






最近在微信群里看到 @mwish 分享 Amazon 关于 MemoryDB 的论文: Amazon MemoryDB: A Fast and Durable Memory-First Cloud Database[1],读完感觉设计思路挺不错,就将个人在阅读中认为论文里面的一些关键要点记录并分享出来。
MemoryDB 是基于 Redis 开发的内存数据库,主要的目标是解决社区 Redis 在数据一致性以及持久化方面的缺陷。
从产品定位上,MemoryDB 是作为数据库数据库而不是缓存,这一点也体现在命名上,主要解决 IoT / 金融 / 广告这类写入吞吐要求高(每秒百万级别),且延时敏感的业务场景。论文核心是如何通过分布日志系统来解决社区 Redis 存在的持久化以及一致性问题,对于想要实现类似功能的人,从设计到实现思路都可以作为不错的参考。
整体设计
MemoryDB 是 Amazon 在 2021 年开发,Redis 代码还没调整为非开源 License,所以在设计时重点考虑了如何最小化改动 Redis 代码,避免合并 Upstream 代码过于困难。从以下设计图可以看到,MemoryDB 主要改动点是主从复制的部分: 数据同步不再是写入主库后主动同步给从库,而是先写入分布式事务日志系统,再由从库来主动拉取这些变更。
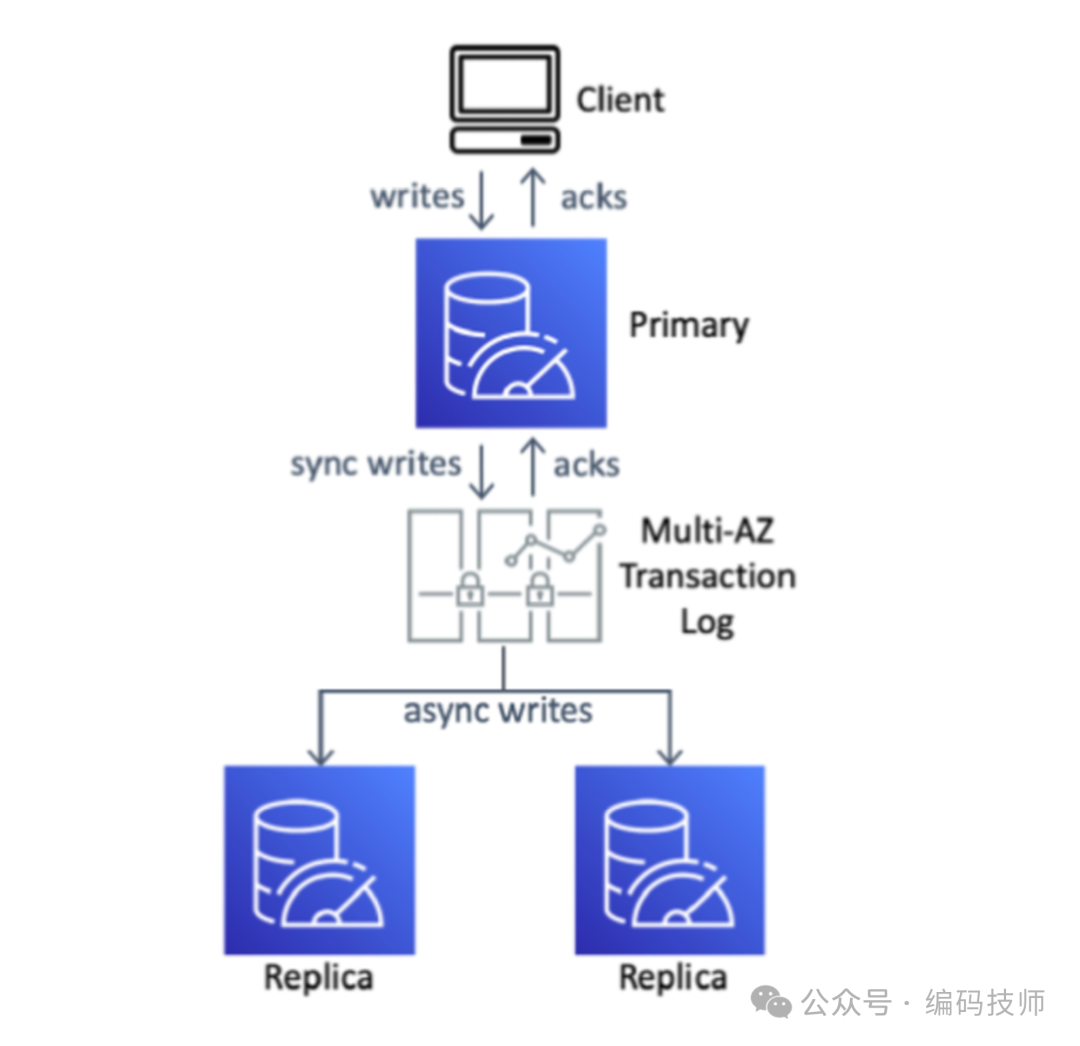
写入和同步流程如下:
对于 Key 变更写入追踪缓冲区(tracker),阻塞写入 Client。注意,这些写入变更再收到分布式日志系统 ACK 之前是不可见的。
提交变更日志到多 AZ 的分布式事务日志系统
写入日志成功之后,主库执行执行追踪缓冲区(tracker)的变更,修改对于 Client 可见并解除写入 写入 Client 阻塞
从库异步主动拉取并回放变更来保持主从数据最终一致
再回到 MemoryDB 的设计目标: 数据强一致和可靠的持久化,那么这个设计如何做到的?
数据的可靠持久化机制主要靠强一致的多 AZ 分布式事务日志服务来保障,写入请求必须等待分布式事务日志服务提交才能返回,从而保障一旦提交就不会丢失。同时主从切换时只有追到最新数据的从库才可能选为新主库。而一致性取决于是否允许读从库:
