






1. 大体流程
- 图像前处理
- 模型结构优化(label assignment)和预训练
- 剪枝(剪枝后还要再次训练)
- 知识蒸馏(知识蒸馏和模型剪枝不是一步)
2. 图像前处理
Hist_Equalization
直方图均衡化是使用图像直方图对对比度进行调整的图像处理方法。目的在于提高图像的全局对比度。

此方使得其像素分布更均匀, 具体操作流如下:
1.统计图像中像素值出现的次数 ,并除上imagepixel个数
2.透过"累加概率"的方式来决定某一个直map之后的数值 * 255
ref: https://cloud.tencent.com/developer/article/1408078
https://www.youtube.com/watch?v=GWCB3pKi2ko
CLAHE
上述的HE算法得到的结果存在一些问题,主要包括:
1)部分区域由于对比度增强过大,成为噪点;
2)一些区域调整后变得更暗/更亮,丢失细节信息。
有人提出问题2的解决方法,自适应直方图均衡算法(AHE),基本思想为:对原图中每个像素,计算其周围一个邻域内的直方图,并使用HE映射得到新的像素值。为了能够处理图像边缘的像素,一般先对原始图像做镜像扩边处理。不过这样做计算量偏大,为了减少计算量,一般先把原始图像分为MXN个子区域,分别对每个子区域进行HE变换。但是这样又产生了新的问题,子区域相接处像素值分布不连续,产生很强的分割线。
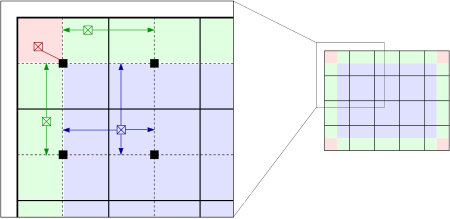
为了解决该问题,有人提出加入双线性插值的AHE,也就形成了完整的CLAHE。算法流程如下:
1)将图像分为多个矩形块大小,对于每个矩形块子图,分别计算其灰度直方图和对应的变换函数(累积直方图)
2)将原始图像中的像素按照分布分为三种情况处理;对比下图,红色区域中的像素按照其所在子图的变换函数进行灰度映射,绿色区域中的像素按照所在的两个相邻子图变换函数变换后进行线性插值得到;紫色区域中的像素按照其所在的四个相邻子图变换函数变换后双线性插值得到
我们主要面对的问题是问题2。
由于Histogram Equalization算法是Global View,考虑一下情况某一个图像中有一个大块区域相对于其他的位置明亮许多,比如一个白色的雕像在昏暗的工作室。由于Histogram Equalization计算方式是累加的,这会使得这块"“明亮区域中的暗区域”"更接近明亮区域,换言之这块大区域将会变成一陀白色的区块,这显然不是我们想要的, 因此 Local View的概念就出来了.
Local View实际就是将图像切成 N * N 的grid, 对于每一个区块进行Histogram Equalization,假设这个区块涵盖noise, 且大量的noise聚焦于某一个pxiel
区间,经过Histogram Equalization后此nosie将被放大, 因此透过contrast limiting来抑制噪声。
