






 本文介绍了如何使用vue和docxtemplater库在前端生成并下载word文档,包括模板制作、数据填充、图片处理等步骤,详细展示了代码实现过程,适合需要前端生成word的开发者参考。
本文介绍了如何使用vue和docxtemplater库在前端生成并下载word文档,包括模板制作、数据填充、图片处理等步骤,详细展示了代码实现过程,适合需要前端生成word的开发者参考。
vue + docxtemplater 实现前端生成并下载word
文章目录
前言
平时工作中需要将多条数据以word形式下载,手动去实现太麻烦,耗时又耗力,然后在网上查了下,发现有符合我需求的插件,记录一下实现过程。
一、docxtemplater介绍
docxtemplater是一款强大的 Word、Powerpoint 和 Excel生成插件,它以编程方式使用并处理条件、循环,并且可以插入图像、html或表格。
基础语法
普通标签:{name}

**循环标签(“#”开始, “/”结束)**:{#table}{/table}
图片标签:{%img}
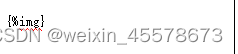
二、使用步骤(包含图片)
1.导入包
npm install docxtemplater
npm install pizzip
npm install file-saver
npm install jszip-utils
npm install docxtemplater-image-module-free
2.页面引用
import docxtemplater from "docxtemplater";
import PizZip from "pizzip";
import JSZipUtils from "jszip-utils";
import { saveAs } from "file-saver";
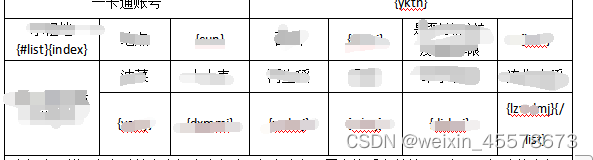
3.制作模板
模板:

实现:

4.实现代码
//测试数据
let item = {
nzy:'',
Illegal:'',
imgPath:'https://fuss10.elemecdn.com/e/5d/4a731a90594a4af544c0c25941171jpeg.jpeg',
imgPath1:'https://fuss10.elemecdn.com/e/5d/4a731a90594a4af544c0c25941171jpeg.jpeg'
}
let docxData = {
nzy:item.nzy,
Illegal:item.Illegal,
imgPath: await that.getBase64Sync(item.imgPath), //图片转base64需要解决异步 async await
imgPath1: await that.getBase64Sync(item.imgPath1)
}
var ImageModule = require('docxtemplater-image-module-free'); //没有图片可以去掉这一段
//*注*模板文件存放位置:vue-cli2在static文件夹下,vue-cli3在public文件夹下,文件后缀名为'.docx'
JSZipUtils.getBinaryContent('file.docx', function (error, content) {
if (error) {
throw error
};
// 图片处理开始
let opts = {}
opts = {
//图像是否居中
centered: false
};
opts.getImage = (chartId) => {
return that.base64DataURLToArrayBuffer(chartId);
}
opts.getSize = function(img, tagValue, tagName) {
//自定义指定图像大小
return [200, 150];
}
//图片处理结束 没有图片可去掉这一段
var zip = new PizZip(content);
var doc = new docxtemplater()
doc.attachModule(new ImageModule(opts)); //没有图片可以去掉这一段
doc.loadZip(zip);
//获取数据
doc.setData({
...docxData
});
try {
doc.render()
} catch (error) {
var e = {
message: error.message,
name: error.name,
stack: error.stack,
properties: error.properties,
}
console.log(JSON.stringify({
error: e
}));
throw error;
}
var out = doc.getZip().generate({
type: "blob",
mimeType: "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
})
saveAs(out, "文件名.docx")
})
}
base64DataURLToArrayBuffer(dataURL) {
const base64Regex = /^data:image\/(png|jpg|jpeg|svg|svg\+xml);base64,/;
if (!base64Regex.test(dataURL)) {
return false;
}
const stringBase64 = dataURL.replace(base64Regex, "");
let binaryString;
if (typeof window !== "undefined") {
binaryString = window.atob(stringBase64);
} else {
binaryString = new Buffer(stringBase64, "base64").toString("binary");
}
const len = binaryString.length;
const bytes = new Uint8Array(len);
for (let i = 0; i < len; i++) {
const ascii = binaryString.charCodeAt(i);
bytes[i] = ascii;
}
return bytes.buffer;
}
getBase64Sync(imgUrl) {
var xhr = new XMLHttpRequest();
xhr.open("get", imgUrl, true);
// 至关重要
xhr.responseType = "blob";
xhr.onload = function () {
if (this.status == 200) {
//得到一个blob对象
var blob = this.response;
console.log("blob", blob)
// 至关重要
let oFileReader = new FileReader();
oFileReader.onloadend = function (e) {
// 此处拿到的已经是 base64的图片了
let base64 = e.target.result;
let image = new Image();
image.src = base64;
let canvas = document.createElement("canvas");
canvas.width = image.width;
canvas.height = image.height;
let context = canvas.getContext("2d");
context.drawImage(image, 0, 0, image.width, image.height);
//返回
resolve(base64);
};
oFileReader.readAsDataURL(blob);
}else {
console.log(imgUrl)
}
}
xhr.send();
},
总结
以上就是今天要讲的内容,本文仅仅简单介绍了部分功能的使用,而docxtemplater提供了大量能使我们快速便捷地处理各类型文件的方法。
https://docxtemplater.com/docs/get-started-node/
https://www.jianshu.com/p/0de31429b12a


















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









