







python办公自动化案例目录
- 批量新建excel文件
- 批量打开excel文件
- 批量重命名excel文件
- 合并多个excel文件
- 合并excel文件多个工作表
- 批量拆分excel文件到多个文件
- 批量合并拆分excel数据表
- 两个excel文件的对比
- python批量对Excel实现分列操作
- 批量提取excel所有表的唯一值
- 批量分类汇总excel文件
- 实现多个excel文件的Vlookup
- 实现多个excel表的Vlookup
- 读取多个excel实现汇总统计
- 给学生随机分配考号
- 计算excel销量数据的日同比
- 批量读取word数据到excel
- 读取word统计词频输出到excel
- 读取excel批量生成word文档
- 在网页上展示透视表
- 制作网页查询excel
- 读取excel存储到MySQL
- 查询MySQL导出到excel(新写法,基于sqlalchemy的)
- 读取excel绘制折线图
- 读取Excel自动生成PDF文档-表格中中文乱码
- 读取Excel自动发送邮件
- 批量重命名图片名
- 读取Excel实现线性回归预测
- 课程总结
批量新建excel文件
import xlwings as xw
app = xw.App(visible=True, add_book=False)
for dept in ["技术部", "销售部", "运营部"]:
workbook = app.books.add()
workbook.save(f"./部门业绩-{dept}.xlsx")
批量打开excel文件
import os
import xlwings as xw
# visible=True表示打开excel文件时可见,add_book=False表示不新建工作簿
app = xw.App(visible=True, add_book=False)
# os.listdir(".")表示当前目录下的所有文件
for file in os.listdir("."):
# endswith()方法用于判断字符串是否以指定后缀结尾
# 这里使用的是office365,程序只能打开.xls的excel文件
if file.endswith(".xls"):
# 打开excel文件
app.books.open(file)
批量重命名excel文件
import xlwings as xw
app = xw.App(visible=True, add_book=False)
workbook = app.books.open("部门业绩-技术部.xls")
# workbook.sheets 获取所有的sheet
for sheet in workbook.sheets:
# 替换
sheet.name = sheet.name.replace("销售", "❤")
# 保存文件
workbook.save()
# 关闭文件
app.quit()
合并多个excel文件
import pandas as pd
# pandas模块的作用 读取excel文件 保存到DataFrame对象中 用于数据分析 也可以保存到excel文件中
import os
# os模块的作用 用于文件操作 比如获取文件名 判断文件是否存在 打开文件等
data_list = []
for fileName in os.listdir("."):
if fileName.startswith("部门业绩-") and fileName.endswith(".xls"):
print(fileName)
# read_excel()方法 读取excel文件 返回DataFrame对象 append()方法 将DataFrame对象添加到列表中
data_list.append(pd.read_excel(fileName))
# concat()方法 将多个DataFrame对象按行合并
data = pd.concat(data_list)
# to_excel()方法 保存到excel文件中 index=False 不保存索引
data.to_excel("部门业绩统计表.xlsx", index=False)
合并excel文件多个工作表
import pandas as pd
import xlwings as xw
# sheet_name=None表示读取所有工作表
df_list = pd.read_excel("部门业绩统计表.xlsx", sheet_name=None)
# 将所有工作表合并为一个数据框
df_all = pd.concat(df_list.values())
app = xw.App(visible=True, add_book=False)
workbook = app.books.open("部门业绩统计表.xlsx")
# before=workbook.sheets[0]表示在第一个工作表之前插入汇总表
workbook.sheets.add("汇总表", before=workbook.sheets[0])
# .range("A1")表示从A1单元格开始写入数据 .options(index=False)表示不写入索引 .value = df_all表示写入数据
workbook.sheets["汇总表"].range("A1").options(index=False).value = df_all
workbook.save()
workbook.close()
app.quit()
批量拆分excel文件到多个文件
import pandas as pd
df = pd.read_excel("产品统计表.xlsx")
# .unique()方法可以获取某一列的所有唯一值
products = df["产品名称"].unique()
for product in products:
df_product = df[df["产品名称"] == product]
df_product.to_excel(f"产品统计表-{product}.xlsx")
批量合并拆分excel数据表
import pandas as pd
# 1.批量读取多个工作表
# parse_dates=False表示不将日期类型的数据转换为datetime类型
df_list = pd.read_excel("产品统计表.xlsx",
sheet_name=None,parse_dates=False)
# .head()方法可以查看前几行数据,默认为5行,这里查看前3行
# df_list['1月'].head(3)
# df_list['2月'].head(3)
# 2.批量合并多个工作表到一个工作表
df_all = pd.concat(df_list.values)
# 3.按照采购物品分组,写出到不同的工作表
# 3.1按照采购物品分组
df_group = df_all.groupby('采购物品')
# 3.2遍历分组,写出到不同的工作表
excel_writer = pd.ExcelWriter("采购物品统计表.xlsx"
,date_format='YYYY-MM-DD')
for product,group in df_group:
# to_excel()方法三个参数:excel_writer, sheet_name, index
# excel_writer表示写出到哪个Excel文件
# sheet_name表示写出到哪个工作表
# index=False表示不写出索引
group.to_excel(excel_writer,product,index=False)
excel_writer.save()
两个excel文件的对比
import xlwings as xw
