






论文地址
https://arxiv.org/pdf/2112.13977.pdf
1 综述
现有方法试图利用频率信息发掘伪造图片中的细微痕迹,但其利用的频率信息是粗粒度的,无法提取细粒度伪造痕迹。本文提出渐近增强学习框架(PEL)来同时利用RGB和粒度频率信息。具体来说,我们对RGB图像进行细粒度分解,以完全解耦频率中的真假轨迹。随后,我们提出基于双流网络的渐近增强学习框架,结合自我增强和互增强模块。自增强模块基于空间噪声和通道注意在不同的输入空间发现伪造轨迹。互增强模块通过在共享空间维度中进行通信来同时增强RGB和频率特征。
2 背景及相关工作
- 利用频率特征帮助分类DCT 《Thinking in Frequency: Face Forgery Detection
by Mining Frequency-aware Clues》或SRM: 《Generalizing Face Forgery Detection with High-frequency Features》。缺点:提取频率是粗粒度的;要么在网络最后拼接RGB和频率特征,要么在早期进行特征融合,很难完全利用分解的频率信息。 - FDFL链接: 《Frequency-aware Discriminative Feature Learning Super-
vised by Single-Center Loss for Face Forgery Detection》
通过DCT和自适应频率信息提取来利用频率信息,RGB和频率信息在早期融合,很难完全利用分解的频率信息。 - 本文利用: 《Learning in the Frequency Domain》将RGB输入分解成细粒度频率成分。
3 内容
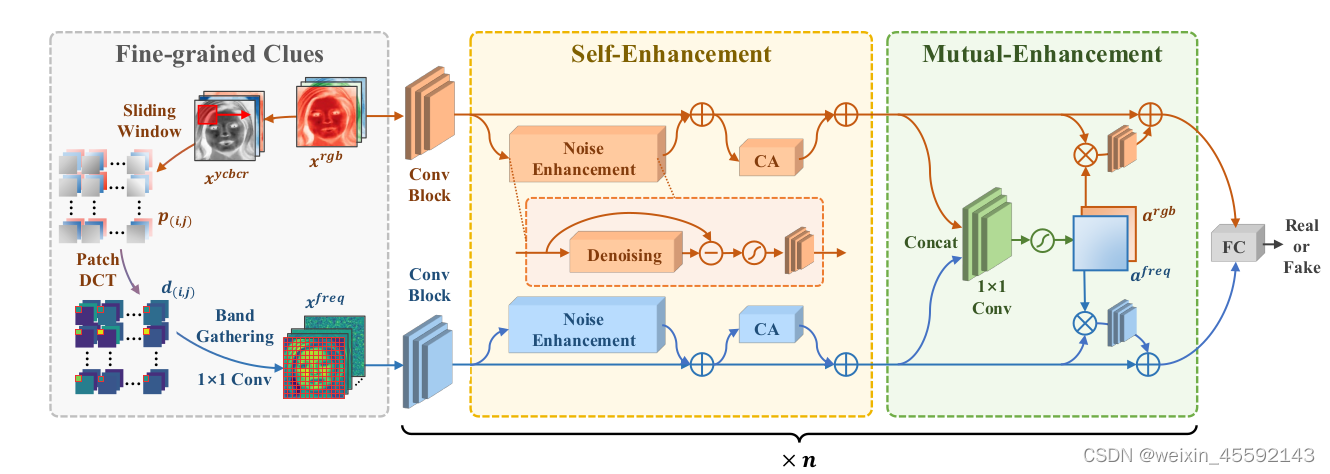 PEL框架:我们将RGB输入转换为细粒度的频率分量,并将它们一起输入到一个以EfficientNet为骨干的双流网络中。主干的每个卷积块后面都有一个自增强模块和一个相互增强模块,以流内和流间的方式逐步增强细粒度线索。
PEL框架:我们将RGB输入转换为细粒度的频率分量,并将它们一起输入到一个以EfficientNet为骨干的双流网络中。主干的每个卷积块后面都有一个自增强模块和一个相互增强模块,以流内和流间的方式逐步增强细粒度线索。
3.1 细粒度频率线索
xrgb(3x H x W)代表RGB图像,将RGB输入转换为与伪造视频中广泛使用的JPEG压缩相一致的YCbCr空间,通过滑动窗口将xyCbCr(3x H x W)切成8×8的patch,每个patch经过DCT处理成8×8的频谱dc(i,j),其中每个值对应于某个频带的强度。我们将频谱扁平化,按照原输入中的patch位置,将同一频率的所有分量组合到一个信道中,形成一个新的输入xflat(192x H2 x W2),H2、W2为滑动窗口的纵向和横向步长数(如果图像是224*224,那么H2=W2=28)。最后,**对频率数据应用1×1卷积层,自适应提取信息量最大的频带,形成细粒度的频率输入xfreq(64x Hx W)**
3.2 自增强模块
自增强模块由噪声增强块和信道注意块两个模块组成,分别对每个流的特征进行增强















 331
331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