只允许读主库,可保证顺序强一致
允许读从库,由于从库是异步更新,只能保证最终一致
只允许读主库的场景之所以能够做到顺序强一致,首先是 Redis 命令处理上是单线程,能够天然保证写入分布式事务日志的顺序性。其次,MemoryDB 也对命令读写做了控制优化,变更需要等待提交成功之后才会可见,同时读请求的 Key 如果还未提交也会等待提交后,拿到更新后的值才会返回,两者结合才能做读写线性强一致。
这一点是 Redis 无法做到的,主要原因是 Redis 没有 MVCC 机制,变更会立马生效,其他 Client 会在写入正式被 ACK 之前看到变更。
例子如下:
Client A 发送请求
SET A 2请求并通过 WAIT 命令等待全部从库返回Client B 发送请求
GET A,这是 WAIT 还没返回,但 Client B 看到却是最新值2
也就是 Client B 可以看到 Client A 还没有真正被确认的更新,MemoryDB 在写入分布式事务日志系统之前会将变更放到缓冲区(tracker),其他 Client 如果读到正在写入 Key 需要等待完成才能返回。
而允许多从库只能做到最终一致比较好理解,因为主从复制是通过异步日志同步,所以从库的数据一定是某个时间窗口的数据,而不是最新数据。
另外,论文里面也提到一个细节点是: 对于查询请求会立即执行,但在返回之前需要检查写入缓冲区(tracker),如果读到 Key 刚好正在写入,则延时到写入成功后才能返回。举个例子,Client A 执行 SET A 1 未完成,此时 Client B 请求 Get B 则会立即返回,如果请求 Get A 则需要等待 Client A 写入成功后才能返回。
on-mutating operations can be executed immediately but must consult the tracker to determine if their results must also be delayed until a particular log write completes. Hazards are detected at the key level.
