import pandas as pd
import numpy as np
pd. Series( [ 1 , '1.' ] ) . astype( 'str' ) . astype( 'string' )
0 1
1 1.
dtype: string
pd. Series( [ 1 , 2 ] ) . astype( 'str' ) . astype( 'string' )
0 1
1 2
dtype: string
pd. Series( [ True , False ] ) . astype( 'str' ) . astype( 'string' )
0 True
1 False
dtype: string
s = pd. Series( [ 'a_b_c' , 'c_d_e' , np. nan, 'f_g_h' ] , dtype= "string" )
s
0 a_b_c
1 c_d_e
2 <NA>
3 f_g_h
dtype: string
s. str . split( '_' )
0 [a, b, c]
1 [c, d, e]
2 <NA>
3 [f, g, h]
dtype: object
s. str . split( '_' ) . str [ 1 ]
0 b
1 d
2 <NA>
3 g
dtype: object
pd. Series( [ 'a_b_c' , [ 'a' , 'b' , 'c' ] ] , dtype= "object" ) . str [ 1 ]
0 _
1 b
dtype: object
s. str . split( '_' , expand= True )
0 1 2 0 a b c 1 c d e 2 <NA> <NA> <NA> 3 f g h
s. str . split( '_' , n= 1 )
0 [a, b_c]
1 [c, d_e]
2 <NA>
3 [f, g_h]
dtype: object
s. str . split( '_' , expand= True , n= 1 )
0 1 0 a b_c 1 c d_e 2 <NA> <NA> 3 f g_h
s = pd. Series( [ 'ab' , None , 'd' ] , dtype= 'string' )
s
0 ab
1 <NA>
2 d
dtype: string
s. str . cat( )
'abd'
s. str . cat( sep= ',' )
'ab,d'
s. str . cat( sep= ',' , na_rep= '*' )
'ab,*,d'
s2 = pd. Series( [ '24' , None , None ] , dtype= 'string' )
s2
0 24
1 <NA>
2 <NA>
dtype: string
s. str . cat( s2)
0 ab24
1 <NA>
2 <NA>
dtype: string
s. str . cat( s2, sep= ',' , na_rep= '*' )
0 ab,24
1 *,*
2 d,*
dtype: string
s. str . cat( pd. DataFrame( { 0 : [ '1' , '3' , '5' ] , 1 : [ '5' , 'b' , None ] } , dtype= 'string' ) , na_rep= '*' )
0 ab15
1 *3b
2 d5*
dtype: string
s. str . cat( [ s+ '0' , s* 2 ] )
0 abab0abab
1 <NA>
2 dd0dd
dtype: string
s2 = pd. Series( list ( 'abc' ) , index= [ 1 , 2 , 3 ] , dtype= 'string' )
s2
1 a
2 b
3 c
dtype: string
s. str . cat( s2, na_rep= '*' )
0 ab*
1 *a
2 db
dtype: string
这份资料 来熟悉s = pd. Series( [ 'A' , 'B' , 'C' , 'Aaba' , 'Baca' , '' , np. nan, 'CABA' , 'dog' , 'cat' ] , dtype= "string" )
s
0 A
1 B
2 C
3 Aaba
4 Baca
5
6 <NA>
7 CABA
8 dog
9 cat
dtype: string
s. str . replace( r'^[AB]' , '***' )
0 ***
1 ***
2 C
3 ***aba
4 ***aca
5
6 <NA>
7 CABA
8 dog
9 cat
dtype: string
https://blog.csdn.net/yg_2012/article/details/75426842
group的意思是你的正则表达式是由好多组组成的,然后用字符串去匹配这个表达式,group(1)指的是匹配到了正则表达式第一组的子串是什么,group(2)是指匹配到了正则表达式第二组的子串是什么, groups()就是由所有子串组成的集合。 PS:下面看下正则表达式 \w \s \d \b