app = xw.App(visible=True, add_book=False)
book = app.books.open("期末考试-学生成绩表.xlsx")
book_backup = app.books.open("期末考试-学生成绩表-备份.xlsx")
# .expand()方法可以扩展到整个工作表的数据范围
for row in book.sheets[0].range("A1").expand():
for cell in row:
# 通过range()方法获取单元格的值
# cell.address获取单元格的地址
backup_cell = book_backup.sheets[0].range(cell.address)
if cell.value != backup_cell.value:
# 通过color属性设置单元格的背景色
cell.color = backup_cell.color = (255, 0, 0)
book.save()
book.close()
book_backup.save()
book_backup.close()
app.quit()
python批量对Excel实现分列操作
import xlwings as xw
import pandas as pd
import os
app = xw.App(visible=True, add_book=False)
directory = "产品记录表"
for fname in os.listdir(directory):
if fname.endswith(".xlsx"):
# os.path.join(directory, fname) 用于拼接路径
# 第一个参数是路径,第二个参数是文件名
workbook = app.books.open(os.path.join(directory, fname))
worksheet = workbook.sheets["规格表"]
# .options()用于指定返回值的类型
# 第一个参数是返回值的类型,第二个参数是扩展参数
# pd.DataFrame表示返回值的类型是DataFrame
# expand="table"表示扩展参数是table
df = worksheet.range("A1").options(pd.DataFrame, expand="table").value
# df["规格"].str用于获取规格列的字符串
# .split()用于分割字符串
# 第一个参数是分割的字符,第二个参数是扩展参数
# expand=True 表示分割后的字符串是多列
split_cols = df["规格"].str.split("x", expand=True)
# 将分割后的字符串赋值给df
df["长"] = split_cols[0]
df["宽"] = split_cols[1]
df["高"] = split_cols[2]
# 删除原先的规格列
# drop()用于删除列或行
# 第一个参数是要删除的列或行的名称,第二个参数是扩展参数
# inplace=True 表示删除后的值赋值给原来的变量
# axis=1 表示删除列,不指定axis默认删除行,axis=0表示删除行
df.drop("规格",inplace=True)
# 将df的值赋值给worksheet
# .range()用于指定赋值的单元格
# .range().value用于指定赋值的值
worksheet.range("A1").value = df
# 保存文件
workbook.save()
# 关闭文件
workbook.close()
app.quit()
批量提取excel所有表的唯一值
import pandas as pd
# sheet_name=None表示读取所有表
df_list = pd.read_excel("采购表.xlsx", sheet_name=None)
# ignore_index=True表示忽略原来的索引
df_all = pd.concat(df_list, ignore_index=True)
# pd.DataFrame()用于创建一个空的DataFrame 接收一个字典作为参数
# list()是一个内置函数,用于将可迭代对象转换为列表
# .unique()用于获取唯一值
df_names = pd.DataFrame({"物品":list(df_all["物品"].unique())})
# .to_excel()用于将DataFrame写入Excel
# index=False表示不写入索引
df_names.to_excel("物品.xlsx", index=False)
批量分类汇总excel文件
import pandas as pd
import os
import xlwings as xw
app = xw.App(visible=False, add_book=False)
for file in os.listdir("销售表文件夹"):
# ~$开头的文件是临时文件,不需要处理
if file.endswith(".xlsx") and not file.startswith("~$"):
wb = app.books.open(os.path.join("销售表文件夹", file))
ws = wb.sheets[0]
df = ws.range("A1").options(pd.DataFrame,expand="table").value
# astype()用于转换数据类型
df["销售表"] = df["销售数量"].astype(float)
# groupby()用于分组
# groupby("销售区域")后面跟[销售数量]用于分组后对销售数量求和
df_agg = df.groupby("销售区域")["销售数量"].sum()
ws.range("J1").value = df_agg
wb.save()
wb.close()
app.quit()
实现多个excel文件的Vlookup
主表👇
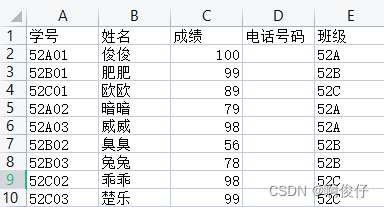
其他的子表,班级学生信息(这里只展示一个子表)👇
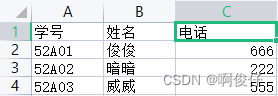
合并之后的学生信息表👇
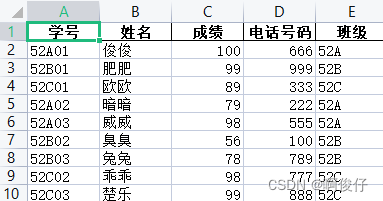
import pandas as pd
import xlwings as xw
import os
import openpyxl
from openpyxl.styles import Font # 导入字体模块
from openpyxl.styles import PatternFill # 导入填充模块
app = xw.App(visible=False, add_book=False)
workbook = app.books.open("成绩表2.xlsx")
# 读取主表数据(成绩表)
df_total = (
workbook
.sheets[0]
.range("A1")
# numbers=int用于将读取的数据转换为整数
.options(pd.DataFrame, expand="table", index=False, numbers=int)
.value
)
# 读取各个班级的学生数据
df_students_list = []
# 从学生信息文件夹读取各个班级的学生数据(每个班级学生表)
for file_name in os.listdir("学生信息"):
if "同学录" not in file_name:
continue
print(f"学生信息文件夹下的xx同学录有:{file_name}\n")
