




 本文探讨了word2vec在训练词向量时的不足,引出了ELMo的出现。重点介绍了Bert的预训练过程,包括输入结构、损失函数,并阐述了Bert作为预训练模型的两种主要应用方式,既可以用cls层输出做句子向量进行分类任务,也可作为更精准的词向量提升下游任务表现。
本文探讨了word2vec在训练词向量时的不足,引出了ELMo的出现。重点介绍了Bert的预训练过程,包括输入结构、损失函数,并阐述了Bert作为预训练模型的两种主要应用方式,既可以用cls层输出做句子向量进行分类任务,也可作为更精准的词向量提升下游任务表现。
word2vec存在问题:
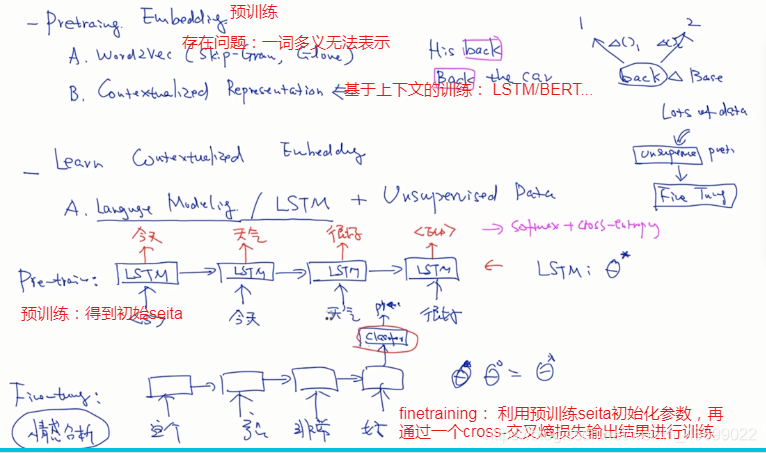
语言模型如rnn、lstm最后输出的是整个句子的向量,而我们需要预测的是其中某个词的向量,所以用其做为词向量训练不合适,
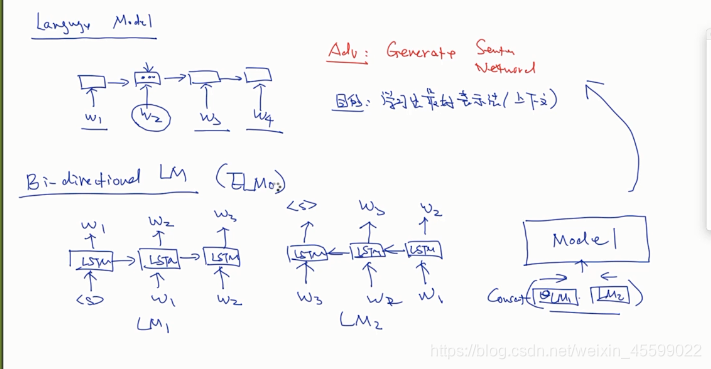
有了双向lstm,即ELMo。
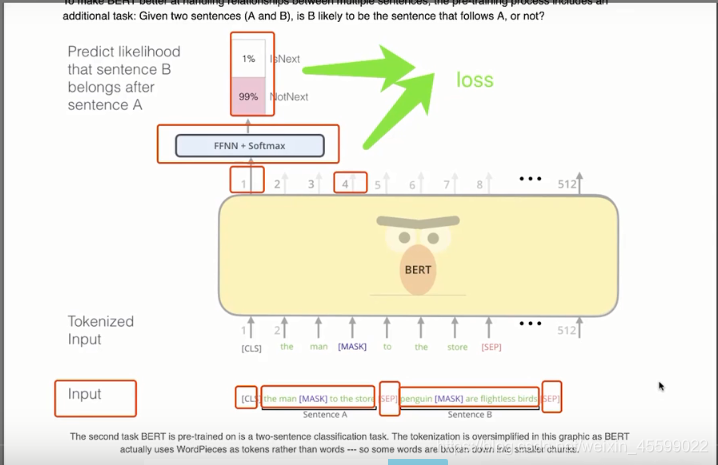
Bert的预训练过程:
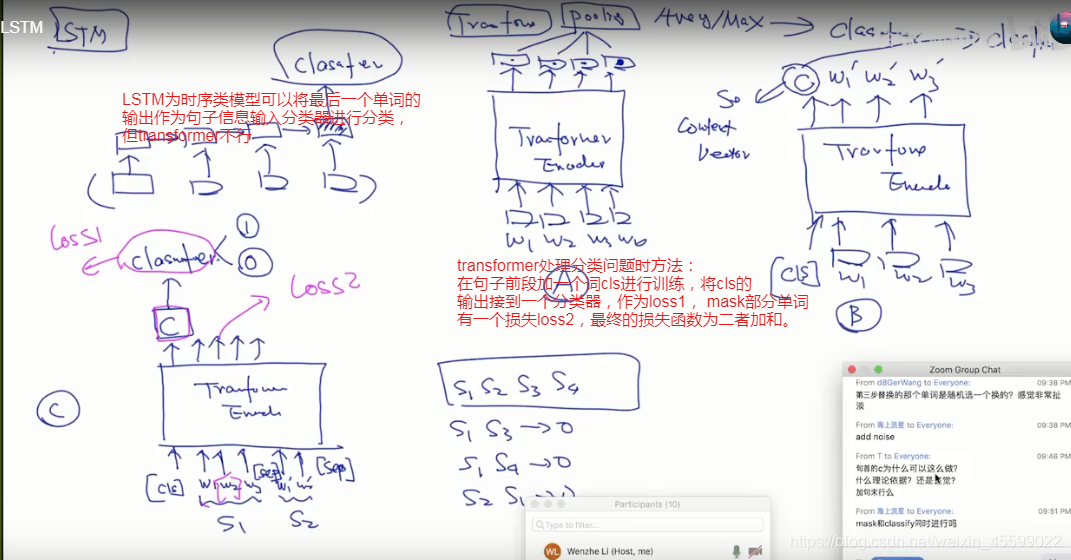
bert:两个句子如果相连则输出0,不相连则输出1,然后将所有句子两两组合输入模型,开头加【cls】第一句【sep】第二句【sep】损失函数为mask单词和句子间关系损失之和。
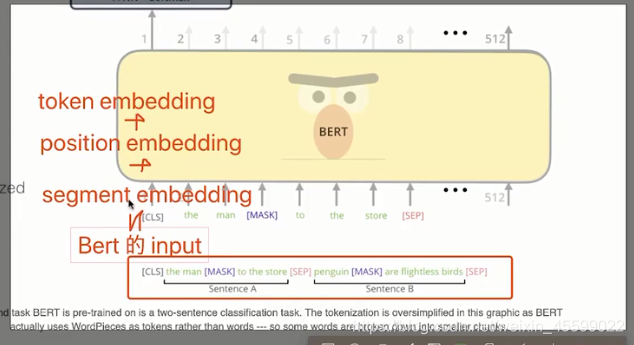
bert作为预训练模型的使用:两种
将cls层输出的向量作为句子的向量,外接一个分类器进行情感分析,主题分类等任务。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1756
1756




 到【灌水乐园】发言
到【灌水乐园】发言







