






20231017
1、[LG] Language Modeling Is Compression
语言模型即压缩。最大化模型对数似然等价于利用该模型进行数据压缩时最小化所需比特数。
通过实验证明了Chinchilla等模型的压缩性能。仅在文本上训练的模型,比专门的压缩算法要更好地压缩图像和音频。
从压缩地视角来看模型,由于压缩考虑了模型的大小,因此模型越大未必压缩性能越好。模型大小与数据集之间存在权衡。
所有曲线在某一点上都会上升,原因是模型大小的增加。当模型过大时,即使它有更好的压缩效果,但由于模型本身的大小,整体的压缩率会变差。(压缩后的数据还得再存个模型)
2、[LG] Accelerated Gradient Descent via Long Steps
论文通过使用非常仔细构造的非恒定、非周期性的越来越大的步长序列,达到了O(1/T^1.02449)的收敛率。
这是第一个展示在光滑凸优化问题中,梯度下降方法可以严格快于O(1/T)的big-O加速收敛率的结果,获得conj所猜测的最优O(1/T^2)收敛率仍然是开放问题。
步长序列是通过连接和重新缩放包含指数级平均步长的指数长度模块h(k)构建的。
以前觉得随着训练的进行,学习率递减才能更好地进行模型优化。但是本文使用设定的非周期性且越来越大的学习率(步长),使得模型更快地收敛。表明在优化的广阔领域中,仍然有很多有待探索的领域,而不同的问题可能需要不同的策略。
2023104
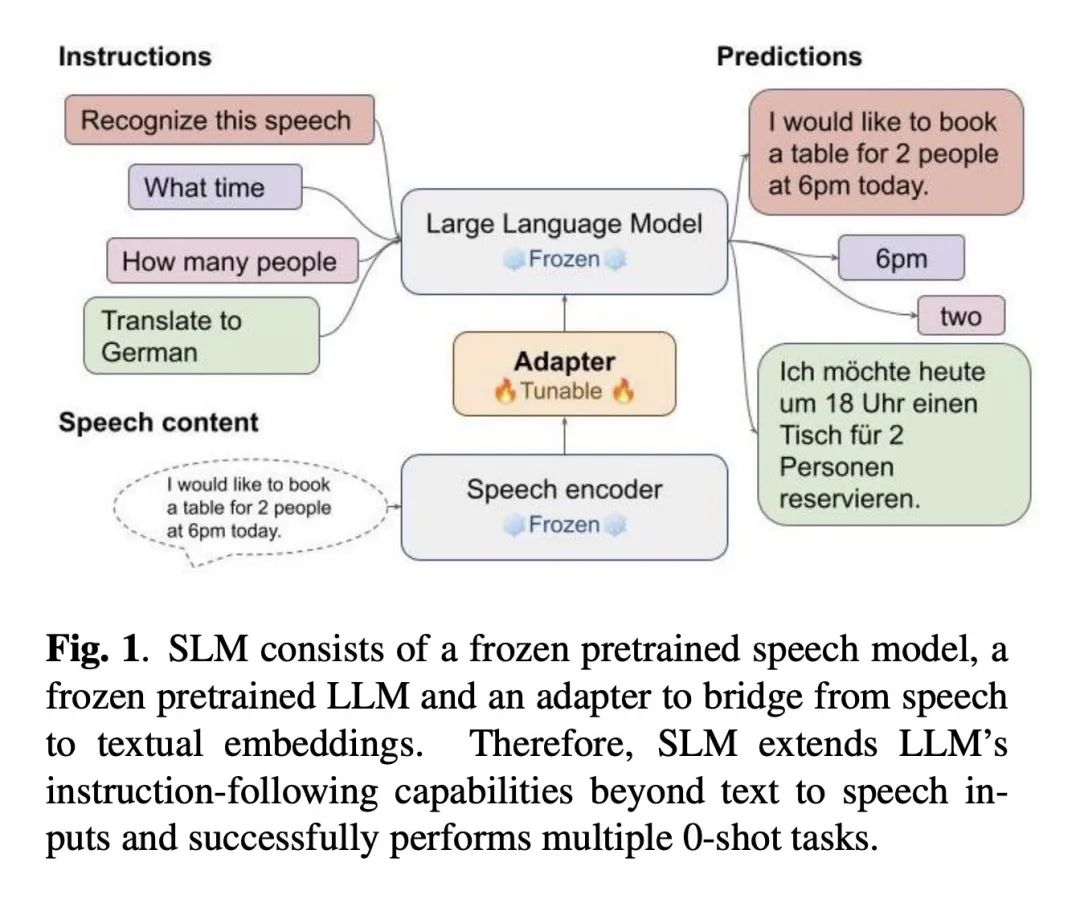
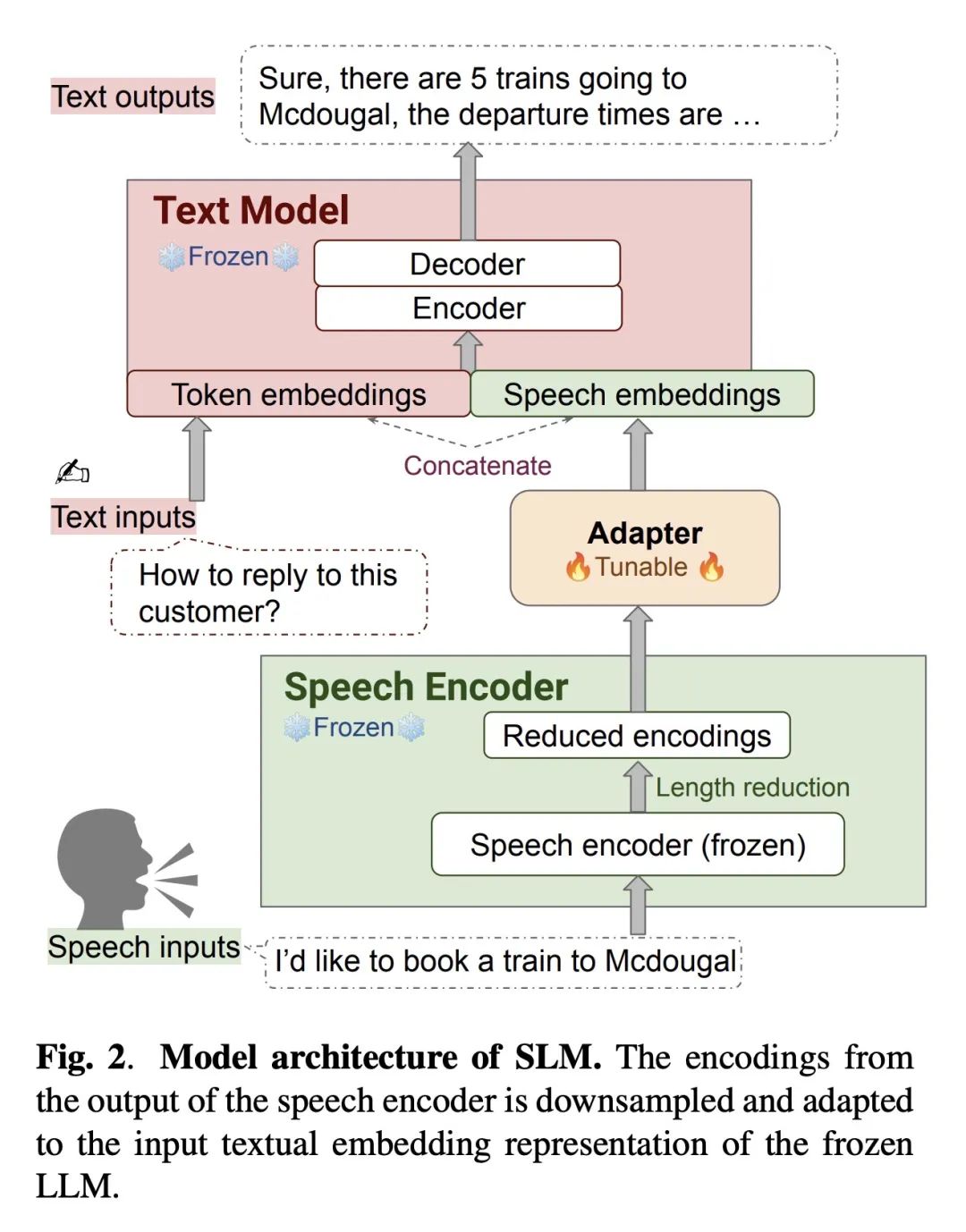
1 、[CL] SLM: Bridge the thin gap between speech and text foundation models
M Wang, W Han, I Shafran, Z Wu, C Chiu, Y Cao, Y Wang, N Chen, Y Zhang...
