







5.1 系统和设置
首先,我们在 Hyperledger Fabric 1.3 之上实现我们的方法,并将生成的系统命名为 FabricSharp 。我们将FabricSharp与普通Fabric[4]、Fabric++[24]以及我们直接采用数据库到Fabric的OCC技术开发的两个新的系统进行比较。
第一个我们称之为 Focc-s 的系统遵循 [9] 中的标准可序列化 OCC 方法。这种方法考虑了由两个连续的并发读写冲突形成的危险模式,至少有一个反RW。我们修改我们的算法 2,以便立即中止具有 c-ww 冲突或危险模式的传入事务。Focc-s 对块形成没有任何作用。第二个系统是 Focc-l,它使用最近的 OCC 技术 [11],在此基础上我们构建了读写依赖图并将其应用于算法 3 中的基于 Sort 的贪心算法进行重新排序。Focc-l 不过滤算法 2 中的任何事务。
其次,我们在 FastFabric [20] 之上实现了我们的细粒度并发控制,这是一种正交 Fabric 改进,并将生成的系统命名为 FastFabricSharp。我们的目标是研究 FastFabricSharp 在具有低争用的真实生产工作负载上的性能。在两组实验中,我们部署了两个orderer,三个Kafka节点和四个peer点,每个对等点都在配备 Intel Xeon E5-1650 3.5GHz CPU 和 32GB RAM 的物理机器上。机器通过 1Gb 以太网连接。我们将智能合约配置为单个对等方得到认可(执行)。四个对等点中的任何一个都可以作为背书者来传播工作负载。实验至少运行三次,并报告平均值。
系统搭建学习思路
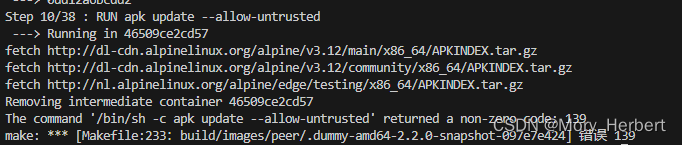
1) 平台搭建(搭建过程中make peer 时出现了证书签名错误)
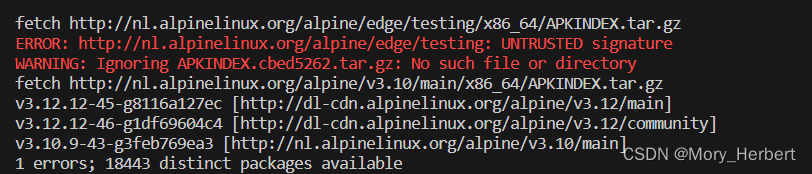
解决方案:https://github.com/ooibc88/FabricSharp/issues/25
仅28行apk update --allow-untrusted

仅56行
56+28行
2) 共识模式切换(solo,kafka),模式切换后在平台运行一遍
3) 优化方案切换,方案切换后(fabric++ ,fabricsharp)执行
orderer/common/blockcutter/scheduler
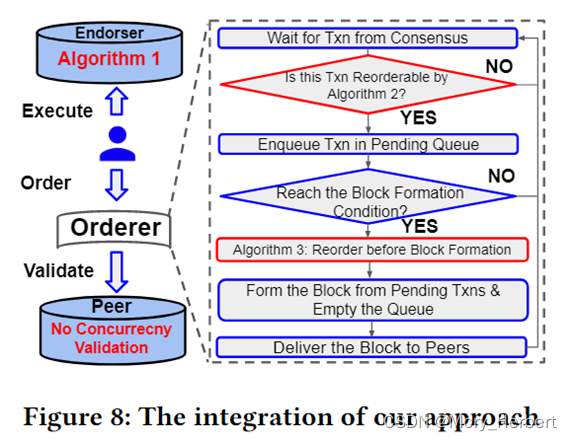
接口和调度规则,明确算法位置和接口
实验演示1
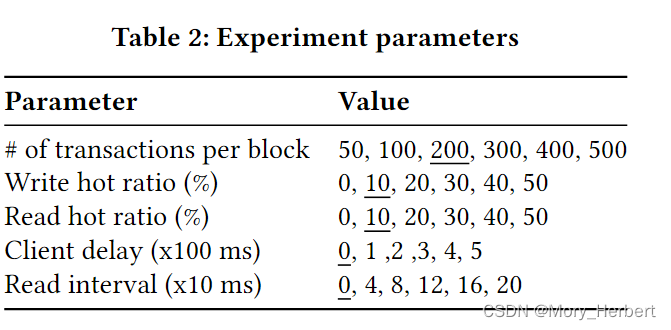
对比1 吞吐量(论文图10左)(区块大小100)
a) 随着区块大小的增加,吞吐量的变化,寻找最大吞吐量
对比2 时延(论文图10右)(区块大小100)
b) 随着区块大小的增加时延的变化
实验演示2
Write Hot Ratio (40%)
c) fabric ++
d) fabricsharp
实验演示3
Read Hot Ratio. (30%)
e) fabric ++
f) fabricsharp
实验演示4
Client Delay.模拟网络传输延迟( 初始值300ms)
g) fabric ++
h) fabricsharp
实验演示5
Read Interval.(80ms)
i) fabric ++
j) fabricsharp
5.2 Workloads and Benchmark Driver
我们使用相同的工作负载来评估基于Smallbank基准测试的Fabric++[24],在 10k 个帐户中,事务读取和写入 4 个银行帐户。我们将它们中的 1% 设置为热帐户。每个读取都有一定的概率访问热帐户,由读取热比参数控制。同样,写入热帐户由 Write 热比控制。我们引入了另外两个工作负载参数,即客户端延迟和读取间隔。前者控制客户端广播的延迟,以便在接收到来自对等体的执行结果后订购器。该参数模拟了客户端的网络传输延迟。后者通过控制连续读取之间的间隔来模拟计算量大的交易。
