







逻辑回归的损失函数
无正则项
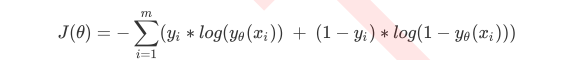
添加正则项
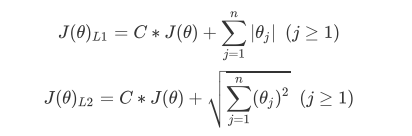
sklearn.linear_model.LogisticRegression (penalty=’l2’, dual=False, tol=0.0001, C=1.0,fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver=’warn’, max_iter=100,multi_class=’warn’, verbose=0, warm_start=False, n_jobs=None)
1.penalty
可以输入"l1"或"l2"来指定使用哪一种正则化方式,不填写默认"l2"。注意,若选择"l1"正则化,参数solver仅能够使用求解方式”liblinear"和"saga“,若使用“l2”正则化,参数solver中所有的求解方式都可以使用。L1会将某些特征系数压缩至0,L2会将某些特征系数压缩至接近0。
2.C
C正则化强度的倒数,必须是一个大于0的浮点数,不填写默认1.0,即默认正则项与损失函数的比值是1:1。C越小,损失函数会越小,模型对损失函数的惩罚越重,正则化的效力越强,参数会逐渐被压缩得越来越小。
3.max_iter
设置最大迭代次数,该参数默认100,可以不设置,如果在100次迭代之后未找到最有解会有提示,这时再修改最大迭代次数,使用属性.n_iter_可以调用本次求解中真正实现的迭代次数。
4.multi_class
1.ovr
表示分类问题是二分类,或让模型使用"一对多"的形式来处理多分类问题。
2.multinomial
表示处理多分类问题,这种输入在参数solver是’liblinear’时不可用。
3.auto
表示会根据数据的分类情况和其他参数来确定模型要处理的分类问题的类型。比如说,如果数据是二分类,或者solver的取值为"liblinear",“auto"会默认选择"ovr”。反之,则会选择"multinomial"。
注意:默认值将在0.22版本中从"ovr"更改为"auto"。
5.solver
1.liblinear
坐标下降法,支持L1 L2,不能处理multinomial,惩罚截距项,对未标准化数据很有用
2.lbfgs
拟牛顿法的一种,利用损失函数的二阶导数矩阵(海森矩阵)来迭代优化损失函数,只支持L2,不惩罚截距项,对未标准化数据很有用
3.newton-cg
牛顿法的一种,利用损失函数的二阶导数矩阵(海森矩阵)来迭代优化损失函数,只支持L2,不惩罚截距项,对未标准化数据很有用
4.sag
随机平均梯度下降,每迭代一次仅仅用一部分的样本来计算梯度,只支持L2,不惩罚截距项,数据需标准化,在大型数据集上更快
5.saga
随机平均梯度下降的进化,稀疏多项逻辑回归的首选,支持L1 L2,不惩罚截距项,数据需标准化,在大型数据集上更快
6.class_weight
用参数class_weight对样本标签进行一定的均衡,给少量的标签更多的权重,让模型更偏向少数类,向捕获少数类的方向建模。该参数默认None,此模式表示自动给与数据集中的所有标签相同的权重,即自动1: 1。当误分类的代价很高的时候,我们使用”balanced“模式,我们只是希望对标签进行均衡的时候,什么都不填就可以解决样本不均衡问题。
但是,sklearn当中的参数class_weight变幻莫测,很难去找出这个参数引导的模型趋势,或者画出学习曲线来评估参数的效果,因此可以说是非常难用。我们有着处理样本不均衡的各种方法,其中主流的是采样法,是通过重复样本的方式来平衡标签,可以进行上采样(增加少数类的样本),比如SMOTE,或者下采样(减少多数类的样本)。对于逻辑回归来说,上采样是最好的办法。
下面给出完整的逻辑回归建模过程,特征工程只给出Embedded嵌入法的过程,wrapper包装法如出一辙这里不详细说明
以上两个方法参考https://blog.csdn.net/weixin_45580742/article/details/104472866
from sklearn.linear_model import LogisticRegression as LR
from sklearn.feature_selection import SelectFromModel
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
from sklearn 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1442
1442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