workbook_student = app.books.open("学生信息/" + file_name)
df_student = (
workbook_student
.sheets[0]
.range("A1")
.options(pd.DataFrame, expand="table", index=False, numbers=int)
.value
)
# 添加班级列,当前文件名中提取班级名
df_student["班级"] = file_name.replace("同学录.xlsx", "")
df_student.drop("姓名", axis=1, inplace=True)
df_students_list.append(df_student)
workbook_student.close()
# 合并各个班级的学生数据
df_students_all = pd.concat(df_students_list)
# 合并主表和学生表
# pd.merge()函数用于合并两个DataFrame
# how="left"表示以主表为基准,学生表中没有的数据用NaN填充
# left_on的参数可以填写一个列表,表示以列表中的列为基准合并,left_on表示主表中的列 right_on表示学生表中的列
df_merge = pd.merge(df_total, df_students_all, left_on=["班级", "学号"], right_on=["班级", "学号"], how="left")
df_merge["电话号码"] = df_merge["电话"]
# 删除电话列
df_merge.drop("电话", axis=1, inplace=True)
# 保存合并后的数据
df_merge.to_excel("成绩表(合并后).xlsx", index=False)
workbook.save()
workbook.close()
workbook2 = app.books.open("成绩表(合并后).xlsx")
df_after_merge = (
workbook2
.sheets[0]
.range("A1")
# numbers=int用于将读取的数据转换为整数
.options(pd.DataFrame, expand="table", index=False, numbers=int)
.value
)
# 遍历成绩表中的每一行的成绩
# index表示行号,row表示每一行的数据
for index, row in df_after_merge.iterrows():
# 成绩小于60分的单元格填充红色
# row["成绩"]表示成绩列的值
if row["成绩"] < 60:
# 成绩上标成红色
workbook2.sheets[0].range(f"E{index+2}").color = (255, 0, 0)
# 成绩大于等于60分小于90分的单元格填充黄色
elif row["成绩"] < 90:
workbook2.sheets[0].range(f"E{index+2}").color = (255, 255, 0)
# 成绩大于等于90分的单元格填充绿色
else:
workbook2.sheets[0].range(f"E{index+2}").color = (0, 255, 0)
# 把颜色填充到单元格后,需要保存一下
workbook2.save()
workbook2.close()
app.quit()
实现多个excel表的Vlookup
import xlwings as xw
import pandas as pd
# 启动excel并打开excel
app = xw.App(visible=True, add_book=False)
wb = app.books.open('成绩表.xlsx')
# 读取主表数据:成绩表
df_total = (
wb
.sheets[0]
.range('A1')
.expand('table')
# header=True表示第一行是列名 False表示没有列名
# numbers=int表示数字类型 将数字类型转换为int类型
.options(pd.DataFrame, index=False, numbers=int, header=True)
.value
)
# 读取多个sheet里的学生数据
df_student_list = []
# [1:]表示 从第二个sheet开始读取
for sheet in wb.sheets[1:]:
# {}[sheet.name]表示 读取sheet的名字
class_={
"一班同学录":"一班",
"二班同学录":"二班",
"三班同学录":"三班",
"四班同学录":"四班",
"五班同学录":"五班"}[sheet.name]
df_student = (
sheet.range('A1')
.expand('table')
.options(pd.DataFrame, index=False, numbers=int, header=True)
.value
)
# 添加班级列
df_student['班级'] = class_
df_student_list.append(df_student)
# 合并多个sheet的学生数据
df_student = pd.concat(df_student_list)
df_merge = pd.merge(df_total, df_student, left_on=["班级", "姓名"], right_on=["班级", "姓名"])
df_merge["电话号码"]=df_merge["号码"]
# inplace=True表示在原数据上修改
df_merge.drop(columns=["号码"], inplace=True)
# 更新excel表格
wb.sheets[0].range('A1').value = df_merge
wb.save()
wb.close()
app.quit()
读取多个excel实现汇总统计
import pandas as pd
import os
# 合并多个excel文件到单个
directory = "销售表"
# 获取文件夹下的所有文件名
df_list = []
for filename in os.listdir(directory):
if filename.endswith(".xlsx"):
# 读取excel文件 并添加到df_list列表中
df_list.append(pd.read_excel(f"{directory}/{filename}"))
# 合并多个excel文件到单个
df_all = pd.concat(df_list)
# 统计每个产品销售利润的综合、最大、最小、平均
def compute_data(df_sub):
return pd.Series({
# round()表示保留两位小数
# df_sub[]表示取df_sub的某一列
"销售利润综合": round(df_sub["销售利润"].sum(), 2),
"销售利润最大": round(df_sub["销售利润"].max(), 2),
"销售利润最小": round(df_sub["销售利润"].min(), 2),
"销售利润平均": round(df_sub["销售利润"].mean(), 2),
})
# 按产品名称分组
# .apply(compute_data)表示对分组后的每个子df执行compute_data函数
df_group = df_all.groupby("产品名称").apply(compute_data)
# 输出到excel,index=True表示输出索引
df_group.to_excel("销售表/销售表统计.xlsx", index=True)
