







基础理论准备
开放存储期刊
开放存取期刊是一种免费的网络期刊,旨在使所有用户都可以通过因特网无限制地访问期刊论文全文。此种期刊一般采用作者付费出版、读者免费获得、无限制使用的运作模式,论文版权由作者保留。在论文质量控制方面,oa期刊与传统期刊类似,采用严格的同行评审制度。开放存取期刊不再利用版权限制获取和使用所发布的文献,而是利用版权和其他工具来确保文献可永久公开获取。
CNKI
精确与模糊
除主题只提供相关度匹配外,其他检索项均提供精确、模糊两种匹配方式
篇关摘(篇名和摘要部分)、篇名、摘要、全文、小标参考文献的精确匹配,是指检索词作为一个整体在该检索项进行匹配,王者包含检索词的结果。模糊匹配,则是检索词进行分词后在该检索项的匹配结果。
篇关摘(关键词部分)、关键词、作者、机构、基金、分类号、文献来源、DOI的精确匹配,是指关键词、作者、机构、基金、分类号、文献来源或DOI与检索词完全一致。模糊匹配,是指关键词、作者、机构、基金、分类号、文献来源DOI包含检索词。
布尔逻辑检索
- 不同检索项之间:使用 AND OR NOT
- 同一个检索项:使用运算符 * + -
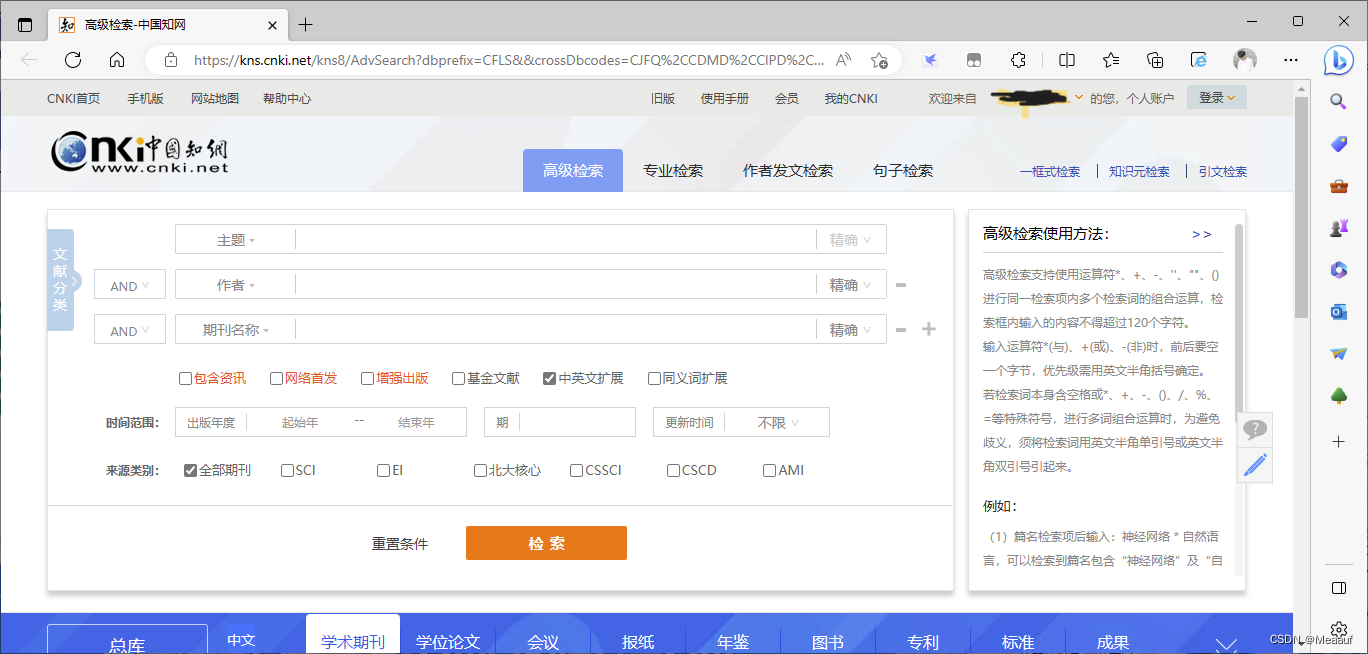
