









由于sklearn模块中集成了很多机器学习算法,像比较常见的svm、ranforest、xgboost等机器学习算法都有,这里我们直接调用就行!!
废话不多说,直接上整体源码:
import numpy as np
from sklearn import svm
from sklearn.ensemble import RandomForestClassifier
import argparse
import scipy.io
parser = argparse.ArgumentParser()
parser.add_argument("-m", "--model", help="the model for classify, svm|rf|xb", type = str, default= "xb")
args = parser.parse_args()
model = args.model
import matplotlib.pyplot as plt
plt.rc("font", family='KaiTi')
def divide_dataset(X1, Y1, X2, Y2):
shuffle_list1 = [i for i in range(0, len(X1))]
np.random.shuffle(shuffle_list1)
X_train = [ X1[shuffle_list1[i]] for i in range(len(shuffle_list1))]
Y_train = [ Y1[shuffle_list1[i]] for i in range(len(shuffle_list1))]
shuffle_list2 = [i for i in range(0, len(X2))]
np.random.shuffle(shuffle_list2)
X_test = [ X2[shuffle_list2[k]] for k in range(len(shuffle_list2))]
Y_test = [ Y2[shuffle_list2[k]] for k in range(len(shuffle_list2))]
return X_train, Y_train, X_test, Y_test
def SVM_MODEL(X_train, Y_train, X_test, Y_test):
accuracy = []
clf = svm.SVC(C=100, gamma=0.05, max_iter=-1,random_state=8)
clf.fit(X_train, Y_train)
Y_pred = clf.predict(X_test)
precision_test = sum(Y_pred == Y_test)/len(Y_test)
print('svm test best precision: ', round(np.max(precision_test), 2))
return round(np.max(precision_test), 2)
# print(shuffle_list)
def RF_MODEL(X_train,Y_train,X_test,Y_test):
# clf = RandomForestClassifier(n_estimators=500, max_depth=32,random_state=8)
clf = RandomForestClassifier(n_estimators=1000,max_features=6,max_depth=25,
oob_score=True,random_state=10)
clf.fit(X_train, Y_train)
Y_pred = clf.predict(X_test)
precision_test = sum(Y_pred == Y_test)/len(Y_test)
print('randforest test precision: ', round(np.max(precision_test), 2))
return round(np.max(precision_test), 2)
if __name__ == '__main__':
mode = input('请输入数据集名称:')
if mode == "AD":
data = scipy.io.loadmat('AD.mat')
X1 = data['xtrain']
Y1 = data['ytrain']
X2 = data['xtest']
Y2 = data['ytest']
X_train, Y_train, X_test, Y_test = divide_dataset(X1, Y1, X2, Y2)
print('start svm training...')
svm_accuracy = SVM_MODEL(X_train,Y_train,X_test,Y_test)
print('start ranforest training...')
rf_accuracy = RF_MODEL(X_train,Y_train,X_test,Y_test)
# plt.axis('off')
# rowLabels = ['svm:', '随机森林:'] # 表格行名
# col_labels = ['最高准确率']
# cellText = [['{:.2f}%'.format(svm_accuracy)], ['{:.2f}%'.format(rf_accuracy)]] # 表格每一行数据
# table = plt.table(cellText=cellText, rowLabels=rowLabels, loc='center', cellLoc='center', rowLoc='center')
# table.auto_set_font_size(False)
# table.set_fontsize(10) # 字体大小
# table.scale(1, 1.5) # 表格缩放
row_labels = ['svm:', '随机森林:']
col_labels = ['最高准确率']
table_vals = [['{}%'.format(svm_accuracy*100)], ['{}%'.format(rf_accuracy*100)]] #
# row_colors = ['gold']
my_table = plt.table(cellText=table_vals, colWidths=[0.3]*3,
rowLabels=row_labels, colLabels=col_labels, loc='center', cellLoc='center', rowLoc='center')
my_table.auto_set_font_size(False)
plt.title('AD')
my_table.set_fontsize(10) # 字体大小
my_table.scale(2, 3) # 表格缩放
plt.savefig("AD" + ".png")
plt.show()
elif mode == "heart":
data = scipy.io.loadmat('heart.mat')
X1 = data['xtrain']
Y1 = data['ytrain']
X2 = data['xtest']
Y2 = data['ytest']
X_train, Y_train, X_test, Y_test = divide_dataset(X1, Y1, X2, Y2)
print('start svm training...')
