







目录
结构体:
在之前接触到的数据类型大多都是基本数据类型,例如int类型、double类型,而结构体是一种自定义数据类型,他可以根据我们的需要来让我们自己设计,一个结构体中可以包含多种数据类型。
C语言中有两种数据类型被称为聚合数据类型(aggregate data type),他们分别是结构体和数组。前面说过数组是相同元素的集合,数组的每个元素都可以通过下标来访问。
但是结构体却是不一样的,虽然结构也是一些值的集合,这些值都称为结构的成员,一个结构里面的成员可能有着不一样的数据类型,例如我们要创建一个学生信息的结构体,里面的成员就包括学生的姓名,年龄,身高,性别,考试成绩。与数组不同,结构体中的每个成员都有自己的名字,结构体中的成员也是通过名字进行访问的。
设计结构体的形式如下:
struct 类型名
{
成员(变量的声明);
};//分号是必须要有的在这里我们通过一个例子来逐步认识结构体:
#include<stdio.h>
struct student
{
const char *name;
int age;
int score;
};
int main()
{
struct student stu1 = {"stu1",9,99};//花括号里面的内容一一对应结构体里面的成员列表
return 0;
}在这里需要注意的是如果我们的文件是纯c代码也就是.c形式的文件,student前面一定要加上struct,但是如果是cpp文件我们则可以直接使用student
例如在这里我定义了一个名为学生的结构体,这个结构体由三个成员构成,分别是姓名、年龄、成绩,我在主程序定义了一个stu1的结构体变量。
结构体占用的空间大小(不考虑内存对齐):
接下来我们来看一下结构体在内存中是什么样的:
类型的设计是不占用内存的,例如我使用int类型,当我没有使用int去定义变量的时候int是不占用内存空间的,但是如果我使用int定义了变量,例如int a = 0;这时int类型才会占用4字节的内存空间,同样我们可以映射到结构体上,只有当我们使用结构体类型定义变量的时候他才会占用空间。
在我们不考虑内存对齐的大前提下,我们来分析一个结构体所占的空间大小:
我在这里给出两个结构体:
一:
struct Student
{
char name[10];
int age;
int score;
}它在内存中的结构应该是这样子的:


二:
struct Student
{
const char* name;
int age;
int score;
};第一种结构体的大小为字符数组中的10字节加上两个int类型一共为18字节。
第二种结构体中name作为指针存储结构体中姓名字符串的地址进行输出,在三十二位系统中指针的大小为4字节,所以结构体的总大小为12字节。
结构体的成员访问:
那么我们应该如何进行结构体中成员中的访问呢?
我们继续使用上面的结构体,并在主程序中定义一个名为stu1的人分别对应结构体成员,通过结构体变量来进行成员的访问:
#include<stdio.h>
struct Student
{
const char* name;
int age;
int score;
};
int main()
{
struct Student stu1 = {"zs",12,100};
printf("%s ",stu1.name);//通过结构体变量来进行成员的访问
return 0;
}运行结果:

同样,我们现在访问结构体中的所有成员:
printf("%s,%d,%d\n",stu1.name,stu1.age,stu1.score);注:这里的“ . ”称为成员访问符。
结构体与数组的结合:
上面我们写的是只有stu1一个学生的情况,如果我们在已经定义了Student结构体的情况下,需要存放多个学生的信息,我们一个一个的去定义就显得麻烦了,我们这时可以通过数组来对学生的信息进行储存:
第一种:
在数组内使用花括号直接输入信息通过数组的下标进行元素访问,再通过成员访问符对元素里面的成员进行定向访问:
#include<stdio.h>
struct Student
{
const char *name;
int age;
int score;
};
int main()
{
struct Student ar[] = {{"zs",10,100},{"lisi",9,99},{"ww",8,88}};
int len = sizeof(ar) / sizeof(ar[0]);
for(int i = 0;i < len;i++){
printf("第%d个学生,姓名:%s,年龄:%d,成绩:%d\n",i,ar[i].name,ar[i].age,ar[i].score);
}
return 0;
}运行结果为:

第二种:
如果我在定义结构体数组前就已经设定好了学生,直接将结构体变量名称存放至数组中也是可以的:
struct Student stu1 = {"zs",10,100};
struct Student stu2 = {"lisi",9,99};
struct Student stu3 = {"ww",8,88};
struct Student ar[] = {stu1,stu2,stu3};
int len = sizeof(ar) / sizeof(ar[0]);
for(int i = 0;i < len;i++){
printf("第%d个学生,姓名:%s,年龄:%d,成绩:%d\n",i,ar[i].name,ar[i].age,ar[i].score);
}运行结果为:

两种方式均可完成对结构体数组访问的需求,第二种方式代码量稍多, 但是比较整齐。
结构体与typedef关键字的结合问题:
我们在定义结构体的时候,不难发现每次要使用到结构体的时候都要将struct Student重新写一遍,显得比较繁琐,于是我们可以使用类型重命名:
例如我们在这里直接将struct Student重命名为student:
struct Student
{
const char* name;
int age;
int score;
};
typedef struct Student student;将语句简洁化:
typedef struct Student
{
const char* name;
int age;
int score;
}student;//将新类型名称添加到分号的前面
对结构体类型进行重命名之后我们就可以使用新的类型名进行变量的定义了,写语句的时候也可将struct省略,比较简洁。
结构体与指针的结合:
通过指针操作符“*”和成员访问符“ . ”:
我们可以通过使用定义结构体类型的指针指向结构体的方法来进行结构体成员的定向访问:
student ar[] = {{"zs",10,100},{"lisi",9,99},{"ww",8,88}};
student *ptr = ar;
printf("%s",(*ptr).name);在这里成员访问符“ . ”的优先级是要高于指针操作符“ * ”的,所以我们在使用指针对结构体进行访问时需要加上括号,同样,如果我们要访问结构体数组中的第二个成员的名字,我们也可以使用指针加1的功能来书写:
(*(ptr + 1)).name);//第二个成员的名字(*(ptr + 2)).name);//第三个成员的名字运行结果:

通过指向符“->”:
在这里需要注意,指向符也是具有解引用作用的。
例如我在这里需要通过指向符访问结构体数组中的第一个元素的name成员:
student ar[] = {{"zs",10,100},{"lisi",9,99},{"ww",8,88}};
student *ptr = ar;
printf("%s",ptr->name);那么我需要使用指向符分别访问第二个和第三个元素中的name成员呢?
还是指针加1的知识,同样因为优先级的问题,我们在进行定向访问的时候应该加上括号:
printf("%s",(ptr+1)->name);//第二个元素中name成员的访问printf("%s",(ptr+2)->name);//第三个元素中name成员的访问我们将这三个结果全部输出,看一下运行结果:

如图,访问成功。
我们再使用typedef关键字对结构体的指针类型进行重命名:
student ar[] = {{"zs",10,100},{"lisi",9,99},{"ww",8,88}};
typedef struct Student *Pstu;
Pstu ptr = ar;
printf("%s\n%s\n%s\n",ptr->name,(ptr+1)->name,(ptr+2)->name);如图,依然是显示编译成功的:

