







论算法是如何优化的:四数之和
心路历程
闲来无事,刷刷力扣,突然看到一道题目叫做四数之和,难度中等,心想,这不就是我大显身手的时候了吗???我直接就是一个点击进入,看到题目,我懵了,这…好像除了暴力解法想不到怎么做,于是转身想要离开,就在离开之际,我转念一想,看看评论,就一眼,进去定睛一看,情形如下:
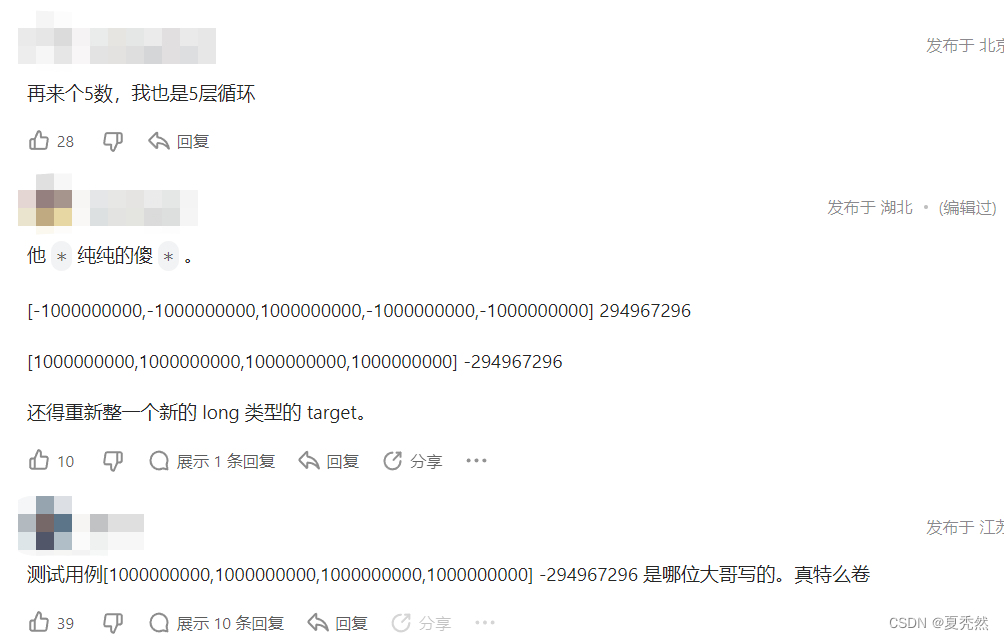
此题必有蹊跷!!!通关率为 37.7% 的一道题目,这样的评论已经刷屏,但是!!! 我用的是python,此等难题,必然不是能够阻挡我的借口,那岂不是说???只要没有这个问题,那通过率岂不是高到起飞,于是!!我打算来此大展身手,小垃圾题目,给我过!!!!