如何恢复数据
设计上可以看到主从同步是通过分布式事务日志系统来实现,那么如果没有其他手段的辅助,实例在重启时就需要全量回放历史变更日志,显然从时间和可用性上都是无法接受。MemoryDB 实现方式是定期创建 Snapshot 的方式来减少需要回放的日志量,也可以理解为 RDB + 增量 AOF:
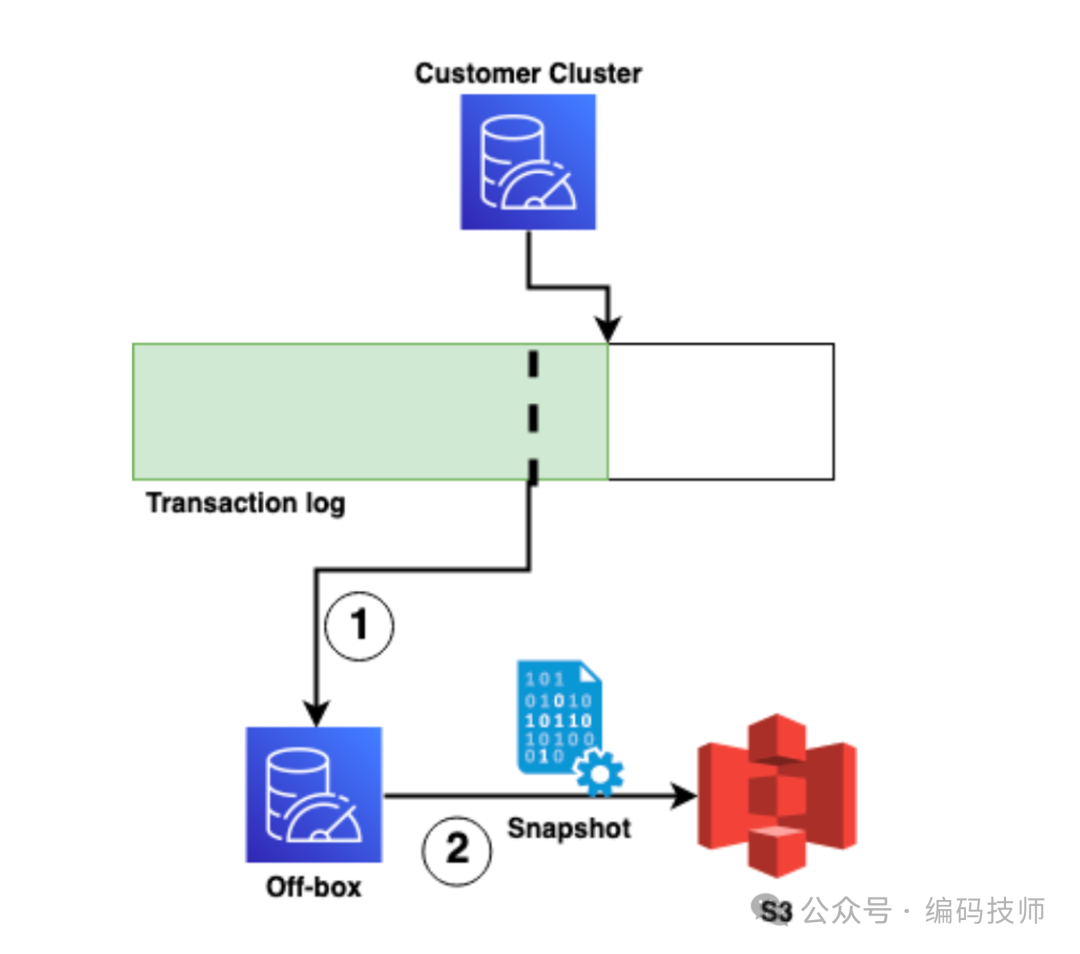
这个过程由外部控制面服务(off-box)来来完成,定时跟据状态来决定是否创建新的 Snapshot(RDB) 并上传到 S3, Snapshot 里会记录分布式事务日志系统的 offset,数据恢复过程是先加载 Snapshot 再从这个 offset 开始回放增量数据。
性能对比
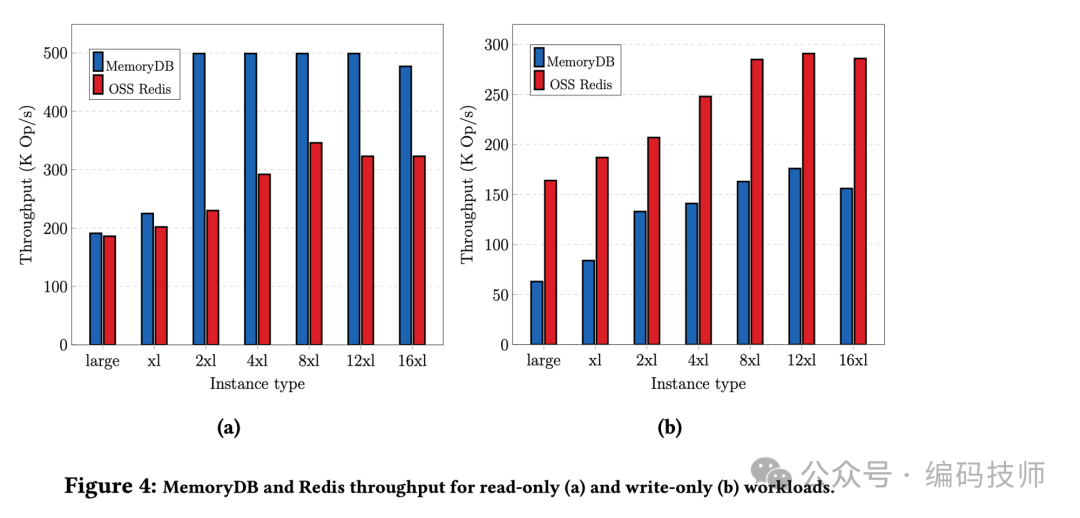
在吞吐方面,只读压测场景 MemoryDB 在 2xlarge 以上的机型比社区 Redis 更好,MemoryDB 峰值 OPS 可以到 500K Op/s 而社区 Redis 大约为 330K Op/s。在只写压测场景,社区 Redis 的性能大约是 MemoryDB 的两倍,主要的原因是 MemoryDB 每次写入都需要提交到分布式事务日志系统,所以延时会更高一些。
