






RocksDB 社区提到在 7.5.3 版本在修复 Compaction 计算问题之后优化效果十分明显。Kvrocks 社区贡献者 @zhaoxiaobiao 对此进行验证,证明了新版本 Compaction 过程写入性能的确很平稳,十分值得期待。
Kvrocks 的社区用户 Juan Crescente 在 RocksDB 社区的 Google Group 里发起了一个讨论: Performance of compactions (kvrocks)[1],主要的意思是 RocksDB 在大批量持续导入数据场景下 Write Stall 会导致服务不可用:
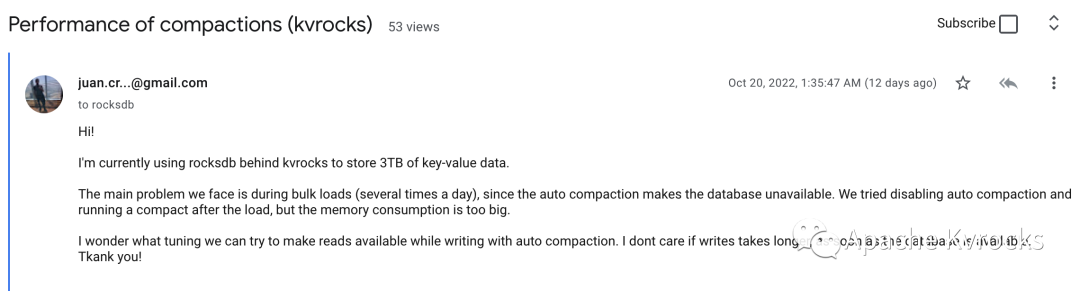
RocksDB 社区的 Mark 回复可以尝试 7.5.3 版本,该版本大大优化了 Compaction 的 Write Stall 时间,具体如下:

Kvrocks 社区的贡献者 @zhaoxiaobiao[2] 之前也遇到过类似的问题,对于该优化十分感兴趣,尝试验证之后将测试数据结果分享到社区。 从整体测试结果来看,RocksDB 7.7.3 的 Compaction 过程对于写入 QPS 和延时基本没有影响,而对比组的 RocksDB 6.29.5 在 Compaction 期间 QPS 会几乎掉到 0。
带来这个优化的主要原因是 RocksDB 7.5.3 修复了一个 Compaction Pending Bytes 计算放大的问题,具体见: rocksdb #issue 9423[6]
测试环境
分别使用 RocksDB 6.29.5/7.7.3 编译 Kvrocks,然后按照如下图部署测试环境: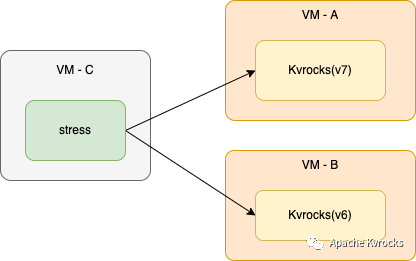
其中 VM - A 和 VM - B 配置都为:
CPU: 4 核
内存: 32 GiB
磁盘: 890G NVME SSD
压测机器 VM - C 是 4 CPU / 8GiB 内存并使用 memtier_benchmark 作为客户端来给 Kvrocks 写入数据。
具体命令如下:
docker run -d --rm redislabs/memtier_benchmark:latest -t 2 -c 20 -s 172.27.255.231 -p 6666 --distinct-client-seed --key-minimum=100000000 --key-maximum=10000000000 --random-data --data-size=10000 -n 10000000000 --command <span data-raw-text="" "="" data-textnode-index-1667281312502="36" data-index-1667281312502="1048" data-textnode-notemoji-index-1667281312502="1048" class="character">"set __key__ __data__<span data-raw-text="" "="" data-textnode-index-1667281312502="36" data-index-1667281312502="1069" data-textnode-notemoji-index-1667281312502="1069" class="character">"其中 memtier_benchmark 的 -c -t 参数是多次实验后,综合吞吐量和超时后选定的最优解。同时设置了定时任务,每隔两小时向 Kvrocks 发起一次手动 Compact 请求 (也可使用 Kvrocks Compact Cron)。
测试结果
以下是来自 @zhaoxiaobiao 的测试数据,对比图统一使用绿色线表示 RocksDB 6.x (6.29.5) ,使用黄色表示新版本 RocksDB 7.x (7.7.3)。但由于篇幅有限,下面展示对照组中的差异指标:
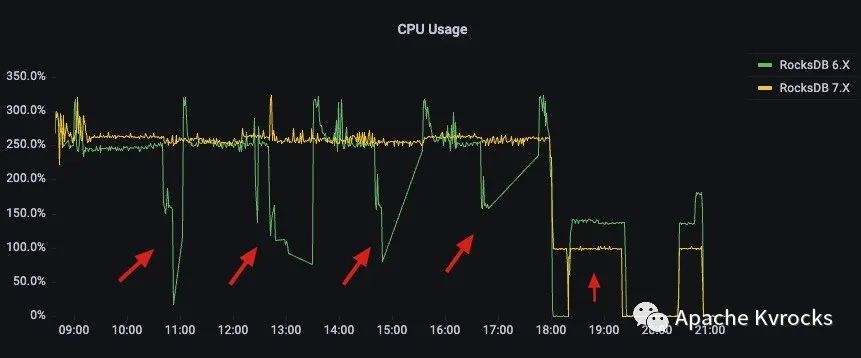
CPU 对比
从 CPU 来看,Compaction 期间 RocksDB 6.x 波动范围比较大,波谷主要是由于 6.x 的 Compaction 和写入有锁竞争导致 CPU 利用率急剧下降,而 7.x 几乎没有波动。同时,最后一段时间停掉写之后,7.x 的 Compaction 的 CPU 利用率也比 6.x 少 40% 左右。