于是便有了下面的内容…先看一下题目介绍吧。
题目介绍:四数之和
难度:中等
给你一个由 n n n 个整数组成的数组 n u m s nums nums,和一个目标值 t a r g e t target target 。请你找出并返回满足下述全部条件且不重复的四元组 [ n u m s [ a ] , n u m s [ b ] , n u m s [ c ] , n u m s [ d ] ] [nums[a], nums[b], nums[c], nums[d]] [nums[a],nums[b],nums[c],nums[d]](若两个四元组元素一一对应,则认为两个四元组重复):
- 0 < = a , b , c , d < n 0 <= a, b, c, d < n 0<=a,b,c,d<n
- a 、 b 、 c a、b、c a、b、c 和 d d d 互不相同
- n u m s [ a ] + n u m s [ b ] + n u m s [ c ] + n u m s [ d ] = = t a r g e t nums[a] + nums[b] + nums[c] + nums[d] == target nums[a]+nums[b]+nums[c]+nums[d]==target
你可以按 任意顺序 返回答案 。
示例 1:
输入:nums = [1,0,-1,0,-2,2], target = 0
输出:[[-2,-1,1,2],[-2,0,0,2],[-1,0,0,1]]
示例 2:
输入:nums = [2,2,2,2,2], target = 8
输出:[[2,2,2,2]]
算法优化过程(心路历程)
版本1
上述就是题目的介绍,看到这样的题目,我思索再三,没什么好的办法,直接上一波四重循环遍历,由于题中表明不可能有重复的数组,那我直接对每次要放进去的列表来一波排序,之后判断改列表是否在返回的答案中,如果没有才进行添加。
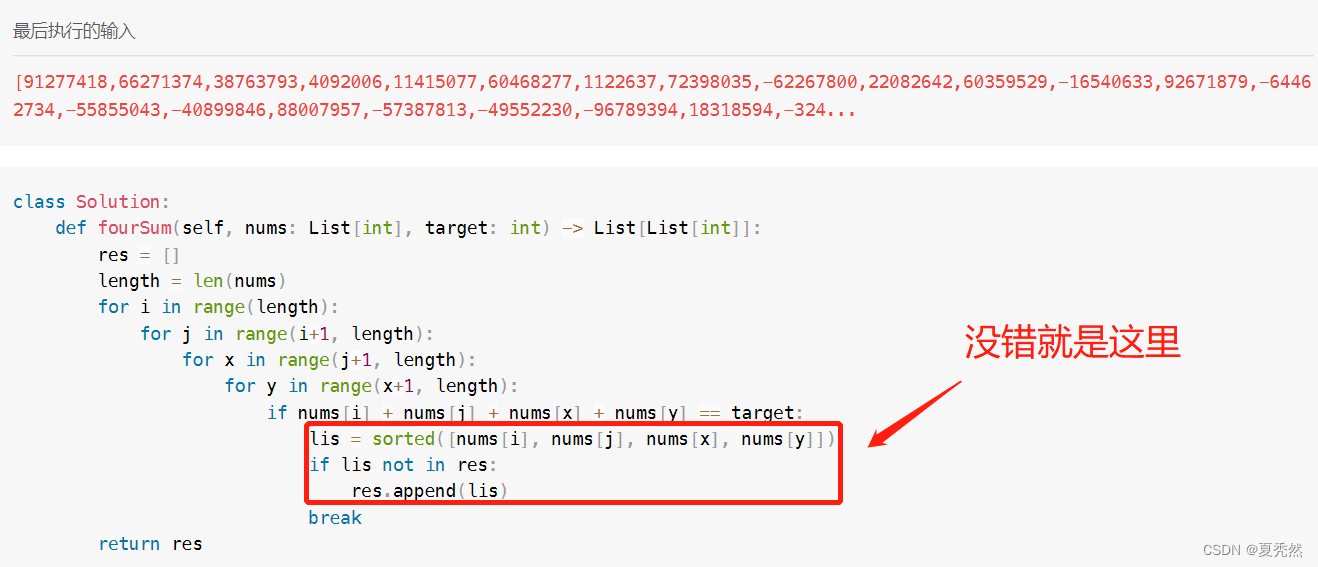
不出意外,果然超时,可恶啊!!!