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字 等价于 ‘[^A-Za-z0-9_]’。
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
\w能不能匹配汉字要视你的操作系统和你的应用环境而定
s. str . replace( r'([ABC])(\w+)' , lambda x: x. group( 2 ) [ 1 : ] + '*' )
0 A
1 B
2 C
3 ba*
4 ca*
5
6 <NA>
7 BA*
8 dog
9 cat
dtype: string
s. str . replace( r'([ABC])(\w+)' , lambda x: print ( x, ' ' , x. group( 2 ) ) )
<_sre.SRE_Match object; span=(0, 4), match='Aaba'> aba
<_sre.SRE_Match object; span=(0, 4), match='Baca'> aca
<_sre.SRE_Match object; span=(0, 4), match='CABA'> ABA
0 A
1 B
2 C
3
4
5
6 <NA>
7
8 dog
9 cat
dtype: string
s. str . replace( r'(?P<one>[ABC])(?P<two>\w+)' , lambda x: x. group( 'two' ) [ 1 : ] + '*' )
0 A
1 B
2 C
3 ba*
4 ca*
5
6 <NA>
7 BA*
8 dog
9 cat
dtype: string
pd. Series( [ 'A' , 'B' ] , dtype= 'string' ) . astype( 'O' ) . replace( r'[A]' , pd. NA, regex= True ) . astype( 'string' )
0 <NA>
1 B
dtype: string
pd. Series( [ 'A' , 'B' ] , dtype= 'string' ) . replace( r'[A]' , 'C' , regex= True )
0 A
1 B
dtype: string
pd. Series( [ 'A' , 'B' ] , dtype= 'O' ) . replace( r'[A]' , 'C' , regex= True )
0 C
1 B
dtype: object
pd. Series( [ 'A' , np. nan] , dtype= 'string' ) . str . replace( 'A' , 'B' )
0 B
1 <NA>
dtype: string
1. str.extract方法
pd. Series( [ '10-87' , '10-88' , '10-89' ] , dtype= "string" ) . str . extract( r'([\d]{2})-([\d]{2})' )
pd. Series( [ '10-87' , '10-88' , '-89' ] , dtype= "string" ) . str . extract( r'(?P<name_1>[\d]{2})-(?P<name_2>[\d]{2})' )
name_1 name_2 0 10 87 1 10 88 2 <NA> <NA>
pd. Series( [ '10-87' , '10-88' , '-89' ] , dtype= "string" ) . str . extract( r'(?P<name_1>[\d]{2})?-(?P<name_2>[\d]{2})' )
name_1 name_2 0 10 87 1 10 88 2 <NA> 89
pd. Series( [ '10-87' , '10-88' , '10-' ] , dtype= "string" ) . str . extract( r'(?P<name_1>[\d]{2})-(?P<name_2>[\d]{2})?' )
name_1 name_2 0 10 87 1 10 88 2 10 <NA>
s = pd. Series( [ "a1" , "b2" , "c3" ] , [ "A11" , "B22" , "C33" ] , dtype= "string" )
s. index
Index(['A11', 'B22', 'C33'], dtype='object')
s. str . extract( r'([\w])' )
s. str . extract( r'([\w])' , expand= False )
A11 a
B22 b
C33 c
dtype: string
s. index. str . extract( r'([\w])' )
s. index. str . extract( r'([\w])' , expand= False )
Index(['A', 'B', 'C'], dtype='object')