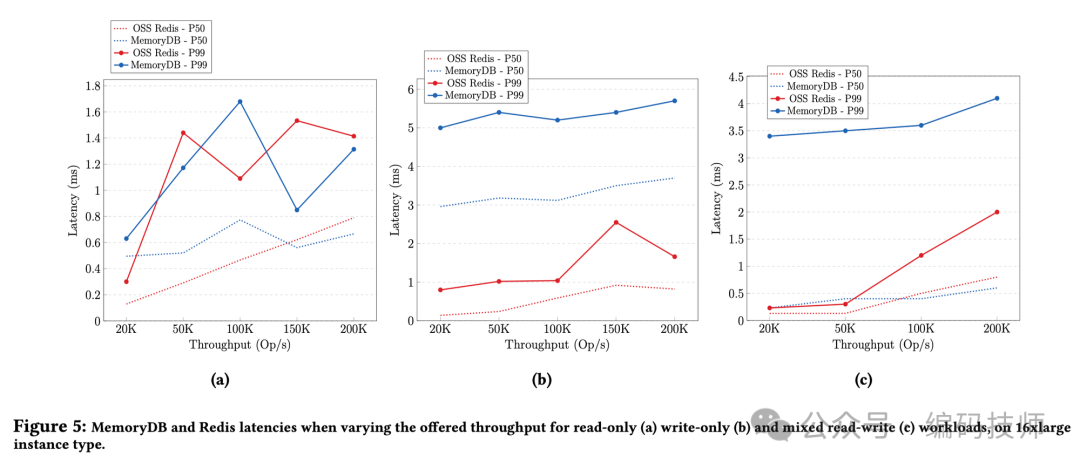
在延时方面,MemoryDB 和社区 Redis 在 P50/P99 在只读延时比较接近(图 a),只写时 MemoryDB 的 P99 约为 6ms,而社区 Redis 是 3ms 左右。混合读写场景,社区 Redis 的延时也比 MemoryDB 低不少,由此也可以推断混合读写场景 MemoryDB 性能也会差一些。
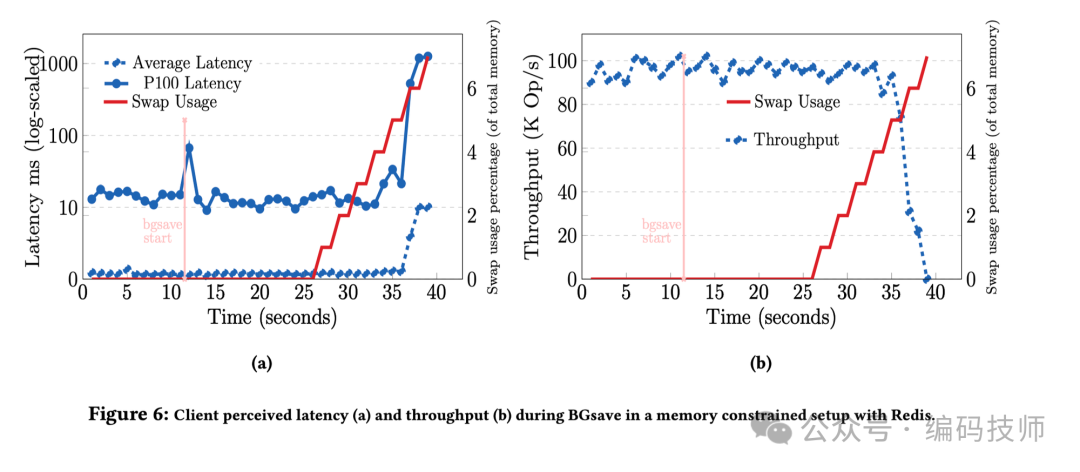
另外,这篇论文还提到了 BGSAVE(生成 RDB 文件) 对于延时的影响,可以看到 BGSAVE 对于平均延时几乎没有影响,但 P100 延时有明显的毛刺点。主要的原因是 BGSAVE 在创建新进程 fork 时内核需要拷贝内存的页表映射,每 GiB 耗时是 12ms 左右。同时,随着红色线上升(COW 导致 SWAP 使用变多) 吞吐和延时都会变差,但实际生产环境建议关闭 SWAP,所以没有太大的参考价值。
最后
除此之外,论文里也提到关于 Slot 迁移以及选主的设计上的调整,选主不再依赖 Cluster Bus 做探测,而是类似 Raft Lease 的方式,一定时间内没有收到 Leader 的心跳日志则发起选主。Slot 迁移过程接近主从复制,将 Slot 对应全部 Key 全部序列化后发送到目标节点,再增量同步新写入的部分。
整体上 MemoryDB 思路是通过分布式事务日志系统来增强 Redis 在数据一致性和持久化的可靠性,同时也牺牲了一些性能。不管是在设计和实现上都很值得借鉴,感兴趣还是直接看论文,点击原文可下载论文。
本文作者 hulk,授权自公众号 编码技师
参考资料
[1]
Amazon MemoryDB: A Fast and Durable Memory-First Cloud Database: https://assets.amazon.science/e0/1b/ba6c28034babbc1b18f54aa8102e/amazon-memorydb-a-fast-and-durable-memory-first-cloud-database.pdf
活动介绍:GIAC全球互联网架构大会于5/24~25日在深圳举行,大会中有更多来自基础架构、AI及大模型精彩案例,点击“阅读原文”了解更多议题。

参考阅读:
本文由高可用架构转载。技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿















 161
161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