版本2
不过我不死心,回想评论区有hxd说再来5个数,我也是5层循环,我抱着循环必过心里,对代码进行初步优化,观测代码,我觉得在 O ( n 4 ) O(n^4) O(n4) 的时间复杂度里面,我用了排序,岂不是有 O ( n 4 l o g ( n ) ) O(n^4 log(n)) O(n4log(n)) 的时间复杂度!!!我慌的不行当即把他拿出去,改成了对整体数组排序,之后再进行循环。
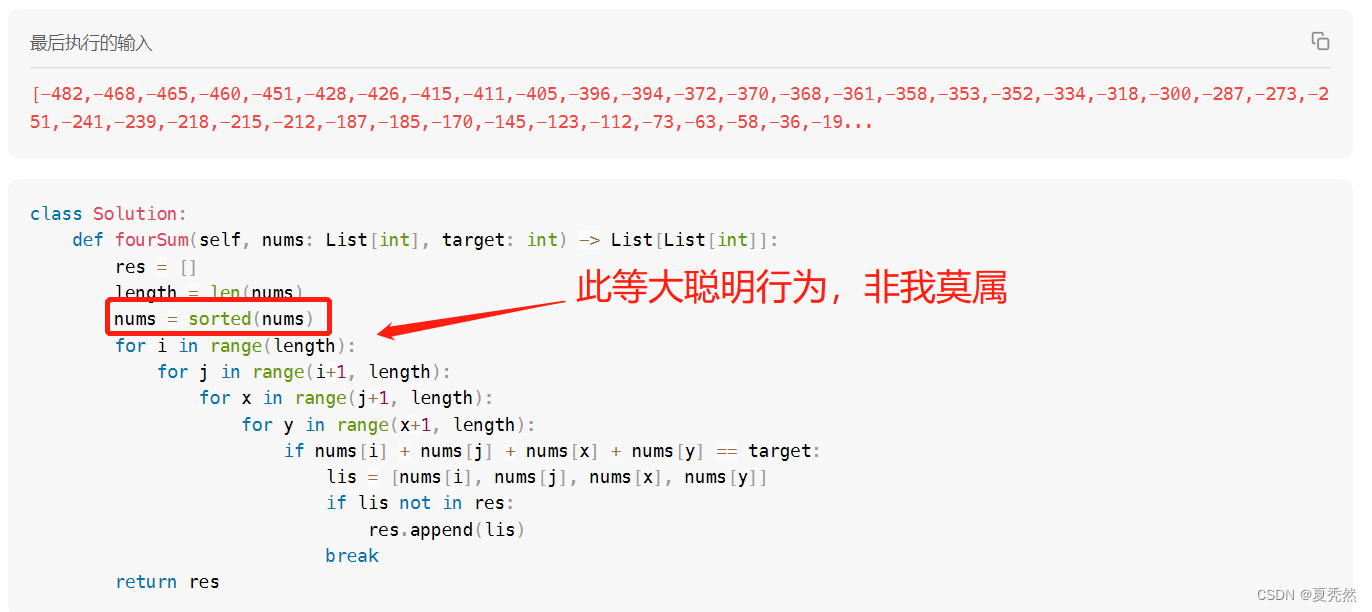
果然!!!就算如此,根本于事无补。
版本3