传统图像处理中,将图像切成grid很显然也不是一个好的方法,其原因为如果只考虑grid内的信息这会使得checkerboard的现象产生,因此引入双线性插值(ROI ALIGN), 以上就是CLAHE的算法过程,解决了Hist_Equalization Global View带来的影响以及Local View下噪声会被放大的现象,以及仅仅关注grid内所产生的Checkerboard。
ref: https://blog.csdn.net/lwx309025167/article/details/103770834#commentBox
https://docs.opencv.org/4.x/d5/daf/tutorial_py_histogram_equalization.html
3. 模型结构优化与预训练
实际应用模型
Teacher:YOLO V5l
Student:YOLO V5s
Decouple head
所谓的decouple就是检测器的输出尾端分成两个分支,一个是classfication head另一个则是detection head,分开后分别进行数次conv后最终得到相应的输出。
两个任务所聚焦和感兴趣的地方不同,分类更加关注所提取的特征与已有类别哪一类最为相近,而定位更加关注与GT Box的位置坐标从而进行边界框参数修正。
fc-head(fully-connected)更适合分类任务,conv-head更适合定位任务.
这个概念由YOLOX提出,但可把YOLO V5修改成对应样式。
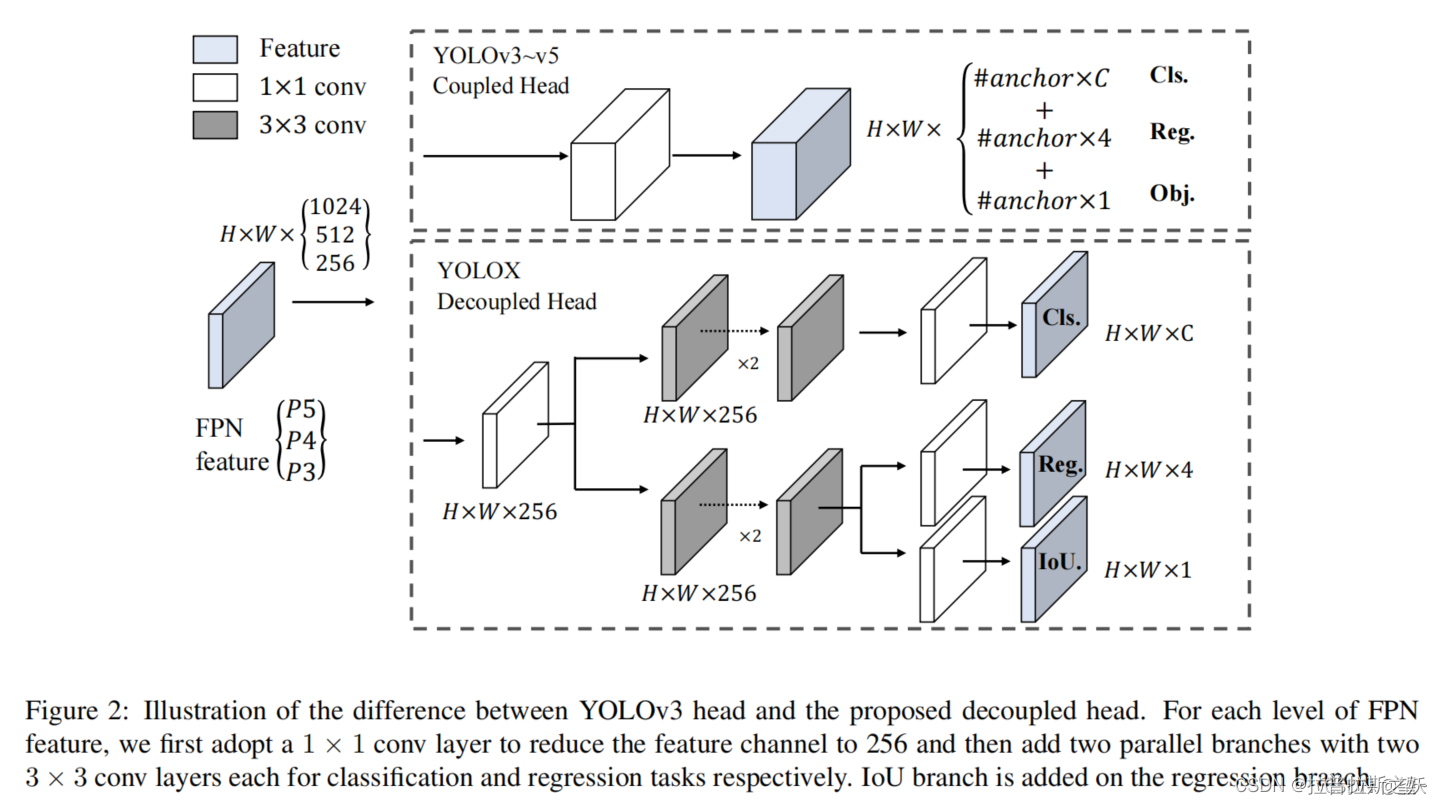
以上这张图就很好的展示了yolox和之前的yolo系列的分类头的区别,对于由backbone得到的特征图,经过一系列降维后,在之前的yolo系列中,关于分类的概率和bbox坐标的预测都是同时完成,它们共享前一层的参数。而在yolox中,他将各个分类任务进行解耦,单独的去预测,不再是单纯的共享前一层参数了。
在论文中提到,实验表明,解耦合检测头能加快模型收敛速度、提高检测精度,同时也会带来一点额外的参数量和计算成本,在YOLOv3 baseline的基础上提升了1.1个百分点的mAP。
其实在GID中就有用到decouple head,但GID论文没细讲。
ref: https://blog.csdn.net/jiacong_wang/article/details/120674145#commentBox
https://www.zhihu.com/question/523790793/answer/2417448320
Anchor based(Yolov5) Anchor free(YOLOX)
Anchor based过程为使用kmeans对所有的gt框进行聚类(K组),挑选出每一层特征金字塔需要使用的anchor大小, 这些anchor则成为候选框来做回归(YOLO V3用的也是这种)。
由于此组anchor数据是Data-specific的换言之就是泛化性较差, 另外由于每一个anchor point 都会配对K组anchor, 这会使得Detector head变得更重,在运行时间有较高要求的场合不一定能落地。
大量的anchor增加了预测输出的复杂度,每个anchor都会输出一个预测结果,并且要配合NMS来过滤无效的预测结果,大量的anchor会带来更大的运算量