s. index. str . extract( r'([\w])([\d])' )
2. str.extractall方法
与extract只匹配第一个符合条件的表达式不同,extractall会找出所有符合条件的字符串,并建立多级索引(即使只找到一个)
s = pd. Series( [ "a1a2" , "b1" , "c1" ] , index= [ "A" , "B" , "C" ] , dtype= "string" )
two_groups = '(?P<letter>[a-z])(?P<digit>[0-9])'
s. str . extract( two_groups, expand= True )
s. str . extractall( two_groups)
letter digit match A 0 a 1 1 a 2 B 0 b 1 C 0 c 1
s[ 'A' ] = 'a1'
s. str . extractall( two_groups)
letter digit match A 0 a 1 B 0 b 1 C 0 c 1
s = pd. Series( [ "a1a2" , "b1b2" , "c1c2" ] , index= [ "A" , "B" , "C" ] , dtype= "string" )
s. str . extractall( two_groups) . xs( 1 , level= 'match' )
pd. Series( [ '1' , None , '3a' , '3b' , '03c' ] , dtype= "string" ) . str . contains( r'[0-9][a-z]' )
0 False
1 <NA>
2 True
3 True
4 True
dtype: boolean
pd. Series( [ '1' , None , '3a' , '3b' , '03c' ] , dtype= "string" ) . str . contains( 'a' , na= False )
0 False
1 False
2 True
3 False
4 False
dtype: boolean
pd. Series( [ '1' , None , '3a_' , '3b' , '03c' ] , dtype= "string" ) . str . match( r'[0-9][a-z]' , na= False )
0 False
1 False
2 True
3 True
4 False
dtype: boolean
pd. Series( [ '1' , None , '_3a' , '3b' , '03c' ] , dtype= "string" ) . str . match( r'[0-9][a-z]' , na= False )
0 False
1 False
2 False
3 True
4 False
dtype: boolean
pd. Series( list ( 'abc' ) , index= [ ' space1 ' , 'space2 ' , ' space3' ] , dtype= "string" ) . index. str . strip( )
Index(['space1', 'space2', 'space3'], dtype='object')
pd. Series( 'A' , dtype= "string" ) . str . lower( )
0 a
dtype: string
pd. Series( 'a' , dtype= "string" ) . str . upper( )
0 A
dtype: string
pd. Series( 'abCD' , dtype= "string" ) . str . swapcase( )
0 ABcd
dtype: string
pd. Series( 'abCD' , dtype= "string" ) . str . capitalize( )
0 Abcd
dtype: string
pd. Series( [ '1.2' , '1' , '-0.3' , 'a' , np. nan] , dtype= "string" ) . str . isnumeric( )
0 False
1 True
2 False
3 False
4 <NA>
dtype: boolean
pd. Series( [ '1.2' , '1' , '-0.3' , 'a' , np. nan, 1 ] ) . apply ( lambda x: True if type ( x) in [ float , int ] and x== x else False )
0 False
1 False
2 False
3 False
4 False
5 True
dtype: bool
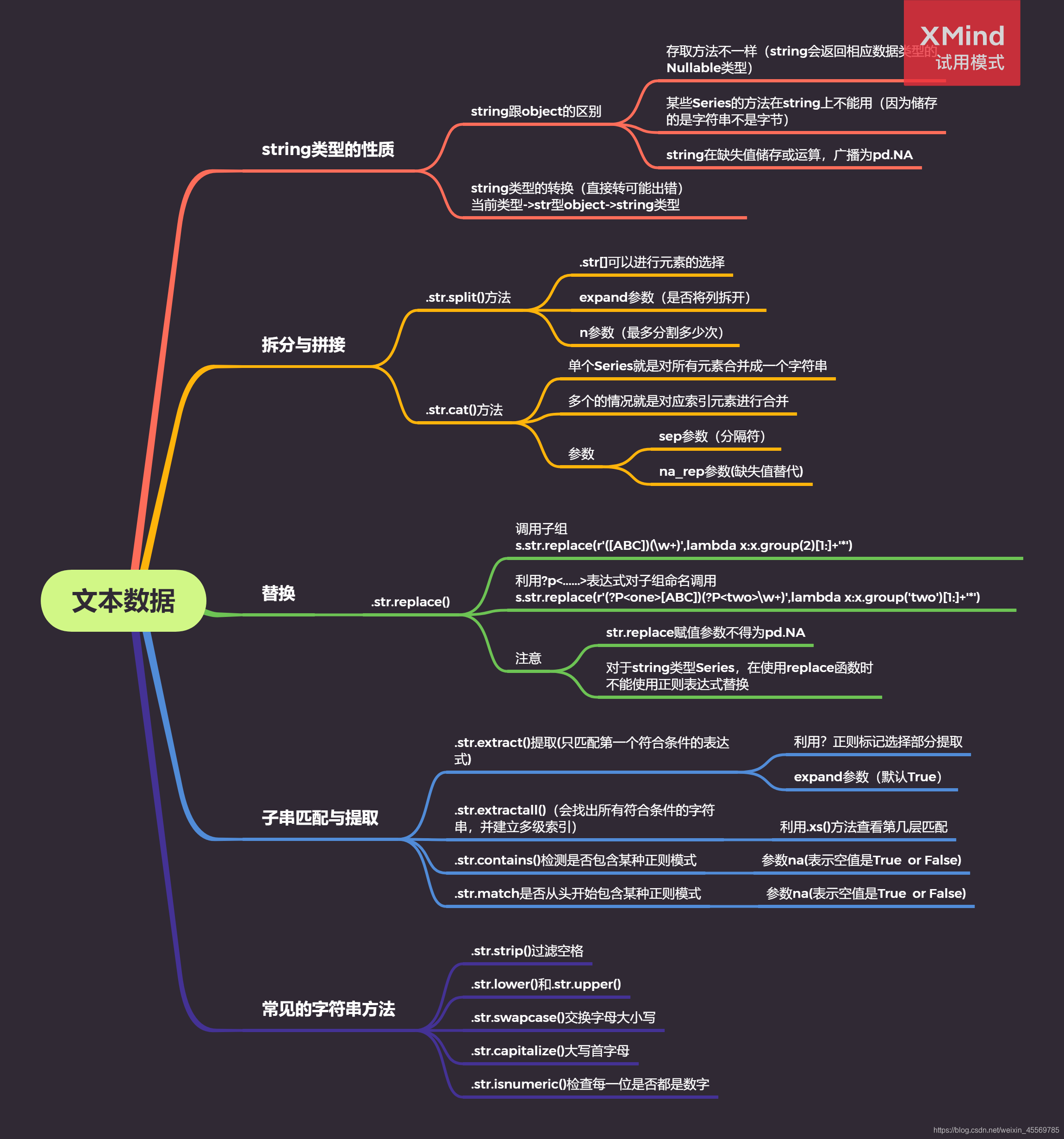
Pandas 为 Series 提供了 str 属性,通过它可以方便的对每个元素进行操作。