马萨卡,就要这样结束了吗?不!!!!我直接一手头头看评论,看到了和三数之和类似,虽然我没刷过,但是我恍惚间想到了第一题:两数之和!!!!,没错,一定是二分查找,能把最内圈循环优化掉,说时迟那时快,我接一波冲。
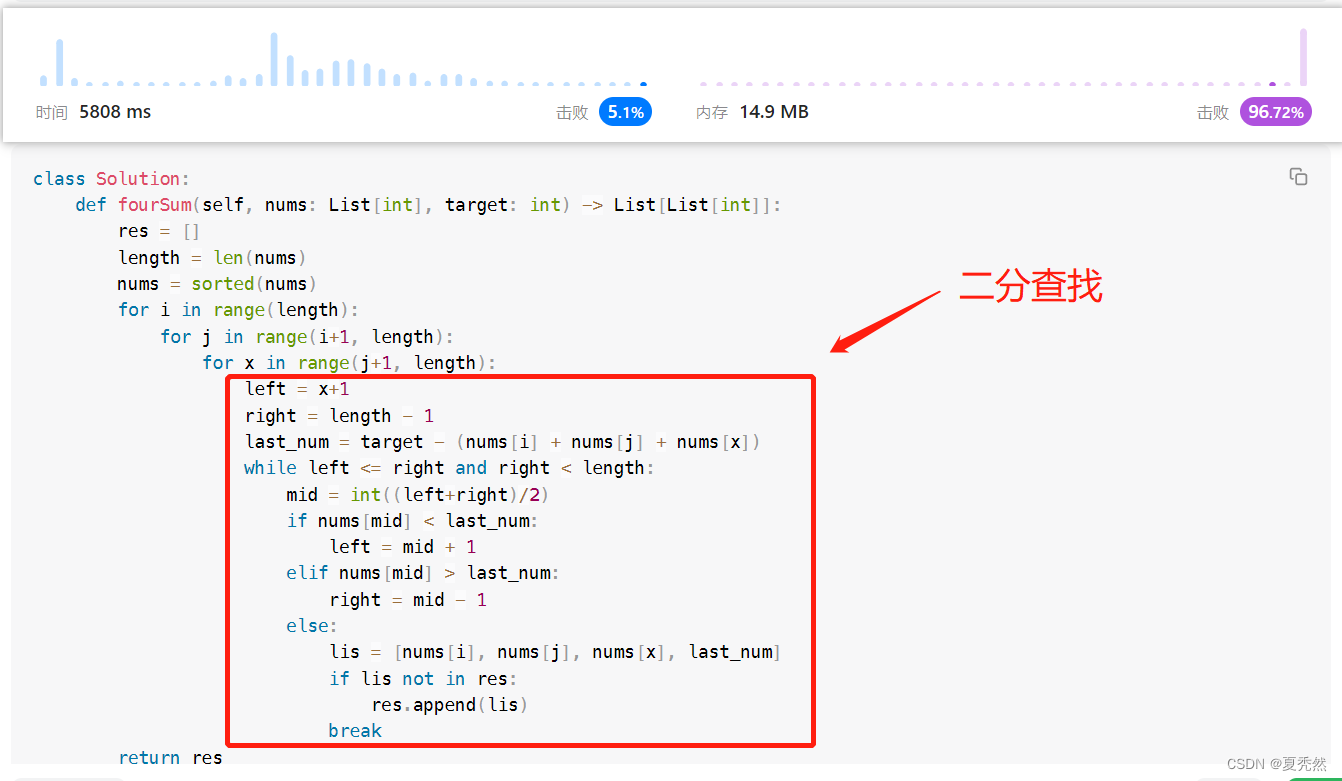
我直接就是一波,过了!!!,然而一看时间,只击败了 5.1%,才5.1%????我如此辛苦做出来的题目,竟然才击败了5.1%,我不服!!!!(时间复杂度是截图到这边的,不然图片太长看不到,我这可不是盗图哈哈哈哈哈哈)
版本4
于是乎,我选择再次悄悄看一下评论,不,是官方题解!!!,他的方法叫做 排序 + 双指针,我一看,排序我已经实现,双指针怎么做,我用的是二分查找,有什么区别吗???