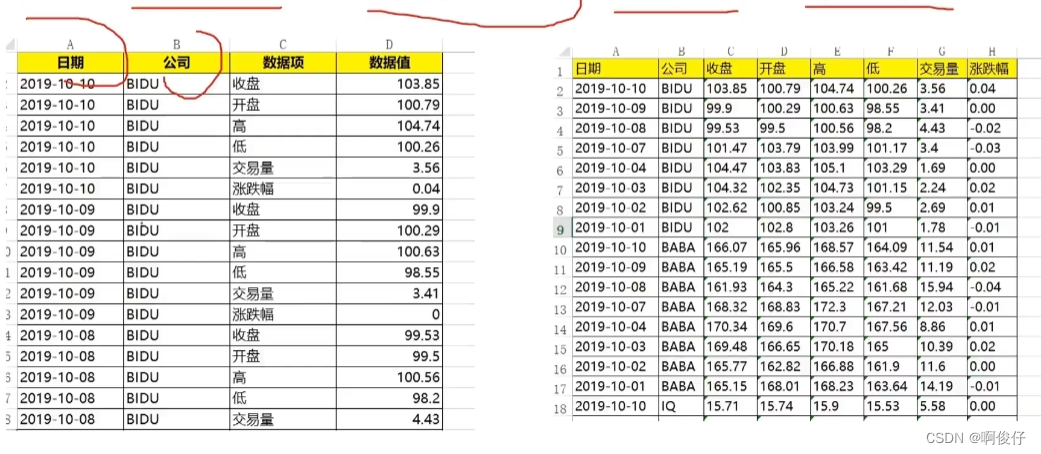
# 什么是透视表?
# 将列式数据转换成二维交叉形式,便于分析,叫做透视表
import pandas as pd
# 读取excel文件
df = pd.read_excel("互联网公司股票.xlsx")
# 透视表数据
# .pivot_table()表示生成透视表
df_pivot = pd.pivot_table(
df
# index表示行索引
,index=["公司", "日期"]
# values表示数据项
,values=["数据值"]
# columns表示列索引
,columns=["数据项"]
)
# 保存透视表数据
df_pivot.to_excel("透视表.xlsx")
-
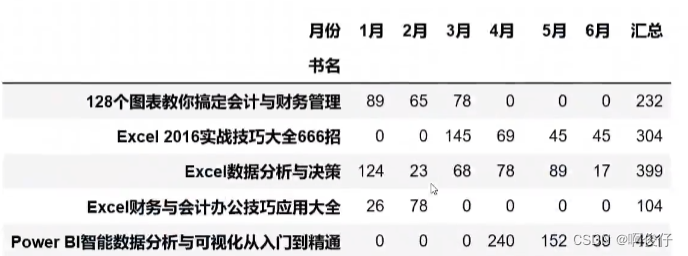

import pandas as pd # 读取excel文件 # sheet_name=None表示读取所有sheet 不加参数表示读取第一个sheet df = pd.read_excel("上半年销售统计表.xlsx",sheet_name=None) # 给sheet添加月份列,并合并多个表格 df_list = [] # df.items()表示遍历df的每一个sheet for sheet_name, sheet in df.items(): # sheet_name表示sheet的名字 sheet["月份"] = sheet_name df_list.append(sheet) # 合并月份列 df_month = pd.concat(df_list) # 透视表数据 df_pivot = pd.pivot_table( df_month, index=["书名"], columns=["月份"], values=["销售数量"], aggfunc="sum", # fill_value=0表示填充空值为0 fill_value=0, # margins=True表示显示总计 margins=True, # margins_name="总计"表示总计的名字为总计 margins_name="总计" ) df_pivot.to_excel("透视表.xlsx") -
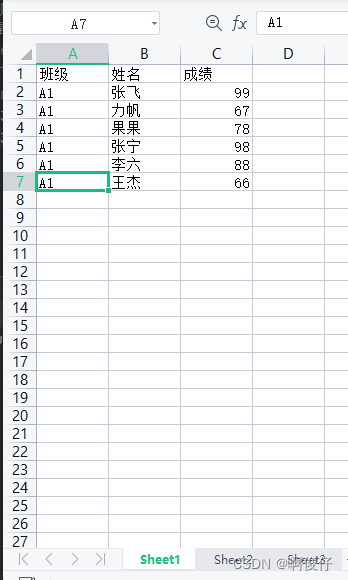

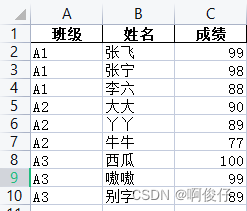
# 一个excel文件,多个sheet,每个sheet中包含班级、姓名、成绩 import pandas as pd # 读取excel文件 # sheet_name=None表示读取所有sheet 不加参数表示读取第一个sheet df = pd.read_excel("学生成绩表.xlsx",sheet_name=None) # 合并成一张表 # df.values()表示遍历df的每一个sheet df_total = pd.concat(df.values()) # 根据班级列分组,取每个班级的前三名 # groupby("班级")和.groupby(["班级"])区别在于前者返回的是Series对象,后者返回的是DataFrame对象 # 什么是Series对象?什么是DataFrame对象? # Series对象是一维数组,DataFrame对象是二维数组 # .apply()表示对每个分组进行操作 # .nlargest(3, "成绩")表示取每个分组的成绩列的前三名,取到的数据例如 100 99 98 df_top3 = df_total.groupby(["班级"]).apply(lambda x: x.nlargest(3, "成绩")) df_top3.to_excel("学生成绩表_前三名.xlsx", index=False)
给学生随机分配考号
import numpy as np
import xlwings as xw
# 用numpy生成随机数
# 生成10个0-9范围内的全排列
# numbers = np.random.permutation(10)
app = xw.App(visible=True, add_book=False)
wb = app.books.open('学生成绩表.xlsx')
sheet = wb.sheets[0]
# 计算学生个数
# 从A4开始,shape[0]表示行数 shape[1]表示列数
student_count = sheet.range('A4').expand('table').shape[0]
# 生成随机全排列
student_count = np.random.permutation(student_count)+1
# 垂直赋值,从e4开始
# transpose=True表示转置
sheet.range('E4').options(transpoe=True).value = student_count
wb.save()
wb.close()
app.quit()
计算excel销量数据的日同比
import pandas as pd
# 什么是日同比? 今天的销量与昨天的销量相比较
# 如何计算日同比? 今天的销量/昨天的销量-1
# 读取excel文件
df = pd.read_excel('销量数据.xlsx')
# 增加移动列
df["上一日"] = df["销量"].shift()
# 计算日同比
df["日同比"] = df["销量"] / df["上一日"] - 1
# 删除上一日列
df.drop(columns=["上一日"], inplace=True)
# 将空值替换为0
df.fillna(0.0, inplace=True)