在对 Series 中每个元素处理时,我们可以使用 map 或 apply 方法。 比如,我想要将每个城市都转为小写,可以使用如下的方式。 user_info.city.map(lambda x: x.lower())#报错 错误原因是因为 float 类型的对象没有 lower 属性。这是因为缺失值(np.nan)属于float 类型。 这时候我们的 str 属性操作来了 user_info.city.str.lower() 可以看到,通过 str 属性来访问之后用到的方法名与 Python 内置的字符串的方法名一样。并且能够自动排除缺失值。 from https://zhuanlan.zhihu.com/p/38603837
个人理解str对象方法更多的是对于Series中的每个小的元素进行处理的时候,把每个小元素当成字符串进行处理,并且方法名也跟python内置的字符串的方法名一样。
pd. Series( [ '1.2' , '1' , '-0.3' , 'a' , np. nan, 1 ] ) . apply ( lambda x: True if type ( x) in [ float , int ] and x== x else False )
0 False
1 False
2 False
3 False
4 False
5 True
dtype: bool
split()正序分割列;rsplit()逆序分割列
s= pd. Series( [ ' 11 111 111 第一大类' , ' 12 第一大类' , ' 21 第二大类' , ' 22 第二大类' ] )
s. str . rsplit( expand= True , n= 1 )
0 1 0 11 111 111 第一大类 1 12 第一大类 2 21 第二大类 3 22 第二大类
rsplit()是逆序分割,当我们最后面有几列需要单独分割出来,而且由于列数比较多从正着数不知道第几列或者是每一行列数都不一样而我们只需要最后一列,再这种情况下感觉是需要用到rsplit()的。
拆分.str.split()
可能应用于将单独的一列分成好几列,比如讲日期中的年份一列单独拿出来方便后面做分析 拼接.str.cat()
将几列拼接起来生成新的一列,有的时候可能根据几列的信息整理出来一个新的重要的信息单独成一列 替换.str.replace()
在每个元素中查找对应的元素,然后进行替换,可能在对于数据整体进行更新的时候可能会用到替换 匹配.str.contains() .str.match()
提取.str.extract() .str.extractall()
查找每个元素中特定的正则表达式的格式的内容并提取出来 pd. read_csv( 'data/String_data_one.csv' , index_col= '人员编号' ) . head( )
姓名 国籍 性别 出生年 出生月 出生日 人员编号 1 aesfd 2 男 1942 8 10 2 fasefa 5 女 1985 10 4 3 aeagd 4 女 1946 10 15 4 aef 4 男 1999 5 13 5 eaf 1 女 2010 6 24
a= pd. read_csv( 'data/String_data_one.csv' , index_col= '人员编号' )
a[ 'ID' ] = a[ '姓名' ]
a[ 'ID' ] = a[ 'ID' ] . str . cat( [ "(名字)" + ':' + a[ '国籍' ] . astype( str ) . astype( 'string' ) + '国人,性别' + a[ '性别' ] + ',生于' + a[ '出生年' ] . astype( str ) . astype( 'string' ) + '年' + a[ '出生月' ] . astype( str ) . astype( 'string' ) + '月' + a[ '出生日' ] . astype( str ) . astype( 'string' ) + '日' ] )
a. head( )
姓名 国籍 性别 出生年 出生月 出生日 ID 人员编号 1 aesfd 2 男 1942 8 10 aesfd(名字):2国人,性别男,生于1942年8月10日 2 fasefa 5 女 1985 10 4 fasefa(名字):5国人,性别女,生于1985年10月4日 3 aeagd 4 女 1946 10 15 aeagd(名字):4国人,性别女,生于1946年10月15日 4 aef 4 男 1999 5 13 aef(名字):4国人,性别男,生于1999年5月13日 5 eaf 1 女 2010 6 24 eaf(名字):1国人,性别女,生于2010年6月24日
df = pd. read_csv( 'data/String_data_one.csv' , index_col= '人员编号' ) . astype( 'str' )
( df[ '姓名' ] + ':' + df[ '国籍' ] + '国人,性别'
+ df[ '性别' ] + ',生于'
+ df[ '出生年' ] + '年'