我们可以直接在主程序之前就重新定义类型名的结构体中写上指针的重命名,对代码做简洁化处理:
typedef struct Student
{
const char *name;
int age;
int score;
}student,*Pstu;这个方法依然是可行的。
注:在我们使用指针的方法对结构体成员进行访问的时候,指向符的使用是要优先于解引用的使用的。
结构体的内存大小:
在前文中提到过,不考虑内存对齐的情况,一个结构体的总大小就是结构体中所有成员的类型大小之和,但是如果考虑了内存对齐,结果就不一样了。
我们先来看看到底什么是内存对齐:
struct A
{
char a;
int b;
short c;
};struct B
{
short c;
char a;
int b;
};A和B两个结构体中,里面成员的数据类型是一样的,只是成员的顺序不一样,我们输出AB两个结构体的大小:
实际上两个结构体分别所占的内存是不一样的,这是为什么呢
答案就是内存对齐导致声明变量顺序不一样的结构体有不同的大小,编译器为计算机中的每个程序分配到合适的内存空间,而这一切的我们可以追溯至CPU。
我们都知道,内存在计算机中起到桥梁的作用,是内存建立起了CPU与外存之间的联系,内存也暂时存储了CPU中的运算信息,这里我们重点来关注一下CPU对内存的读取方式:
cpu读取内存的方式是块状的,块的大小可以是2,4,8,16 个字节,一般都是2的整数倍,因此CPU在读取内存的时候是一块一块进行读取的,块的大小称为(memory granularity)内存读取粒度。既然读取内存是以块状进行读取的,那么必定会出现内存浪费。
结构体成员在内存中的分布有以下三条规则:
结构体变量的首地址,必须是MIN(结构体变量中最大基本数据类型,指定内存对齐方式)的成员所占字节数的整数倍。
结构体变量中每个成员相对结构体首地址的偏移量都是MIN(该成员基本数据类型所占字节树的整数倍,指定内存对齐方式)。
结构体总大小为结构体MIN(变量中最大基本数据类型或追定内存对齐方式所占字节)的整数倍。
注:这里的MIN指的是两者之间的最小值。
结构体变量的第一个成员位于地址为0的位置,我们以这个结构体为例子:
struct A
{
int a;
char b;
short c;
long long d;
};在结构体A中,最大的基本数据类型为long long,所占为8字节,其余分别为4字节,1字节,2字节,如图:
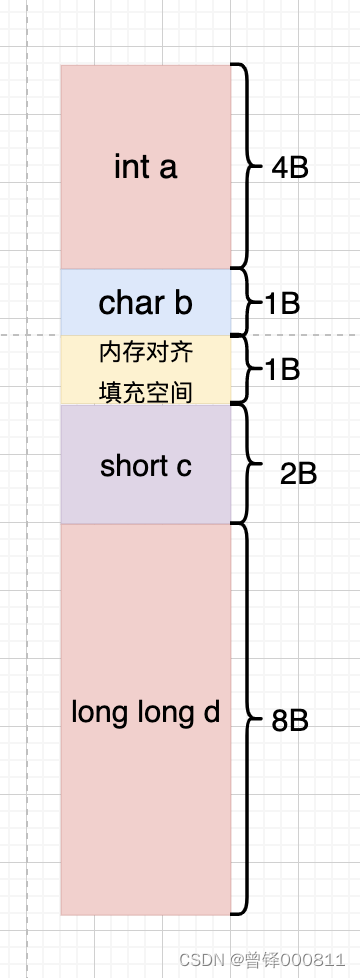
此时我们默认数据类型对齐方式为8字节,初识地址为0,结构体从int a开始占四字节,接下里是char b,前面提到过,CPU读取内存的方式一块一块的进行读取,所以char b 所占是一字节,因为内存对齐,我们需要在后面继续添加一字节的空间,这块空间并没有存储数据,他只是因为计算机要内存对齐而产生出来的空间,所以此时加上前面的int类型空间一共是6字节,是2的整数倍,所以我们后面直接对short进行内存空间分配,现在是8字节,我们继续在后面添加long long类型,总大小为16字节,前文中提到过,结构体的总大小必须是结构体变量中最大基本数据类型的整数倍,这个结构体变量类型里面最大的是long long类型,为8字节,我们的总大小为16字节,是8的整数倍,所以这个结构体的总大小就应该是16字节。
我们来看一下运行结果:

结果正确。
那么如果我们在结构体中再添加一个整形类型的成员,所有类型加起来并算上内存对齐所分配的空间应该是20,但是20并不是结构体中最大基本数据类型的整数倍,所以我们应该在后面再分配4个字节的空间,总大小为24字节。我们通过程序来进行验证:

结果是正确的。
前面我们提到过,内存读取是块状的,而内存对齐方式也有2,4,8等方式,并且内存对齐方式是可以自定义的,那么如何制定内存对齐方式?
#progma pack(1)//对齐方式开始括号内填写需要制定几字节作为内存对齐方式
例如我们使用上面的结构体A:
struct A
{
int a;
char b;
short c;
long long d;
}当我们不使用内存对齐方式自定义语句时,程序是会以最大基本数据类型的整数倍来决定最终结构体的总大小的,就是24。
如果我们使用自定义内存对齐方式语句的话,我们这里分别设置为4和1:

此时只要成员加上内存对齐后是4的整数倍大小即可,也就是20。
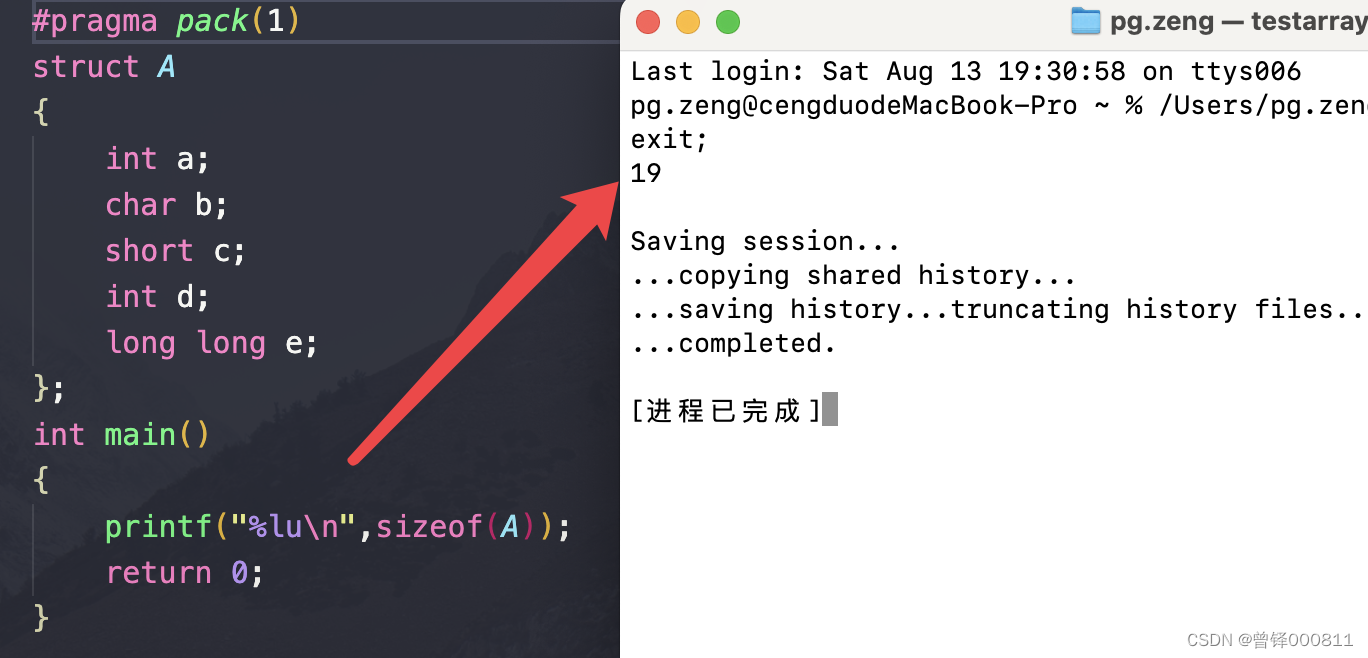
如果内存对齐方式为1,我们就不用在char类型的后面再分配空间,因为内存方式本来就是1,所以也就是结构体所有成员类型大小加起来的总和,19.
当我们使用完自定义内存对齐自然也需要对它进行结束,结束语句为:
#pragma pack()//内存对齐方式结束#pragma pack()与#define一样,均为预处理指令。
结构体中的成员在内存中开辟空间以及内存对齐的完整过程:
结构体:
struct student
{
int a;
char b;
short c;
int e;
long long d;
};
如图所示:下面为在结构体student中,每个成员进行内存开辟的过程:
1:首先对int 类型的成员a进行空间的开辟,大小为4.
2:因为int类型的大小为4,是大小为1的char类型的整数倍,所以直接紧接着int类型进行空间开辟
3:short类型的大小为2,前面int类型加上char类型的大小为5,不是2的整数倍,所以我们再次开辟1个字节的空间进行内存对齐,这时总大小为6,恰好为2的整数倍,成员c在新开辟的一个字节后进行开辟