高级搜索支持使用运算符【 * + - ‘’ “” ()】,运算符*表示与 运算符+表示或 运算符- 表示非,前后留空一个字节,优先级需要使用()进行确定
// 匹配篇名包含“神经网络”及“自然语言”的文献
篇名: 神经网络 * 自然语言
// 主题为“锻造”或“自由锻”,且有关“裂纹”的文献
主题: (锻造 + 自由锻) * 裂纹
// 检索篇名包含“digital library”和“information service”的文献
篇名:digital library * information service
// 检索篇名包含“2+3”和“人才培养”的文献
篇名: '2+3' * 人才培养
精确匹配和模糊匹配的区别:
精确搜索就是指输入的检索词在检索结果字序、字间间隔完全一样,而模糊搜索就是输入的检索词再检索结果中出现即可,字序、自间间隔可以产生变换。在CNKI的数据库中,精确匹配是按照词语检索,而模糊匹配是按单字检索。
作者单位: 学院 + 大学 [模糊] // 在检索中,作者单位一栏必须出现学院或大学
其它布尔逻辑检索关系
没有明确的连接关系,不一定都是AND;不同检索项中,没用明确布尔逻辑连接符,一般是“并且”关系;同一检索项内,如果存在多选,一般是“或者”关系

专业搜索
- AU:作者
- AF:机构
- TI:标题
// 搜索清华大学钱伟长在清华大学和上海大学时发表的文章