[Google Deepmind]
通过冻结预训练的语音和文本基础模型,仅训练一个简单的适配器来实现语音和文本之间的桥接,构建了一种高效、多功能的联合语音和语言模型,能实现零样本指令遵循和多任务处理。
一些核心思想有:
2.深度神经网络对于分布外数据倾向于可预测的外推
这是怎么设计实验证明的?有例子吗? 是否指的是倾向于回答分布内的答案?
3.通过任务提示改进Transformer长度泛化
- 4.表示工程——实现人工智能透明度的自上而下方法
如何实现从黑箱到白箱的过程?
5.人工反馈并非黄金标准
人工反馈的缺陷有哪些?
要点:
-
仅使用基础模型参数的1%(156M)来训练简单的适配器,基础模型保持冻结。
-
本身语音文本能力强劲,展示了SLM的零样本指令遵循新能力,给出语音输入和文本指令,SLM可以完成未见过的生成任务,如上下文识别、对话、问答等。
-
结果显示语音语言模型的表示鸿沟比预期的更小,浅层adapter即可成功地将语音映射到文本嵌入,实现语音理解。
2 、[LG] Deep Neural Networks Tend To Extrapolate Predictably
K Kang, A Setlur, C Tomlin, S Levine
[UC Berkeley & CMU]
深度神经网络对于分布外的数据倾向于可预测的外推。
通过观察和理论分析,研究发现神经网络在高维超出分布范围的输入上表现出可预测的外推行为(神经网络的预测往往在输入数据变得越来越超出分布范围时趋向于一个固定的常数值,并与最优常数解OCS非常接近),并提出一种利用这种行为实现风险敏感决策的简单策略(使OCS与谨慎的默认输出对齐)。
- 传统观点认为神经网络在面对训练集以外的数据时,预测往往是不可预测的和过于自信的。
- 但是作者发现,随着输入数据越来越不符合训练分布,神经网络的预测往往会收敛到一个常数值。(什么是预测收敛到一个常数值?)