kmeans:
初始化:首先决定K是多少组,(如果不确定K,可以透过elbow method来决定), 并随机选择K个点作为中心
循环:
1. 将上一轮的centorid保存
2. 计算其余的点到这K个点的值1 - iou,看跟谁离着最近就将该点打上该类别标签
3. 将每一个类别所拥有的点取上平均,得到新的centorid
4. 将新的centorid跟上一轮的centorid进行对比,如果小于某一个预值,则说明已经收敛否则继续循环
ref: https://blog.csdn.net/cxx654/article/details/124561288
label assignment
YOLO V5的label assignment方法与V3类似。
ref:
重点分析YOLOX的label assignment方法。(待详细了解)
OTA: Optimal Transport Assignment for Object Detection
如何评价旷视开源的YOLOX,效果超过YOLOv5? - 旷视科技的回答 - 知乎 :
剪枝
剪枝大概的实现过程:
1.基于l1 sum和预剪枝和比例参数取得mask, 这个mask会保留的哪些kernels是会留下来, 并保留在dictionary(maskbndict)里面.其key为layer name, value为mask,接着需要将层与层连接起来,我们需要另一个dictionary(from_to_map)来保存上一层的信息,key为layer name, value为上一层的layer name。
2.记录完之后开始循环将mask的节点删去。
关于L1正则化的补充:


L1,L2正则化共通点:让w向零逼近;l1 regularization训练下其权重会相对l2 regularization更稀疏。
4.知识蒸馏
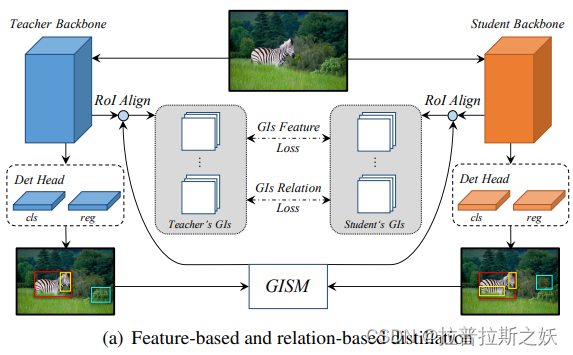
GIs
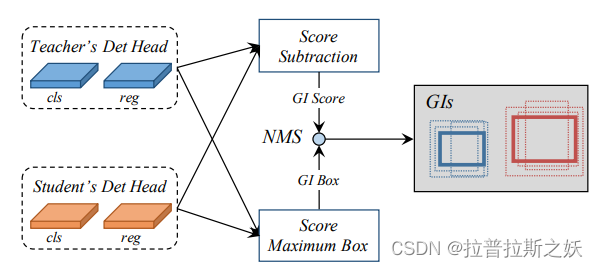
GID知识蒸馏算法中使用了挑选出了学生与老师之间其置信度相差较多的anchor point进行蒸馏。这点与原论文不同,没有使用背景信息!
过去针对目标检测表明跟gt较近的区域的信息量是丰富,此篇作者发现背景区域也是具有相当的信息量,这跟gi score的思想是契合的,蒸馏初期可以发现gi bbox会关注在gt附近, 然而随着训练过程,学生和老师对于gt附近区域的认知愈来愈接近,此时gi score的差距逐渐缩小;因此模型会关注到gt以外的地方,比如具有一定特征的背景; 但是经过实验后发现,gi bbox更多的是关注到具有特征的背景,我们的数据集背景的区域是相对没有信息量的,可能是一些机台结构,可能是地板等,对于想要达到的目的是没有太大的关联性的,因此训练了另一个检测负责检测有料的检测器,并结合原本的检测结果成为我们的gi bbox进行蒸馏。
随着训练过程,所提取到的特征都是动态的。Gi score 为学生与老师置信度的差值, Gi bbox则看学生和老师谁的score较高就选谁的当作Gi bbox.
蒸馏
蒸馏部份分成3个部份, Feature based, Realtion based, Response based。
前两者取的特征是从FPN出来后(进入Head分支以前)的特征块取出gi bbox对应的位置并透过ROI Align萃取特征后进行蒸馏, 最后一个是将head输出的特征进行蒸馏。
Feature based:将teacher 和student的feature经过ROIALign后利用计算loss(MSE)并回归, 至于用ROIAlign的原因为了避免大目标与小目标对于梯度贡献的不平衡。
Relation based: 将teacher以及student分别计算"batch"之间的差异,矩个例子假设现在batch size是2,第一张是大象第2张狮子,对于老师而言假设大象和狮子的差异是x, 我们期待学生对于大象和狮子的差异也可以越接近x愈好.
Response based:将teacher 以及student的head输出进行蒸馏, 由于目检测中存在大量的样本不平衡, 这会使得简单的负样本主导了训练,因此在这边我们使用的label assignment中的fg_masks来筛选出要进行Response based的区域, 这边关于类别的response loss是使用BCE(待详细了解)。
ref: BCE loss 梯度计算















 7816
7816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









