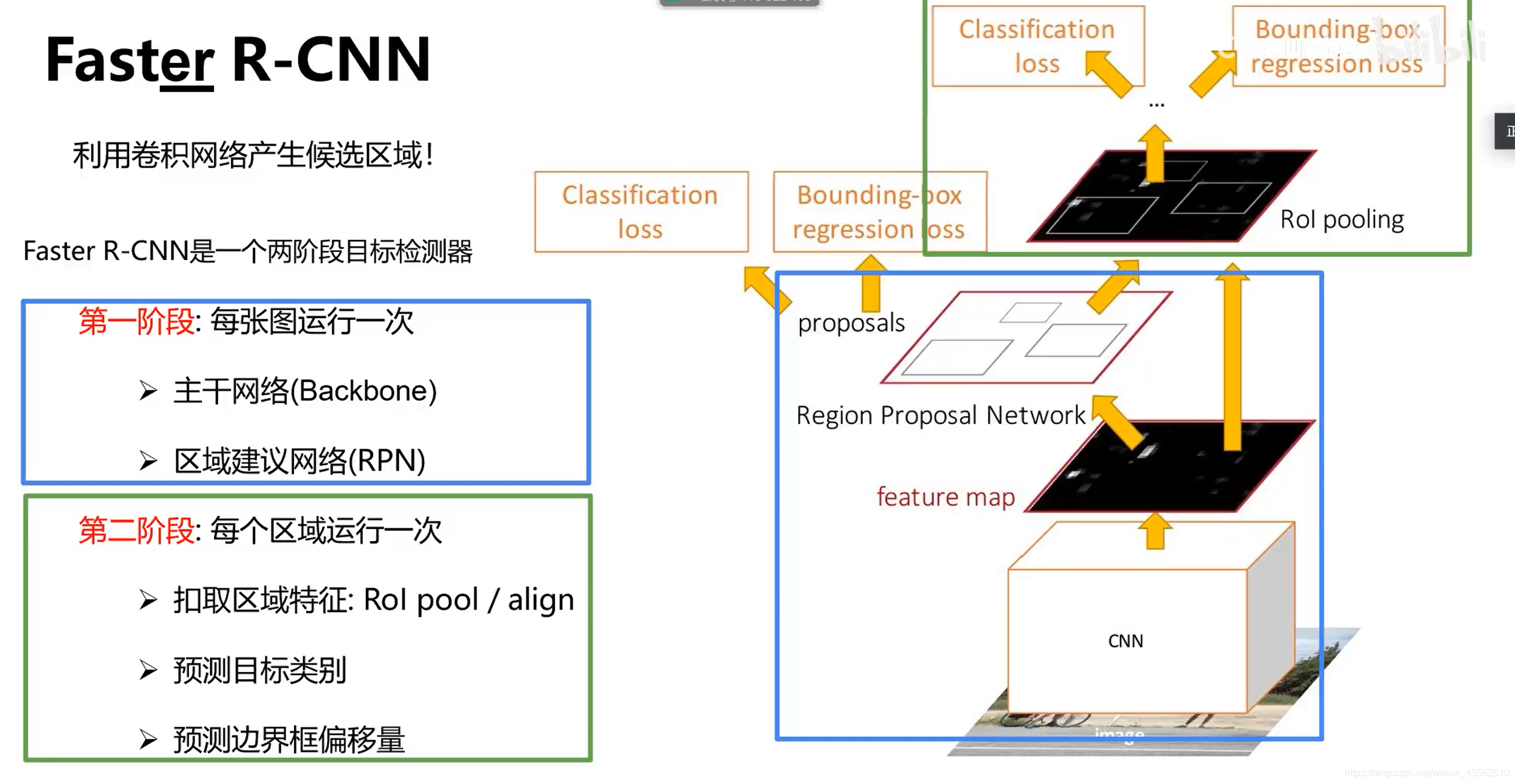
- 9.2.1先寻找anchor(锚)大致锁定以锚为中心的固定区域内有个可识别的物体(锚从图像左上到右下扫一遍,每个锚点实验几个不同的框,就能确定几个可能的位置)(其中1×20×15的意思是,在画幅为20×15的图上的每一个锚点,问一下自己这是不是A物体。注意这里只问了是不是A,所以乘以1,后面问K次是不是特定物体,就是K×20×15。)
(三)多目标检测—R-CNN—YOLO4(常见方法)
- 1.YOLO是独立发展的,但在经过第四代发展之后,可以看作上面刚刚介绍的Faster R-CNN的左半边Region Proposal Network部分的独立应用。