OPS 对比
从 OPS 的对比来看, RocksDB 6.x 的 OPS 波谷和 CPU 几乎是一致的,Compaction 期间可能会几乎掉到 0,而 7.x 则是十分稳定。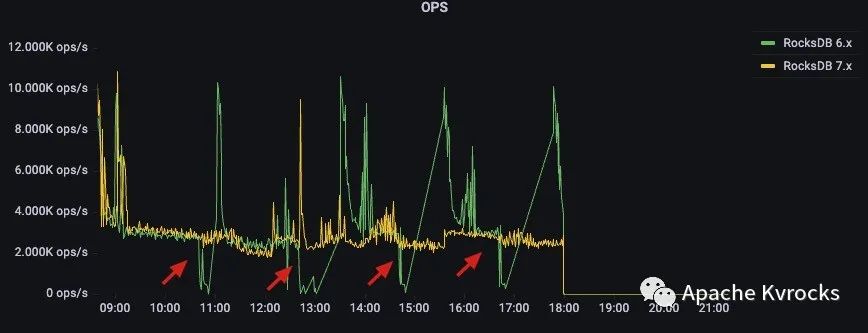
延时对比
同样,RocksDB 6.x 的延时在 Compaction 期间也会有剧烈的波动,而 RocksDB 7.x 则表现十分平稳,甚至低到在对比图中几乎看不到。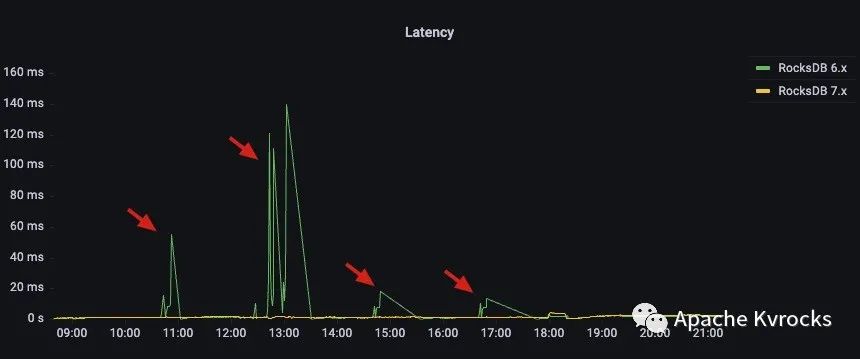
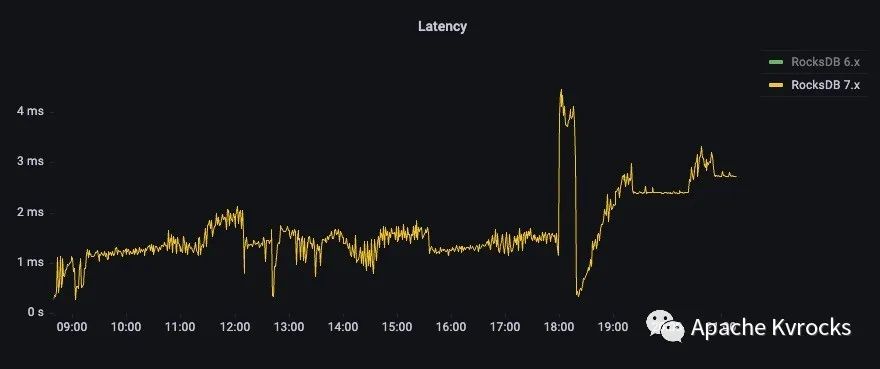
为了可以更清楚看到 7.x 的延时情况,下图把 RocksDB 6.x 去掉,可以看到新版本的延时几乎没有波动。
Compaction 耗时对比
同样的数据量,RocksDB 7.x 会比 RocksDB 6.x Compaction 的持续周期会更长一些。说明了 RocksDB 7.x 除了锁优化之外,也将后台的 Compaction 相关的周期拉得更长来规避影响正常的读写请求。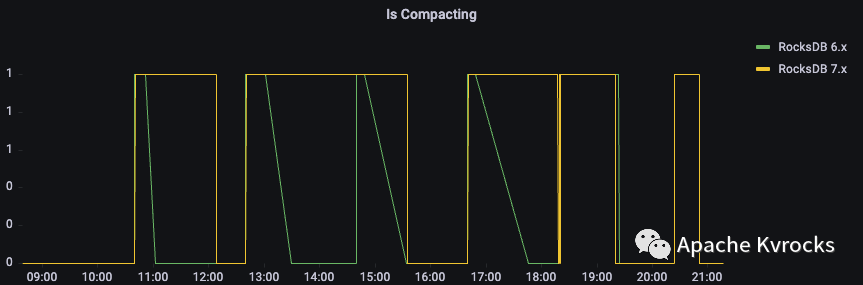
其他关键指标
从 Estimate Keys 数量以及 DB 大小来看,两个版本存储的数据量比较接近,整体上符合预期。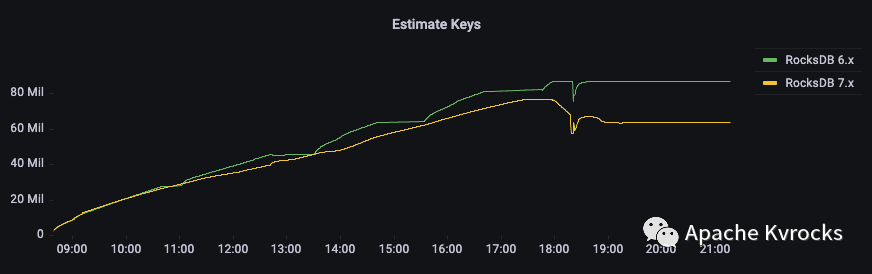
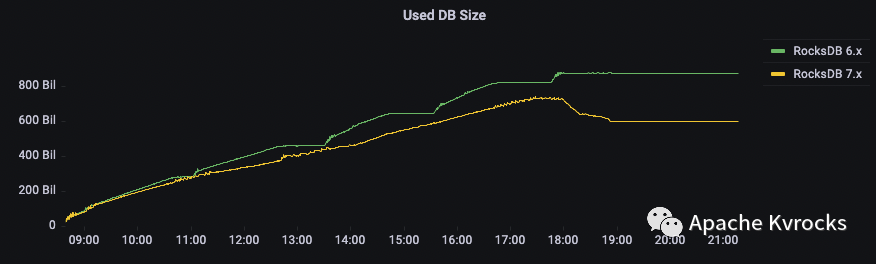
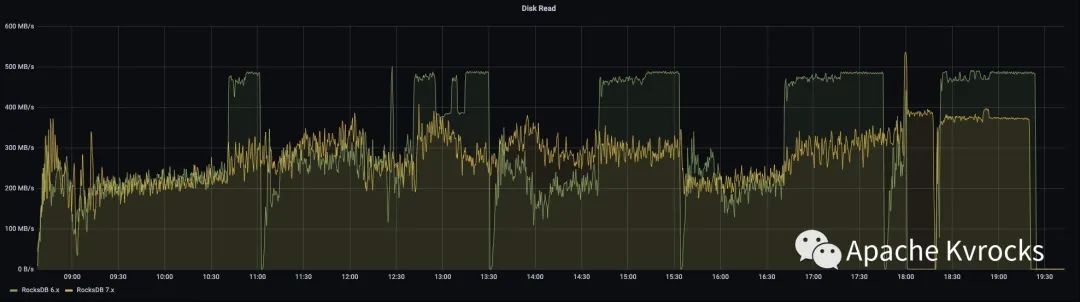
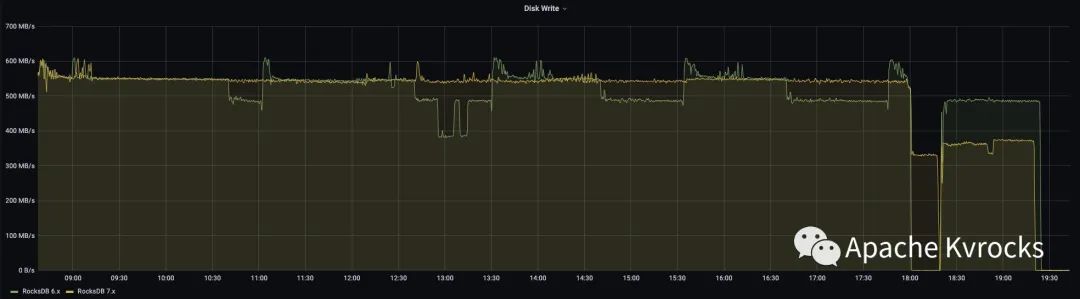
磁盘读写也印证了 RocksDB 7.X 在 Compact 策略上会比 6.x 更加缓和,从本次测试结果来看几乎对于实时读写没有造成任何影响。
总结
从以上单次的压测数据来看,RocksDB 7.x 版本的 Compaction 几乎没有对写入造成太大影响。主要优化来自两方面:
RocksDB 修复了 Compaction Pending Bytes 计算放大问题导致长时间 Write Stall 问题,具体讨论见: rocksdb #issue 9423[6]
减少了 Compaction 和写入的锁竞争,从而规避了 Compaction 期间阻塞写入问题
其实在更早之前 @aleksraiden[3] 就在 Kvrocks 社区发起过将 RocksDB 升级到 7.x 的讨论: Change RocksDB to 7.х?[4],考虑到稳定性以及当时还没有看到明显收益,所以没有继续往前推进。但有了这次具体的测试案例和数据,社区可以更快去推进 RocksDB 7.x 在 Kvrocks 的落地。目前 @zhaoxiaobiao 也已经提了 PR #1056[5],欢迎更多用户的测试和反馈。
参考资料
[1]
Performance of compactions (kvrocks): https://groups.google.com/g/rocksdb/c/umRPboha0as/m/5VP6zvwiCgAJ?utm_medium=email&utm_source=footer
[2]@zhaoxiaobiao: https://github.com/xiaobiaozhao
[3]aleksraiden: https://github.com/aleksraiden
[4]Change RocksDB to 7.х?: https://github.com/apache/incubator-kvrocks/discussions/1013
[5]PR #1056: https://github.com/apache/incubator-kvrocks/pull/1056
[6] rocksdb #issue 9423: https://github.com/facebook/rocksdb/issues/9423
参考阅读:
本文由高可用架构转载。技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。

















 291
291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