+ df[ '出生月' ] + '月' + df[ '出生日' ] + '日' ) . to_frame( ) . rename( columns= { 0 : 'ID' } ) . head( )
ID 人员编号 1 aesfd:2国人,性别男,生于1942年8月10日 2 fasefa:5国人,性别女,生于1985年10月4日 3 aeagd:4国人,性别女,生于1946年10月15日 4 aef:4国人,性别男,生于1999年5月13日 5 eaf:1国人,性别女,生于2010年6月24日
def f ( s) :
map = { '0' : '零' , '1' : '一' , '2' : '二' , '3' : '三' , '4' : '四' , '5' : '五' , '6' : '六' , '7' : '七' , '8' : '八' , '9' : '九' , '10' : '十' , '11' : '十一' , '12' : '十二' }
re= ''
for i in s:
re+= map [ i]
return re
def f2 ( s) :
map = { '0' : '零' , '1' : '一' , '2' : '二' , '3' : '三' , '4' : '四' , '5' : '五' , '6' : '六' , '7' : '七' , '8' : '八' , '9' : '九' , '10' : '十' , '11' : '十一' , '12' : '十二' }
return map [ s]
def f3 ( s) :
map = { '0' : '零' , '1' : '一' , '2' : '二' , '3' : '三' , '4' : '四' , '5' : '五' , '6' : '六' , '7' : '七' , '8' : '八' , '9' : '九' , '10' : '十' , '11' : '十一' , '12' : '十二' }
if len ( s) == 1 :
return map [ s]
elif s[ 1 ] == '0' :
return map [ s[ 0 ] ] + '十'
else :
return map [ s[ 0 ] ] + '十' + map [ s[ 1 ] ]
a= pd. read_csv( 'data/String_data_one.csv' , index_col= '人员编号' )
a[ 'ID' ] = a[ '姓名' ]
a[ 'ID' ] = a[ 'ID' ] . str . cat( [ ':' + a[ '国籍' ] . astype( str ) . astype( 'string' ) + '国人,性别' + a[ '性别' ] + ',生于' + a[ '出生年' ] . astype( str ) . astype( 'string' ) . apply ( lambda x: f( x) ) + '年' + a[ '出生月' ] . astype( str ) . astype( 'string' ) . apply ( lambda x: f2( x) ) + '月' + a[ '出生日' ] . astype( str ) . astype( 'string' ) . apply ( lambda x: f3( x) ) + '日' ] )
a. head( )
姓名 国籍 性别 出生年 出生月 出生日 ID 人员编号 1 aesfd 2 男 1942 8 10 aesfd:2国人,性别男,生于一九四二年八月一十日 2 fasefa 5 女 1985 10 4 fasefa:5国人,性别女,生于一九八五年十月四日 3 aeagd 4 女 1946 10 15 aeagd:4国人,性别女,生于一九四六年十月一十五日 4 aef 4 男 1999 5 13 aef:4国人,性别男,生于一九九九年五月一十三日 5 eaf 1 女 2010 6 24 eaf:1国人,性别女,生于二零一零年六月二十四日
L_year = list ( '零一二三四五六七八九' )
L_one = [ s. strip( ) for s in list ( ' 二三四五六七八九' ) ]
L_two = [ s. strip( ) for s in list ( ' 一二三四五六七八九' ) ]
df_new = ( df[ '姓名' ] + ':' + df[ '国籍' ] + '国人,性别' + df[ '性别' ] + ',生于'
+ df[ '出生年' ] . str . replace( r'\d' , lambda x: L_year[ int ( x. group( 0 ) ) ] ) + '年'
+ df[ '出生月' ] . apply ( lambda x: x if len ( x) == 2 else '0' + x) \
. str . replace( r'(?P<one>[\d])(?P<two>\d?)' , lambda x: L_one[ int ( x. group( 'one' ) ) ]
