







- 一、配置 LMDeploy 运行环境:

 下载好的预训练模型如上图。
下载好的预训练模型如上图。
二、以命令行方式与 InternLM2-Chat-1.8B 模型对话:
1.使用Transformer库运行模型:

2.使用LMDeploy与模型对话:

能明显感觉到LMDeploy比Transformer速度快很多。
3.速度比较:
(1)加载模型的速度:
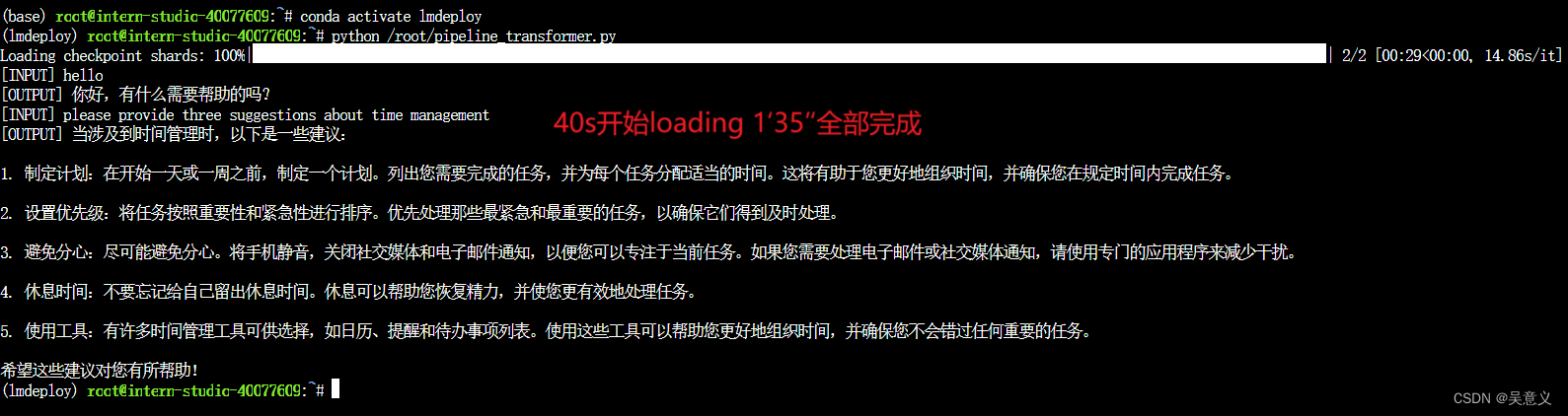
transformer约一分半,如下图:
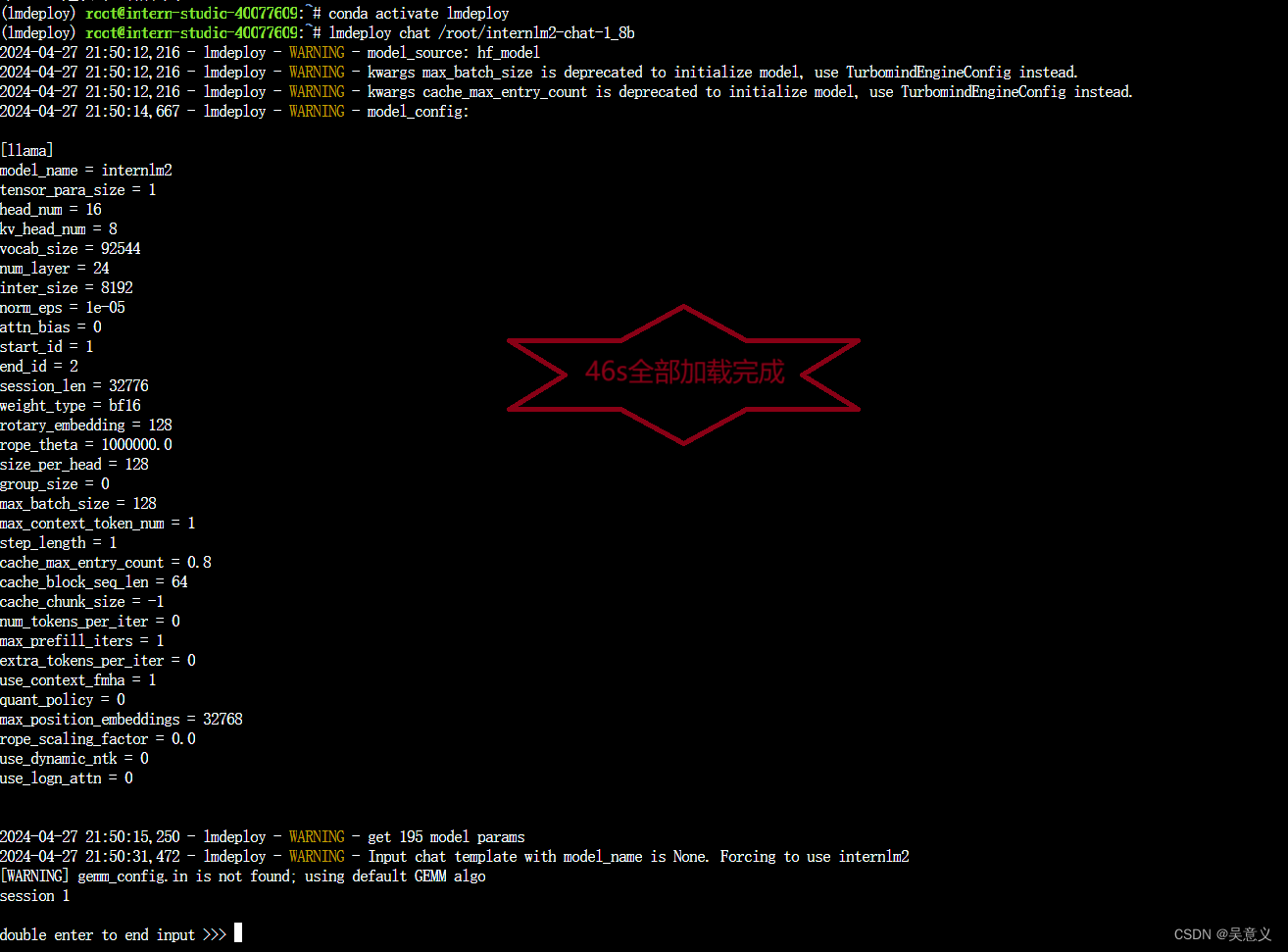
lmdeploy约46s,如下图: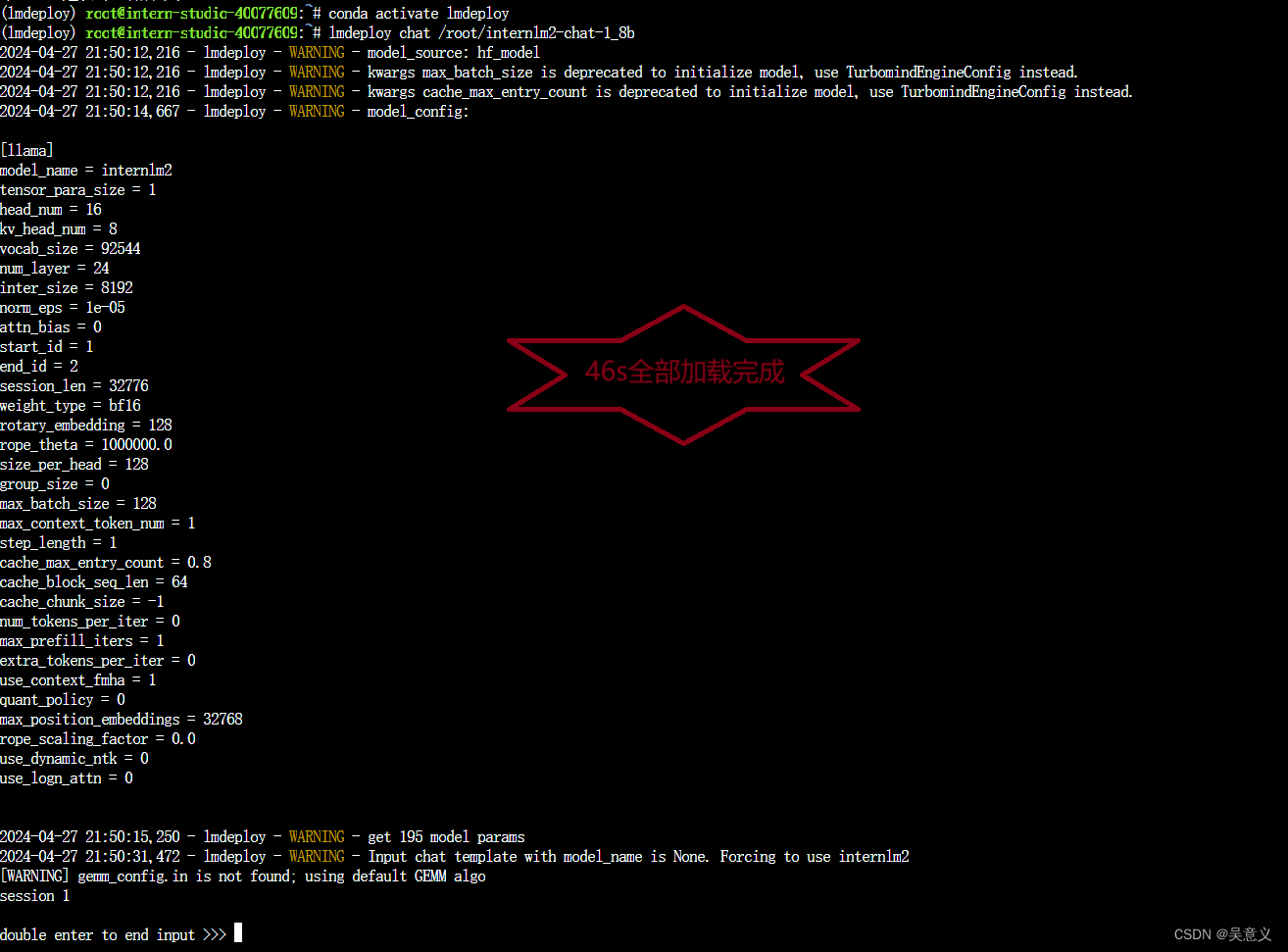
(2)生成西瓜的故事:
transformer约19秒,如下图:

lmdeploy约3s,如下图:

4.LMDeploy模型量化(lite)
1.无限制:
 2. --cache-max-entry-count 0.1
2. --cache-max-entry-count 0.1
 3.--cache-max-entry-count 0.01 几乎禁止KV Cache占用显存:
3.--cache-max-entry-count 0.01 几乎禁止KV Cache占用显存:
 总结:禁用前后模型加载速度和推理速度衰减不明显,可能是“生成小故事”过于简单。具体差异应该会在复杂问题的推理上体现。
总结:禁用前后模型加载速度和推理速度衰减不明显,可能是“生成小故事”过于简单。具体差异应该会在复杂问题的推理上体现。
四、总结
| 运行方式对比 | Transformer | LMDeploy |
| 加载模型 | 76-95s | 46s |
| 生成故事 | 19s | 3-4s |
| 显存限制对比 | 无限制 | 0.1 | 0.01 |
| 显存占用 | 7856 | 4944 | 4560 |
| 生成小故事速度 | 约4s | 约4s | 约4s |















 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