svm_accuracy = SVM_MODEL(X_train,Y_train,X_test,Y_test)
print('start ranforest training...')
rf_accuracy = RF_MODEL(X_train,Y_train,X_test,Y_test)
row_labels = ['svm:', '随机森林:']
col_labels = ['最高准确率']
table_vals = [['{:.2f}%'.format(svm_accuracy*100)], ['{:.2f}%'.format(rf_accuracy*100)]] #
# row_colors = ['gold']
my_table = plt.table(cellText=table_vals, colWidths=[0.3]*3,
rowLabels=row_labels, colLabels=col_labels, loc='center', cellLoc='center', rowLoc='center')
my_table.auto_set_font_size(False)
plt.title('heart')
my_table.set_fontsize(10) # 字体大小
my_table.scale(2, 3) # 表格缩放
plt.savefig("heart" + ".png")
plt.show()
elif mode == "maxLittle":
data = scipy.io.loadmat('maxLittle.mat')
X1 = data['xtrain']
Y1 = data['ytrain']
X2 = data['xtest']
Y2 = data['ytest']
X_train, Y_train, X_test, Y_test = divide_dataset(X1, Y1, X2, Y2)
print('start svm training...')
svm_accuracy = SVM_MODEL(X_train,Y_train,X_test,Y_test)
print('start ranforest training...')
rf_accuracy = RF_MODEL(X_train,Y_train,X_test,Y_test)
row_labels = ['svm:', '随机森林:']
col_labels = ['最高准确率']
table_vals = [['{:.2f}%'.format(svm_accuracy*100)], ['{:.2f}%'.format(rf_accuracy*100)]] # # row_colors = ['gold']
my_table = plt.table(cellText=table_vals, colWidths=[0.3]*3,
rowLabels=row_labels, colLabels=col_labels, loc='center', cellLoc='center', rowLoc='center')
my_table.auto_set_font_size(False)
plt.title('maxLittle')
my_table.set_fontsize(10) # 字体大小
my_table.scale(2, 3) # 表格缩放
plt.savefig("maxLittle" + ".png")
plt.show()
elif mode == "PD":
data = scipy.io.loadmat('PD.mat')
X1 = data['xtrain']
Y1 = data['ytrain']
X2 = data['xtest']
Y2 = data['ytest']
X_train, Y_train, X_test, Y_test = divide_dataset(X1, Y1, X2, Y2)
print('start svm training...')
svm_accuracy = SVM_MODEL(X_train,Y_train,X_test,Y_test)
print('start ranforest training...')
rf_accuracy = RF_MODEL(X_train,Y_train,X_test,Y_test)
row_labels = ['svm:', '随机森林:']
col_labels = ['最高准确率']
table_vals = [['{:.2f}%'.format(svm_accuracy*100)], ['{:.2f}%'.format(rf_accuracy*100)]] # # row_colors = ['gold']
my_table = plt.table(cellText=table_vals, colWidths=[0.3]*3,
rowLabels=row_labels, colLabels=col_labels, loc='center', cellLoc='center', rowLoc='center')
my_table.auto_set_font_size(False)
plt.title('PD')
my_table.set_fontsize(10) # 字体大小
my_table.scale(2, 3) # 表格缩放
plt.savefig("PD" + ".png")
plt.show()
elif mode == "pima-indians-diabetes":
data = scipy.io.loadmat('pima-indians-diabetes.mat')
X1 = data['xtrain']
Y1 = data['ytrain']
X2 = data['xtest']
Y2 = data['ytest']
X_train, Y_train, X_test, Y_test = divide_dataset(X1, Y1, X2, Y2)
print('start svm training...')
svm_accuracy = SVM_MODEL(X_train,Y_train,X_test,Y_test)
print('start ranforest training...')