有!!!那就是二分查找只能取消一层循环,但是双指针能取消两层循环,这波双指针就叫做头尾双指针,和盛最多水的容器这道题类似,这题我刷过!!!直接干。
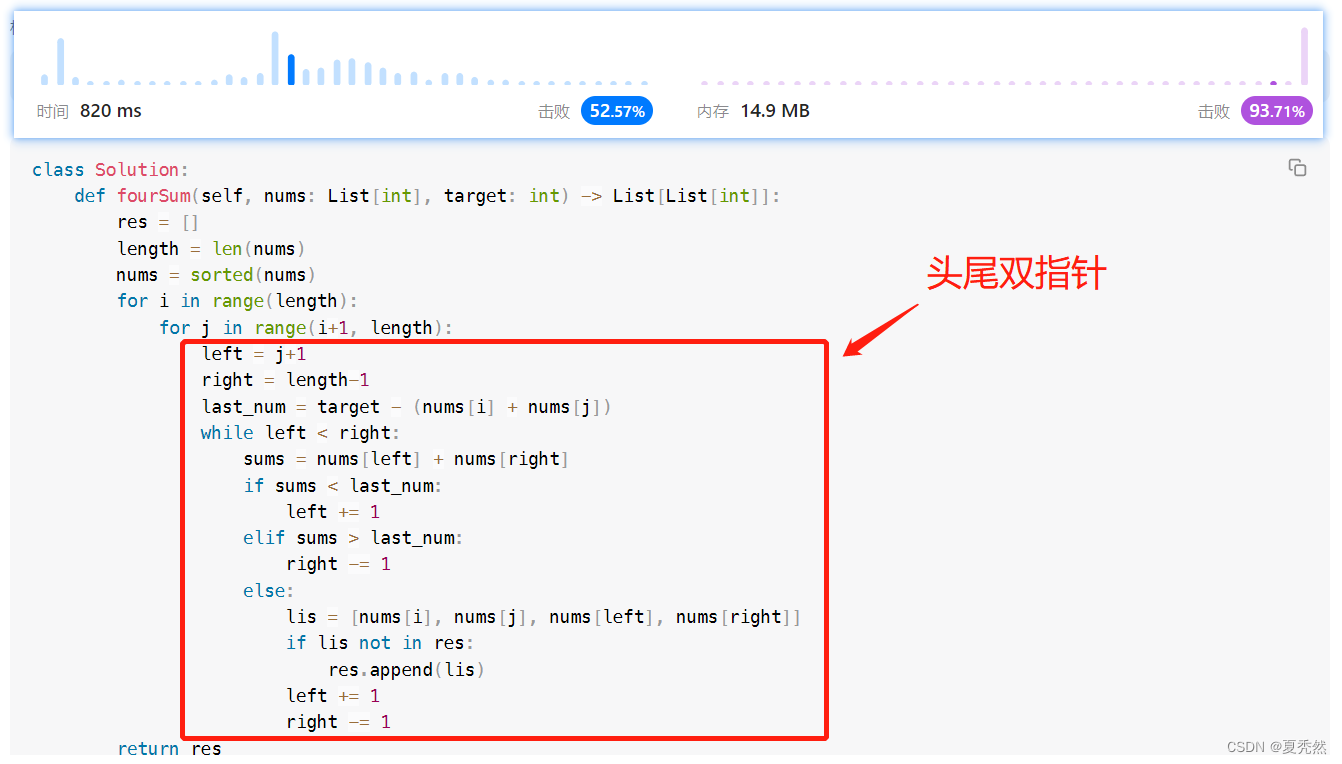
过了过了!!!,时间提升到了52.57%,就当我打算适可而止的时候,发现在统计提交时间的柱状图里面,最前面为什么会有那么高的比例,而且比我的时间还少一大截,难道还有优化???
版本5
我抱着怀疑的心态,去细细查看官方题解,上面是这么说的:

这也是我为什么写这篇文章的意义,可能在实际算法设计以及实现时,剪枝操作也是必不可少的,于是便有了下面的代码。