-
这个常数值通常非常接近最优常数解(OCS),也就是在不观察输入的情况下,可以使训练数据平均损失最小化的预测。(也就是说模型本身也有惯性思维?)(是否可以用这个例子?比如分类任务,每个样本都有预测的概率分布,如果将所有概率分布叠加,然后取概率分布最大的那个数,这个数就是OCS)
-
在8个数据集上,"输入分布的转移量"与"模型输出与OCS之间的距离"高度相关(这句话如何理解?),这种相关性贯穿不同的分布变化、损失函数和模型架构。
-
训练集之外的数据往往对应更小的范数(什么意思?)的特征表示,导致预测主要取决于网络的偏置,而偏置往往会累计为OCS。()
-
一种简单的策略是使OCS与谨慎的默认输出对齐,这可以在训练集之外的输入上实现风险敏感的决策。
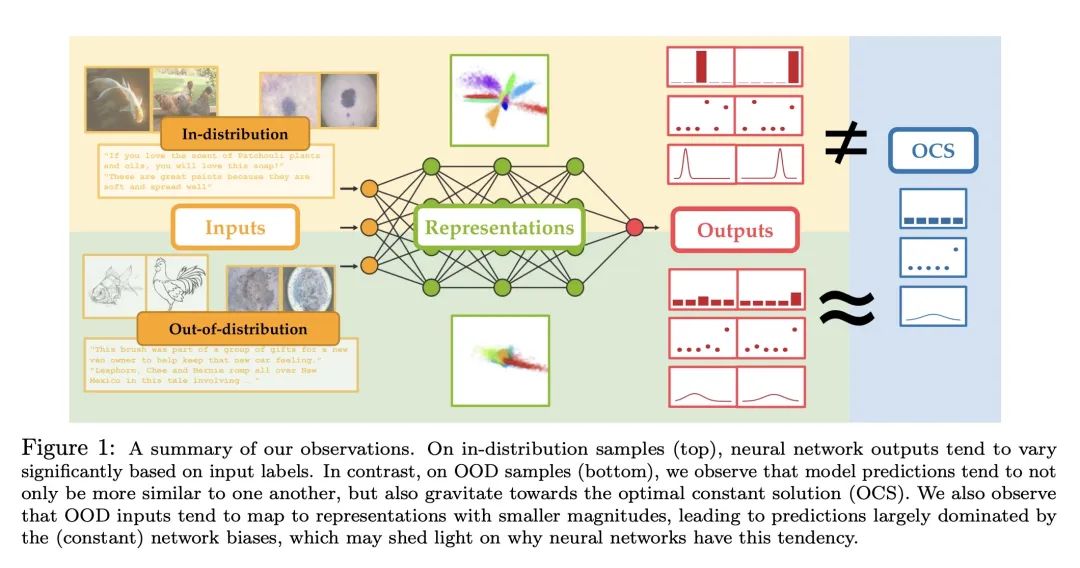
OOD的样本输出的分布非常相似,且接近OCS。可能的原因是:OOD输入倾向于映射到较小幅度的表示,导致预测在很大程度上由(恒定的)网络偏差主导。
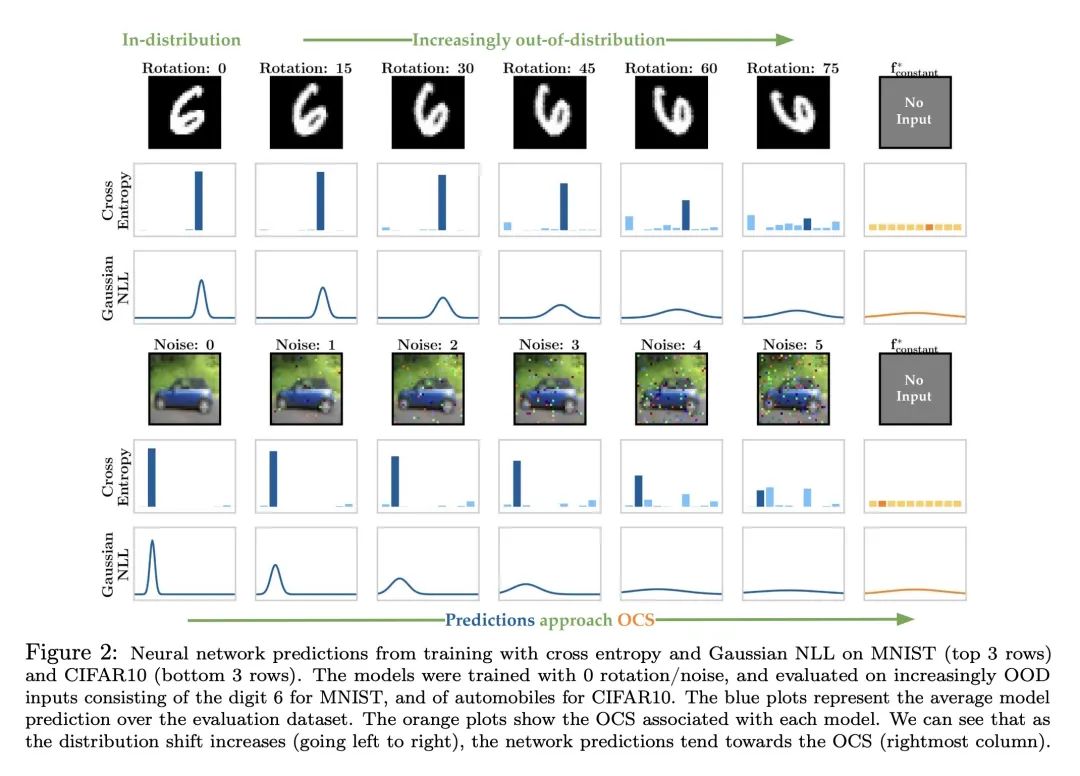
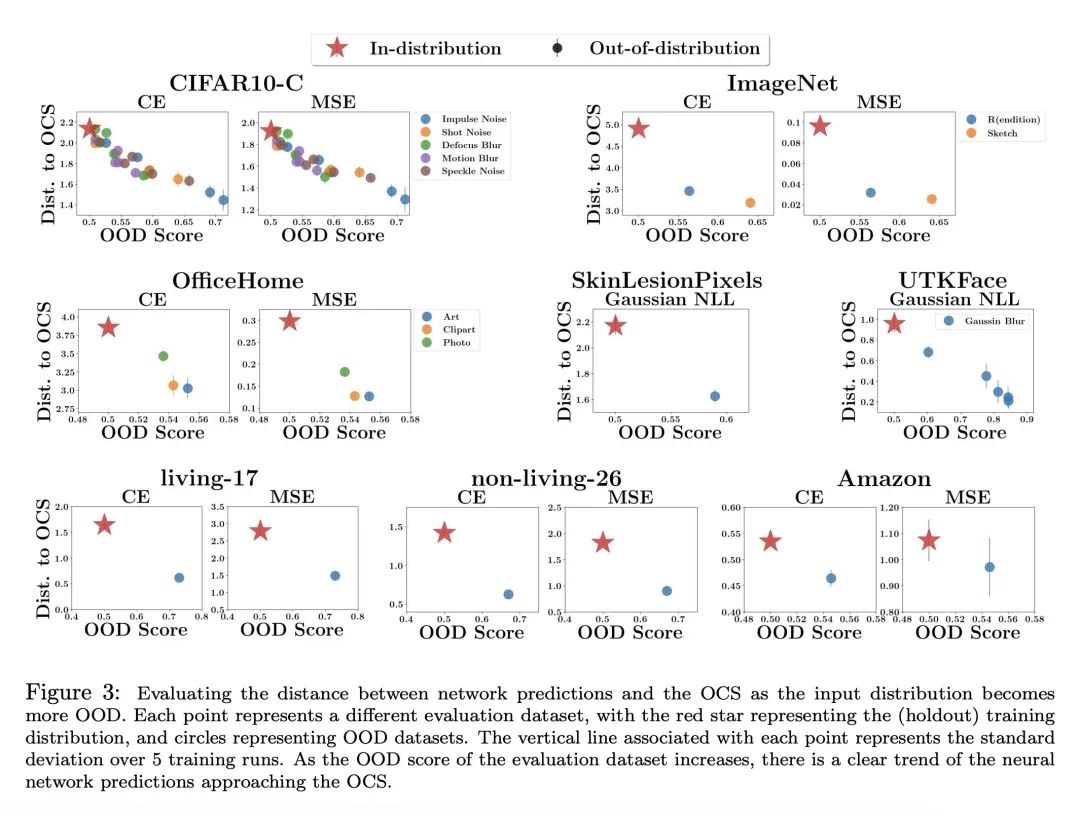
如何构建OOD Score的评价标准?有什么办法可以让OOD Score降低?