# 将日同比列的数据格式化为小数点后两位
df["日同比"] = df["日同比"].map(lambda x: format(x, ".2%"))
file = '销量数据.xlsx'
with pd.ExcelFile(file,date_format='YYYY-MM-DD') as writer:
df.to_excel(writer, sheet_name='日同比', index=False)
批量读取word数据到excel




读取word统计词频输出到excel
import docx
import jieba
import pandas as pd
from collections import Counter
document = docx.Document("python从入门到入土学习笔记.docx")
content = " ".join([para.text for para in document.paragraphs])
# cut_all=False 精确模式
# .cut()方法接受两个输入参数:一是需要分词的字符串;二是是否使用HMM模型。
seg_list = jieba.cut(content, cut_all=False)
# 过滤标点符号、无意义的单个词
seg_list = [
# word for word in seg_list表示将seg_list中的每个元素word取出来
# if len(word) > 1 and word != '\r\n'表示对word进行过滤
# 最后将过滤后的word放入列表中
word for word in seg_list
if len(word) > 1 and word != '\r\n'
]
# seg_list里的数据格式为列表,需要将列表转换为字符串
# 词频统计
word_counts = Counter(seg_list)
for key, count in list(word_counts.items()):
print(key, count)
# 构造pandas并且排序
# columns=['word','count']表示构造一个两列的DataFrame,列名分别为word和count
df = pd.DataFrame(list(Counter.items()), columns=['word', 'count'])
# 按照count列进行降序排列
df.sort_values(by=['count'], ascending=False, inplace=True)
# 将DataFrame写入excel
df.to_excel('python从入门到入土学习笔记词频统计.xlsx', index=False)
读取excel批量生成word文档
import pandas as pd
from docxtpl import DocxTemplate
import datetime
# 读取excel
# index_col='姓名' 以姓名为索引
df = pd.read_excel('学生成绩表.xlsx', index_col='姓名')
print(df.head(5))
# .now()获取当前时间 .strftime('%Y-%m-%d')格式化时间
pdate = datetime.datetime.now().strftime('%Y-%m-%d')
# 遍历excel
for name,row in df.iterrows():
# .format()格式化字符串
print("正在生成{}的成绩单...".format(name))
# 生成word文档,这个模板是我自己写的,可以根据自己的需求写
doc = DocxTemplate('成绩单模板.docx')
# 生成word文档的数据
doc.render(dict(
姓名=name,
语文=row['语文'],
数学=row['数学'],
英语=row['英语'],
总分=row['语文']+row['数学']+row['英语'],
日期=pdate
))
# 保存word文档
doc.save('成绩单/{}.docx'.format(name))

import flask
# flask是一个轻量级的web框架,可以用来在网页上展示excel文件
import pandas as pd
# flask.Flask(__name__)创建一个Flask对象,__name__是当前模块名字
app = flask.Flask(__name__)
# 通过route()装饰器告诉Flask什么样的URL能触发我们的函数
@app.route('/excel')
def show_excel():
df = pd.read_excel('学生成绩表.xlsx')
return df.to_html()
app.run()
# 查看ip,ipconfig
在网页上展示透视表
import pandas as pd
import flask
app = flask.Flask(__name__)
@app.route("/excel")
def show_excel():
df = pd.read_excel("按月采购表.xlsx")
df_pivot = pd.pivot_table(
df, index="月份", columns="采购物品", values="采购金额", fill_value=0.0
)
return f"""
<html>
<body>
<h1>按月采购表-透视图</h1>
<body>
<html>
""" % df_pivot.to_html()
app.run()
制作网页查询excel
# flask用于制作网页
import flask
# pandas用于读取excel文件
import pandas as pd