AU=钱伟长 AND (AF=清华大学 OR AF=上海大学)
搜索引擎高级搜索语法
site语法的使用
在搜索中避免带 http:// 或 在结尾带 /
特定的域名类型( cn、uk、gov、edu.cn等)
投标 site:cn // 表示仅在域名中以 cn 结尾的网站中搜索有关投标的信息
指定的网站 | 指定网站的频道
二十大 site:www.xuexi.cn/ // 在整个学习强国中搜索关于二十大的信息
site:xxx.xxx.xxx.cn // 限制在具体频道中[不添加www]
搜索查询词出现在url正文中
xx inurl:xxx.xxx.cn // 返回网址中包含xx的页面
限定查询词在网页标题出现的网址
身高 年龄 体重 intitle:小明 // 可以查询小明个人资料
关键词与或
xx and yy site:www.baiud.com // 查找www.baidu.com中包含xx和yy有关的网站
xx or yy site:www.baiud.com // 查找www.baidu.com中包含xx和yy有关的网站
标准
国家标准
国家标准的代号是由大写汉字拼音字母构成
- GB/T 推荐性国家标准(GB/)
- GB 强制性国家标准
强制性国家标准(GB)

推荐性国家标准(GB/T)
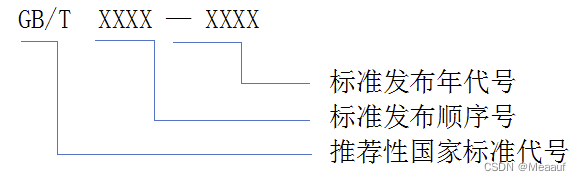