rf_accuracy = RF_MODEL(X_train,Y_train,X_test,Y_test)
row_labels = ['svm:', '随机森林:']
col_labels = ['最高准确率']
table_vals = [['{:.2f}%'.format(svm_accuracy*100)], ['{:.2f}%'.format(rf_accuracy*100)]] # # row_colors = ['gold']
my_table = plt.table(cellText=table_vals, colWidths=[0.3]*3,
rowLabels=row_labels, colLabels=col_labels, loc='center', cellLoc='center', rowLoc='center')
my_table.auto_set_font_size(False)
plt.title('pima-indians-diabetes')
my_table.set_fontsize(10) # 字体大小
my_table.scale(2, 3) # 表格缩放
plt.savefig("pima-indians-diabetes" + ".png")
plt.show()
elif mode == "vehicle":
data = scipy.io.loadmat('vehicle.mat')
X1 = data['xtrain']
Y1 = data['ytrain']
X2 = data['xtest']
Y2 = data['ytest']
X_train, Y_train, X_test, Y_test = divide_dataset(X1, Y1, X2, Y2)
print('start svm training...')
svm_accuracy = SVM_MODEL(X_train,Y_train,X_test,Y_test)
print('start ranforest training...')
rf_accuracy = RF_MODEL(X_train,Y_train,X_test,Y_test)
row_labels = ['svm:', '随机森林:']
col_labels = ['最高准确率']
table_vals = [['{:.2f}%'.format(svm_accuracy*100)], ['{:.2f}%'.format(rf_accuracy*100)]] # # row_colors = ['gold']
my_table = plt.table(cellText=table_vals, colWidths=[0.3]*3,
rowLabels=row_labels, colLabels=col_labels, loc='center', cellLoc='center', rowLoc='center')
my_table.auto_set_font_size(False)
plt.title('vehicle')
my_table.set_fontsize(10) # 字体大小
my_table.scale(2, 3) # 表格缩放
plt.savefig("vehicle" + ".png")
plt.show()
elif mode == "WDBC":
data = scipy.io.loadmat('WDBC.mat')
X1 = data['xtrain']
Y1 = data['ytrain']
X2 = data['xtest']
Y2 = data['ytest']
X_train, Y_train, X_test, Y_test = divide_dataset(X1, Y1, X2, Y2)
print('start svm training...')
svm_accuracy = SVM_MODEL(X_train,Y_train,X_test,Y_test)
print('start ranforest training...')
rf_accuracy = RF_MODEL(X_train,Y_train,X_test,Y_test)
row_labels = ['svm:', '随机森林:']
col_labels = ['最高准确率']
table_vals = [['{:.2f}%'.format(svm_accuracy*100)], ['{:.2f}%'.format(rf_accuracy*100)]] # # row_colors = ['gold']
my_table = plt.table(cellText=table_vals, colWidths=[0.3]*3,
rowLabels=row_labels, colLabels=col_labels, loc='center', cellLoc='center', rowLoc='center')
my_table.auto_set_font_size(False)
plt.title('WDBC')
my_table.set_fontsize(10) # 字体大小
my_table.scale(2, 3) # 表格缩放
plt.savefig("WDBC" + ".png")
plt.show()
elif mode == "Wisconsin":
data = scipy.io.loadmat('Wisconsin.mat')
X1 = data['xtrain']
Y1 = data['ytrain']
X2 = data['xtest']
Y2 = data['ytest']
X_train, Y_train, X_test, Y_test = divide_dataset(X1, Y1, X2, Y2)
print('start svm training...')
svm_accuracy = SVM_MODEL(X_train,Y_train,X_test,Y_test)
print('start ranforest training...')