+ bool ( int ( x. group( 'one' ) ) ) * '十' + L_two[ int ( x. group( 'two' ) ) ] ) + '月'
+ df[ '出生日' ] . apply ( lambda x: x if len ( x) == 2 else '0' + x) \
. str . replace( r'(?P<one>[\d])(?P<two>\d?)' , lambda x: L_one[ int ( x. group( 'one' ) ) ]
+ bool ( int ( x. group( 'one' ) ) ) * '十' + L_two[ int ( x. group( 'two' ) ) ] ) + '日' ) \
. to_frame( ) . rename( columns= { 0 : 'ID' } )
df_new. head( )
ID 人员编号 1 aesfd:2国人,性别男,生于一九四二年八月十日 2 fasefa:5国人,性别女,生于一九八五年十月四日 3 aeagd:4国人,性别女,生于一九四六年十月十五日 4 aef:4国人,性别男,生于一九九九年五月十三日 5 eaf:1国人,性别女,生于二零一零年六月二十四日
re= a[ 'ID' ] . str . extract( r'(?P<姓名>[a-zA-Z]{1,}):(?P<国籍>[\d])国人,性别(?P<性别>[\w]),生于(?P<出生年>[\w]{4})年(?P<出生月>[\w]+)月(?P<出生日>[\w]+)日' )
def f11 ( s) :
map = { '零' : '0' , '一' : '1' , '二' : '2' , '三' : '3' , '四' : '4' , '五' : '5' , '六' : '6' , '七' : '7' , '八' : '8' , '九' : '9' , '十' : '10' }
re= ''
for i in s:
re+= map [ i]
return re
def f22 ( s) :
map = { '零' : '0' , '一' : '1' , '二' : '2' , '三' : '3' , '四' : '4' , '五' : '5' , '六' : '6' , '七' : '7' , '八' : '8' , '九' : '9' , '十' : '10' , '十一' : '11' , '十二' : '12' }
return map [ s]
def f33 ( s) :
re= ''
if len ( s) >= 2 and s[ - 2 ] == '十' :
map = { '零' : '0' , '一' : '1' , '二' : '2' , '三' : '3' , '四' : '4' , '五' : '5' , '六' : '6' , '七' : '7' , '八' : '8' , '九' : '9' , '十' : '' }
for i in s:
re+= map [ i]
return re
elif s[ - 1 ] == '十' :
map = { '零' : '0' , '一' : '1' , '二' : '2' , '三' : '3' , '四' : '4' , '五' : '5' , '六' : '6' , '七' : '7' , '八' : '8' , '九' : '9' , '十' : '0' }
for i in s:
re+= map [ i]
return re
else :
map = { '零' : '0' , '一' : '1' , '二' : '2' , '三' : '3' , '四' : '4' , '五' : '5' , '六' : '6' , '七' : '7' , '八' : '8' , '九' : '9' , '十' : '10' }
re= ''
for i in s:
re+= map [ i]
return re
re[ '出生年' ] = re[ '出生年' ] . apply ( lambda x: f11( x) )
re[ '出生月' ] = re[ '出生月' ] . apply ( lambda x: f22( x) )
re[ '出生日' ] = re[ '出生日' ] . apply ( lambda x: f33( x) )
re. head( )
姓名 国籍 性别 出生年 出生月 出生日 人员编号 1 aesfd 2 男 1942 8 10 2 fasefa 5 女 1985 10 4 3 aeagd 4 女 1946 10 15 4 aef 4 男 1999 5 13 5 eaf 1 女 2010 6 24
test= pd. read_csv( 'data/String_data_one.csv' , index_col= '人员编号' ) . astype( str )
re. equals( test)
True
test. info( )
<class 'pandas.core.frame.DataFrame'>
Int64Index: 2000 entries, 1 to 2000
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 姓名 2000 non-null object