4:此时前面的总大小加起来为8,恰好是int类型成员e大小的整数倍,所以直接在后面进行开辟
5;前面的大小加起来为12,不为long long类型的成员e的整数倍,所以我们开辟4字节的空间用于内存填充,此时大小为16,恰好为8的整数倍,所以成员d在后面进行开辟。
6:结构体的成员总大小为24,我们用程序进行验证:
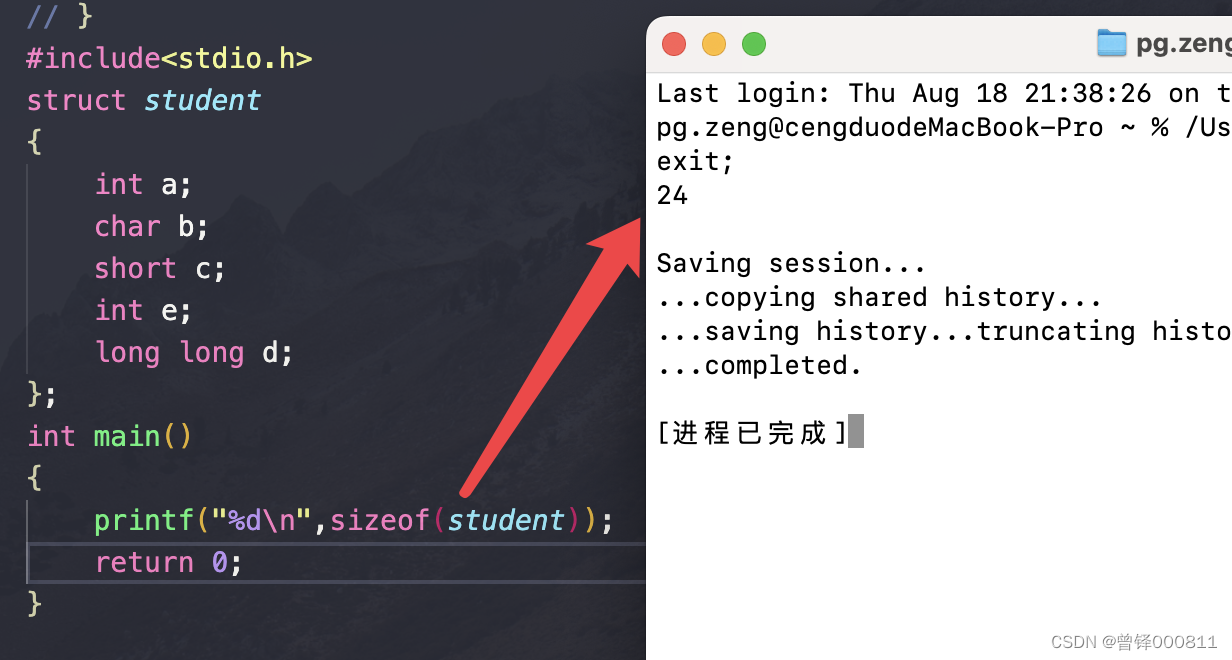
结果正确
结构体的嵌套:
struct address
{
const char *city;
const char *street;
};
struct student
{
const char *name;
int age;
struct address;
};同样,我们来分析包含内存对齐的内存开辟的过程:
1:address结构体中的两个成员类型均为指针类型,指针类型的大小为4,所以addree结构体的总大小为8
2:student结构体中先对成员char *name进行内存开辟,大小为4字节,age成员为int类型,也为4字节,4为4的整数倍,所以直接衔接着进行开辟,address结构体的总大小为8字节,前面成员的大小总和为8字节,是整数倍,直接在后面进行内存开辟,期间没有内存对齐,所以student结构体总大小为16.
我们利用程序来进行验证:

如图,结果正确
结构体和动态内存的结合:
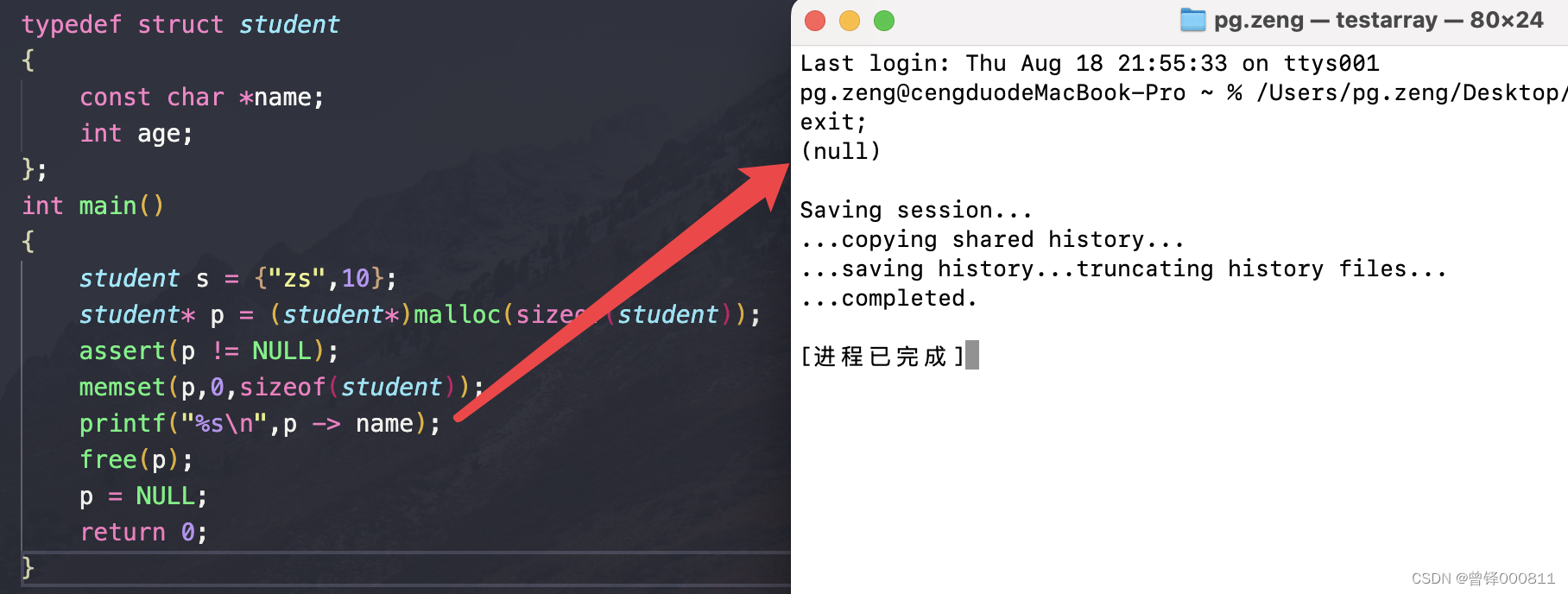
typedef struct student
{
const char *name;
int age;
};
int main()
{
student s = {"zs",10};
student* p = (student*)malloc(sizeof(student));
assert(p != NULL);
memset(p,0,sizeof(student));
printf("%s\n",p -> name);
free(p);
p = NULL;
return 0;
}使用malloc函数申请student类型大小的堆空间,并用0对这片区域进行初始化,我们将初始化后的属于成员name的这片空间用字符串的形式打印出来,结果应该为空。
运行结果:
变量:
我们在编程中,必须要分清楚每个变量之间的联系,弄清楚变量之间的区别,才能正确的使用变量,变量一共分为两种:
局部变量:
在函数内部定义的变量:
例子:
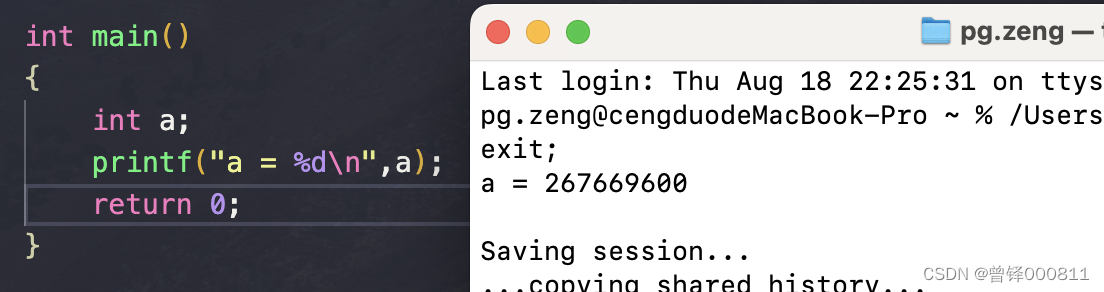
此时,a在testarray这个cpp文件下的main主程序中被定义,所以此时的a就为局部变量。
且局部变量在定义时未被赋值的前提下,系统会将随机值赋给局部变量。
局部变量的生命周期:
函数中被定义 -> 定义处生 -> 函数结束时变量也结束
栈 -> 栈中内存的开辟与释放
全局变量:
在函数外部定义的变量:
例子:

此时,变量a被定义在了main函数之外,a面向的是testarray文件中所有的函数,此时的a就为全局变量。
全局变量在定义时未被赋值的前提下,系统会自动的将默认值(也就是0) 赋值给全局变量。
全局变量的声明周期:
程序启动,全局变量生;程序结束,全局变量结束。
当我们在其他文件中定义全局变量时,在main程序中对全局变量的值进行修改时,程序会进行报错,但是我们可以通过C语言中的一个关键字extern来进行不同文件中的全局变量的链接。
由此我们引入extern关键字:
如图,我在my_struct文件中定义全局变量a,然后在testarray文件中试图对a变量进行赋值,程序发生了报错:

但是当我在main程序前添加这个语句之后,程序就能正常编译了:
extern int a;extern关键字的作用为链接外部文件中的全局变量。
注:如果此时的全局变量为静态全局变量,也就是在定义全局变量时前面加上了static关键字,此时全局变量就没有了可链接属性,只有在本文件中是可见的,如果我们仍使用extern关键字进行链接,程序就会进行报错.
static int a;结构体的练习:
结构体成员的定向访问以及和排序的结合:
编写一个程序,使用机构体来存储学生的信息,并使用排序将学生成绩进行升序排序,成绩相同,按照名字降序排列:
#include<stdio.h>
#include<assert.h>
#include<string.h>
typedef struct Student//重新定义结构体类型名
{
const char *name;
int age;
int score;
}student;
void Swap(student *p,student *q)//交换函数
{
assert(p != NULL && q != NULL);
student temp = *p;//因为我们需要交换的是结构体中的成员,所以临时值temp也应是我们重新定义的类型
*p = *q;
*q = temp;
}
void Bubble_sort(student *ar,int len)//冒泡排序(针对结构体中的成员,所以形参类型为结构体类型)
{
assert(ar != NULL && len >= 0);
while(len--){
int flag = 0;
for(int i = 0;i < len;i++){
if(ar[i].score > ar[i + 1].score){
flag = 1;
Swap(&ar[i],&ar[i + 1]);
}
else if(ar[i].score == ar[i + 1].score){//如果成绩相同的情况下
if(strcmp(ar[i].name,ar[i + 1].name) < 0){//使用strcmp函数,如果前一个字符串返回的整数值是小于后一个字符串的则直接进行交换
Swap(&ar[i],&ar[i + 1]);
}
}
}
if(!flag){
break;
}
}
}
int main()
{
student ar[] = {{"zs",10,100},{"lisi",9,100},{"ww",8,100}};
int len = sizeof(ar) / sizeof(ar[0]);
Bubble_sort(ar,len);
for(int i = 0;i < len;i++){
printf("姓名:%s,成绩:%d\n",ar[i].name,ar[i].score);
}
return 0;
} 运行结果:

















 827
827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