# request用于获取网页传递的参数
from flask import request
# 创建一个flask对象
app = flask.Flask(__name__)
@app.route('/query_grade', methods=['get', 'post'])
def query_grade():
df = pd.read_excel('学生成绩表.xlsx')
# pd.DataFrame()创建一个空的DataFrame 用于存放查询结果
grade_data = pd.DataFrame()
# request.values.get()获取网页传递的参数
# 例如:student_name = request.values.get('student_name')
# request.from.get()获取网页传递的参数
# 例如:student_name = request.form.get('student_name')
# 区别:request.values.get()可以获取get和post方式传递的参数
# request.from.get()只能获取post方式传递的参数
student_name = request.values.get('student_name')
if student_name:
# df.query()用于查询数据 返回一个DataFrame
grade_data = df.query(f"姓名=='{student_name}'")
# 页面显示一个查询框、按钮以及显示查询结果
# 用于显示查询结果的表格
html = grade_data.to_html()
# 用于显示查询框、按钮以及显示查询结果的网页
# 没有查到提示查询错误
return f'''
<form action="/query_grade" method="post">
<p>请输入学生姓名:<input type="text" name="student_name" /></p>
<p><button type="submit">查询</button></p>
</form>
{html}
'''
app.run()
读取excel存储到MySQL
import pandas as pd
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
user='root',
password='5477',
port=3306,
db='test_school',
charset='utf8'
)
df = pd.read_excel("学生成绩表.xlsx")
for idx, row in df.iterrows():
print(f"正在插入第{idx}条数据:", row)
# row里的数据是Series类型的,可以通过row['列名']或者row.列名来获取数据
sql = f"""
insert into score(name,yw_score,sx_score,yy_score,total_score)
values('{row["姓名"]}',{row["语文"]},{row["数学"]},{row["英语"]},{row["语文"]+row["数学"]+row["英语"]})
"""
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
cursor.close()
查询MySQL导出到excel(新写法,基于sqlalchemy的)
import pandas as pd
import pymysql
from sqlalchemy import create_engine
MYSQL_HOST = 'localhost'
MYSQL_PORT = '3306'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '5477'
MYSQL_DB = 'test_school'
engine = create_engine('mysql+pymysql://%s:%s@%s:%s/%s?charset=utf8'
% (MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, MYSQL_DB))
sql = 'select * from score'
df = pd.read_sql(sql, engine)
df.to_excel("从MySQL导出的成绩表.xlsx", index=False)
读取excel绘制折线图
import xlwings as xl
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
# visible=False表示不显示excel文件 add_book=False表示不新建工作簿
app = xl.App(visible=False, add_book=False)
# 打开excel文件
wb = app.books.open('销售情况折线图.xlsx')
sheet = wb.sheets[0]
df = sheet.range("A1").options(pd.DataFrame, expand='table').value
# 绘制折线图
# figasize表示图像大小 dpi表示图像清晰度
figure = plt.figure(figsize=(12, 6), dpi=100)
# df["销量"]表示绘制的数据
plt.plot(df["销量"])
sheet.pictures.add(figure,
name='销售情况折线图',
update=True,
left=sheet.range("E3").left,
top=sheet.range("E3").top)