rf_accuracy = RF_MODEL(X_train,Y_train,X_test,Y_test)
row_labels = ['svm:', '随机森林:']
col_labels = ['最高准确率']
table_vals = [['{:.2f}%'.format(svm_accuracy*100)], ['{:.2f}%'.format(rf_accuracy*100)]] # # row_colors = ['gold']
my_table = plt.table(cellText=table_vals, colWidths=[0.3]*3,
rowLabels=row_labels, colLabels=col_labels, loc='center', cellLoc='center', rowLoc='center')
my_table.auto_set_font_size(False)
plt.title('Wisconsin')
my_table.set_fontsize(10) # 字体大小
my_table.scale(2, 3) # 表格缩放
plt.savefig("Wisconsin" + ".png")
plt.show()
效果图展示:
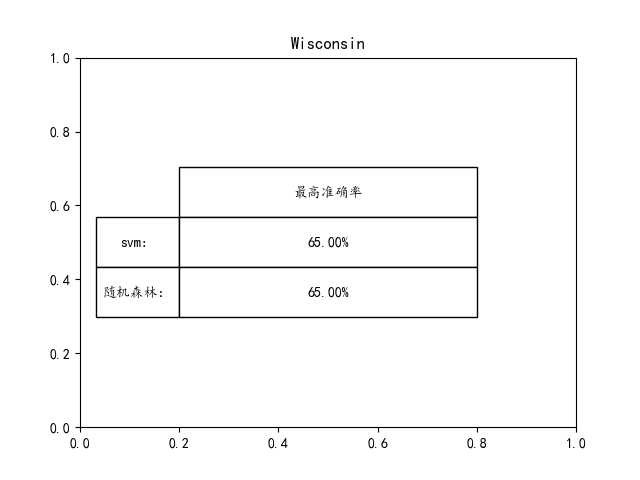
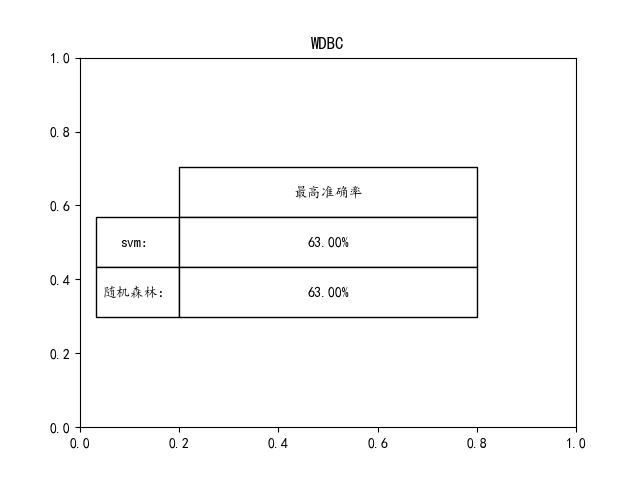
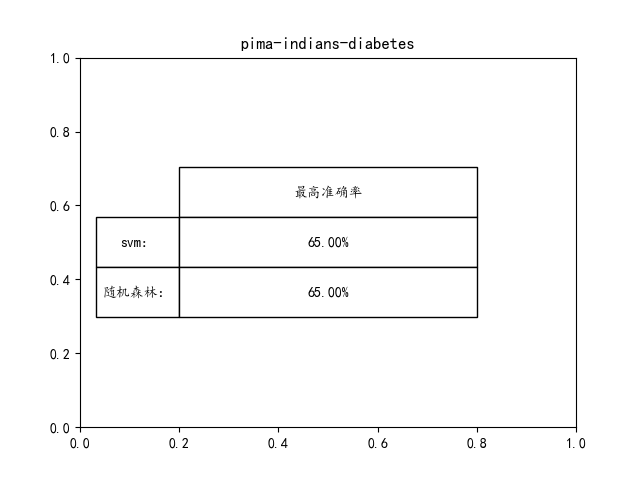
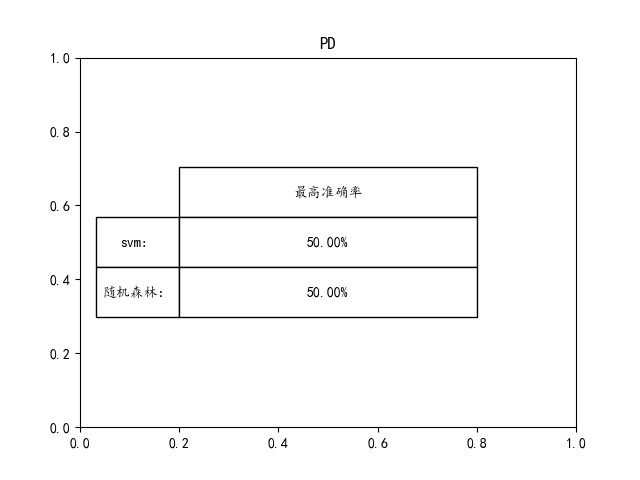
如果想要达到更高的准确率可以在源码里面调节参数就可!!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











