






此文根据【QCON高可用架构群】分享内容,由群内【编辑组】志愿整理,转发请注明出处。
2015年4月25日尼泊尔发生了8.1级地震,很多古建筑群遭到了严重损毁。 百度发起“See You Again,加德满都”通用用户上传的照片, 进行尼泊尔古迹复原行动,其中用的技术就是三维全景重建。
这次我们邀请到杭州得图的技术专家给大家讲解三维全景重建的技术。
孙其瑞,得图技术总监
负责得图的图像技术以及服务后端的技术架构。 曾负责游戏服务端引擎、游戏平台,垂直电商平台等工作。
在了解三维全景的实现之前我们先了解一下什么是三维全景图片重建。
什么是三维全景图片重建
第一种是三维全景图片,就是我们常看到的街景。通过相机360度拍摄的多张照片拼接成一个全景图像。 当然街景是通过硬件一次成像。硬件成本比较高。像现在的VR眼镜就可以用来浏览三维图像,给人以立体感。
算法整体思路如下图:(插图1)
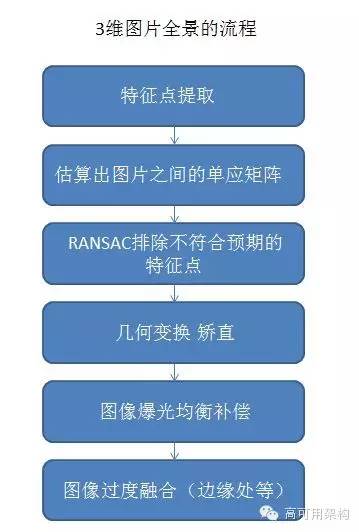
第二种是三维模型的重建,不知道各位还记得百度推出一个大家一起三维重建尼泊尔古迹,用的就是这种技术,当你的图片越多,图片视角越多,形成的三维模型理论上是最精确,三维模型的重建,根据二维的图像的光照、相机信息(比如说每个相机型号都有这么一个ccd)等等(插图2)
摄像机标定(指的是3D到2D的一个对应关系,对于前面的得到的一个摄像机内部参数信息等等,假设图片与三维的物品存在一种关系,那么我们就知道2D的投影)。 再基于sift特征点重建(通过每个摄像机的发也射线交点进行重建), 经过RBF神经网络进行学习优化点坐标,再纹理映射等形成三维模型。
下面是随机的一组二维图片例子(丽水的应星楼),变成3D模型的例子。不过这个重建过程很花时间的,要大量的计算。(插图3)

这是重建后的结果(插图4)

下面主要讲第一种三维全景图片在移动端怎么做。
如何打造一个三维全景拍照工具
我们的大体思路是这样,通过陀螺仪知道图片的基本的三维关系,然后提取特征点算出单应矩阵修正陀螺仪的误差,最后再处理各种光线边缝融合问题。虽然理论上听起来似乎比较简单,但实际操作中会有很多算法性的问题。特别是手机的性能问题。(插图5)
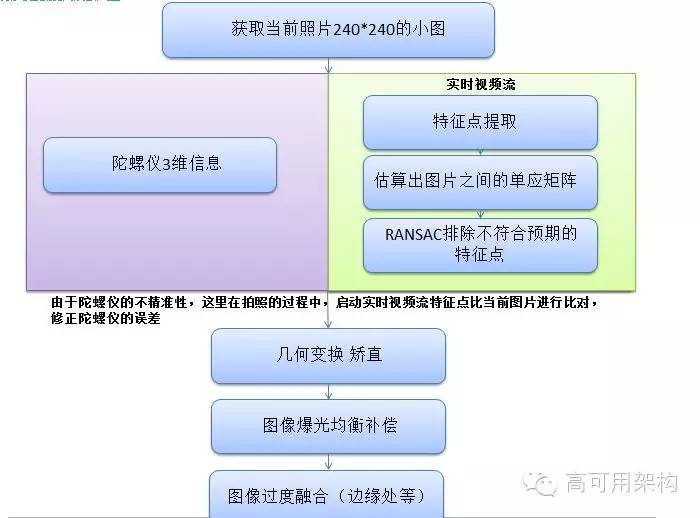
上面图说明了整体的移动端拍照工具的思路。
那我们会遇到什么问题呢,又该如何解决。以下是根据我们的流程,列出的几个问题:
问题1
对于移动端拍照,我们可以根据陀螺仪的位置关系,就能知道图片之间三维的关系,但不幸的是,陀螺仪本身就是不可靠的,特别是在水平方向,误差特别大,那么我们如何对陀螺仪实时校准?特别是特征点不足或者本身就误差了,引起的单应矩阵就有问题,如何处理?
解决方法:当我拍第二张照片的时候,会在后台启动视频进行实时的特征点检测,并进行单应矩阵运算,用来实时修正陀螺仪的误差,这样看上去似乎解决了问题,但是存在问题,比如说由于特征点不足或者本身就存在误差时,那得到的单应矩阵肯定也就是错误的,所以我们要进行更多的概论运算。
第一步 找出两张离得最近照片的中心陀螺仪的角度,并且认为在三维坐标体系中,两者之间不能超过45度,否则不进行修正。
第二步 将所有特征点进行直方图算法运算,我们尽可能找出在直方图最密集的特征点区域,那这个最密集区域我们再进行均值处理,我们就能得到我们认为比较靠谱的单应矩阵与特征点对应信息,当特征点信息点不足3个的时候,我们会认为这个特征点检测失败了。
第三步 当修正三维中一个图片的三维信息后,图片周边的处理角度平移处理。
问题2
特征点提取有 surf,sift,fast 等等方法,在移动端怎么选型,以及他们各个的差异在哪里?性能如何优化?
解决方法 关于surf,sift,fast这个特征点的算法介绍很多,只说说我们的经验,sift最为稳定, 但是效率也是最低的。surf的效率居中,但他对动态像素处理会更好(只是个人实验的一个结果),fast这些对于不同场景适应性比较差,所以我们最后选择了surf算法。
在手机里面,当然不能直接拿拍的图进行实时检测,这样会性能会很低,所以会进行金字塔算法的缩略处理,尽可能保证原精度,因为缩略后,会造成一定的单应矩阵信息不精确,所以我们会利用概论的一些统计手段得到我们认为最优的解。比如上面所说的直方图算法。
问题3
当我们拍照的时候,对着阳光与背着阳光的时候,两张图片产生爆光度不同,那我们如何让图像合成光线过度起来很柔和?(插图6)