3 、[LG] Improving Length-Generalization in Transformers via Task Hinting
P Awasthi, A Gupta
[Google Research & CMU]
通过任务提示改进Transformer长度泛化
-
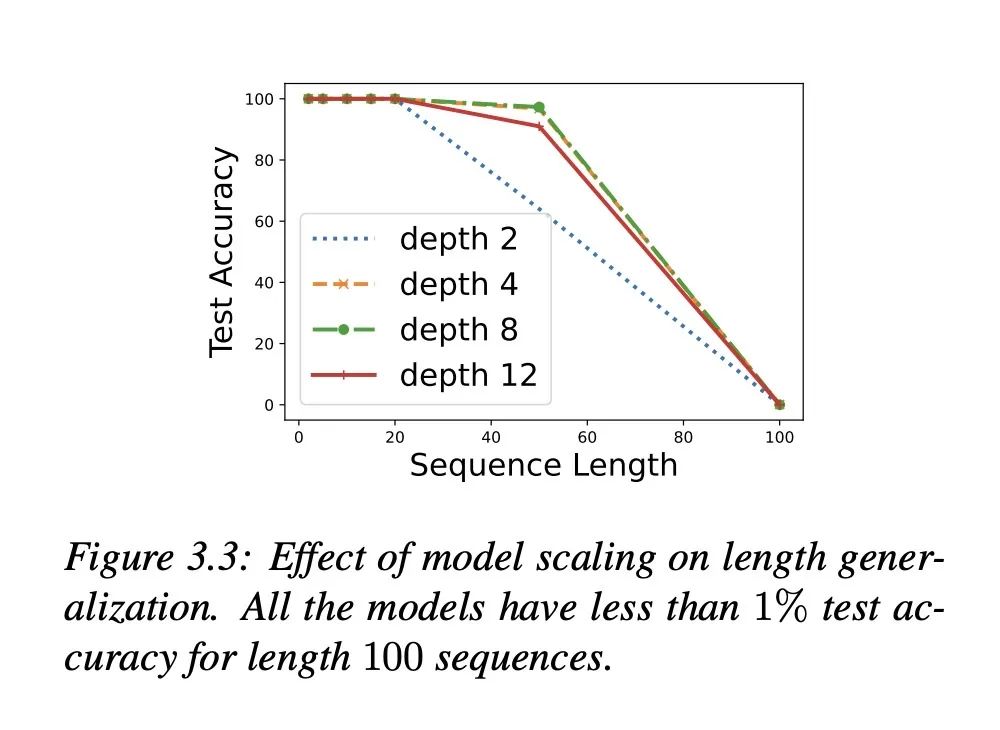
研究发现,对于某些推理和算术任务,Transformer在更长的序列长度上具有泛化问题,即在相同问题的更长实例上,训练在一定长度上训练的Transformer模型的性能显著下降。
-
本文提出任务提示的方法,在训练模型同时主任务(例如排序)和相关的简单辅助任务(例如找出后继元素)。
-
以排序作为典型例子。在长度达20的序列上训练模型,在长度100上测试。标准训练在长度100上的准确率低于1%,而任务提示可以达到高于92%。(对于流式的手语问题可能有启发,是否能够设置辅助任务,使得流式的准确率提高?)
-
并非所有辅助任务都同样有效。对于排序任务,找出后继元素帮助最大,计数帮助最小。
-
可视化显示网络学习解决该任务的偏置机制(什么是解决该任务的偏置机制?),与这种偏置一致的辅助任务最有效。
-
(带有权重的关键点,例如“你好”中主要是用手进行操作,所以手部和手臂的关键点要突出)
-
(拼接视频,拉长Vlen,从而进行多语言翻译。)
-
网络似乎(怎么通过实验和可视化看出这个假设?)通过首先找到最小元素,然后计算后继来解决排序,这解释了为何找出后继很有帮助。
-
引入理论分析所提出的长度相关参数可进一步提升长度泛化。
-
在整数增量任务中(什么是整数增量任务?),任务提示也改善了泛化,显示出更广泛的应用潜力。
方法:本研究使用任务提示的方法,即在训练模型解决特定任务的同时,同时训练模型解决一个更简单但相关的辅助任务。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