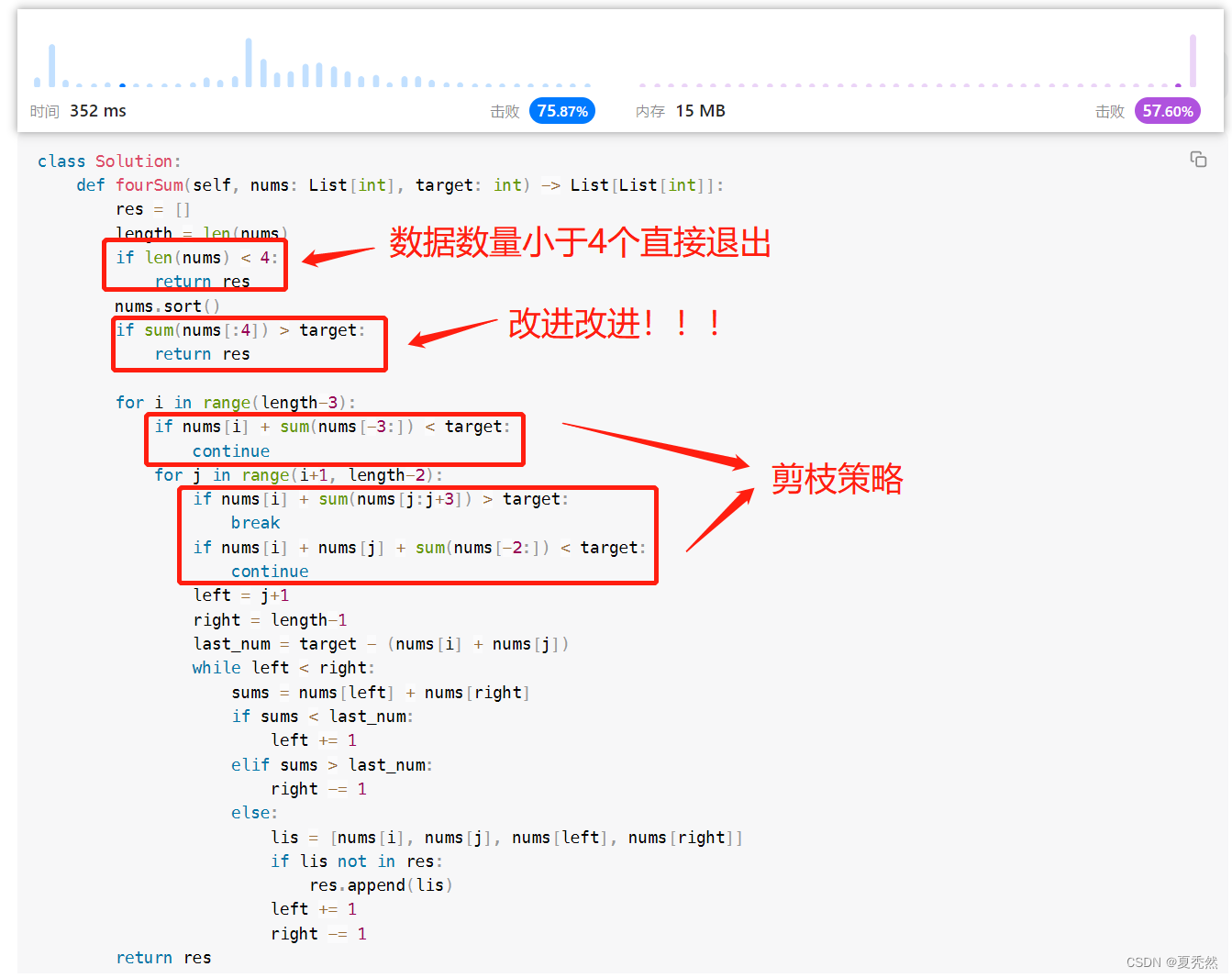
可以看到上述,我添加了官方题解中的剪枝策略,并且!!!我把确定第一个数判断最小的四个值之和大于目标值放到了最外面判断,因为!!!如果在里面判断,但凡第一次判断最小的四个值之和小于目标值,那么后续不管第一个数怎么变换,值一定小于,所以不需要放到里面,放在里面反而在小于的时候多判断n-3次,我可太机智了!!!
对了,还有数据量小于4直接返回空即可,可以不进行排序操作。
但是尽管如此,我的 300+ms 还是和 60+ms 有不少的差距。
版本6
于是,我又又又去看了官方题解,有没有什么遗漏,果然!!!