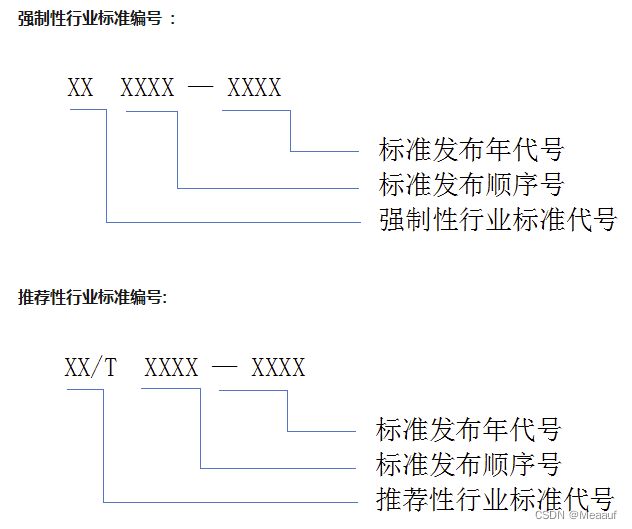
行业标准
行业标准代号由汉字拼音大写字母组成
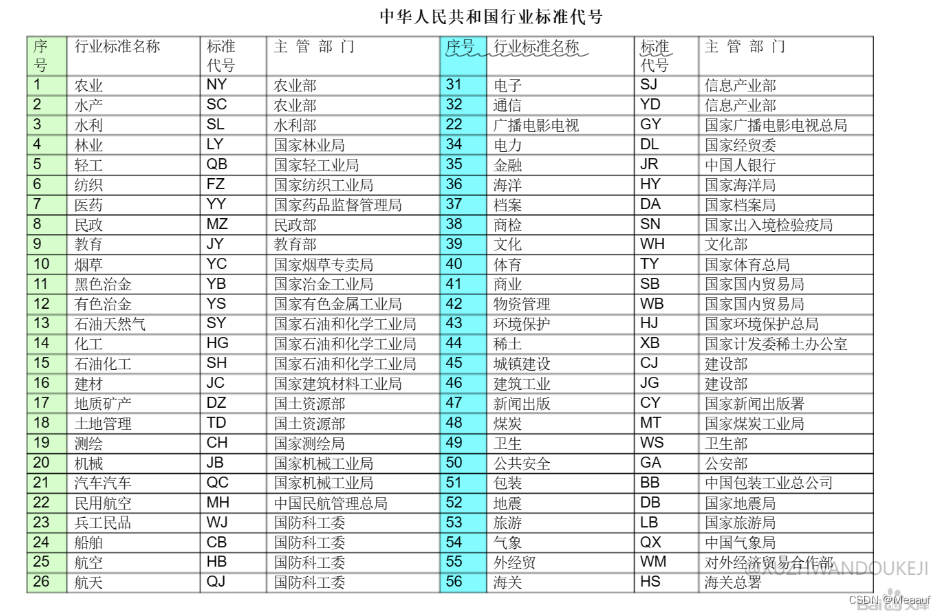
中国行业标准代号
Linggle(语料搜索引擎)
linggle是一个语料搜索引擎,是大数据的典型应用,英文协作拿不准词语搭配可以使用它。linggle可以通过精确的统计数据告诉我们合适的英文词语搭配,有些搭配linggle会给出我们具体的搭配。
查找语句后搭配词
// 查找 make friend后面一般接什么词
make friend _ [ _表示匹配一个单词 ]
make friend _ _ [ _ _表示匹配两个单词]
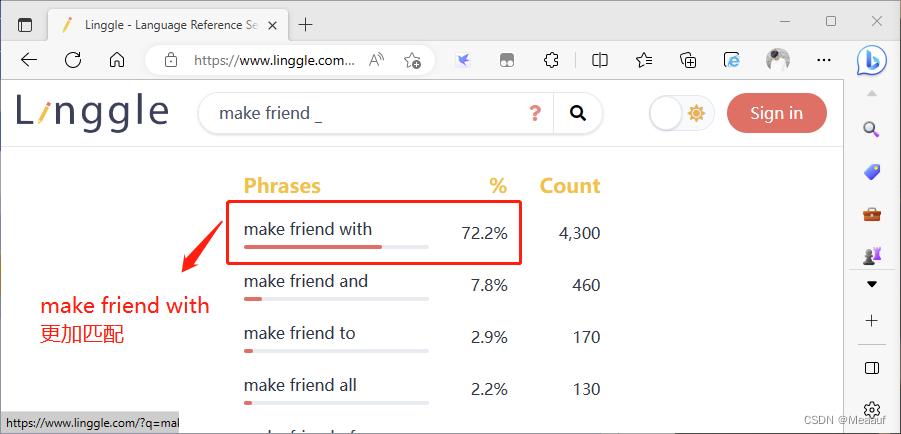
判断词语搭配更合理一项
// 判断 in the room 和 at the room 那一种更合适
in/at the room
单词前面的动词/名词可以是那种
| 词性 | 缩写 |
|---|---|
| 名词 | n |
| 动词 | v |
| 形容词 | adj |
| 副词 | adv |
| 介词 | prep |
| 代词 | pron |
| 连接词 | conj |