1 国籍 2000 non-null object
2 性别 2000 non-null object
3 出生年 2000 non-null object
4 出生月 2000 non-null object
5 出生日 2000 non-null object
dtypes: object(6)
memory usage: 109.4+ KB
re. info( )
<class 'pandas.core.frame.DataFrame'>
Int64Index: 2000 entries, 1 to 2000
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 姓名 2000 non-null object
1 国籍 2000 non-null object
2 性别 2000 non-null object
3 出生年 2000 non-null object
4 出生月 2000 non-null object
5 出生日 2000 non-null object
dtypes: object(6)
memory usage: 109.4+ KB
dic_year = { i[ 0 ] : i[ 1 ] for i in zip ( list ( '零一二三四五六七八九' ) , list ( '0123456789' ) ) }
dic_two = { i[ 0 ] : i[ 1 ] for i in zip ( list ( '十一二三四五六七八九' ) , list ( '0123456789' ) ) }
dic_one = { '十' : '1' , '二十' : '2' , '三十' : '3' , None : '' }
df_res = df_new[ 'ID' ] . str . extract( r'(?P<姓名>[a-zA-Z]+):(?P<国籍>[\d])国人,性别(?P<性别>[\w]),生于(?P<出生年>[\w]{4})年(?P<出生月>[\w]+)月(?P<出生日>[\w]+)日' )
df_res[ '出生年' ] = df_res[ '出生年' ] . str . replace( r'(\w)+' , lambda x: '' . join( [ dic_year[ x. group( 0 ) [ i] ] for i in range ( 4 ) ] ) )
df_res[ '出生月' ] = df_res[ '出生月' ] . str . replace( r'(?P<one>\w?十)?(?P<two>[\w])' , lambda x: dic_one[ x. group( 'one' ) ] + dic_two[ x. group( 'two' ) ] ) . str . replace( r'0' , '10' )
df_res[ '出生日' ] = df_res[ '出生日' ] . str . replace( r'(?P<one>\w?十)?(?P<two>[\w])' , lambda x: dic_one[ x. group( 'one' ) ] + dic_two[ x. group( 'two' ) ] ) . str . replace( r'^0' , '10' )
df_res. head( )
姓名 国籍 性别 出生年 出生月 出生日 人员编号 1 aesfd 2 男 1942 8 10 2 fasefa 5 女 1985 10 4 3 aeagd 4 女 1946 10 15 4 aef 4 男 1999 5 13 5 eaf 1 女 2010 6 24
pd. read_csv( 'data/String_data_two.csv' ) . head( )
col1 col2 col3 0 鄂尔多斯市第2例确诊患者治愈出院 19 363.6923 1 云南新增2例,累计124例 -67 -152.281 2 武汉协和医院14名感染医护出院 -86 325.6221 3 山东新增9例,累计307例 -74 -204.9313 4 上海开学日期延至3月 -95 4.05
a= pd. read_csv( 'data/String_data_two.csv' ) . convert_dtypes( )
a[ a[ 'col1' ] . str . contains( r'上海' ) | a[ 'col1' ] . str . contains( r'北京' ) ] . head( )
col1 col2 col3 4 上海开学日期延至3月 -95 4.05 5 北京新增25例确诊病例,累计确诊253例 -4 -289.1719 6 上海新增10例,累计243例 2 -73.7105 36 上海新增14例累计233例 -55 -83 40 上海新增14例累计233例 -88 -99
df = pd. read_csv( 'data/String_data_two.csv' )
df. head( )
df[ df[ 'col1' ] . str . contains( r'[北京]{2}|[上海]{2}' ) ] . head( )