wb.save()
wb.close()
app.quit()
读取Excel自动生成PDF文档-表格中中文乱码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
# reportlab库是用来生成pdf文件的
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
from reportlab.lib.styles import getSampleStyleSheet, ParagraphStyle
from reportlab.platypus import Paragraph, SimpleDocTemplate, Spacer, Image, Table, TableStyle
from reportlab.lib import colors
from reportlab.lib.units import inch
from reportlab.lib.pagesizes import A4, landscape
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
pdfmetrics.registerFont(TTFont('msyh', 'msyh.ttf'))
# 读取Excel文件
df = pd.read_excel("销售情况折线图.xlsx", index_col='类型')
df_desc = (
df.describe()
.applymap(lambda x: format(x, '0.2f'))
.reset_index()
.rename(columns={'index': '统计项'})
)
# 输出统计图
# bins: 指定直方图的条形数为20个
# alpha: 指定透明度为0.5
# figsize: 指定图表大小为10*6
# subplots: 指定绘制子图
df.plot.hist(bins=20, alpha=0.5, figsize=(10, 6), subplots=True)
# .savefig方法保存图片,dpi指定图片像素
plt.savefig('销售情况折线图.png', dpi=300)
# 开始构建pdf,添加标题文字
# 容纳所有的pdf的内容
elements = []
# 读取reportlab的样式
styles = getSampleStyleSheet()
# 添加标题文字
elements.append(Paragraph('销售情况折线图', styles['Title']))
# 添加表格
# 转成数组,to_numpy()方法用于将DataFrame转换为NumPy数组
table_data = [list(df_desc.columns)] + df_desc.to_numpy().tolist()
# 小标题
elements.append(Paragraph('统计明细', styles['Heading2']))
# 表格对象
mytable = Table(table_data)
# 添加表格样式
mytable.setStyle(TableStyle([
('BACKGROUND', (0, 0), (-1, 0), colors.green),
('ALIGN', (0, 0), (-1, -1), 'CENTER'),
('TEXTCOLOR', (0, 0), (-1, 0), colors.whitesmoke),
('INNERGRID', (0, 0), (-1, -1), 0.25, colors.black),
('BOX', (0, 0), (-1, -1), 0.25, colors.black),
]))
# 添加对象
elements.append(mytable)
# 添加空行
elements.append(Spacer(1, 12))
# 添加小标题
elements.append(Paragraph('统计图', styles['Heading2']))
# 添加图片
elements.append(Image('销售情况折线图.png', 10 * inch, 6 * inch))
# 添加空行
elements.append(Spacer(1, 12))
# 生成pdf文件
# pagesize: 指定页面大小为A4,landscape()方法用于将页面设置为横向
# A4[0],A4[1]分别表示A4纸的宽和高
doc = SimpleDocTemplate('销售情况折线图.pdf', pagesize=landscape(A4))
doc.build(elements)
读取Excel自动发送邮件
import pandas as pd
import smtplib
from email.mime.text import MIMEText
from email.header import Header
# 邮件内容
df = pd.read_excel('学生成绩表.xlsx')
html = df.to_html()
message = MIMEText(html, 'html', 'utf-8')
# 发送地址
from_addr,to_email = '1184403572@qq.com','1184403572@qq.com'
# 邮件信息
message['Subject'] = Header('学生成绩表', 'utf-8')
message['From'],message['To'] = from_addr,to_email
# 使用qq邮箱的服务,发送邮件
# .SMTP_SSL()是安全传输,端口号是465
smtp_server = smtplib.SMTP_SSL('smtp.qq.com', 465)