| 数词 | num |
| 感叹词 | int |
| 冠词 | art |
| 感叹词 | interj |
| 主词 | s |
| 不及物动词 | vi |
| 及物动词 | vt |
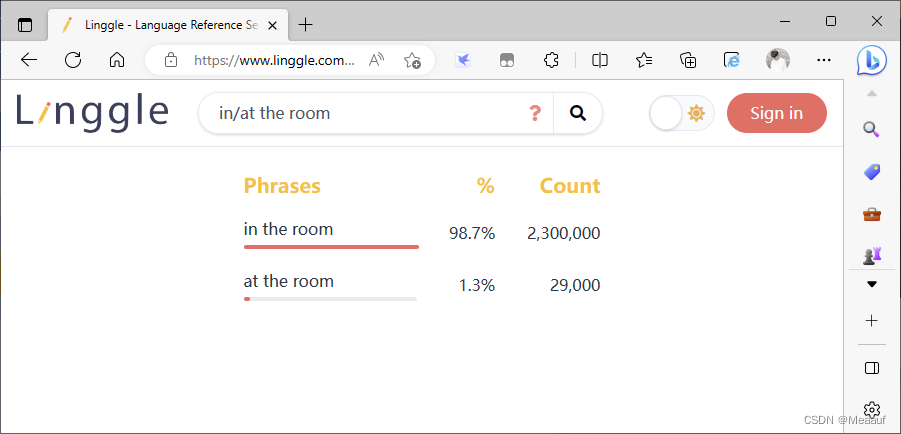
// difficulty前面的动词可以是那些【需要加.】
v. difficulty
// love后面的名词可以是那些
love n.
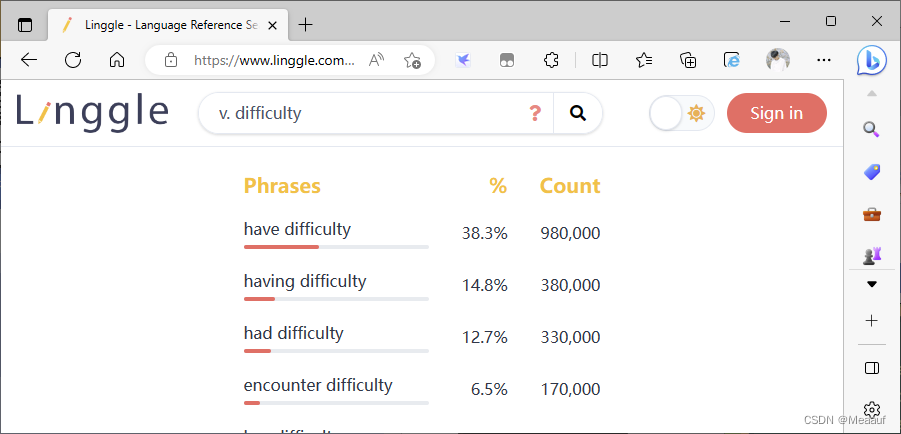
判断单词之间是否需要某单词
// 判断go to home 还是 go home
go ?to home
中图分类号
中图分类号是一本书在中国图书馆分类法体系下的分类号

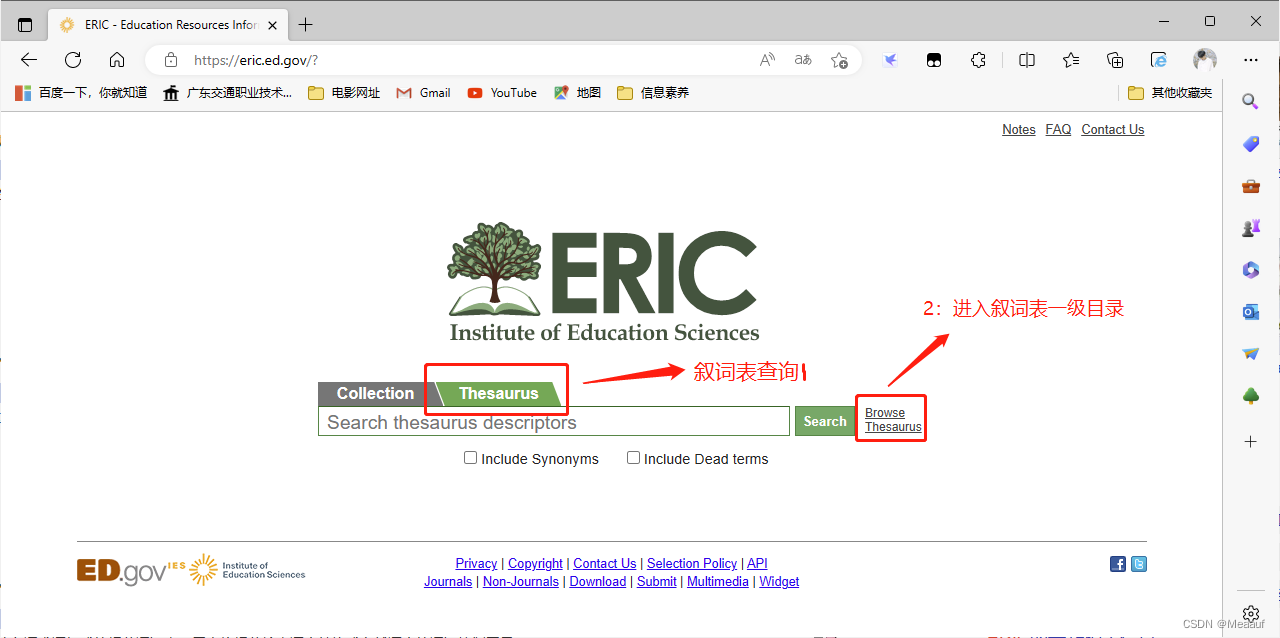
叙词表
- 叙词表也称为主题词表,是一个规范化的词汇表
- 叙词表的作用是规范检索语言,提升检索效率
- 在ERIC的官网上,我们可以通过叙词表查找文献,其中很多是可以下载全文的
- 是概括某一学科或若干学科领域的名次术语组成的规范词汇表,用来将自然语言转换为规范检索语言的词汇控制工具
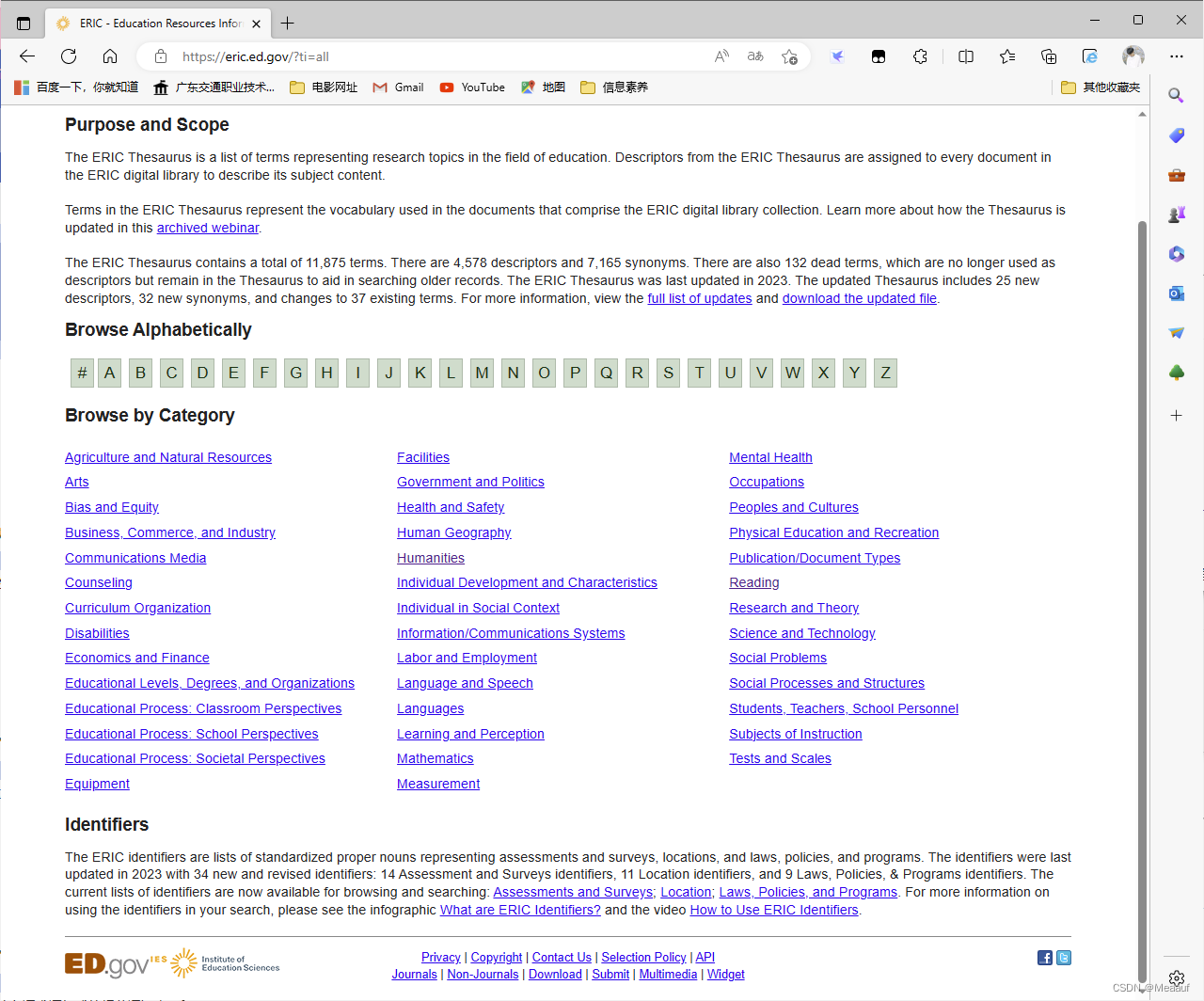
主题词/主题词表