col1 col2 col3 4 上海开学日期延至3月 -95 4.05 5 北京新增25例确诊病例,累计确诊253例 -4 -289.1719 6 上海新增10例,累计243例 2 -73.7105 36 上海新增14例累计233例 -55 -83 40 上海新增14例累计233例 -88 -99
b= pd. read_csv( 'data/String_data_two.csv' ) . convert_dtypes( )
b[ 'col2' ] [ ~ b[ 'col2' ] . str . contains( r'^-?\d+$' ) ]
309 0-
396 9`
485 /7
Name: col2, dtype: string
b[ 'col2' ] [ ~ b[ 'col2' ] . str . contains( r'^-?\d+$' ) ] = [ '0' , '9' , '7' ]
b[ 'col2' ] . apply ( lambda x: int ( x) ) . mean( )
-0.984
df[ 'col2' ] [ ~ ( df[ 'col2' ] . str . replace( r'-?\d+' , 'True' ) == 'True' ) ]
309 0-
396 9`
485 /7
Name: col2, dtype: object
def is_number ( x) :
try :
float ( x)
return True
except :
return False
df[ ~ df. col2. map ( is_number) ]
df. loc[ [ 309 , 396 , 485 ] , 'col2' ] = [ 0 , 9 , 7 ]
df[ 'col2' ] . astype( 'int' ) . mean( )
-0.984
c= pd. read_csv( 'data/String_data_two.csv' ) . convert_dtypes( )
c. columns
Index(['col1', 'col2', 'col3 '], dtype='object')
c. info( )
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 500 entries, 0 to 499
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 col1 500 non-null string
1 col2 500 non-null string
2 col3 500 non-null string
dtypes: string(3)
memory usage: 11.8 KB
c[ 'col3 ' ] [ ~ c[ 'col3 ' ] . str . contains( r'^-?\d+(.)?(\d+)?$' ) ] = [ '355.3567' , '9056.2253' , '3534.6554' ]
c[ 'col3 ' ] . astype( 'float' ) . mean( )
F:\dev\anaconda\envs\python35\lib\site-packages\pandas\core\strings.py:1954: UserWarning: This pattern has match groups. To actually get the groups, use str.extract.
return func(self, *args, **kwargs)
24.707484999999988
df. columns = df. columns. str . strip( )
df. columns
Index(['col1', 'col2', 'col3'], dtype='object')
df[ 'col3' ] [ ~ ( df[ 'col3' ] . str . replace( r'-?\d+\.?\d+' , 'True' ) == 'True' ) ]
28 355`.3567
37 -5
73 1
122 9056.\2253
332 3534.6554{
370 7
Name: col3, dtype: object
def is_number ( x) :
try :
float ( x)
return True
except :
return False
df[ ~ df. col3. map ( is_number) ]
df. loc[ [ 28 , 122 , 332 ] , 'col3' ] = [ 355.3567 , 9056.2253 , 3534.6554 ]
df[ 'col3' ] . astype( 'float' ) . mean( )
24.707484999999988






















 5461
5461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