表 2 列出了所有参数,默认值下划线。我们将 max_span 固定为 10,请求率固定为 700 tp。这是因为 Fabric 在我们的设置中可以维持大约 700 tp 的最大原始吞吐量,如图 1 所示。除非另有说明,所有报告的吞吐量都表示有效吞吐量,它表示通过可序列化检查并持久化其状态的事务。
#caliper的基准文件
smallbankArgs: &smallbank-args
accountsGenerated: 100
txnPerBatch: 1
//Rate Controllers 交易输入区块链系统的速度是性能测试中的关键因素。可能需要以指定的速率或遵循指定的配置文件发送事务。我们允许指定自定义速率控制器,以使用户能够在自定义加载机制下执行测试。
rateControl: &rate
type: fixed-rate
opts:
tps: 20
test:
// Short name of the benchmark to display in the report.
name: smallbank
//Detailed description of the benchmark to display in the report.
//测试说明 要在报告中显示的基准的详细说明。
description: Smallbank benchmark for evaluating create, modify, and query operations.
//Object of worker-related configurations.
workers:
number: 5 //test.workers.number Specifies the number of worker processes to use for executing the workload.与工作相关的配置的对象。
rounds: //test.rounds Array of objects, each describing the settings of a round.
- label: create //test.rounds[i].label A short name of the rounds, usually corresponding to the types of submitted TXs.对象数组,每个对象描述一个回合的设置。
txNumber: 500 //test.rounds[i].txNumber The number of TXs Caliper should submit during the round.
rateControl: *rate
//test.rounds[i].rateControl The object describing the rate controller to use for the
//round.描述用于回合的汇率控制器的对象。
//关于速率控制的细节 https://hyperledger.github.io/caliper/v0.4.2/rate-controllers/
workload:
// test.rounds[i].workload The object describing the workload module
//used for the round.描述用于轮次的工作负载模块的对象。
//基准工作负载模块实现的路径,该实现将构造要提交的 TX
module: benchmarks/scenario/smallbank/create.js
//test.rounds[i].workload.arguments 将作为配置传递给工作负载模块的任意对象。