- 主题词:经过规范化处理的词,又称叙词或者受控词,与之对应的是自由词
- 按照一定的逻辑把主题词组织起来,就形成了主题词表
- 主题词可以规范文献的标引和检索,提升文献检索的效率和质量
- 使用主题词,大多数情况下,可以兼顾查准率和查全率
- 与用“题名”
Word相关操作
“查找内容”和“替换为”
| 特殊字符 | 功能 | 备注 |
|---|---|---|
| ^p | 段落标记 | 选中“使用农通配符”复选框时在”查找内容“框中无效 |
| ^t | 制表符 | |
| ^0nnn | ANSI或ASCII字符 | 其中nnn为字符码 |
| ^+ | 长划线 | |
| ^= | 短划线 | |
| ^^ | 符号 | |
| ^l | 人工换行符 | |
| ^n | 分栏符 | |
| ^m | 人工分页符 | 选中”使用通配符“复选框时将查找和替换分节符 |
| ^s | 不间断空格 | |
| ^~ | 不间断连字符 | |
| ^- | 可选连字符 | |
| ^a | 批注标记 | |
| ^g | 图形 | |
| ^? | 任意字符 | |
| ^# | 任意数字 | |
| ^$ | 任意字母 | |
| ^f | 脚注标记 | |
| ^d | 域 | |
| ^b | 分节符 | |
| ^w | 空白区域 | |
