










一、题目描述
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
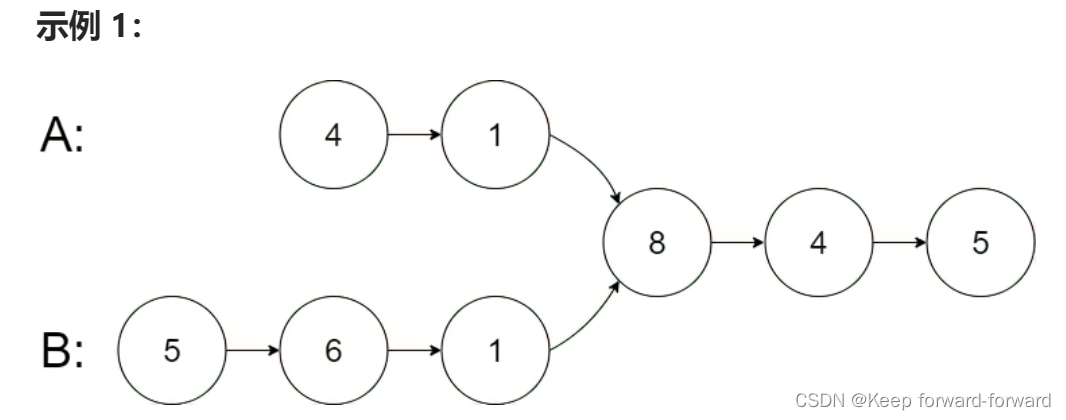
图示两个链表在节点 c1 开始相交:

题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0
listA - 第一个链表
listB - 第二个链表
skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数
skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。

示例2

二、思路解析
1.图解法
思路清晰,代码简洁。
2.哈希集合
判断两个链表是否相交,可以使用哈希集合存储链表节点。
首先遍历链表headA,并将链表headA 中的每个节点加入哈希集合中。然后遍历链表headB,对于遍历到的每个节点,判断该节点是否在哈希集合中:
1)如果当前节点不在哈希集合中,则继续遍历下一个节点;
2)如果当前节点在哈希集合中,则后面的节点都在哈希集合中,即从当前节点开始的所有节点都在两个链表的相交部分,因此在链表 headB 中遍历到的第一个在哈希集合中的节点就是两个链表相交的节点,返回该节点。
如果链表headB 中的所有节点都不在哈希集合中,则两个链表不相交,返回 null。
三、知识点
1.什么是哈希表
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
四、代码
1.图解法java
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) return null;
ListNode pA = headA, pB = headB;
while (pA != pB) {
pA = pA == null ? headB : pA.next;
pB = pB == null ? headA : pB.next;
}
return pA;
}
2.哈希集合C++
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
unordered_set<ListNode *> visited;
ListNode *temp = headA;
while (temp != nullptr) {
visited.insert(temp);
temp = temp->next;
}
temp = headB;
while (temp != nullptr) {
if (visited.count(temp)) {
return temp;
}
temp = temp->next;
}
return nullptr;
}
};
五、总结
1.绘图法复杂度
空间复杂度 O(1)
时间复杂度为 O(n)
2.哈希集合
时间复杂度:O(m+n),其中 m 和 n 是分别是链表headA 和 headB 的长度。需要遍历两个链表各一次。
空间复杂度:O(m),其中 m 是链表 headA 的长度。需要使用哈希集合存储链表headA 中的全部节点。















 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