arguments: *smallbank-args
//回合2
- label: modify
txNumber: 500
rateControl: *rate
workload:
module: benchmarks/scenario/smallbank/modify.js
arguments: *smallbank-args
- label: query
txNumber: 500
rateControl: *rate
workload:
module: benchmarks/scenario/smallbank/query.js
arguments: *smallbank-args
//监视设置
//监视相关 https://hyperledger.github.io/caliper/v0.4.2/caliper-monitors/
monitors:
resource:
- module: docker
options:
interval: 1
containers: ['all']
Rate Controllers:
https://hyperledger.github.io/caliper/v0.4.2/rate-controllers/
Fixed rate 固定速率
Fixed feedback rate 固定反馈速率
Fixed load 固定负载
Maximum rate 最高速率
Linear rate 线性速率
Composite rate 综合速率
Zero rate 0速率
Record rate 记录速率
Replay rate 重播速率
5.3FabricSharp的性能
块大小。
我们首先确定导致每个系统吞吐量最高的块大小,并将这些大小用于其余实验。图 10 显示,当块大小设置为 100 个事务时,FabricSharp 实现了最高吞吐量(542 个 tps)。相比之下,当块分别限制为 200、200、200 和 400 个事务时,Fabric、Fabric++、Focc 和 Focc-l 的峰值性能分别为 411、437、327 和 415 tp。因此,与最先进的Fabric++相比,我们的FabricSharp的吞吐量提高了25%。
与我们的预期相反,Fabric++ 不会在更大的块上实现更高的吞吐量,即使有更多的事务可用于重新排序。我们将其归因于加剧争用的较长延迟,从而导致更多不可序列化的交易。一方面,形成块需要更长的时间。另一方面,块形成之前的重新排序需要更多的时间,因为有更多的事务。例如,我们观察到Fabric++中的重新排序在每个块有50个事务时需要4.3ms,每个块有500个事务时每个块有401ms,。相比之下,由于其轻量级的方法,Focc-l 分别需要 0.12ms 和 5.19ms,即使它类似地构建了一个依赖图。这解释了为什么 Focc-l 的延迟更短,并且在更大的块上表现更好。但是当块大小小于200时,FabricSharp和Focc-s的吞吐量明显高于Fabric、Fabric++和Focc-l。这是因为FabricSharp和Focc在排序过程中重新排序前的阶段施加的预防中止这减轻了验证阶段的拥塞,这是瓶颈。相比之下,Fabric、Fabric++ 和 Focc-l 在块较小的情况下表现出高延迟,因为许多不可序列化的交易都包含在分类帐中,并且它们过载了验证阶段。
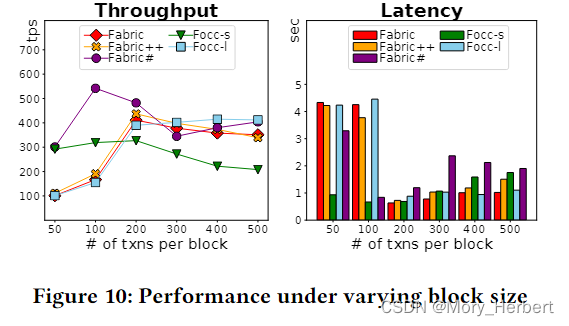