| ^c | “Windows剪贴板”的内容 | 只能在“替换为”框中使用的代码 |
| ^& | “查找内容”框的内容 | 只能在“替换为”框中使用的代码 |
CC协议
CC0协议:随便用、随便改、无须署名
CC4.0协议(creative commons),知识共享许可协议
-
署名(by):在共享的过程中,必须保留原作品的署名

-
非商业性使用(nc):仅限于非商业性目的的使用

-
禁止演绎(nd):允许别人对自己的作品原封不动的共享,不能在此基础上进行二次演绎

-
相同方式共享(sa):针对演绎作品,演绎后的作品,也必须共享,而且共享的许可协议必须和你的一样

六种主要许可协议(严格度由上至下递减):
- 署名-非商业性使用-禁止演绎 by-nc-nd
- 署名-非商业性使用-相同方式共享 by-nc-sa
- 署名-非商业性使用 by-nc
- 署名-禁止演绎 by-nd
- 署名-相同方式共享 by-sa
- 署名 by
专利检索
检索步步骤:
- 明确检索主题,确定关键词以及同义词
- 明确基本要素的表达,确定检索表达式
- 选取合适的专利检索平台,输入检索表达式,获取目标专利
国家知识产权局官网–专利检索页
中文社科核心期刊
| 机构 | 索引名称 | 简称 |
|---|---|---|
| 南京大学 | 《中文社会科学引立索引》 | CSSCI |