于是乎,我再次对代码进行修改,结果如下:
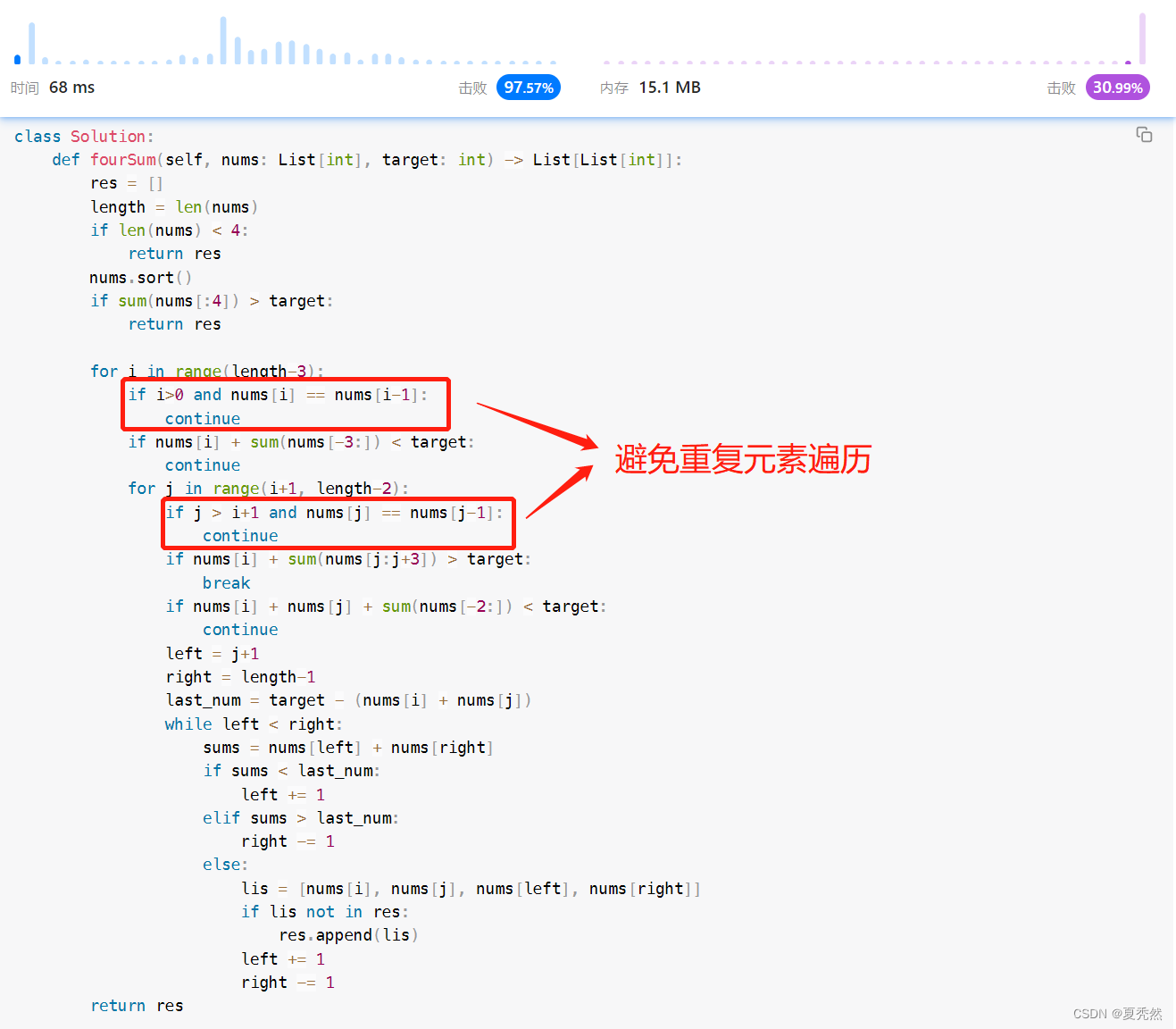
终于!!!功夫不负有心人,进行了6个版本的改进,时间从超时变成了击败97.57%!!!!这就是这道算法题的优化过程。
记录此次解题经历不仅是为了对解题过程的记录,还为了提醒自己以及在座的兄弟们,优化来自多个方面,算法只不过是优化的一部分,除去算法,设立一定的决策条件也是必不可少的。
当然不止如此。就好比我把所有的测试用例的结果都写出来之后用字典返回结果的速度肯定比这个更快哈哈哈。
这就是本次分享的全部内容,溜了溜了。















 335
335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