Write Hot Ratio 写热比。为了评估写-写冲突的效果,我们将更多的写操作集中到固定数量的热帐户中。FabricSharp 的吞吐量在所有系统中都最高,如图 11(左)所示。正如预期的那样,由于 Focc-sw 的预防,Focc-s 的吞吐量显着下降。我们还观察到 Fabric++ 的重新排序延迟始终很大,而 Focc-l 中的这种延迟更小并且与增加的偏度成正比。这是因为 Focc-l 轮流遍历轮次中挂起事务的依赖图。在每一轮中,它的基于排序的贪心算法不断修剪事务,直到只有没有依赖关系的事务。相比之下,Fabric++ 计算所有循环并确定要以批处理模式中止的事务。因此,与 Focc-l 相比,它的重新排序过程对工作负载偏度不太敏感。图 11 显示 FabricSharp(算法 3)中的重新排序延迟很低。这是因为FabricSharp在事务到达时将大部分工作(例如,依赖图维护)转移到算法2。我们注意到FabricSharp中重排序延迟的很大一部分(~ 50%)是由于ww冲突的恢复,这个比率随着写热比的增加而增加。
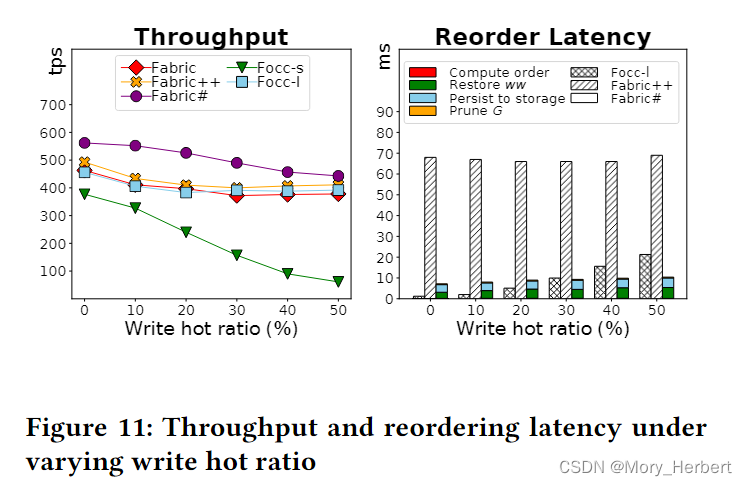
Read Hot Ratio. 读取热比。我们增加了读取热比,以在工作负载中生成更多的读写冲突。如定理3.16所述,这些冲突的依赖循环永远不能重新排序为可序列化。与我们的解释一致,我们在图 12 中表明,除 Focc-s 之外的所有系统的吞吐量都以相似的速率下降。当 50% 的读取请求在热帐户上时,与 Fabric 和 Focc-l 相比,Focc-s 的吞吐量更大。这是因为与 Fabric 和 Focc-l 相比,Focc-s 对可序列化性施加了更严格的条件。Focc-s中止如果事务与至少一个反rw形成两个连续的读写冲突,而其他系统,除了FabricSharp,当只有一个反rw时立即中止。因此,Focc-s 可以恢复更多可序列化的交易,尤其是在繁重的读写争用下。图 12(右)显示了传入事务的处理延迟分解。正如预期的那样,依赖图上的可达性更新采用 FabricSharp 中最大比例的延迟,因为必须遍历来自传入事务的所有可达事务。这种开销随着工作负载中更多依赖关系而增加。与FabricSharp相比,Focc和Fabric++中的事务处理延迟几乎可以忽略不计。然而,Focc-s 需要比 Fabric++ 长一点,因为它需要额外识别冲突的交易,而不仅仅是根据访问的记录索引事务,如 Fabric++ 所示。
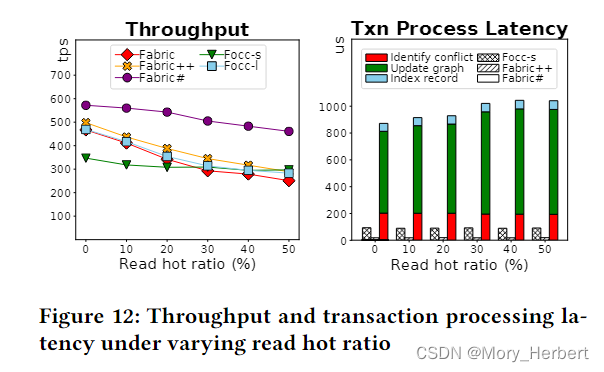
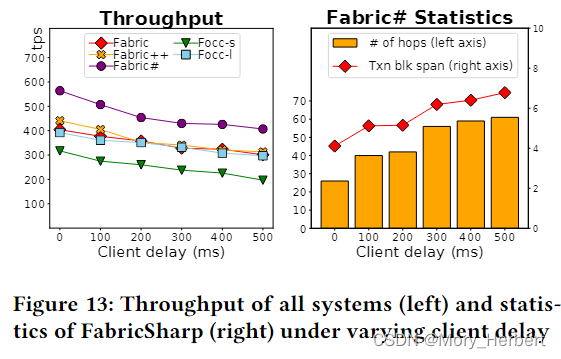
Client Delay.客户端延迟。接下来,我们在客户端模拟网络传输延迟,以研究其对事务的端到端处理的影响。使用客户端延迟参数,我们在执行阶段和排序阶段之间引入了延迟。正如预期的那样,较长的客户端延迟增加了事务的端到端延迟和块跨度。反过来,这会导致较低的吞吐量,如图 13(左)所示。此外,较大的块跨度会导致更多的并发交易和更多依赖关系。如图 13(右)所示,当客户端延迟较高时,FabricSharp 在依赖图中遍历更多的事务来更新它们的可达性(算法 2)。尽管如此,FabricSharp 优于所有其他系统。
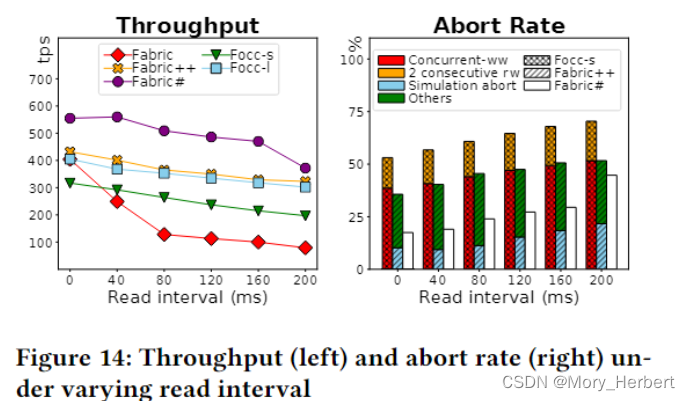
Read Interval. 读取间隔。为了模拟事务产生大量计算的场景,我们在事务执行期间增加连续读取之间的间隔。当事务需要更长的时间来执行时,跨块读取的概率更高。Fabric++ 通过中止跨块读取的事务来防止这种情况,即使有些可能是可序列化的。这可以通过执行阶段早期中止的更大比例的事务来证明,如图 14(右)所示。Focc-s 始终从有效的块快照读取,因此扩展事务执行的效果会导致更高的端到端延迟。这导致更多的并发事务,进而导致 c-w,ww 和 Focc 中的危险模式具有更高的中止率。值得注意的是,随着事务执行较长,vanilla Fabric 的性能急剧下降。我们将此归因于模拟和块提交期间使用的读写锁,以防止并行性。
















 7490
7490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