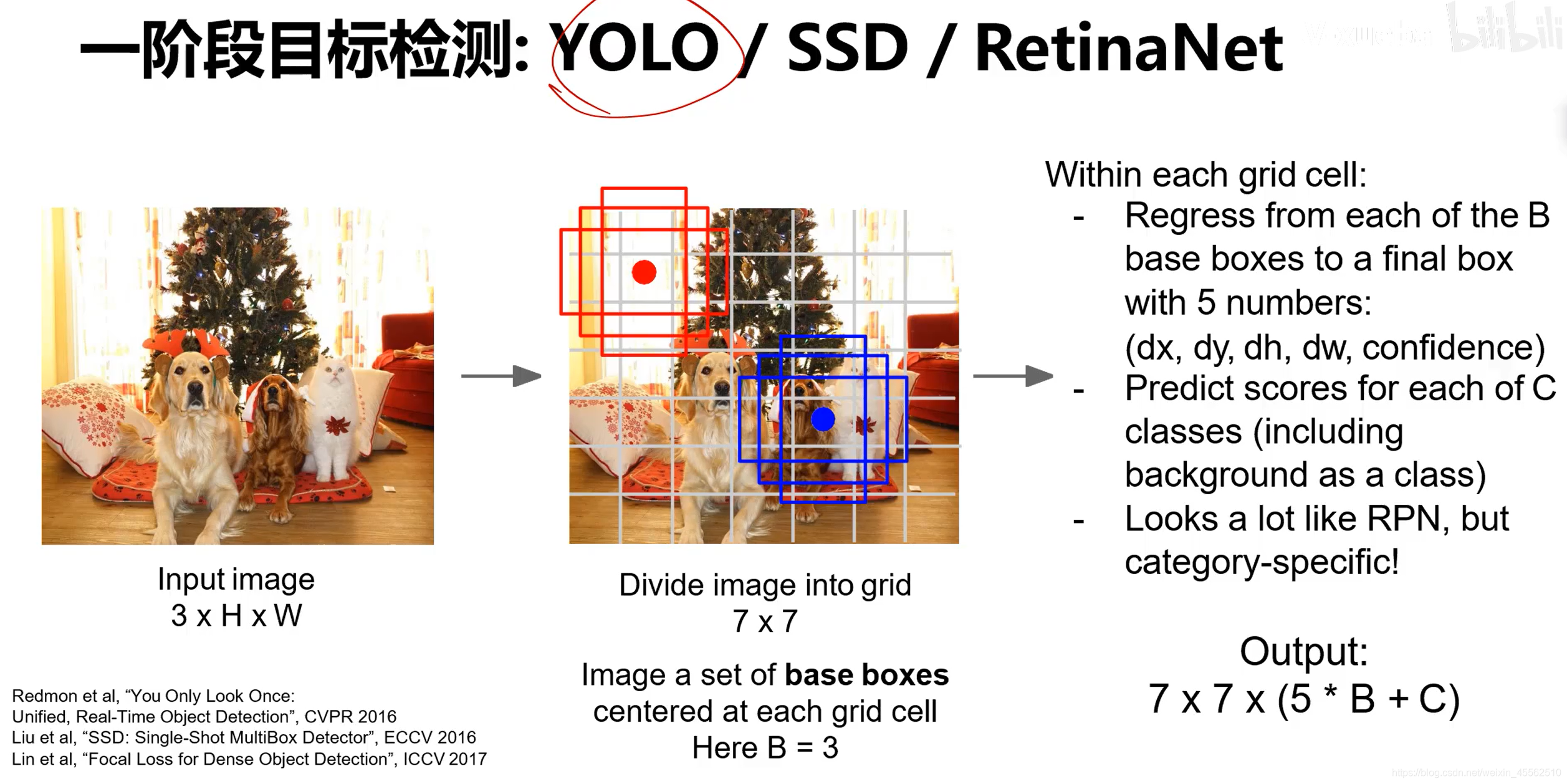
- 2.其流程可以理解为,提取特征—划分为7×7的网格—网格内画B种框(框包含5个参数:x,y,h,w,置信度)—对每一个格子的每一种框进行C种类别的识别—得到结论。(看起来非常向RPN)
(四)目标检测:影响精度的因素

anchor free一种新的目标检测研究小方向
二、实例分隔
- 1.Mask R-CNN:能够实现实例分隔,经过简单的回归还能进行姿态检测。
- 2.几个推荐的开源框架



















 700
700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