如上所示,此为比较典型的爆光度不同,就算边缘问题不太明显,但是爆光的原因,导致效果不好。在移动端处理图片的性能,是没办法跟PC机比的,这个算法比较复杂,优化比较多的地方,CPU计算尽可能进行整型运算,重复性的利用起GPU帮你预处理一部分。
解决方法 我会先建立好一个大画布,把这个画布当成mask处理,然后对区域内的所有边隙处进行mask标记,然后再对mask进行过度性处理,然后再进行gamma叠加。
一些其它算法问题
由于经常会做像素点在球面投影上面的转换。比如 p(x,y) * sin A 等等,会产生小数点的像素。通过插值算法,让打点在球面上面的时候,如何让像素的精度提到最高。
解决方法 我们会根据Lanczos算法进行插值去算。Lanczos算法是一种将对称矩阵通过正交相似变换变成对称三对角矩阵的算法,以20世纪匈牙利数学家Cornelius Lanczos命名。Lanczos算法实际上是Arnoldi算法对于对称矩阵的特殊形式,可应用于对称矩阵线性方程组求解的Krylov子空间方法以及对称矩阵的特征值问题。
还有一些其他的问题,优化过程中的,金字塔降采样图片算法,中值滤波等等。
Q&A
Q1:三维模型重建是否可以用在美女网购试衣服的场景,解决现在网购无法看到衣服穿在自己身上效果的问题?
对于这个问题,我们要得到更多的自己的多视角数据,把你多个方位的图片上传到服务器,服务器可以对你的图片进行三维重建,基于特征与摄像机定们,去判断出你的整体体征结构。然后把你的体征贴到一个做好的3D模型上面进行重建。
Q2:金字塔降采样这个你们一般进行几次降采样?就是假设一个512*512的图像,我要得到一个1024*256这种不再任何一个金字塔之间的。
降采样标准都不一样的,一般进行4次采样比较多。如果这种情况,我们会通过插值运算,让图像尽可能不失真。
Q3:图像的模式识别,比如黄图识别,有没有什么开源的解决方案?
开源的方案不清楚。将图片提取颜值信息、还有图像内容的轮廓信息,然后进行训练,看是不是是我们常看到的一些黄图特征。然后还可以根据,通过图像训练,把人体的三点进行更多的特征信息,这样就可以像人脸识别一样去识别一些关键部分。
Q4:特征点是怎么得来的?一张图片,算法是怎么知道哪些像素是特征点,哪些不是呢?
它的局部邻域具有一定的模式特征。事实上,特征点是一个具有一定特征的局部区域的位置标识。得到特征点的算法很多。有surf,fast,sift,gftt,brisk等等,可以满足你的要求。
Q5:镜头畸变在没有预处理或者镜头参数的时候,如何还原畸变?有可能完全消除畸变带来的拼接误差么?
镜头畸变在硬件那端都会有畸变参数的,根据他们的光学投射方式,简单的算法还原。像我们这次要做两路摄像头硬件。他们的畸变其实就是一圈一圈的外围点,查表然后进行三角运算。
推荐大家可以看看这本书,差不多的主流图像技术都在里面(插图7)

感谢国忠的记录与整理,Carson的公众号文章编辑,其他多位编辑组志愿者对本文亦有贡献。更多关于架构方面的内容,请长按下面图片,关注“高可用架构”公众号,获取通往架构师的宝贵经验。
















 159
159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