# 登录邮箱
smtp_server.login(from_addr, 'vkvadnswwoldiiic')
# 发送邮件
# 第一个参数是发送地址,第二个参数是接收地址,第三个参数是发送的信息
# .as_string()是将信息转化为字符串
smtp_server.sendmail(from_addr, [to_email], message.as_string())
# 关闭邮箱
smtp_server.quit()
批量重命名图片名
# coding=utf-8
import os
import shutil
import zipfile
path = "C:\\Users\\GJunJ\\Desktop\\图片"
path2 = "C:\\Users\\GJunJ\\Desktop\\图片result"
list_id = []
def getIDList():
for i in range(2):
id = input("输入编号:")
list_id.append(id)
print(id, '\n')
# 根据编号前缀[]、源文件夹路径、目标文件夹路径
def newFileName(listId):
for ii in listId:
print(ii, '\n')
for i in os.listdir(path):
print("i = ", {i}, "\n")
# # 设置旧文件名(就是路径+文件名)
fname = i
oldname = path + os.sep + i
print("oldname = ", {oldname}, "\n")
# 设置新文件名 qaz1234567898
newname = path + os.sep + ii + fname[13:]
print("newname = ", {newname}, "\n")
os.rename(oldname, newname)
shutil.copy(newname, path2)
# p = "C:\\Users\\GJunJ\\Desktop\\图片result\\"
# 删除指定路径下的全部文件(不删除文件夹)
def removeAllFiles(path):
for i in os.listdir(path):
os.remove(path + os.path.basename(i))
# os.getcwd() 获取当前路径
print("成功删除", {path + os.path.basename(i)}, "\n")
# 压缩文件路径
zip_path = 'C:\\Users\\GJunJ\\Desktop\\图片.zip'
# 文件存储路径
save_path = 'C:\\Users\\GJunJ\\Desktop\\'
# 解压.zip文件,并将解压后的文件放入指定文件夹中
def unzipFile(zip_path, save_path):
# 读取压缩文件
file = zipfile.ZipFile(zip_path)
# 解压文件
print('开始解压...')
file.extractall(save_path)
print('解压结束。')
# 关闭文件流
file.close()
if __name__ == '__main__':
getIDList()
newFileName(list_id)
# removeAllFiles(p)
# pyinstaller -F 批量重命名图片名.py
# pyinstaller -F -i favicon.ico --name=work.exe 批量重命名图片名.py
读取Excel实现线性回归预测
# 用总金额预测消费
import pandas as pd
import matplotlib.pyplot as plt
# 导入线性回归模型
from sklearn.linear_model import LinearRegression
# 读取数据
df = pd.read_excel('小费数据集.xlsx')
# 散点图观测效果
plt.scatter(df['total_bill'], df['tip'])
# 训练回归预测
# 1. 创建模型
model = LinearRegression()
# 2. 训练模型
# .fit()方法的第一个参数是自变量,第二个参数是因变量
# .to_numpy()是将数据框转化为数组
# .reshape(-1,1)是将一维数组转化为二维数组
model.fit(df[['total_bill']].to_numpy().reshape(-1, 1), df['tip'])
# 3. 预测
# .predict()方法的参数是自变量
predicts = model.predict(df[['total_bill']].to_numpy().reshape(-1, 1))
# .scatter()方法的第一个参数是自变量,第二个参数是因变量,此方法是画散点图
plt.scatter(df['total_bill'], df['tip'])
# .plot()方法的第一个参数是自变量,第二个参数是因变量,此方法是画线
plt.plot(df['total_bill'], predicts, color='red')
# .show()方法是显示图形
plt.show()
# 输入账单金额预测小费
total_bill = 40
predicts = model.predict([total_bill])
课程总结
-
python能做的

-
发开工具
















 1275
1275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