| 中国社会科学院 | 《中国人文社会科学核心期刊要览》 | A刊 |
| 北京大学 | 《中文核心期刊要目总览》 | 北大核心 |
相关例题
南京大学信息管理学院2000年以来发表了多少篇北大核心论文
初步检索
可以发现共有 2790条结果
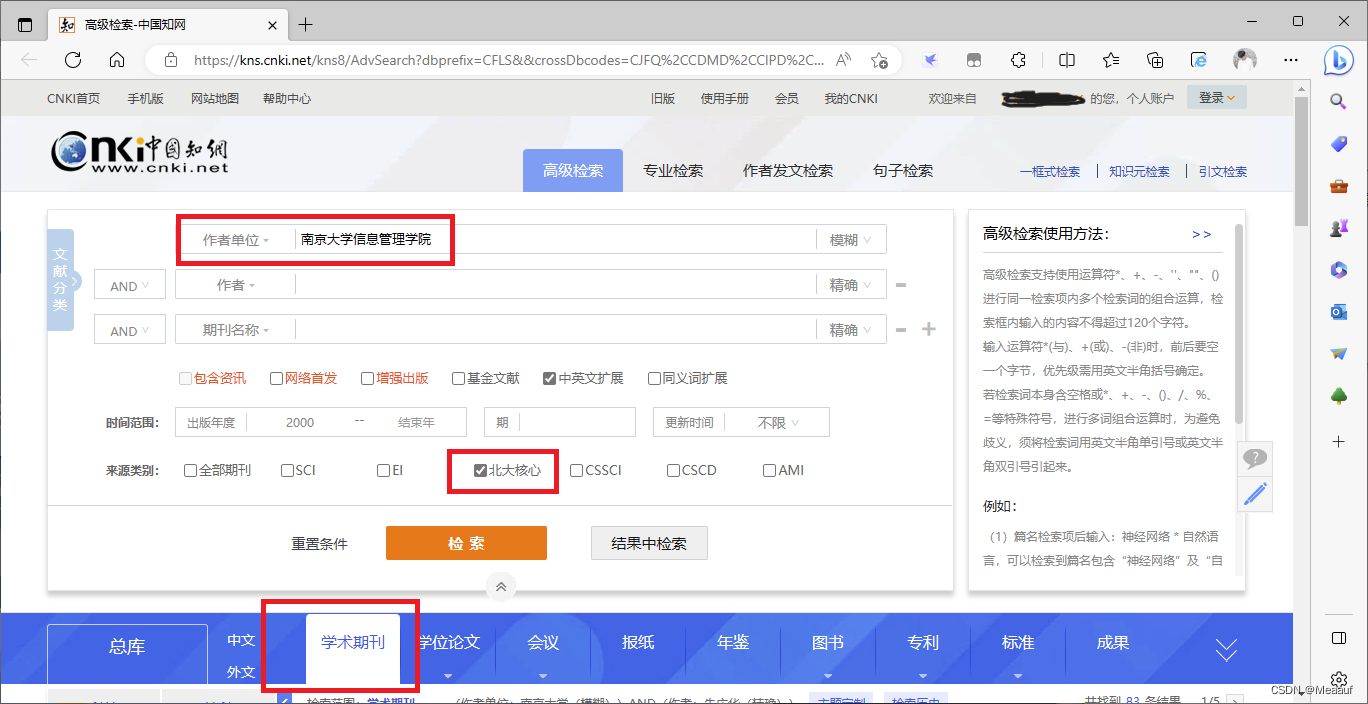
分析结果正确性
-
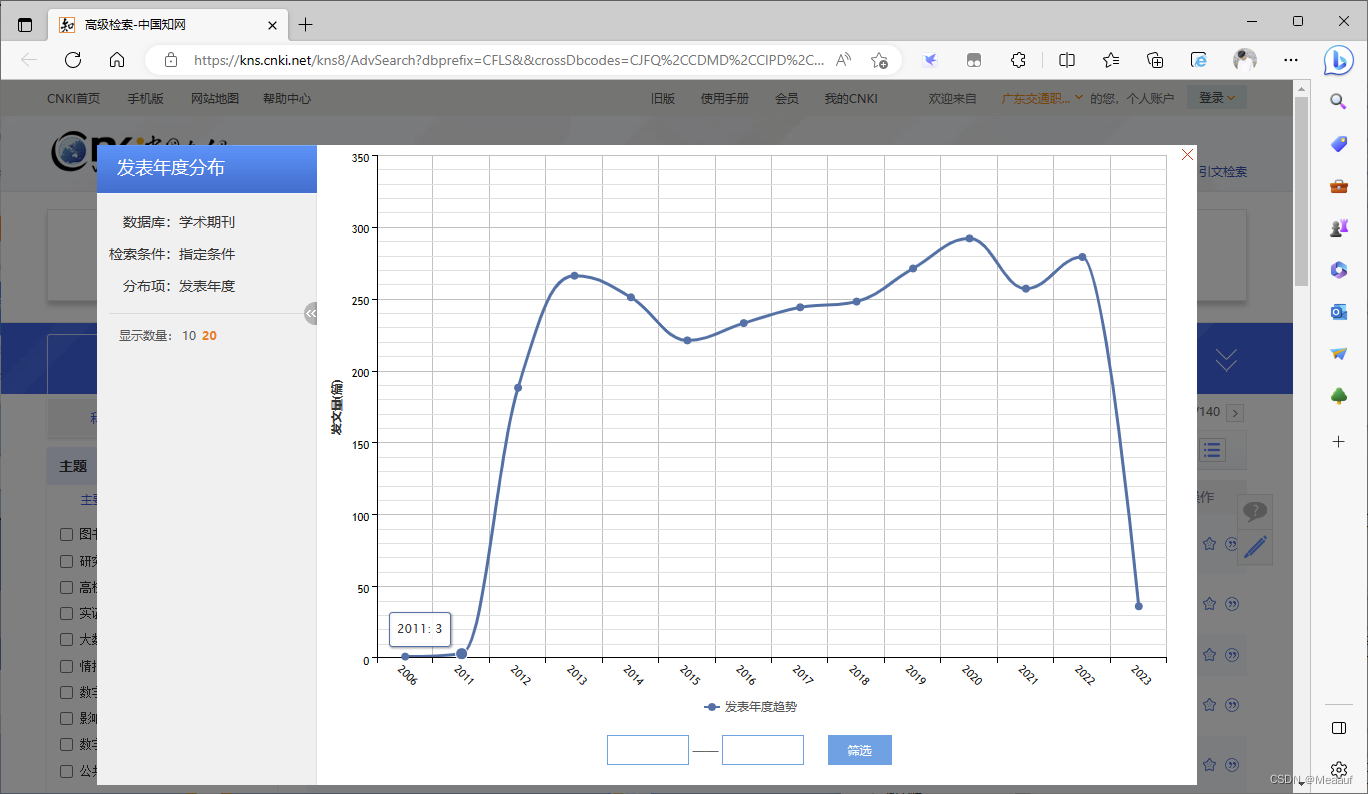
查看发表年度趋势图
-
可以看到在2011年前的发文数基本为0
-
验证结果,查看该校高产作者在2011前的文章中的单位署名
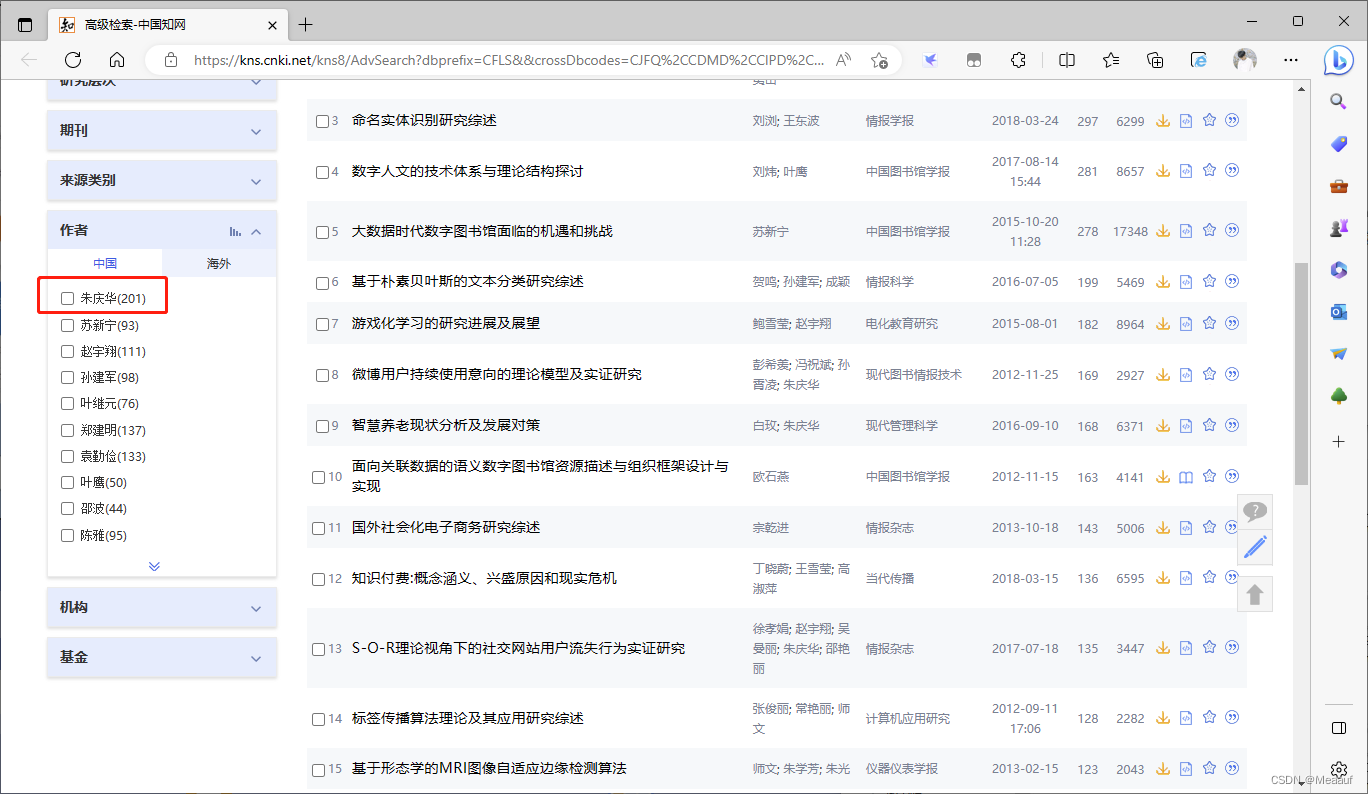
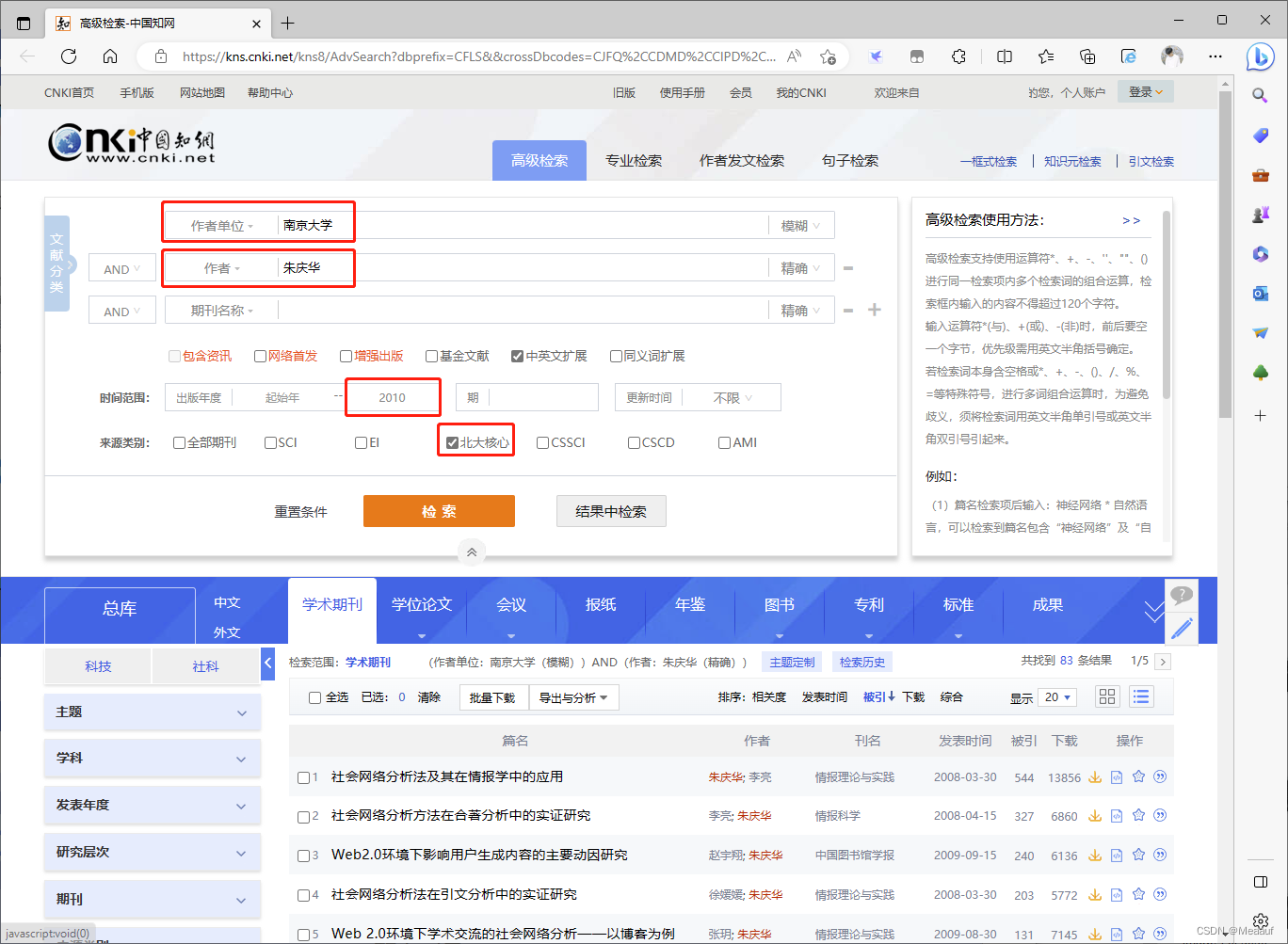
单击第一篇论文,可以看到单位署名为“南京大学信息管理系”
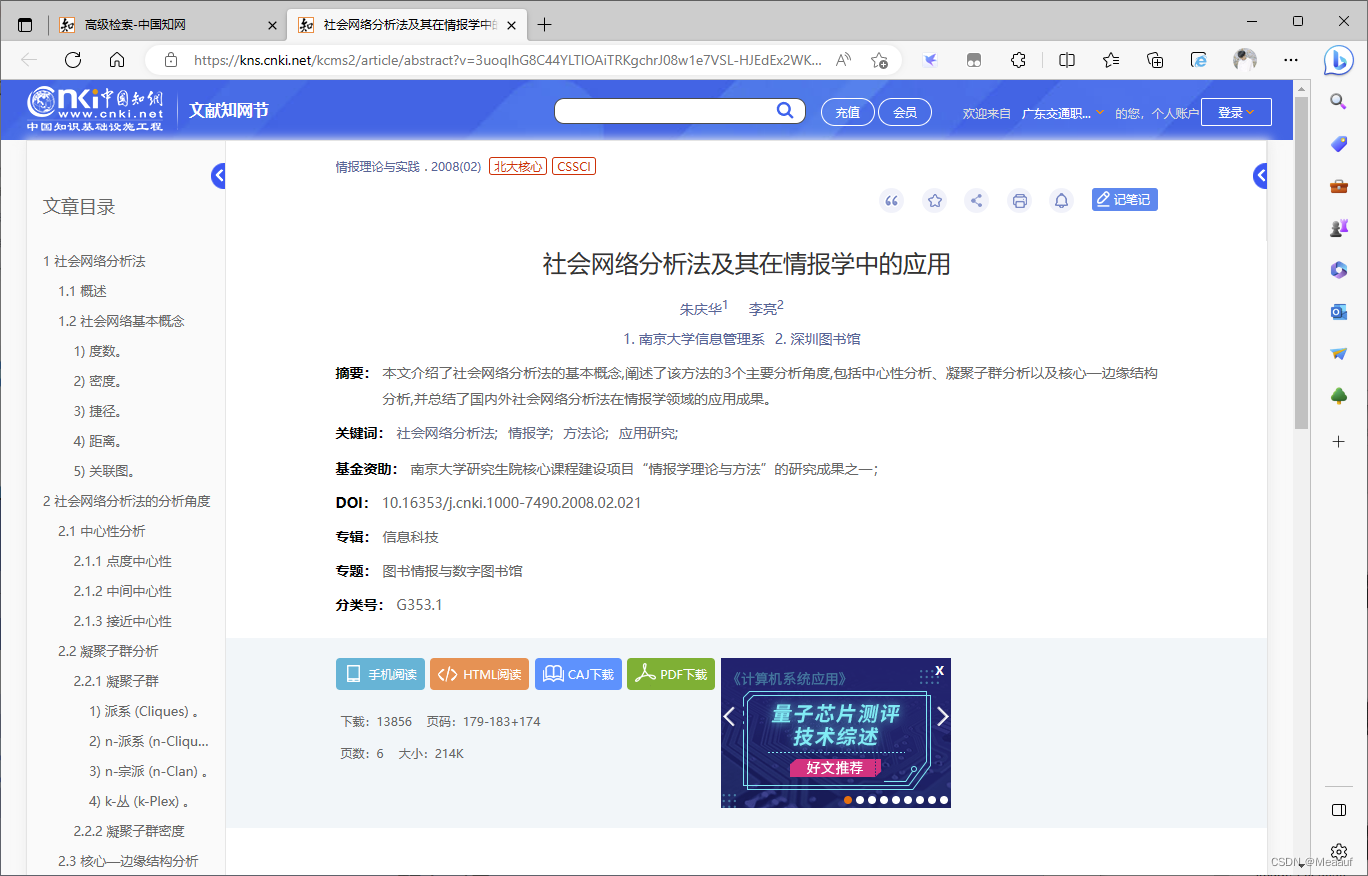
-
重新检索
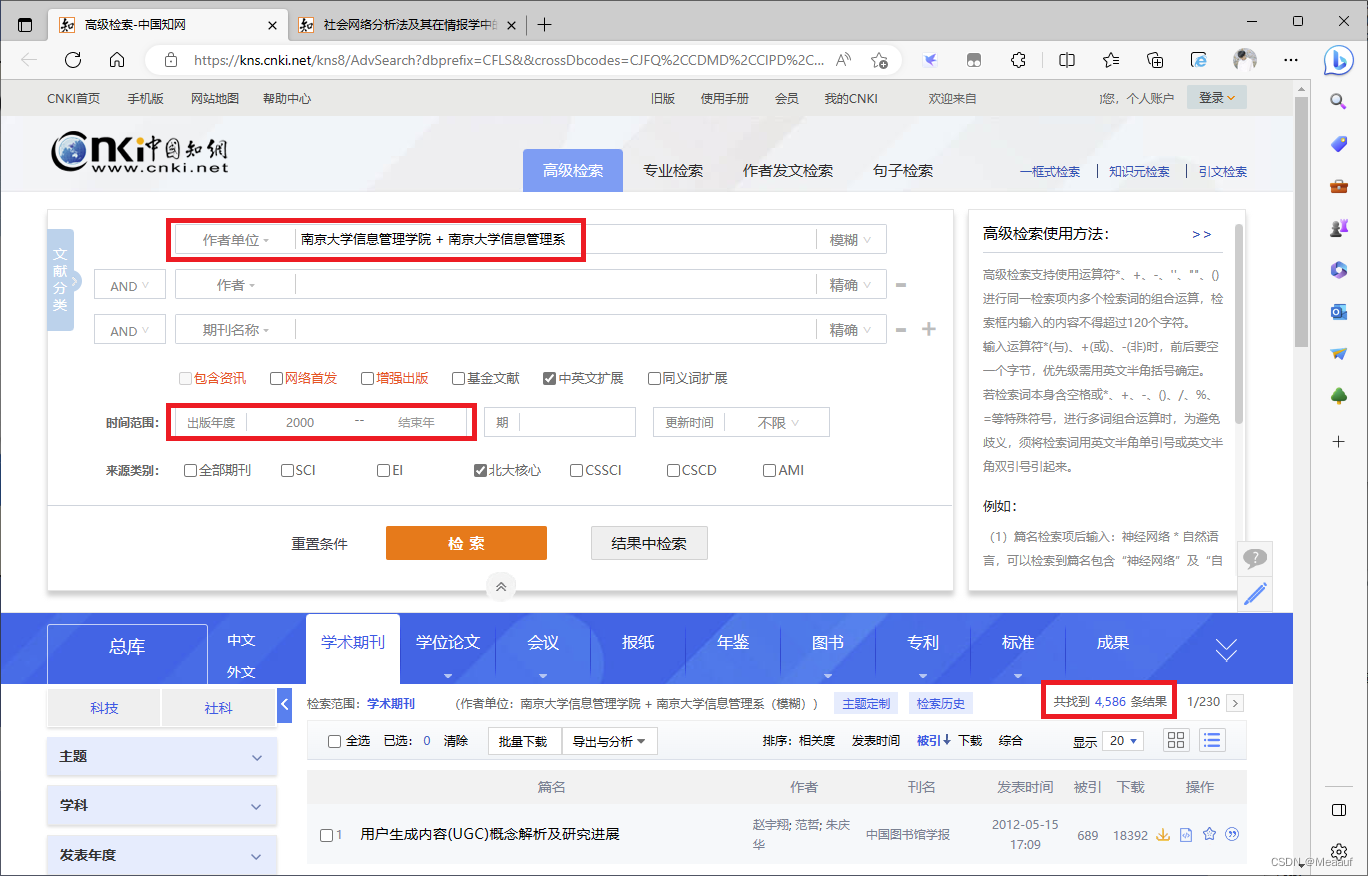



















 4527
4527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











